 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSublinear Optimal Policy Value Estimation in Contextual Bandits
Dec 13, 2019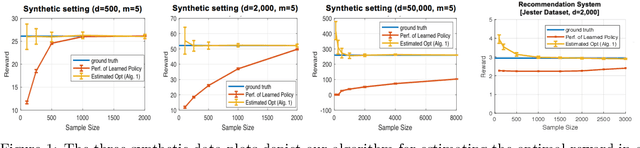
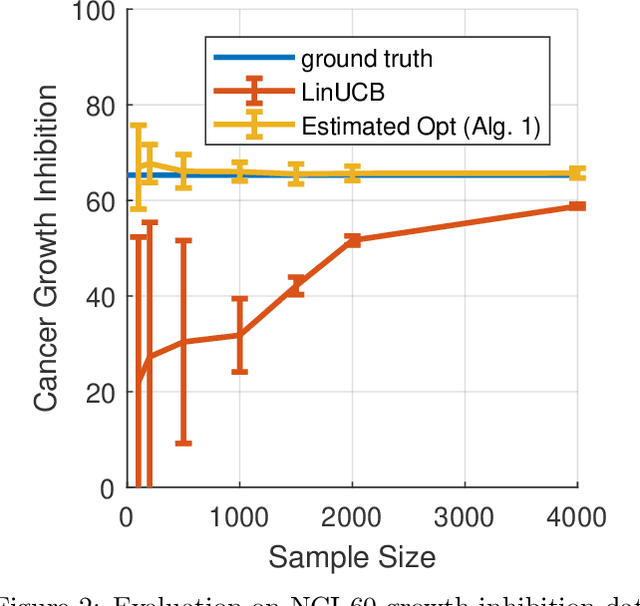
We study the problem of estimating the expected reward of the optimal policy in the stochastic disjoint linear bandit setting. We prove that for certain settings it is possible to obtain an accurate estimate of the optimal policy value even with a number of samples that is sublinear in the number that would be required to \emph{find} a policy that realizes a value close to this optima. We establish nearly matching information theoretic lower bounds, showing that our algorithm achieves near optimal estimation error. Finally, we demonstrate the effectiveness of our algorithm on joke recommendation and cancer inhibition dosage selection problems using real datasets.
Missingness as Stability: Understanding the Structure of Missingness in Longitudinal EHR data and its Impact on Reinforcement Learning in Healthcare
Nov 16, 2019

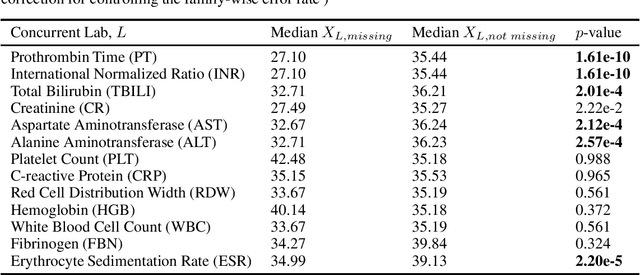
There is an emerging trend in the reinforcement learning for healthcare literature. In order to prepare longitudinal, irregularly sampled, clinical datasets for reinforcement learning algorithms, many researchers will resample the time series data to short, regular intervals and use last-observation-carried-forward (LOCF) imputation to fill in these gaps. Typically, they will not maintain any explicit information about which values were imputed. In this work, we (1) call attention to this practice and discuss its potential implications; (2) propose an alternative representation of the patient state that addresses some of these issues; and (3) demonstrate in a novel but representative clinical dataset that our alternative representation yields consistently better results for achieving optimal control, as measured by off-policy policy evaluation, compared to representations that do not incorporate missingness information.
