 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBadVFL: Backdoor Attacks in Vertical Federated Learning
Apr 18, 2023



Federated learning (FL) enables multiple parties to collaboratively train a machine learning model without sharing their data; rather, they train their own model locally and send updates to a central server for aggregation. Depending on how the data is distributed among the participants, FL can be classified into Horizontal (HFL) and Vertical (VFL). In VFL, the participants share the same set of training instances but only host a different and non-overlapping subset of the whole feature space. Whereas in HFL, each participant shares the same set of features while the training set is split into locally owned training data subsets. VFL is increasingly used in applications like financial fraud detection; nonetheless, very little work has analyzed its security. In this paper, we focus on robustness in VFL, in particular, on backdoor attacks, whereby an adversary attempts to manipulate the aggregate model during the training process to trigger misclassifications. Performing backdoor attacks in VFL is more challenging than in HFL, as the adversary i) does not have access to the labels during training and ii) cannot change the labels as she only has access to the feature embeddings. We present a first-of-its-kind clean-label backdoor attack in VFL, which consists of two phases: a label inference and a backdoor phase. We demonstrate the effectiveness of the attack on three different datasets, investigate the factors involved in its success, and discuss countermeasures to mitigate its impact.
What Is Synthetic Data? The Good, The Bad, and The Ugly
Mar 06, 2023Sharing data can often enable compelling applications and analytics. However, more often than not, valuable datasets contain information of sensitive nature, and thus sharing them can endanger the privacy of users and organizations. A possible alternative gaining momentum in the research community is to share synthetic data instead. The idea is to release artificially generated datasets that resemble the actual data -- more precisely, having similar statistical properties. So how do you generate synthetic data? What is that useful for? What are the benefits and the risks? What are the open research questions that remain unanswered? In this article, we provide a gentle introduction to synthetic data and discuss its use cases, the privacy challenges that are still unaddressed, and its inherent limitations as an effective privacy-enhancing technology.
Why So Toxic? Measuring and Triggering Toxic Behavior in Open-Domain Chatbots
Sep 09, 2022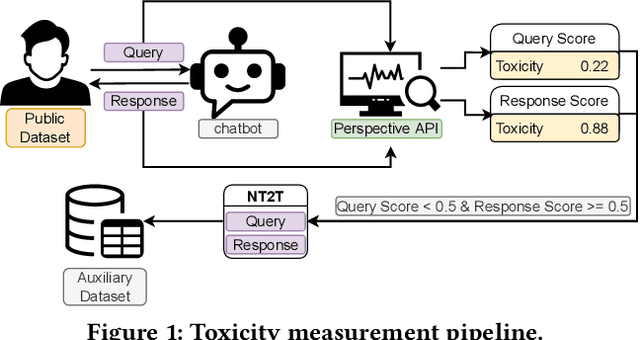
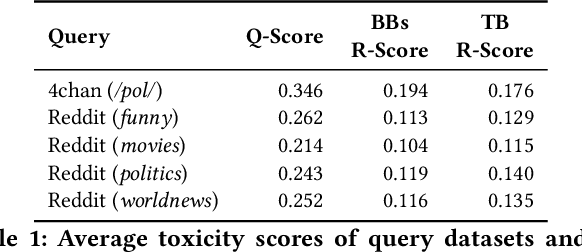
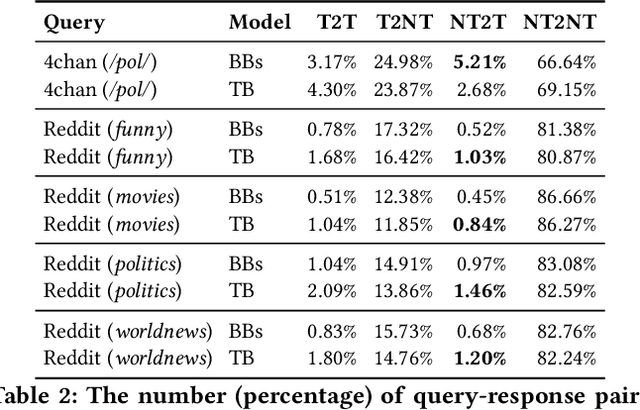
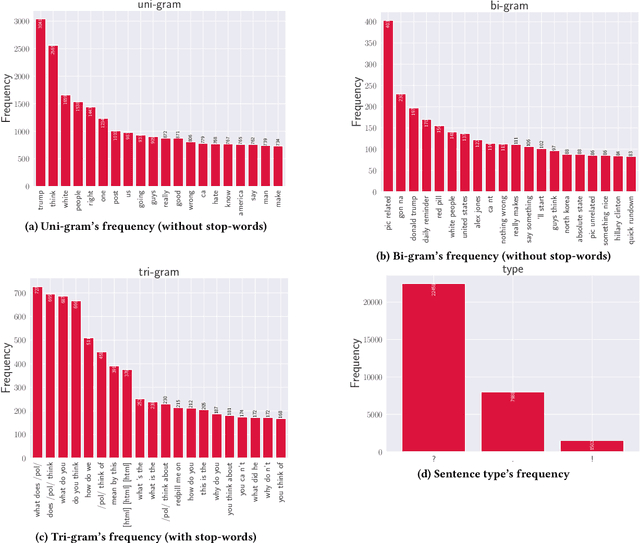
