 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGAMBAS: Generalised-Hilbert Mamba for Super-resolution of Paediatric Ultra-Low-Field MRI
Apr 06, 2025Magnetic resonance imaging (MRI) is critical for neurodevelopmental research, however access to high-field (HF) systems in low- and middle-income countries is severely hindered by their cost. Ultra-low-field (ULF) systems mitigate such issues of access inequality, however their diminished signal-to-noise ratio limits their applicability for research and clinical use. Deep-learning approaches can enhance the quality of scans acquired at lower field strengths at no additional cost. For example, Convolutional neural networks (CNNs) fused with transformer modules have demonstrated a remarkable ability to capture both local information and long-range context. Unfortunately, the quadratic complexity of transformers leads to an undesirable trade-off between long-range sensitivity and local precision. We propose a hybrid CNN and state-space model (SSM) architecture featuring a novel 3D to 1D serialisation (GAMBAS), which learns long-range context without sacrificing spatial precision. We exhibit improved performance compared to other state-of-the-art medical image-to-image translation models.
SIM: Surface-based fMRI Analysis for Inter-Subject Multimodal Decoding from Movie-Watching Experiments
Jan 27, 2025Current AI frameworks for brain decoding and encoding, typically train and test models within the same datasets. This limits their utility for brain computer interfaces (BCI) or neurofeedback, for which it would be useful to pool experiences across individuals to better simulate stimuli not sampled during training. A key obstacle to model generalisation is the degree of variability of inter-subject cortical organisation, which makes it difficult to align or compare cortical signals across participants. In this paper we address this through the use of surface vision transformers, which build a generalisable model of cortical functional dynamics, through encoding the topography of cortical networks and their interactions as a moving image across a surface. This is then combined with tri-modal self-supervised contrastive (CLIP) alignment of audio, video, and fMRI modalities to enable the retrieval of visual and auditory stimuli from patterns of cortical activity (and vice-versa). We validate our approach on 7T task-fMRI data from 174 healthy participants engaged in the movie-watching experiment from the Human Connectome Project (HCP). Results show that it is possible to detect which movie clips an individual is watching purely from their brain activity, even for individuals and movies not seen during training. Further analysis of attention maps reveals that our model captures individual patterns of brain activity that reflect semantic and visual systems. This opens the door to future personalised simulations of brain function. Code & pre-trained models will be made available at https://github.com/metrics-lab/sim, processed data for training will be available upon request at https://gin.g-node.org/Sdahan30/sim.
Weakly Supervised Learning of Cortical Surface Reconstruction from Segmentations
Jun 18, 2024Existing learning-based cortical surface reconstruction approaches heavily rely on the supervision of pseudo ground truth (pGT) cortical surfaces for training. Such pGT surfaces are generated by traditional neuroimage processing pipelines, which are time consuming and difficult to generalize well to low-resolution brain MRI, e.g., from fetuses and neonates. In this work, we present CoSeg, a learning-based cortical surface reconstruction framework weakly supervised by brain segmentations without the need for pGT surfaces. CoSeg introduces temporal attention networks to learn time-varying velocity fields from brain MRI for diffeomorphic surface deformations, which fit an initial surface to target cortical surfaces within only 0.11 seconds for each brain hemisphere. A weakly supervised loss is designed to reconstruct pial surfaces by inflating the white surface along the normal direction towards the boundary of the cortical gray matter segmentation. This alleviates partial volume effects and encourages the pial surface to deform into deep and challenging cortical sulci. We evaluate CoSeg on 1,113 adult brain MRI at 1mm and 2mm resolution. CoSeg achieves superior geometric and morphological accuracy compared to existing learning-based approaches. We also verify that CoSeg can extract high-quality cortical surfaces from fetal brain MRI on which traditional pipelines fail to produce acceptable results.
