 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContextualization of Morphological Inflection
May 04, 2019
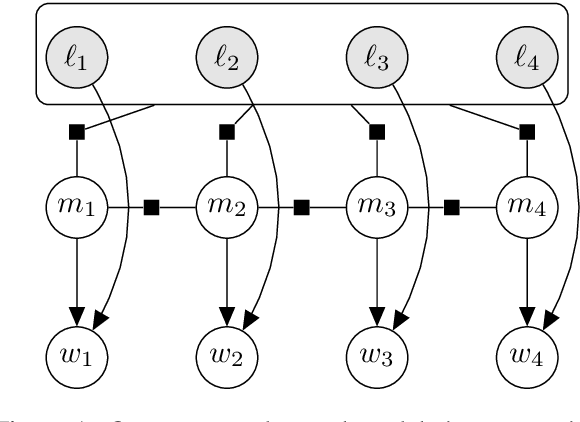
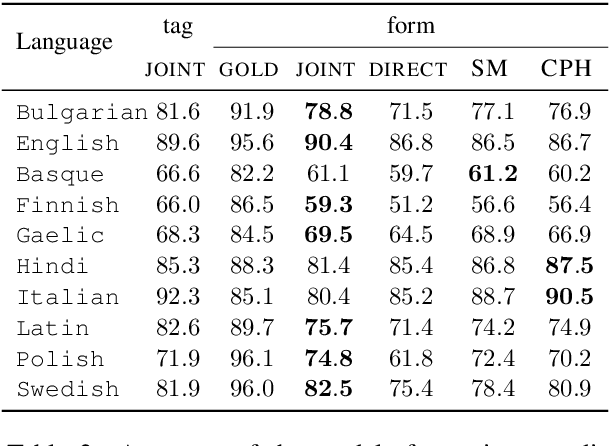
Critical to natural language generation is the production of correctly inflected text. In this paper, we isolate the task of predicting a fully inflected sentence from its partially lemmatized version. Unlike traditional morphological inflection or surface realization, our task input does not provide ``gold'' tags that specify what morphological features to realize on each lemmatized word; rather, such features must be inferred from sentential context. We develop a neural hybrid graphical model that explicitly reconstructs morphological features before predicting the inflected forms, and compare this to a system that directly predicts the inflected forms without relying on any morphological annotation. We experiment on several typologically diverse languages from the Universal Dependencies treebanks, showing the utility of incorporating linguistically-motivated latent variables into NLP models.
UniMorph 2.0: Universal Morphology
Oct 25, 2018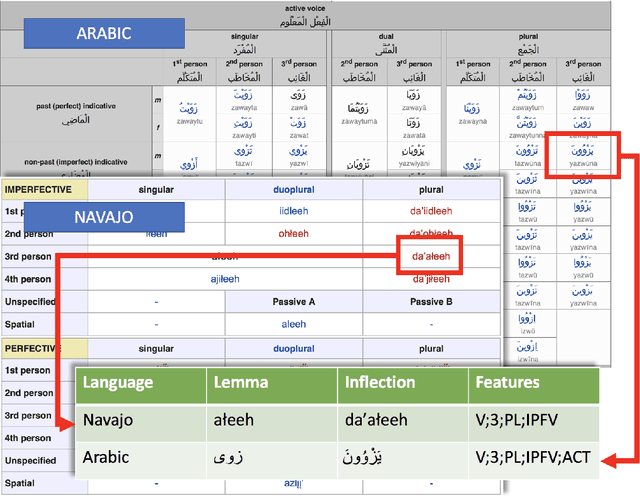
