 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman Decision Makings on Curriculum Reinforcement Learning with Difficulty Adjustment
Aug 04, 2022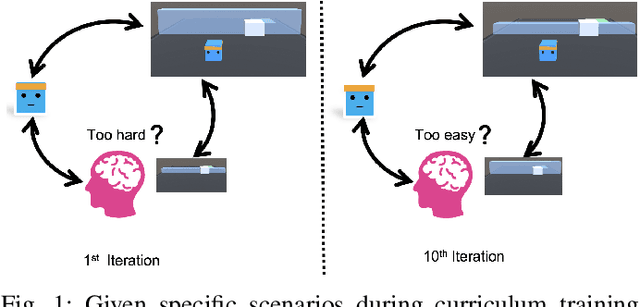
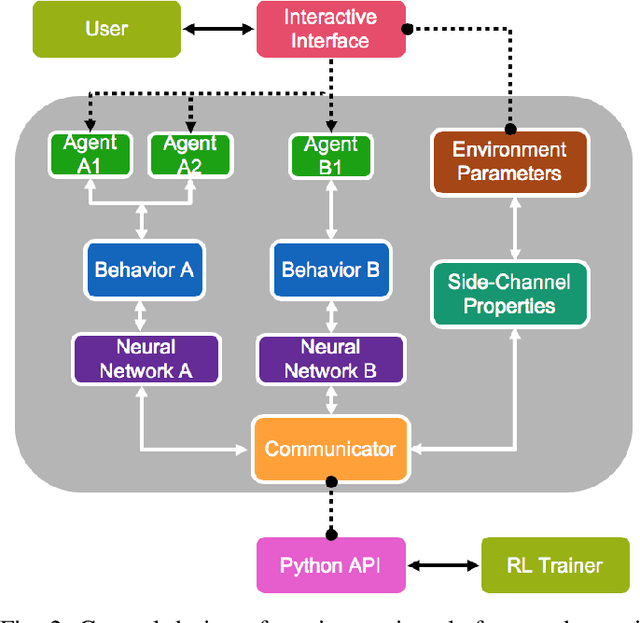
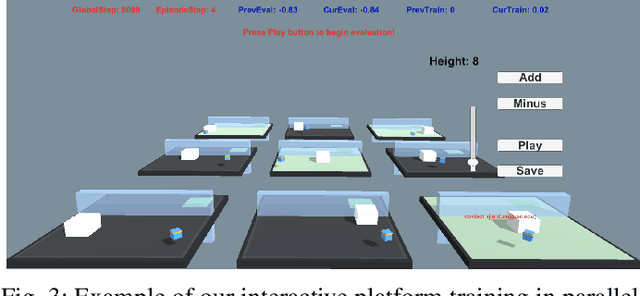
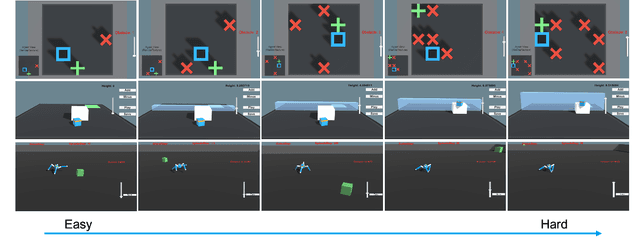
Human-centered AI considers human experiences with AI performance. While abundant research has been helping AI achieve superhuman performance either by fully automatic or weak supervision learning, fewer endeavors are experimenting with how AI can tailor to humans' preferred skill level given fine-grained input. In this work, we guide the curriculum reinforcement learning results towards a preferred performance level that is neither too hard nor too easy via learning from the human decision process. To achieve this, we developed a portable, interactive platform that enables the user to interact with agents online via manipulating the task difficulty, observing performance, and providing curriculum feedback. Our system is highly parallelizable, making it possible for a human to train large-scale reinforcement learning applications that require millions of samples without a server. The result demonstrates the effectiveness of an interactive curriculum for reinforcement learning involving human-in-the-loop. It shows reinforcement learning performance can successfully adjust in sync with the human desired difficulty level. We believe this research will open new doors for achieving flow and personalized adaptive difficulties.
