 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLOGAN: Membership Inference Attacks Against Generative Models
Aug 21, 2018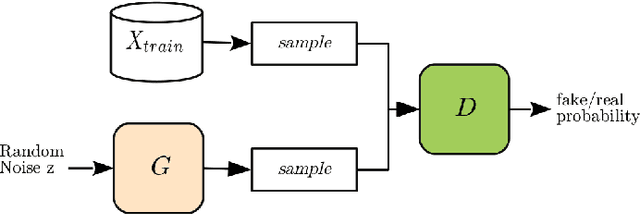
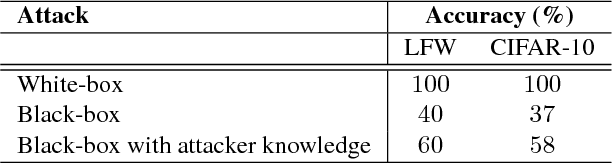
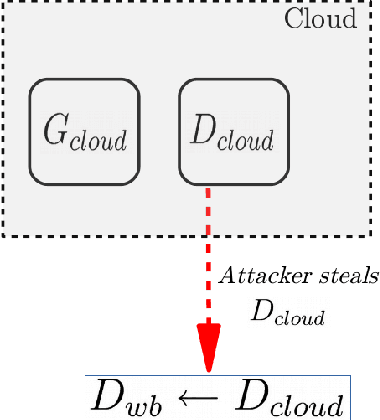
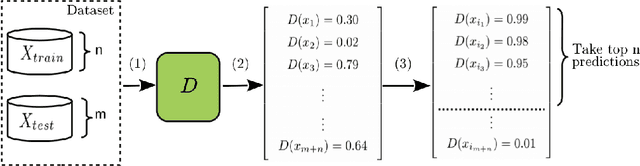
Generative models estimate the underlying distribution of a dataset to generate realistic samples according to that distribution. In this paper, we present the first membership inference attacks against generative models: given a data point, the adversary determines whether or not it was used to train the model. Our attacks leverage Generative Adversarial Networks (GANs), which combine a discriminative and a generative model, to detect overfitting and recognize inputs that were part of training datasets, using the discriminator's capacity to learn statistical differences in distributions. We present attacks based on both white-box and black-box access to the target model, against several state-of-the-art generative models, over datasets of complex representations of faces (LFW), objects (CIFAR-10), and medical images (Diabetic Retinopathy). We also discuss the sensitivity of the attacks to different training parameters, and their robustness against mitigation strategies, finding that defenses are either ineffective or lead to significantly worse performances of the generative models in terms of training stability and/or sample quality.
Learning Universal Adversarial Perturbations with Generative Models
Jan 05, 2018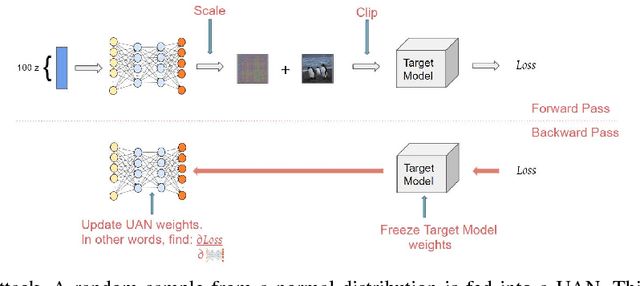
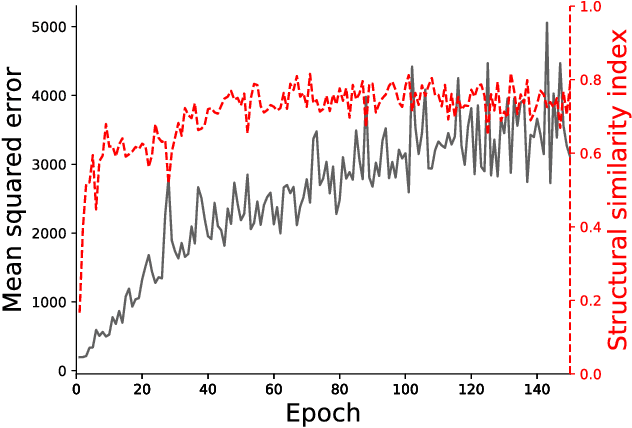


Neural networks are known to be vulnerable to adversarial examples, inputs that have been intentionally perturbed to remain visually similar to the source input, but cause a misclassification. It was recently shown that given a dataset and classifier, there exists so called universal adversarial perturbations, a single perturbation that causes a misclassification when applied to any input. In this work, we introduce universal adversarial networks, a generative network that is capable of fooling a target classifier when it's generated output is added to a clean sample from a dataset. We show that this technique improves on known universal adversarial attacks.
Generating Steganographic Images via Adversarial Training
Jul 24, 2017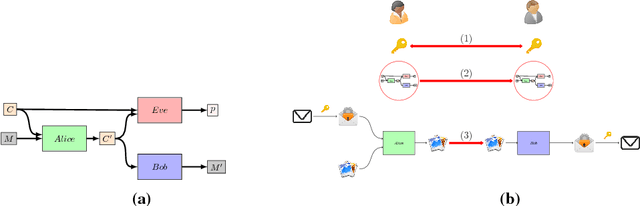
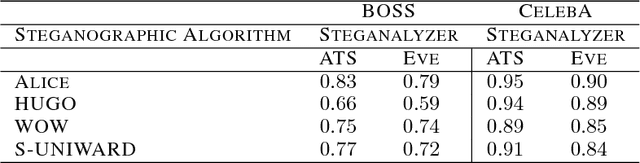

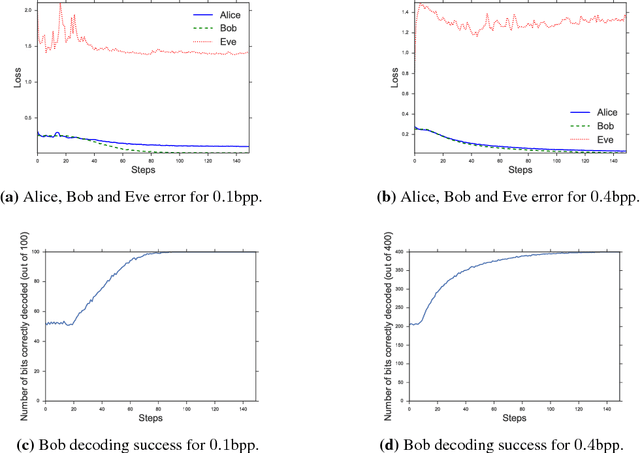
Adversarial training was recently shown to be competitive against supervised learning methods on computer vision tasks, however, studies have mainly been confined to generative tasks such as image synthesis. In this paper, we apply adversarial training techniques to the discriminative task of learning a steganographic algorithm. Steganography is a collection of techniques for concealing information by embedding it within a non-secret medium, such as cover texts or images. We show that adversarial training can produce robust steganographic techniques: our unsupervised training scheme produces a steganographic algorithm that competes with state-of-the-art steganographic techniques, and produces a robust steganalyzer, which performs the discriminative task of deciding if an image contains secret information. We define a game between three parties, Alice, Bob and Eve, in order to simultaneously train both a steganographic algorithm and a steganalyzer. Alice and Bob attempt to communicate a secret message contained within an image, while Eve eavesdrops on their conversation and attempts to determine if secret information is embedded within the image. We represent Alice, Bob and Eve by neural networks, and validate our scheme on two independent image datasets, showing our novel method of studying steganographic problems is surprisingly competitive against established steganographic techniques.