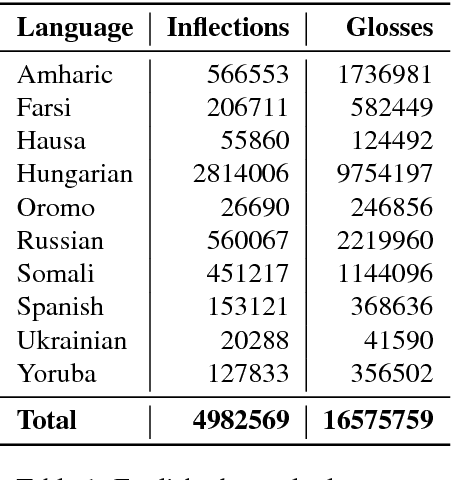

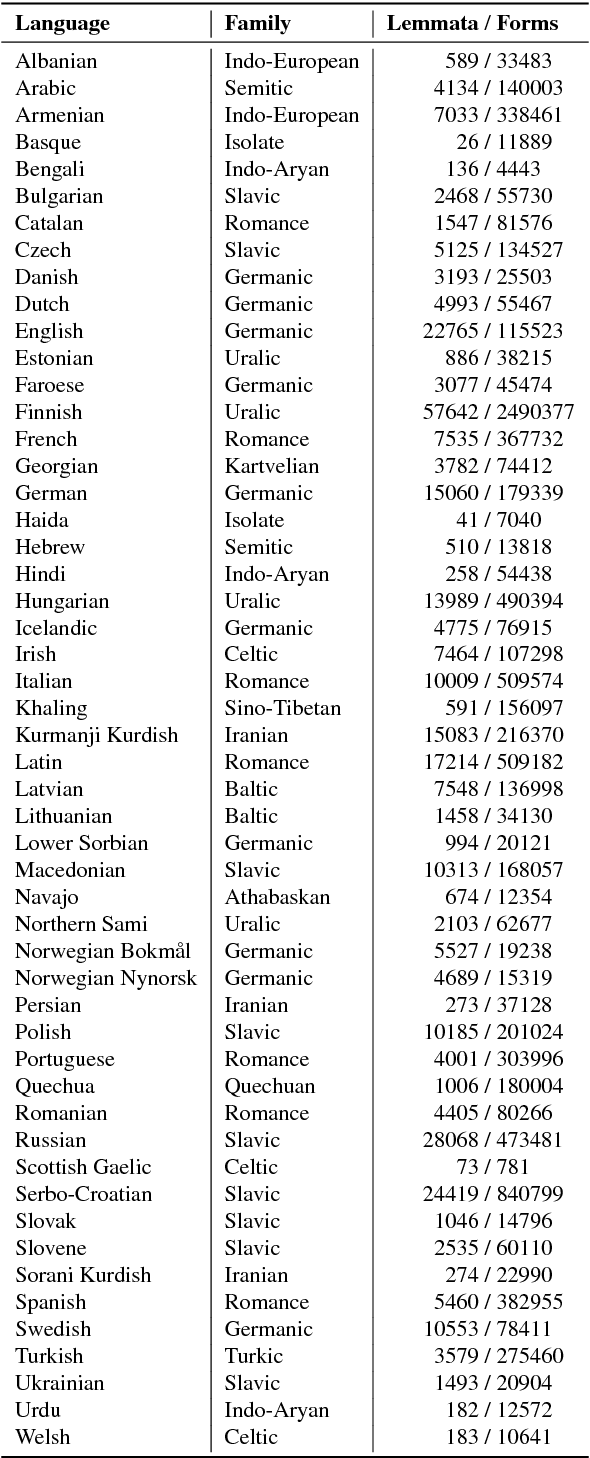
The Universal Morphology UniMorph project is a collaborative effort to improve how NLP handles complex morphology across the world's languages. The project releases annotated morphological data using a universal tagset, the UniMorph schema. Each inflected form is associated with a lemma, which typically carries its underlying lexical meaning, and a bundle of morphological features from our schema. Additional supporting data and tools are also released on a per-language basis when available. UniMorph is based at the Center for Language and Speech Processing (CLSP) at Johns Hopkins University in Baltimore, Maryland and is sponsored by the DARPA LORELEI program. This paper details advances made to the collection, annotation, and dissemination of project resources since the initial UniMorph release described at LREC 2016. lexical resources} }
The CoNLL--SIGMORPHON 2018 Shared Task: Universal Morphological Reinflection
Oct 18, 2018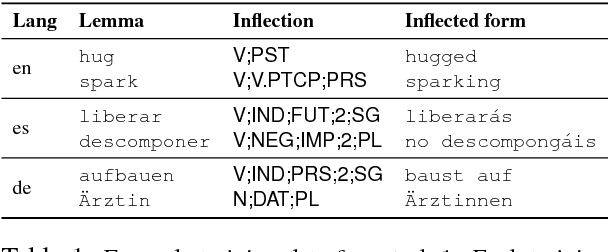
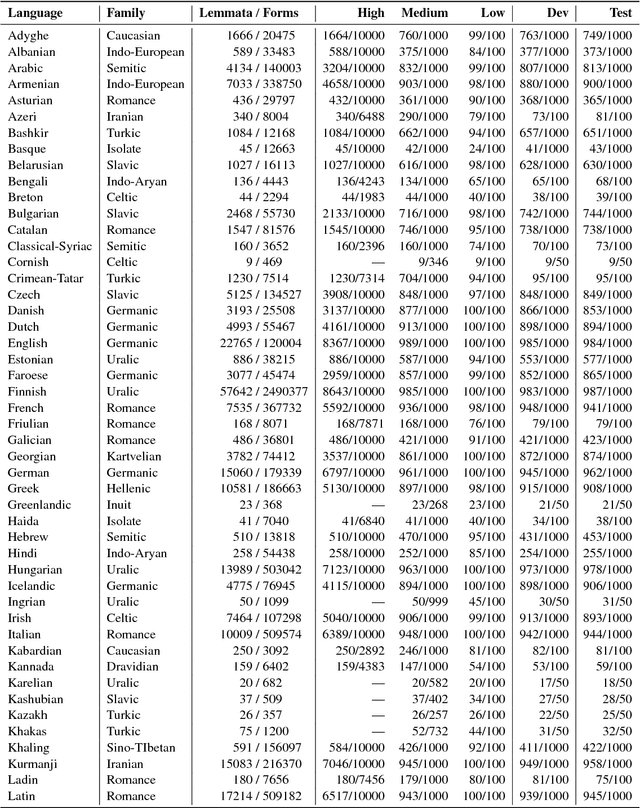
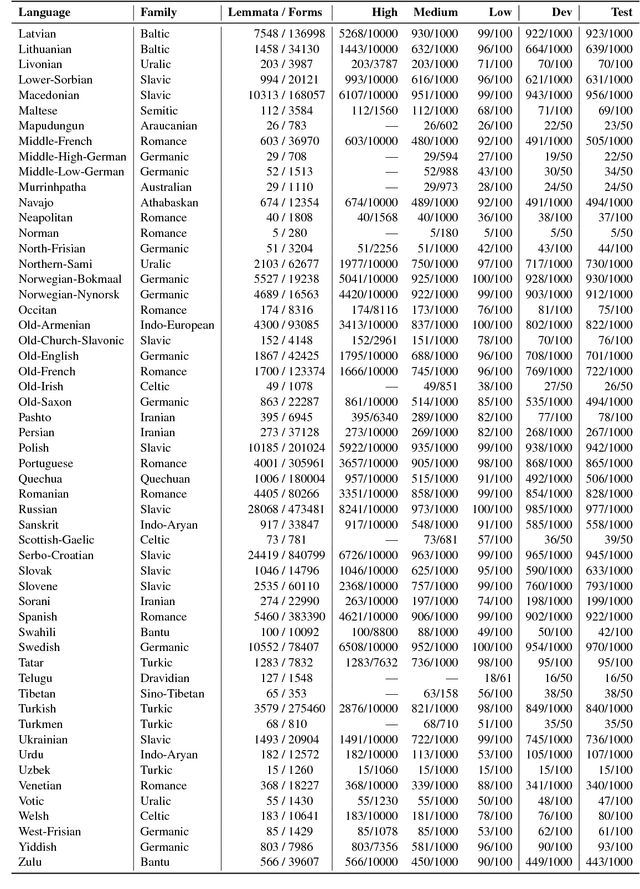