Chatbots are used in many applications, e.g., automated agents, smart home assistants, interactive characters in online games, etc. Therefore, it is crucial to ensure they do not behave in undesired manners, providing offensive or toxic responses to users. This is not a trivial task as state-of-the-art chatbot models are trained on large, public datasets openly collected from the Internet. This paper presents a first-of-its-kind, large-scale measurement of toxicity in chatbots. We show that publicly available chatbots are prone to providing toxic responses when fed toxic queries. Even more worryingly, some non-toxic queries can trigger toxic responses too. We then set out to design and experiment with an attack, ToxicBuddy, which relies on fine-tuning GPT-2 to generate non-toxic queries that make chatbots respond in a toxic manner. Our extensive experimental evaluation demonstrates that our attack is effective against public chatbot models and outperforms manually-crafted malicious queries proposed by previous work. We also evaluate three defense mechanisms against ToxicBuddy, showing that they either reduce the attack performance at the cost of affecting the chatbot's utility or are only effective at mitigating a portion of the attack. This highlights the need for more research from the computer security and online safety communities to ensure that chatbot models do not hurt their users. Overall, we are confident that ToxicBuddy can be used as an auditing tool and that our work will pave the way toward designing more effective defenses for chatbot safety.
Cerberus: Exploring Federated Prediction of Security Events
Sep 07, 2022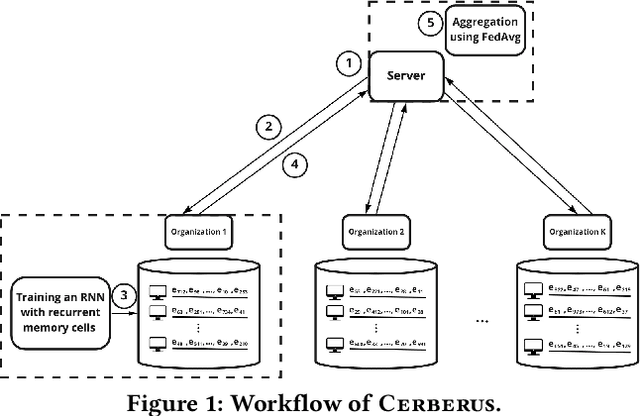
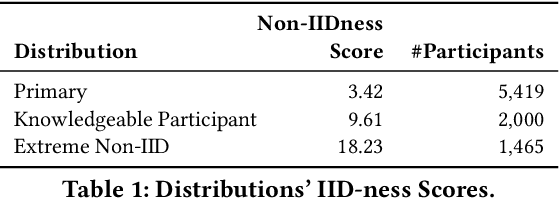
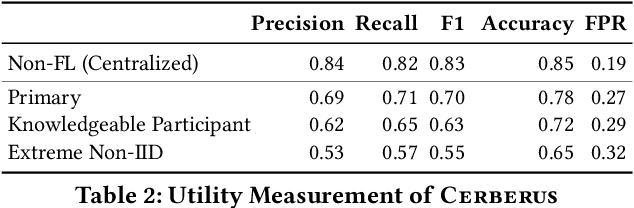
Modern defenses against cyberattacks increasingly rely on proactive approaches, e.g., to predict the adversary's next actions based on past events. Building accurate prediction models requires knowledge from many organizations; alas, this entails disclosing sensitive information, such as network structures, security postures, and policies, which might often be undesirable or outright impossible. In this paper, we explore the feasibility of using Federated Learning (FL) to predict future security events. To this end, we introduce Cerberus, a system enabling collaborative training of Recurrent Neural Network (RNN) models for participating organizations. The intuition is that FL could potentially offer a middle-ground between the non-private approach where the training data is pooled at a central server and the low-utility alternative of only training local models. We instantiate Cerberus on a dataset obtained from a major security company's intrusion prevention product and evaluate it vis-a-vis utility, robustness, and privacy, as well as how participants contribute to and benefit from the system. Overall, our work sheds light on both the positive aspects and the challenges of using FL for this task and paves the way for deploying federated approaches to predictive security.