GCN-WP -- Semi-Supervised Graph Convolutional Networks for Win Prediction in Esports
Jul 26, 2022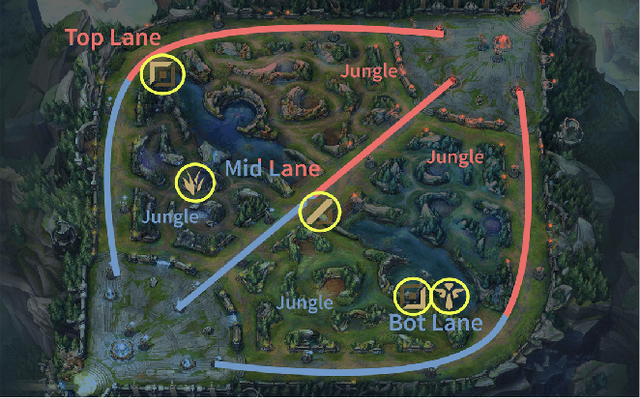
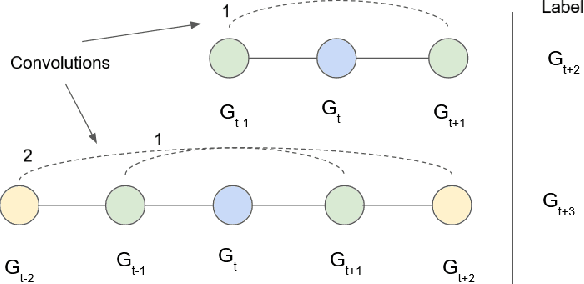
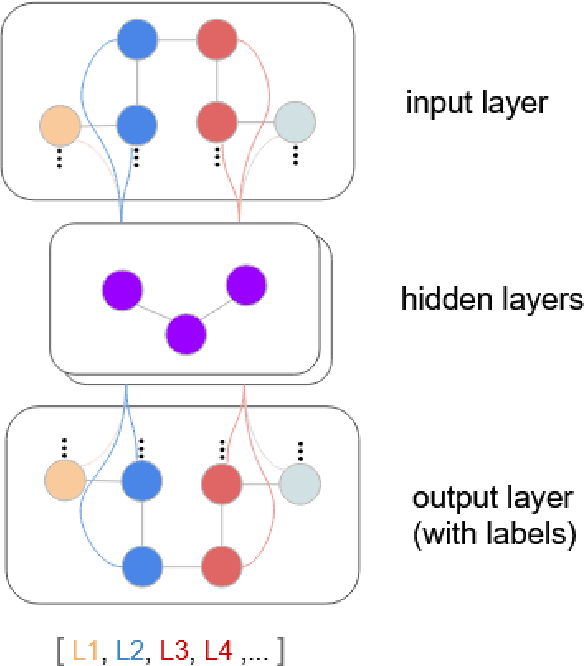
Win prediction is crucial to understanding skill modeling, teamwork and matchmaking in esports. In this paper we propose GCN-WP, a semi-supervised win prediction model for esports based on graph convolutional networks. This model learns the structure of an esports league over the course of a season (1 year) and makes predictions on another similar league. This model integrates over 30 features about the match and players and employs graph convolution to classify games based on their neighborhood. Our model achieves state-of-the-art prediction accuracy when compared to machine learning or skill rating models for LoL. The framework is generalizable so it can easily be extended to other multiplayer online games.
Retweet-BERT: Political Leaning Detection Using Language Features and Information Diffusion on Social Networks
Jul 18, 2022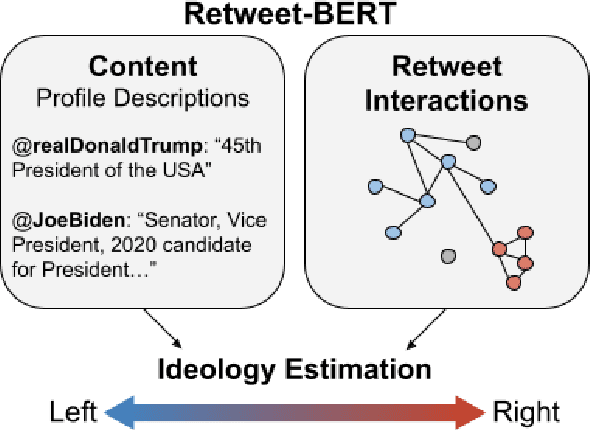
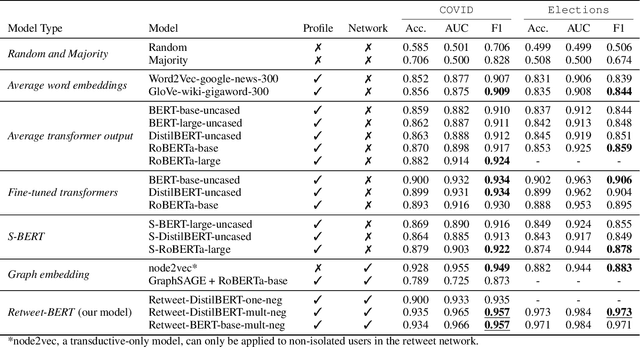
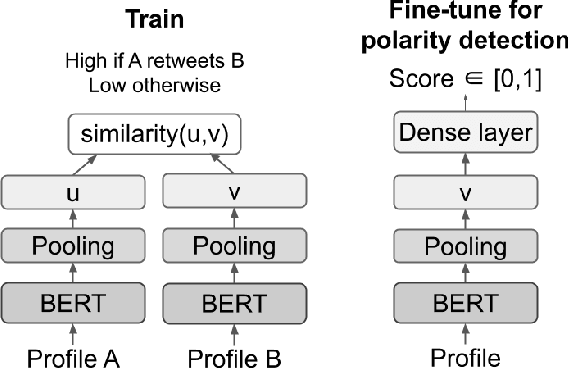

Estimating the political leanings of social media users is a challenging and ever more pressing problem given the increase in social media consumption. We introduce Retweet-BERT, a simple and scalable model to estimate the political leanings of Twitter users. Retweet-BERT leverages the retweet network structure and the language used in users' profile descriptions. Our assumptions stem from patterns of networks and linguistics homophily among people who share similar