Being Optimistic to Be Conservative: Quickly Learning a CVaR Policy
Nov 05, 2019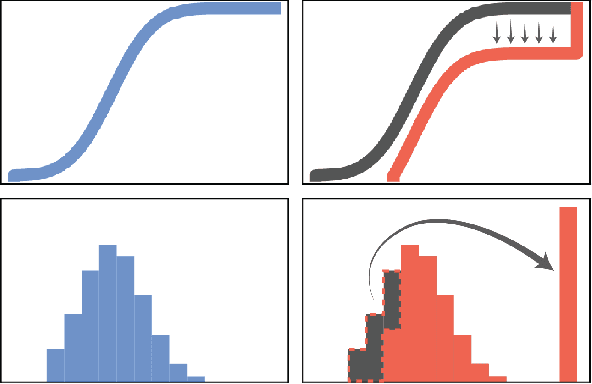
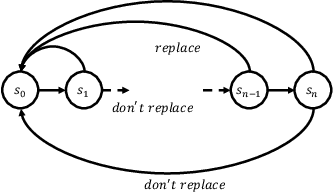
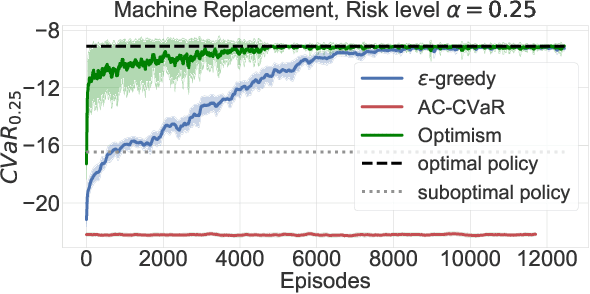
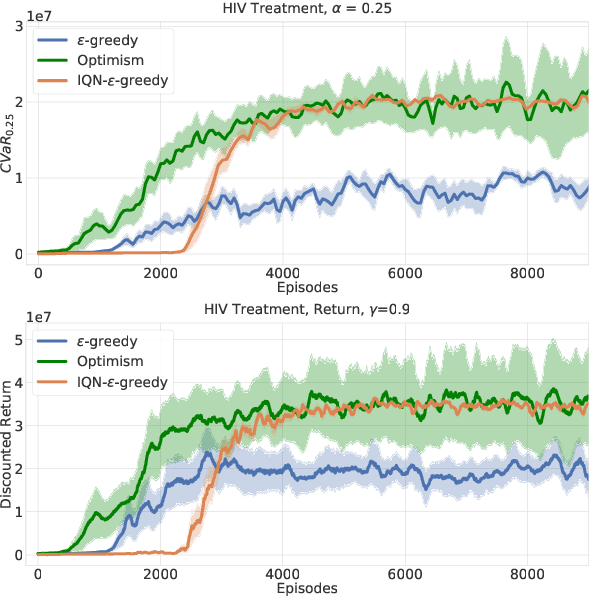
While maximizing expected return is the goal in most reinforcement learning approaches, risk-sensitive objectives such as conditional value at risk (CVaR) are more suitable for many high-stakes applications. However, relatively little is known about how to explore to quickly learn policies with good CVaR. In this paper, we present the first algorithm for sample-efficient learning of CVaR-optimal policies in Markov decision processes based on the optimism in the face of uncertainty principle. This method relies on a novel optimistic version of the distributional Bellman operator that moves probability mass from the lower to the upper tail of the return distribution. We prove asymptotic convergence and optimism of this operator for the tabular policy evaluation case. We further demonstrate that our algorithm finds CVaR-optimal policies substantially faster than existing baselines in several simulated environments with discrete and continuous state spaces.
Problem Dependent Reinforcement Learning Bounds Which Can Identify Bandit Structure in MDPs
Nov 03, 2019In order to make good decision under uncertainty an agent must learn from observations. To do so, two of the most common frameworks are Contextual Bandits and Markov Decision Processes (MDPs). In this paper, we study whether there exist algorithms for the more general framework (MDP) which automatically provide the best performance bounds for the specific problem at hand without user intervention and without modifying the algorithm. In particular, it is found that a very minor variant of a recently proposed reinforcement learning algorithm for MDPs already matches the best possible regret bound $\tilde O (\sqrt{SAT})$ in the dominant term if deployed on a tabular Contextual Bandit problem despite the agent being agnostic to such setting.