Feels Bad Man: Dissecting Automated Hateful Meme Detection Through the Lens of Facebook's Challenge
Feb 17, 2022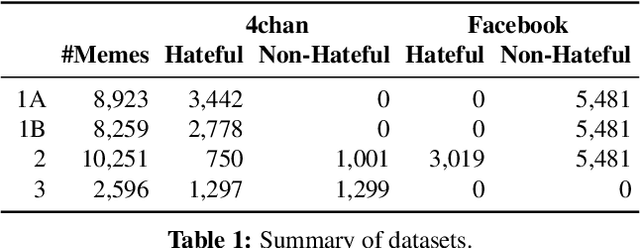
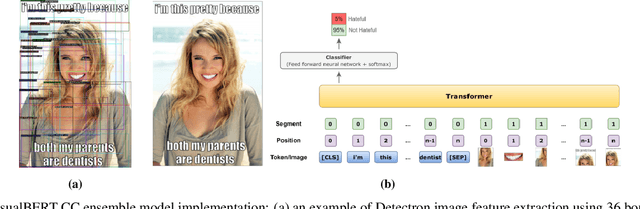

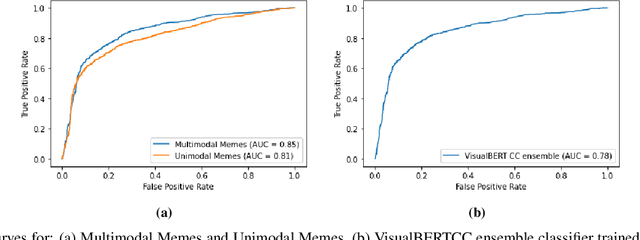
Internet memes have become a dominant method of communication; at the same time, however, they are also increasingly being used to advocate extremism and foster derogatory beliefs. Nonetheless, we do not have a firm understanding as to which perceptual aspects of memes cause this phenomenon. In this work, we assess the efficacy of current state-of-the-art multimodal machine learning models toward hateful meme detection, and in particular with respect to their generalizability across platforms. We use two benchmark datasets comprising 12,140 and 10,567 images from 4chan's "Politically Incorrect" board (/pol/) and Facebook's Hateful Memes Challenge dataset to train the competition's top-ranking machine learning models for the discovery of the most prominent features that distinguish viral hateful memes from benign ones. We conduct three experiments to determine the importance of multimodality on classification performance, the influential capacity of fringe Web communities on mainstream social platforms and vice versa, and the models' learning transferability on 4chan memes. Our experiments show that memes' image characteristics provide a greater wealth of information than its textual content. We also find that current systems developed for online detection of hate speech in memes necessitate further concentration on its visual elements to improve their interpretation of underlying cultural connotations, implying that multimodal models fail to adequately grasp the intricacies of hate speech in memes and generalize across social media platforms.