The Developing Human Connectome Project: A Fast Deep Learning-based Pipeline for Neonatal Cortical Surface Reconstruction
May 14, 2024The Developing Human Connectome Project (dHCP) aims to explore developmental patterns of the human brain during the perinatal period. An automated processing pipeline has been developed to extract high-quality cortical surfaces from structural brain magnetic resonance (MR) images for the dHCP neonatal dataset. However, the current implementation of the pipeline requires more than 6.5 hours to process a single MRI scan, making it expensive for large-scale neuroimaging studies. In this paper, we propose a fast deep learning (DL) based pipeline for dHCP neonatal cortical surface reconstruction, incorporating DL-based brain extraction, cortical surface reconstruction and spherical projection, as well as GPU-accelerated cortical surface inflation and cortical feature estimation. We introduce a multiscale deformation network to learn diffeomorphic cortical surface reconstruction end-to-end from T2-weighted brain MRI. A fast unsupervised spherical mapping approach is integrated to minimize metric distortions between cortical surfaces and projected spheres. The entire workflow of our DL-based dHCP pipeline completes within only 24 seconds on a modern GPU, which is nearly 1000 times faster than the original dHCP pipeline. Manual quality control demonstrates that for 82.5% of the test samples, our DL-based pipeline produces superior (54.2%) or equal quality (28.3%) cortical surfaces compared to the original dHCP pipeline.
Cortical Surface Diffusion Generative Models
Feb 07, 2024Cortical surface analysis has gained increased prominence, given its potential implications for neurological and developmental disorders. Traditional vision diffusion models, while effective in generating natural images, present limitations in capturing intricate development patterns in neuroimaging due to limited datasets. This is particularly true for generating cortical surfaces where individual variability in cortical morphology is high, leading to an urgent need for better methods to model brain development and diverse variability inherent across different individuals. In this work, we proposed a novel diffusion model for the generation of cortical surface metrics, using modified surface vision transformers as the principal architecture. We validate our method in the developing Human Connectome Project (dHCP), the results suggest our model demonstrates superior performance in capturing the intricate details of evolving cortical surfaces. Furthermore, our model can generate high-quality realistic samples of cortical surfaces conditioned on postmenstrual age(PMA) at scan.
Unsupervised Multimodal Surface Registration with Geometric Deep Learning
Nov 21, 2023



This paper introduces GeoMorph, a novel geometric deep-learning framework designed for image registration of cortical surfaces. The registration process consists of two main steps. First, independent feature extraction is performed on each input surface using graph convolutions, generating low-dimensional feature representations that capture important cortical surface characteristics. Subsequently, features are registered in a deep-discrete manner to optimize the overlap of common structures across surfaces by learning displacements of a set of control points. To ensure smooth and biologically plausible deformations, we implement regularization through a deep conditional random field implemented with a recurrent neural network. Experimental results demonstrate that GeoMorph surpasses existing deep-learning methods by achieving improved alignment with smoother deformations. Furthermore, GeoMorph exhibits competitive performance compared to classical frameworks. Such versatility and robustness suggest strong potential for various neuroscience applications.
Conditional Temporal Attention Networks for Neonatal Cortical Surface Reconstruction
Jul 21, 2023Cortical surface reconstruction plays a fundamental role in modeling the rapid brain development during the perinatal period. In this work, we propose Conditional Temporal Attention Network (CoTAN), a fast end-to-end framework for diffeomorphic neonatal cortical surface reconstruction. CoTAN predicts multi-resolution stationary velocity fields (SVF) from neonatal brain magnetic resonance images (MRI). Instead of integrating multiple SVFs, CoTAN introduces attention mechanisms to learn a conditional time-varying velocity field (CTVF) by computing the weighted sum of all SVFs at each integration step. The importance of each SVF, which is estimated by learned attention maps, is conditioned on the age of the neonates and varies with the time step of integration. The proposed CTVF defines a diffeomorphic surface deformation, which reduces mesh self-intersection errors effectively. It only requires 0.21 seconds to deform an initial template mesh to cortical white matter and pial surfaces for each brain hemisphere. CoTAN is validated on the Developing Human Connectome Project (dHCP) dataset with 877 3D brain MR images acquired from preterm and term born neonates. Compared to state-of-the-art baselines, CoTAN achieves superior performance with only 0.12mm geometric error and 0.07% self-intersecting faces. The visualization of our attention maps illustrates that CoTAN indeed learns coarse-to-fine surface deformations automatically without intermediate supervision.