ideologies. Retweet-BERT demonstrates competitive performance against other state-of-the-art baselines, achieving 96%-97% macro-F1 on two recent Twitter datasets (a COVID-19 dataset and a 2020 United States presidential elections dataset). We also perform manual validation to validate the performance of Retweet-BERT on users not in the training data. Finally, in a case study of COVID-19, we illustrate the presence of political echo chambers on Twitter and show that it exists primarily among right-leaning users. Our code is open-sourced and our data is publicly available.
* 11 pages, 3 figures, 4 tables. arXiv admin note: text overlap with arXiv:2103.10979
Word Embedding for Social Sciences: An Interdisciplinary Survey
Jul 07, 2022
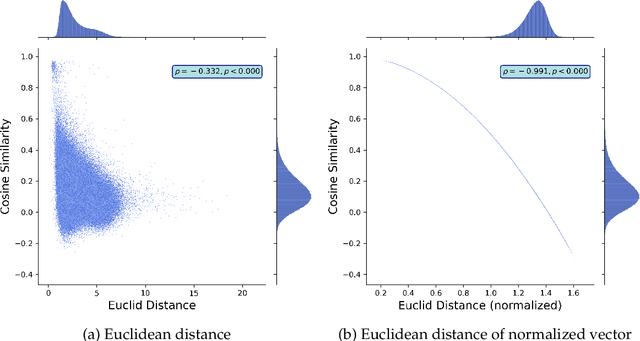
To extract essential information from complex data, computer scientists have been developing machine learning models that learn low-dimensional representation mode. From such advances in machine learning research, not only computer scientists but also social scientists have benefited and advanced their research because human behavior or social phenomena lies in complex data. To document this emerging trend, we survey the recent studies that apply word embedding techniques to human behavior mining, building a taxonomy to illustrate the methods and procedures used in the surveyed papers and highlight the recent emerging trends applying word embedding models to non-textual human behavior data. This survey conducts a simple experiment to warn that common similarity measurements used in the literature could yield different results even if they return consistent results at an aggregate level.