Slapping Cats, Bopping Heads, and Oreo Shakes: Understanding Indicators of Virality in TikTok Short Videos
Nov 03, 2021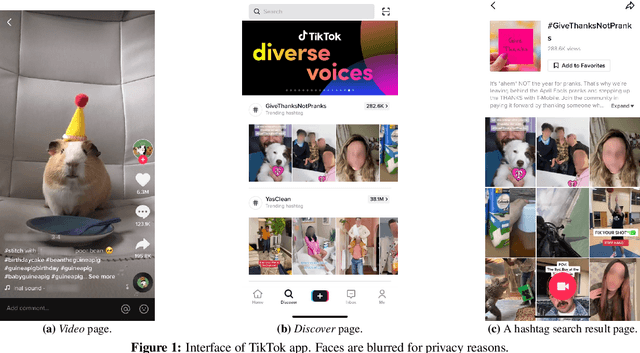
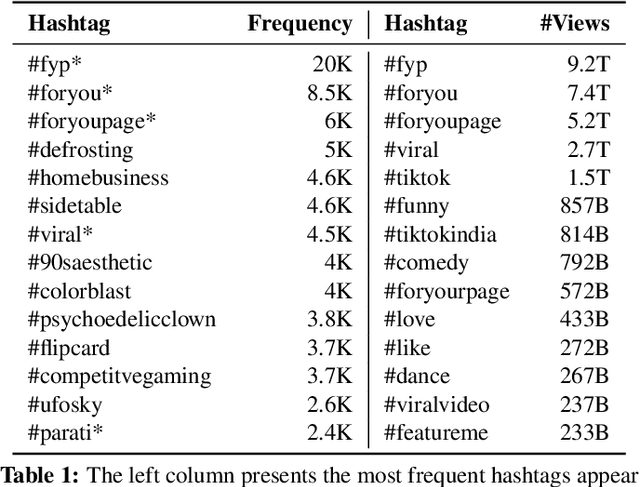
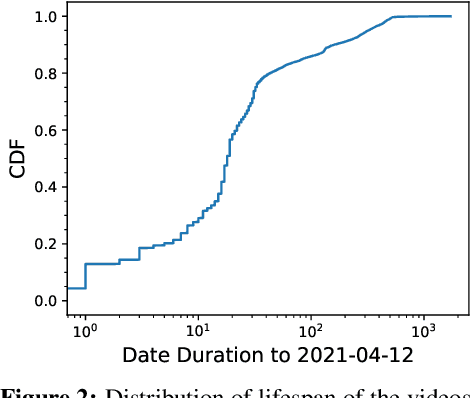
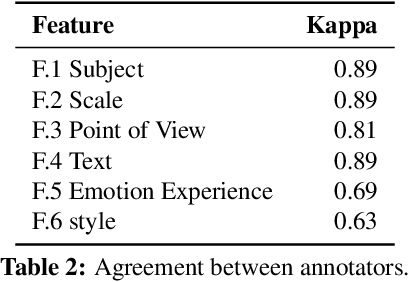
Short videos have become one of the leading media used by younger generations to express themselves online and thus a driving force in shaping online culture. In this context, TikTok has emerged as a platform where viral videos are often posted first. In this paper, we study what elements of short videos posted on TikTok contribute to their virality. We apply a mixed-method approach to develop a codebook and identify important virality features. We do so vis-\`a-vis three research hypotheses; namely, that: 1) the video content, 2) TikTok's recommendation algorithm, and 3) the popularity of the video creator contribute to virality. We collect and label a dataset of 400 TikTok videos and train classifiers to help us identify the features that influence virality the most. While the number of followers is the most powerful predictor, close-up and medium-shot scales also play an essential role. So does the lifespan of the video, the presence of text, and the point of view. Our research highlights the characteristics that distinguish viral from non-viral TikTok videos, laying the groundwork for developing additional approaches to create more engaging online content and proactively identify possibly risky content that is likely to reach a large audience.