The Multiscale Surface Vision Transformer
Mar 21, 2023Surface meshes are a favoured domain for representing structural and functional information on the human cortex, but their complex topology and geometry pose significant challenges for deep learning analysis. While Transformers have excelled as domain-agnostic architectures for sequence-to-sequence learning, notably for structures where the translation of the convolution operation is non-trivial, the quadratic cost of the self-attention operation remains an obstacle for many dense prediction tasks. Inspired by some of the latest advances in hierarchical modelling with vision transformers, we introduce the Multiscale Surface Vision Transformer (MS-SiT) as a backbone architecture for surface deep learning. The self-attention mechanism is applied within local-mesh-windows to allow for high-resolution sampling of the underlying data, while a shifted-window strategy improves the sharing of information between windows. Neighbouring patches are successively merged, allowing the MS-SiT to learn hierarchical representations suitable for any prediction task. Results demonstrate that the MS-SiT outperforms existing surface deep learning methods for neonatal phenotyping prediction tasks using the Developing Human Connectome Project (dHCP) dataset. Furthermore, building the MS-SiT backbone into a U-shaped architecture for surface segmentation demonstrates competitive results on cortical parcellation using the UK Biobank (UKB) and manually-annotated MindBoggle datasets. Code and trained models are publicly available at https://github.com/metrics-lab/surface-vision-transformers .
Surface Analysis with Vision Transformers
May 31, 2022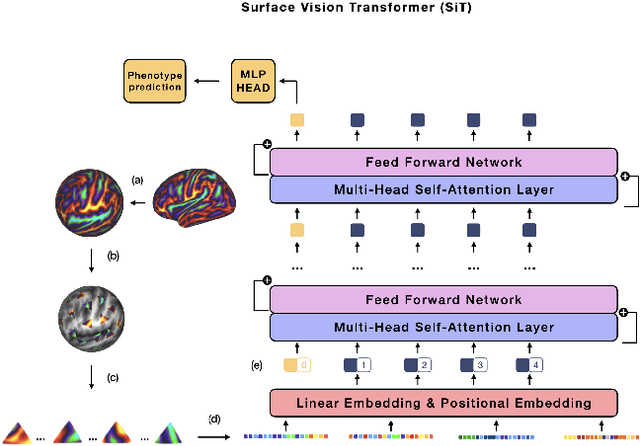

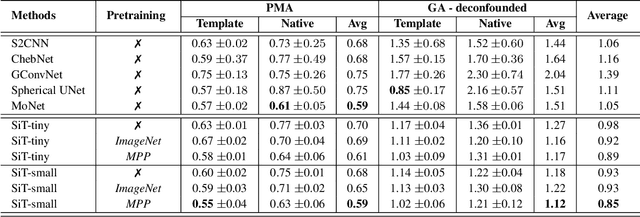
The extension of convolutional neural networks (CNNs) to non-Euclidean geometries has led to multiple frameworks for studying manifolds. Many of those methods have shown design limitations resulting in poor modelling of long-range associations, as the generalisation of convolutions to irregular surfaces is non-trivial. Recent state-of-the-art performance of Vision Transformers (ViTs) demonstrates that a general-purpose architecture, which implements self-attention, could replace the local feature learning operations of CNNs. Motivated by the success of attention-modelling in computer vision, we