Extracting Fast and Slow: User-Action Embedding with Inter-temporal Information
Jun 20, 2022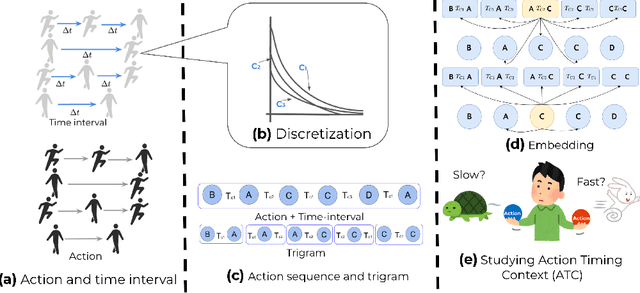
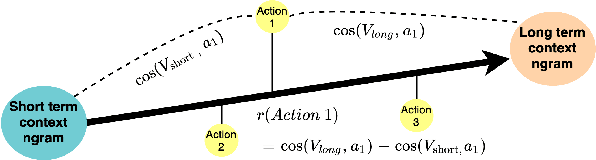
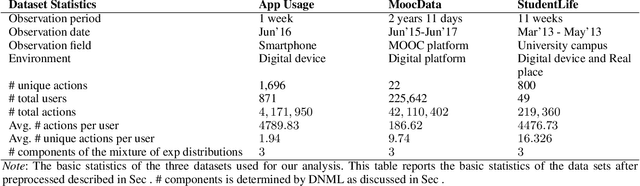

With the recent development of technology, data on detailed human temporal behaviors has become available. Many methods have been proposed to mine those human dynamic behavior data and revealed valuable insights for research and businesses. However, most methods analyze only sequence of actions and do not study the inter-temporal information such as the time intervals between actions in a holistic manner. While actions and action time intervals are interdependent, it is challenging to integrate them because they have different natures: time and action. To overcome this challenge, we propose a unified method that analyzes user actions with intertemporal information (time interval). We simultaneously embed the user's action sequence and its time intervals to obtain a low-dimensional representation of the action along with intertemporal information. The paper demonstrates that the proposed method enables us to characterize user actions in terms of temporal context, using three real-world data sets. This paper demonstrates that explicit modeling of action sequences and inter-temporal user behavior information enable successful interpretable analysis.
Zero-shot meta-learning for small-scale data from human subjects
Mar 29, 2022
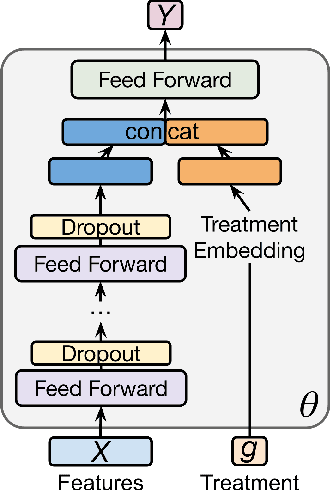
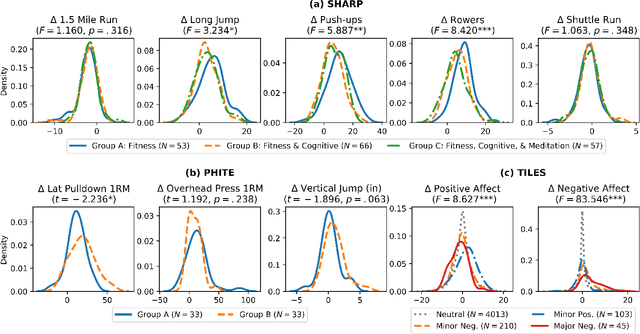
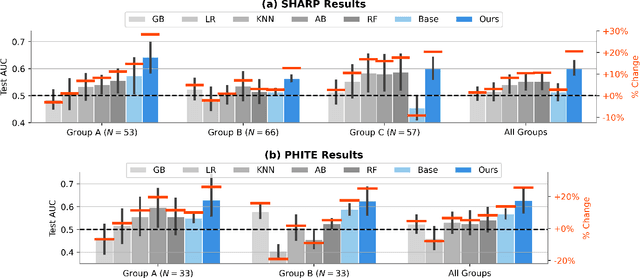
While developments in machine learning led to impressive performance gains on big data, many human subjects data are, in actuality, small and sparsely labeled. Existing methods applied to such data often do not easily generalize to out-of-sample subjects. Instead, models must make predictions on test data that may be drawn from a different distribution, a problem known as \textit{zero-shot learning}. To address this challenge, we develop an end-to-end framework using a meta-learning approach, which enables the model to rapidly adapt to a new prediction task with limited training data for out-of-sample test data. We use three real-world small-scale human subjects datasets (two randomized control studies and one observational study), for which we predict treatment outcomes for held-out treatment groups. Our model learns the latent treatment effects of each intervention and, by design, can naturally handle multi-task predictions. We show that our model performs the best holistically for each held-out group and especially when the test group is distinctly different from the training group. Our model has implications for improved generalization of small-size human studies to the wider population.