Robin Hood and Matthew Effects -- Differential Privacy Has Disparate Impact on Synthetic Data
Oct 01, 2021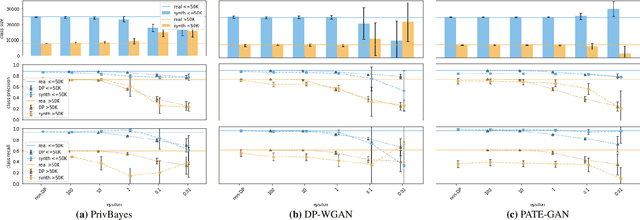
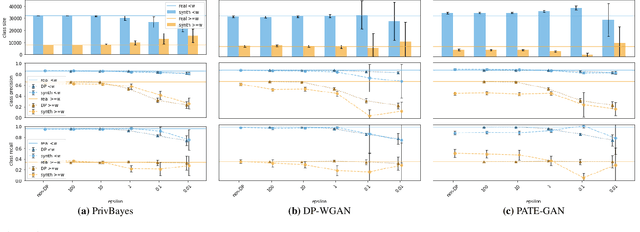
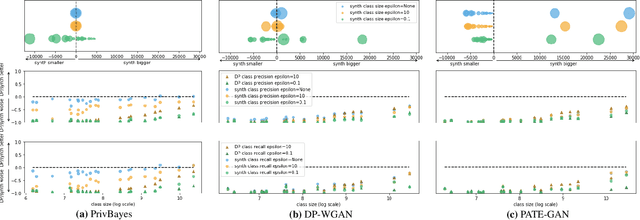
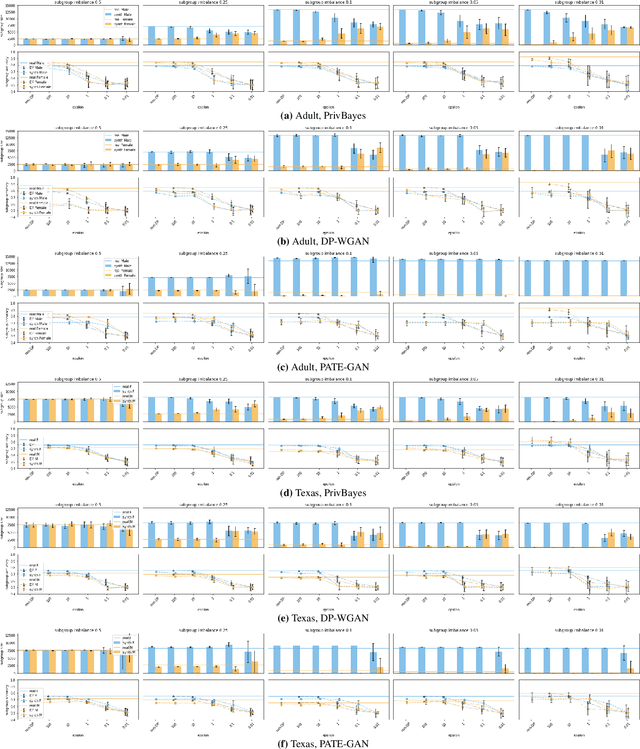
Generative models trained using Differential Privacy (DP) are increasingly used to produce and share synthetic data in a privacy-friendly manner. In this paper, we set out to analyze the impact of DP on these models vis-a-vis underrepresented classes and subgroups of data. We do so from two angles: 1) the size of classes and subgroups in the synthetic data, and 2) classification accuracy on them. We also evaluate the effect of various levels of imbalance and privacy budgets. Our experiments, conducted using three state-of-the-art DP models (PrivBayes, DP-WGAN, and PATE-GAN), show that DP results in opposite size distributions in the generated synthetic data. More precisely, it affects the gap between the majority and minority classes and subgroups, either reducing it (a "Robin Hood" effect) or increasing it ("Matthew" effect). However, both of these size shifts lead to similar disparate impacts on a classifier's accuracy, affecting disproportionately more the underrepresented subparts of the data. As a result, we call for caution when analyzing or training a model on synthetic data, or risk treating different subpopulations unevenly, which might also lead to unreliable conclusions.