Understanding the Curse of Horizon in Off-Policy Evaluation via Conditional Importance Sampling
Oct 15, 2019

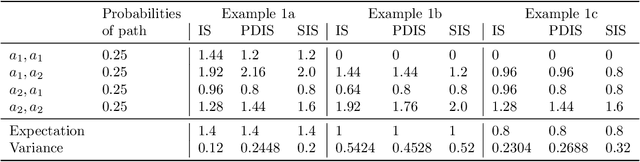
We establish a connection between the importance sampling estimators typically used for off-policy policy evaluation in reinforcement learning and the extended conditional Monte Carlo method. We show with some examples that in the finite horizon case there is no strict ordering in general between the variance of such conditional importance sampling estimators: the variance of the per-decision or stationary variants may, in fact, be higher than that of the crude importance sampling estimator. We also provide sufficient conditions for the finite horizon case under which the per-decision or stationary estimators can reduce the variance. We then develop an asymptotic analysis and derive sufficient conditions under which there exists an exponential v.s. polynomial gap (in terms of horizon $T$) between the variance of importance sampling and that of the per-decision or stationary estimators.
Directed Exploration for Reinforcement Learning
Jun 18, 2019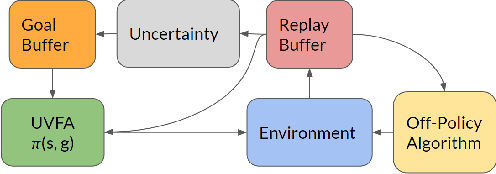
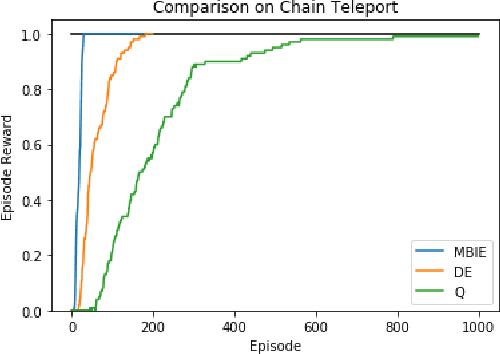
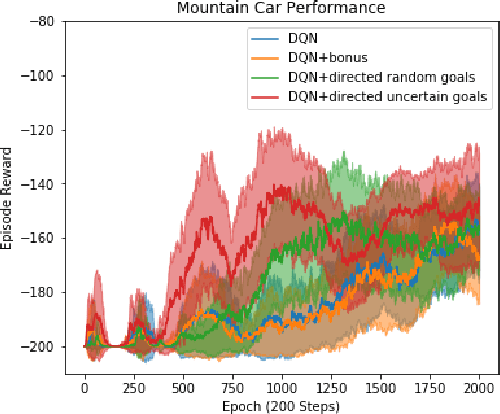
Efficient exploration is necessary to achieve good sample efficiency for reinforcement learning in general. From small, tabular settings such as gridworlds to large, continuous and sparse reward settings such as robotic object manipulation tasks, exploration through adding an uncertainty bonus to the reward function has been shown to be effective when the uncertainty is able to accurately drive exploration towards promising states. However reward bonuses can still be inefficient since they are non-stationary, which means that we must wait for function approximators to catch up and converge again when uncertainties change. We propose the idea of directed exploration, that is learning a goal-conditioned policy where goals are simply other states, and using that to directly try to reach states with large uncertainty. The goal-conditioned policy is independent of uncertainty and is thus stationary. We show in our experiments how directed exploration is more efficient at exploration and more robust to how the uncertainty is computed than adding bonuses to rewards.