Construction of Large-Scale Misinformation Labeled Datasets from Social Media Discourse using Label Refinement
Feb 24, 2022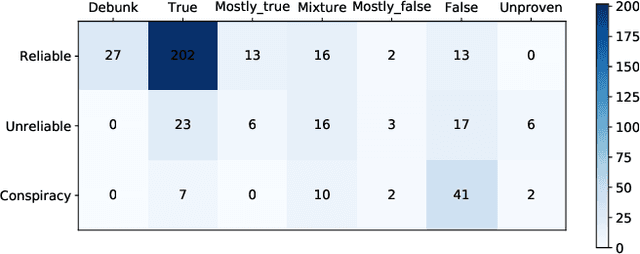

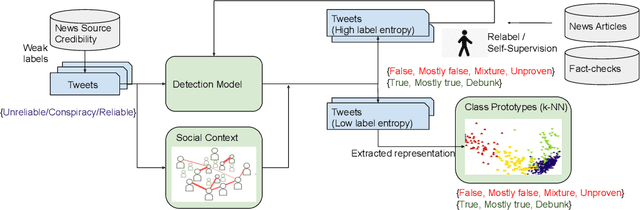

Malicious accounts spreading misinformation has led to widespread false and misleading narratives in recent times, especially during the COVID-19 pandemic, and social media platforms struggle to eliminate these contents rapidly. This is because adapting to new domains requires human intensive fact-checking that is slow and difficult to scale. To address this challenge, we propose to leverage news-source credibility labels as weak labels for social media posts and propose model-guided refinement of labels to construct large-scale, diverse misinformation labeled datasets in new domains. The weak labels can be inaccurate at the article or social media post level where the stance of the user does not align with the news source or article credibility. We propose a framework to use a detection model self-trained on the initial weak labels with uncertainty sampling based on entropy in predictions of the model to identify potentially inaccurate labels and correct for them using self-supervision or relabeling. The framework will incorporate social context of the post in terms of the community of its associated user for surfacing inaccurate labels towards building a large-scale dataset with minimum human effort. To provide labeled datasets with distinction of misleading narratives where information might be missing significant context or has inaccurate ancillary details, the proposed framework will use the few labeled samples as class prototypes to separate high confidence samples into false, unproven, mixture, mostly false, mostly true, true, and debunk information. The approach is demonstrated for providing a large-scale misinformation dataset on COVID-19 vaccines.
Heterogeneous Effects of Software Patches in a Multiplayer Online Battle Arena Game
Oct 27, 2021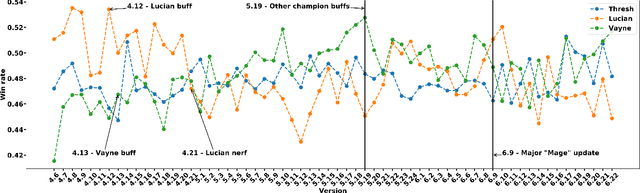
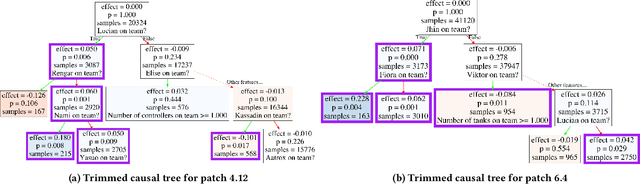

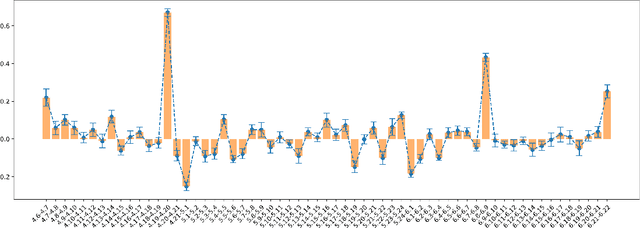
The popularity of online gaming has grown dramatically, driven in part by streaming and the billion-dollar e-sports industry. Online games regularly update their software to fix bugs, add functionality that improve the game's look and feel, and change the game mechanics to keep the games fun and challenging. An open question, however, is the impact of these changes on player performance and game balance, as well as how players adapt to these sudden changes. To address these questions, we use causal inference to measure the impact of software patches to League of Legends, a popular team-based multiplayer online game. We show that game patches have substantially different impacts on players depending on their skill level and whether they take breaks between games. We find that the gap between good and bad players increases after a patch, despite efforts to make gameplay more equal. Moreover, longer between-game breaks tend to improve player performance after patches. Overall, our results highlight the utility of causal inference, and specifically heterogeneous treatment effect estimation, as a tool to quantify the complex mechanisms of game balance and its interplay with players' performance.