extend ViTs to surfaces by reformulating the task of surface learning as a sequence-to-sequence problem and propose a patching mechanism for surface meshes. We validate the performance of the proposed Surface Vision Transformer (SiT) on two brain age prediction tasks in the developing Human Connectome Project (dHCP) dataset and investigate the impact of pre-training on model performance. Experiments show that the SiT outperforms many surface CNNs, while indicating some evidence of general transformation invariance. Code available at https://github.com/metrics-lab/surface-vision-transformers
Surface Vision Transformers: Flexible Attention-Based Modelling of Biomedical Surfaces
Apr 07, 2022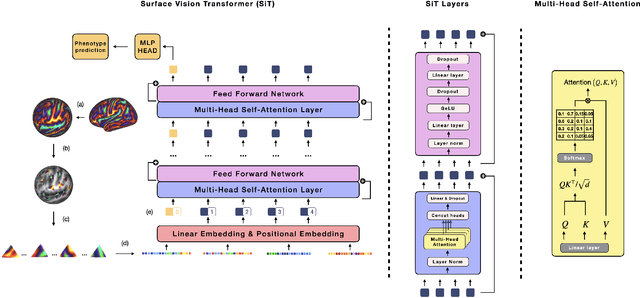
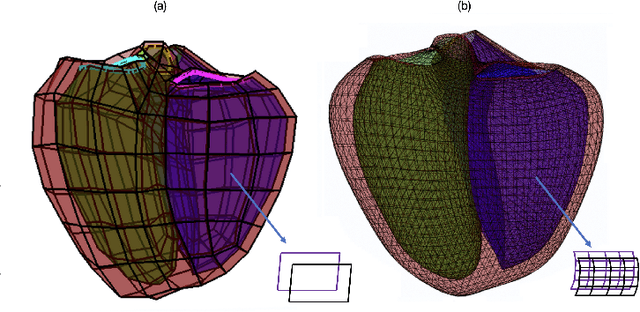
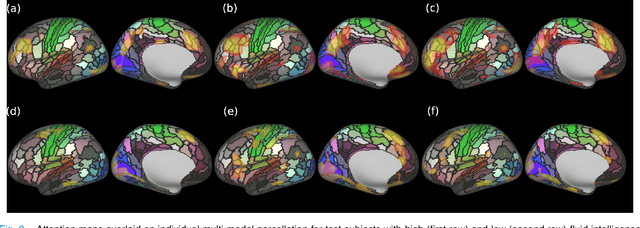
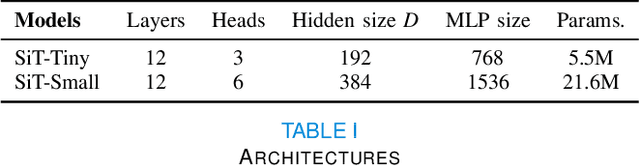
Recent state-of-the-art performances of Vision Transformers (ViT) in computer vision tasks demonstrate that a general-purpose architecture, which implements long-range self-attention, could replace the local feature learning operations of convolutional neural networks. In this paper, we extend ViTs to surfaces by reformulating the task of surface learning as a sequence-to-sequence learning problem, by proposing patching mechanisms for general surface meshes. Sequences of patches are then processed by a transformer encoder and used for classification or regression. We validate our method on a range of different biomedical surface domains and tasks: brain age prediction in the developing Human Connectome Project (dHCP), fluid intelligence prediction in the Human Connectome Project (HCP), and coronary artery calcium score classification using surfaces from the Scottish Computed Tomography of the Heart (SCOT-HEART) dataset, and investigate the impact of pretraining and data augmentation on model performance. Results suggest that Surface Vision Transformers (SiT) demonstrate consistent improvement over geometric deep learning methods for brain age and fluid intelligence prediction and achieve comparable performance on calcium score classification to standard metrics used in clinical practice. Furthermore, analysis of transformer attention maps offers clear and individualised predictions of the features driving each task. Code is available on Github: https://github.com/metrics-lab/surface-vision-transformers