Learning When-to-Treat Policies
May 23, 2019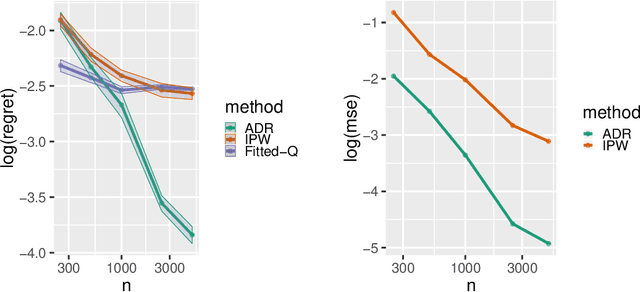
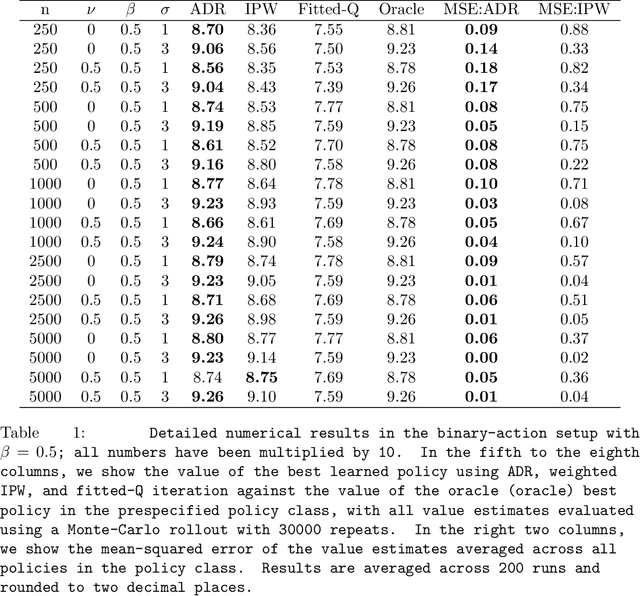
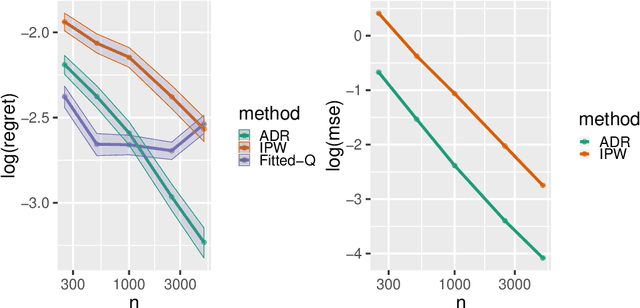
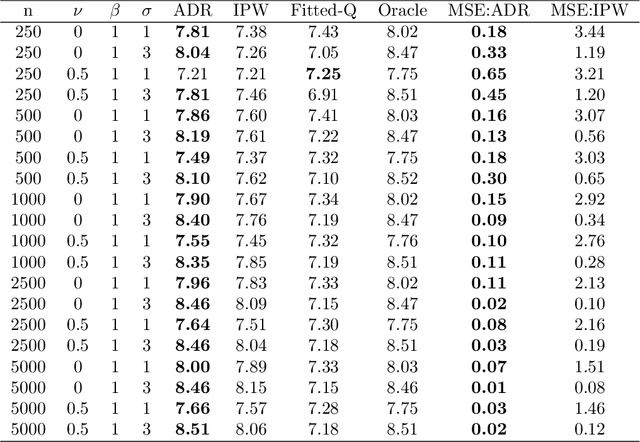
Many applied decision-making problems have a dynamic component: The policymaker needs not only to choose whom to treat, but also when to start which treatment. For example, a medical doctor may see a patient many times and, at each visit, need to choose between prescribing either an invasive or a non-invasive procedure and postponing the decision to the next visit. In this paper, we develop an \say{advantage doubly robust} estimator for learning such dynamic treatment rules using observational data under sequential ignorability. We prove welfare regret bounds that generalize results for doubly robust learning in the single-step setting, and show promising empirical performance in several different contexts. Our approach is practical for policy optimization, and does not need any structural (e.g., Markovian) assumptions.