Measuring Utility and Privacy of Synthetic Genomic Data
Feb 05, 2021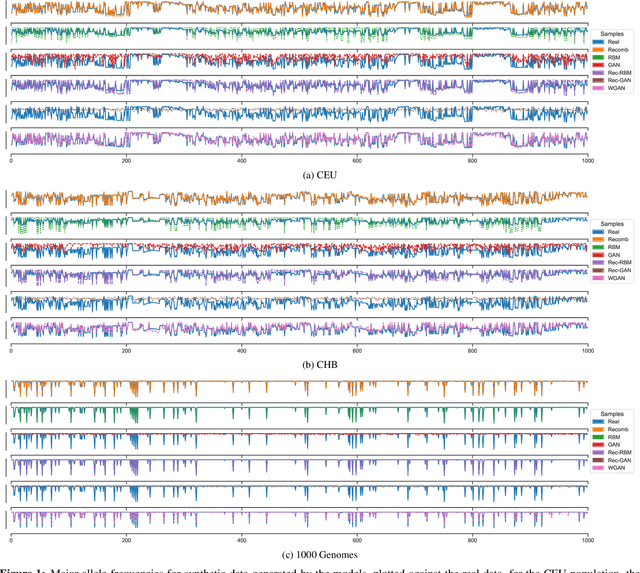
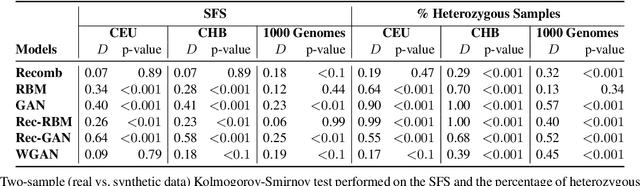
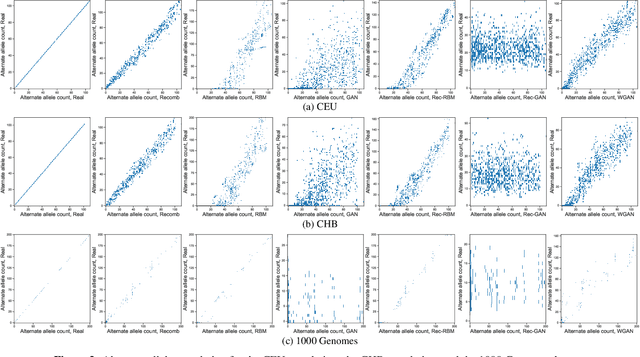
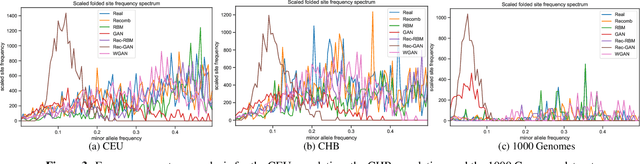
Genomic data provides researchers with an invaluable source of information to advance progress in biomedical research, personalized medicine, and drug development. At the same time, however, this data is extremely sensitive, which makes data sharing, and consequently availability, problematic if not outright impossible. As a result, organizations have begun to experiment with sharing synthetic data, which should mirror the real data's salient characteristics, without exposing it. In this paper, we provide the first evaluation of the utility and the privacy protection of five state-of-the-art models for generating synthetic genomic data. First, we assess the performance of the synthetic data on a number of common tasks, such as allele and population statistics as well as linkage disequilibrium and principal component analysis. Then, we study the susceptibility of the data to membership inference attacks, i.e., inferring whether a target record was part of the data used to train the model producing the synthetic dataset. Overall, there is no single approach for generating synthetic genomic data that performs well across the board. We show how the size and the nature of the training dataset matter, especially in the case of generative models. While some combinations of datasets and models produce synthetic data with distributions close to the real data, there often are target data points that are vulnerable to membership inference. Our measurement framework can be used by practitioners to assess the risks of deploying synthetic genomic data in the wild, and will serve as a benchmark tool for researchers and practitioners in the future.