* 9 pages, 11 figures
FairFed: Enabling Group Fairness in Federated Learning
Oct 02, 2021
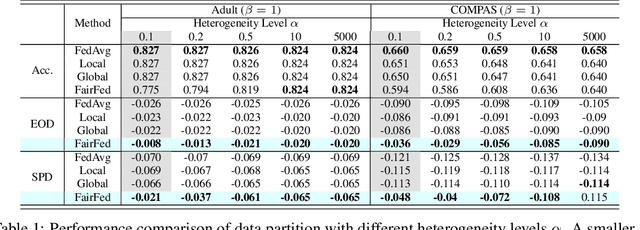
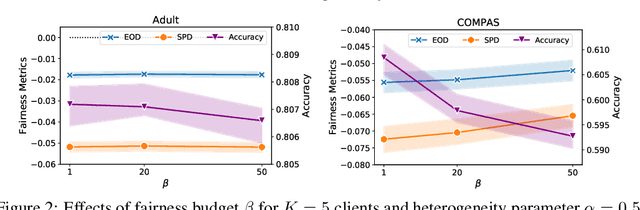
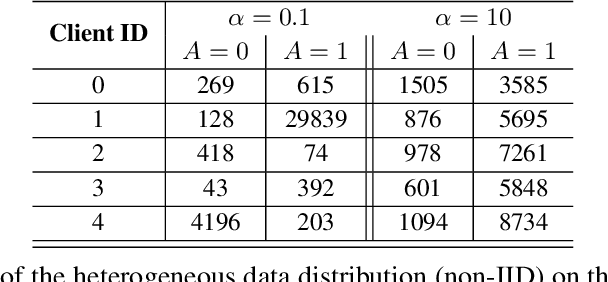
As machine learning becomes increasingly incorporated in crucial decision-making scenarios such as healthcare, recruitment, and loan assessment, there have been increasing concerns about the privacy and fairness of such systems. Federated learning has been viewed as a promising solution for collaboratively learning machine learning models among multiple parties while maintaining the privacy of their local data. However, federated learning also poses new challenges in mitigating the potential bias against certain populations (e.g., demographic groups), which typically requires centralized access to the sensitive information (e.g., race, gender) of each data point. Motivated by the importance and challenges of group fairness in federated learning, in this work, we propose FairFed, a novel algorithm to enhance group fairness via a fairness-aware aggregation method, aiming to provide fair model performance across different sensitive groups (e.g., racial, gender groups) while maintaining high utility. The formulation can potentially provide more flexibility in the customized local debiasing strategies for each client. When running federated training on two widely investigated fairness datasets, Adult and COMPAS, our proposed method outperforms the state-of-the-art fair federated learning frameworks under a high heterogeneous sensitive attribute distribution.
Characterizing Online Engagement with Disinformation and Conspiracies in the 2020 U.S. Presidential Election
Jul 17, 2021


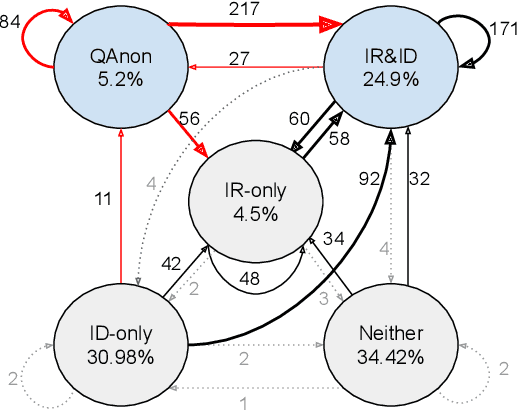
Identifying and characterizing disinformation in political discourse on social media is critical to ensure the integrity of elections and democratic processes around the world. Persistent manipulation of social media has resulted in increased concerns regarding the 2020 U.S. Presidential Election, due to its potential to influence individual opinions and social dynamics. In this work, we focus on the identification of distorted facts, in the form of unreliable and conspiratorial narratives in election-related tweets, to characterize discourse manipulation prior to the election. We apply a detection model to separate factual from unreliable (or conspiratorial) claims analyzing a dataset of 242 million election-related tweets. The identified claims are used to investigate targeted topics of disinformation, and conspiracy groups, most notably the far-right QAnon conspiracy group. Further, we characterize account engagements with unreliable and conspiracy tweets, and with the QAnon conspiracy group, by political leaning and tweet types. Finally, using a regression discontinuity design, we investigate whether Twitter's actions to curb QAnon activity on the platform were effective, and how QAnon accounts adapt to Twitter's restrictions.
* Accepted at ICWSM'22