Combining Parametric and Nonparametric Models for Off-Policy Evaluation
May 16, 2019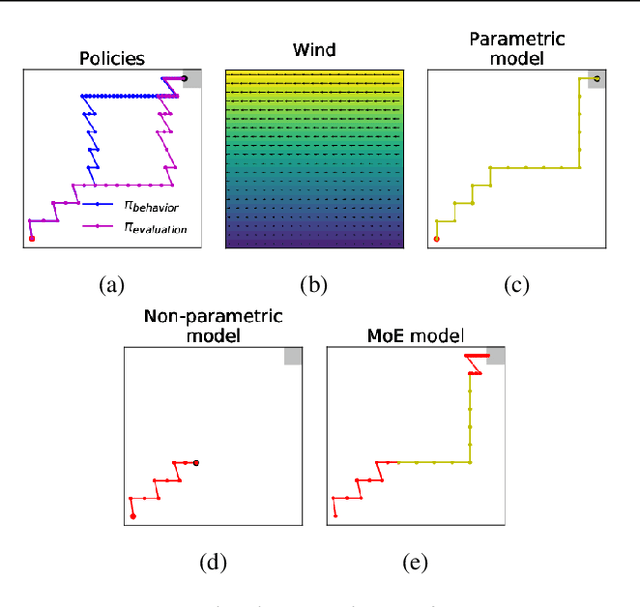

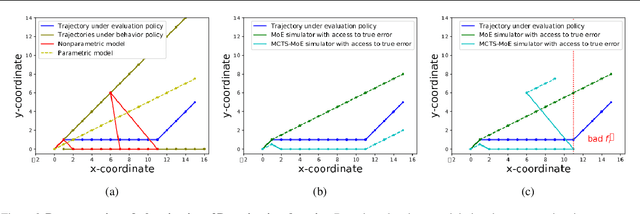

We consider a model-based approach to perform batch off-policy evaluation in reinforcement learning. Our method takes a mixture-of-experts approach to combine parametric and non-parametric models of the environment such that the final value estimate has the least expected error. We do so by first estimating the local accuracy of each model and then using a planner to select which model to use at every time step as to minimize the return error estimate along entire trajectories. Across a variety of domains, our mixture-based approach outperforms the individual models alone as well as state-of-the-art importance sampling-based estimators.
PLOTS: Procedure Learning from Observations using Subtask Structure
Apr 17, 2019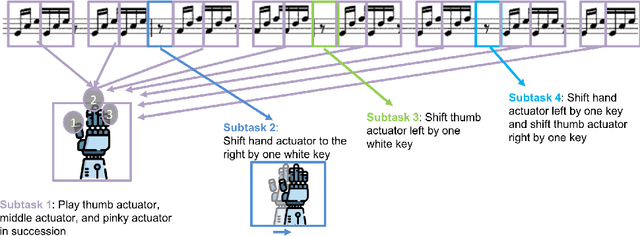
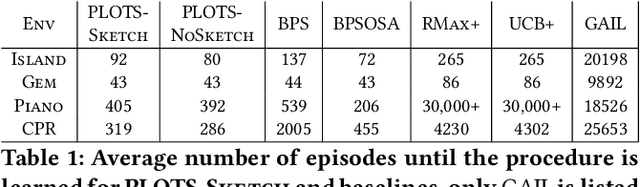
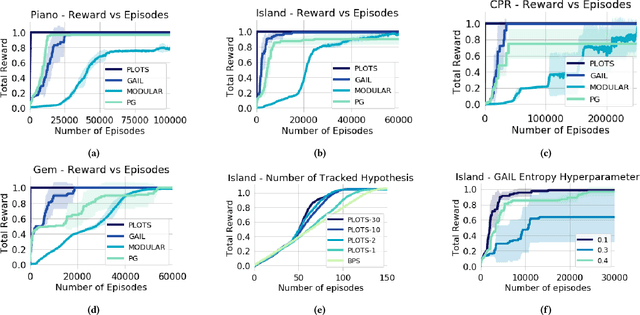
In many cases an intelligent agent may want to learn how to mimic a single observed demonstrated trajectory. In this work we consider how to perform such procedural learning from observation, which could help to enable agents to better use the enormous set of video data on observation sequences. Our approach exploits the properties of this setting to incrementally build an open loop action plan that can yield the desired subsequence, and can be used in both Markov and partially observable Markov domains. In addition, procedures commonly involve repeated extended temporal action subsequences. Our method optimistically explores actions to leverage potential repeated structure in the procedure. In comparing to some state-of-the-art approaches we find that our explicit procedural learning from observation method is about 100 times faster than policy-gradient based approaches that learn a stochastic policy and is faster than model based approaches as well. We also find that performing optimistic action selection yields substantial speed ups when latent dynamical structure is present.