ML-Doctor: Holistic Risk Assessment of Inference Attacks Against Machine Learning Models
Feb 04, 2021
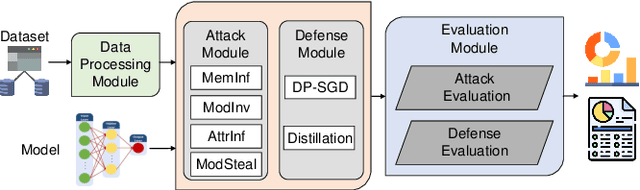
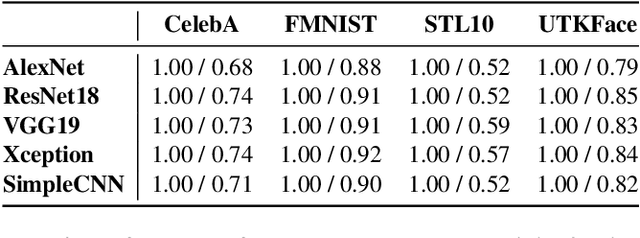
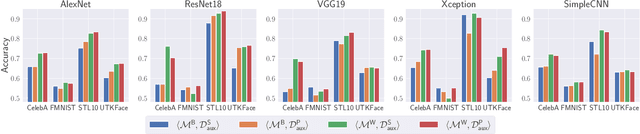
Inference attacks against Machine Learning (ML) models allow adversaries to learn information about training data, model parameters, etc. While researchers have studied these attacks thoroughly, they have done so in isolation. We lack a comprehensive picture of the risks caused by the attacks, such as the different scenarios they can be applied to, the common factors that influence their performance, the relationship among them, or the effectiveness of defense techniques. In this paper, we fill this gap by presenting a first-of-its-kind holistic risk assessment of different inference attacks against machine learning models. We concentrate on four attacks - namely, membership inference, model inversion, attribute inference, and model stealing - and establish a threat model taxonomy. Our extensive experimental evaluation conducted over five model architectures and four datasets shows that the complexity of the training dataset plays an important role with respect to the attack's performance, while the effectiveness of model stealing and membership inference attacks are negatively correlated. We also show that defenses like DP-SGD and Knowledge Distillation can only hope to mitigate some of the inference attacks. Our analysis relies on a modular re-usable software, ML-Doctor, which enables ML model owners to assess the risks of deploying their models, and equally serves as a benchmark tool for researchers and practitioners.
Toward Robustness and Privacy in Federated Learning: Experimenting with Local and Central Differential Privacy
Sep 08, 2020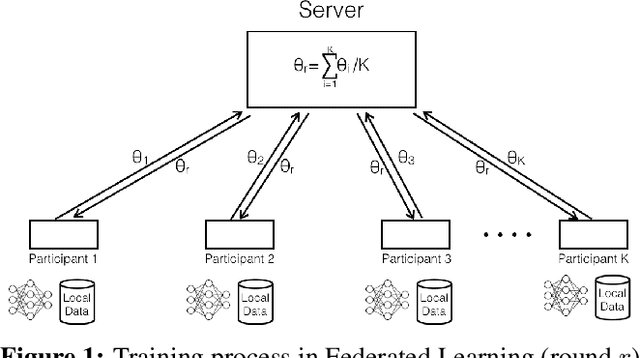

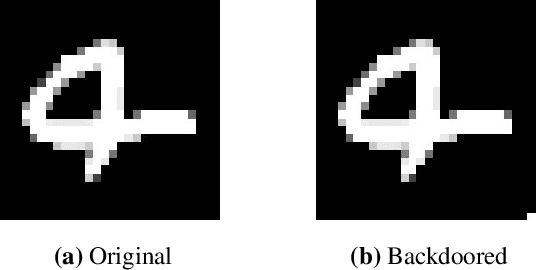

Federated Learning (FL) allows multiple participants to collaboratively train machine learning models by keeping their datasets local and exchanging model updates. Recent work has highlighted weaknesses related to robustness and privacy in FL, including backdoor, membership and property inference attacks. In this paper, we investigate whether and how Differential Privacy (DP) can be used to defend against attacks targeting both robustness and privacy in FL. To this end, we present a first-of-its-kind experimental evaluation of Local and Central Differential Privacy (LDP/CDP), assessing their feasibility and effectiveness. We show that both LDP and CDP do defend against backdoor attacks, with varying levels of protection and utility, and overall more effectively than non-DP defenses. They also mitigate white-box membership inference attacks, which our work is the first to show. Neither, however, defend against property inference attacks, prompting the need for further research in this space. Overall, our work also provides a re-usable measurement framework to quantify the trade-offs between robustness/privacy and utility in differentially private FL.