Off-Policy Policy Gradient with State Distribution Correction
Apr 17, 2019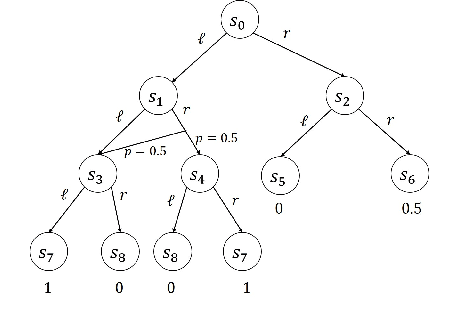
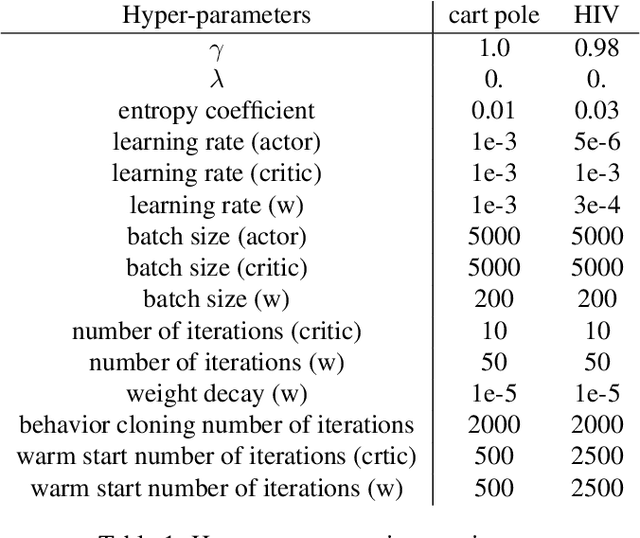
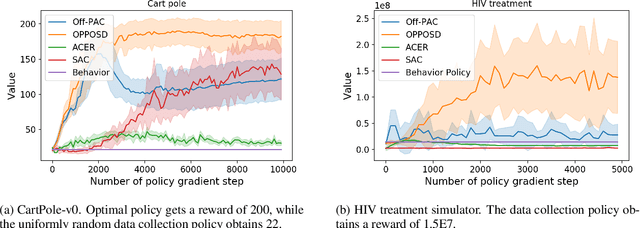
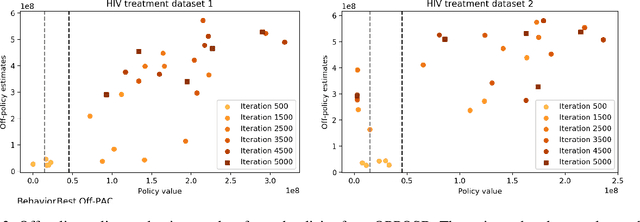
We study the problem of off-policy policy optimization in Markov decision processes, and develop a novel off-policy policy gradient method. Prior off-policy policy gradient approaches have generally ignored the mismatch between the distribution of states visited under the behavior policy used to collect data, and what would be the distribution of states under the learned policy. Here we build on recent progress for estimating the ratio of the Markov chain stationary distribution of states in policy evaluation, and presentan off-policy policy gradient optimization technique that can account for this mismatch in distributions.We present an illustrative example of why this is important, theoretical convergence guarantee for our approach and empirical simulations that highlight the benefits of correcting this distribution mismatch.