The CoNLL--SIGMORPHON 2018 shared task on supervised learning of morphological generation featured data sets from 103 typologically diverse languages. Apart from extending the number of languages involved in earlier supervised tasks of generating inflected forms, this year the shared task also featured a new second task which asked participants to inflect words in sentential context, similar to a cloze task. This second task featured seven languages. Task 1 received 27 submissions and task 2 received 6 submissions. Both tasks featured a low, medium, and high data condition. Nearly all submissions featured a neural component and built on highly-ranked systems from the earlier 2017 shared task. In the inflection task (task 1), 41 of the 52 languages present in last year's inflection task showed improvement by the best systems in the low-resource setting. The cloze task (task 2) proved to be difficult, and few submissions managed to consistently improve upon both a simple neural baseline system and a lemma-repeating baseline.
Classifying Idiomatic and Literal Expressions Using Topic Models and Intensity of Emotions
Feb 27, 2018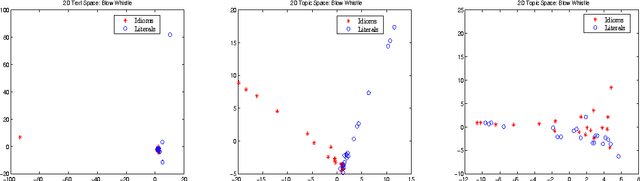
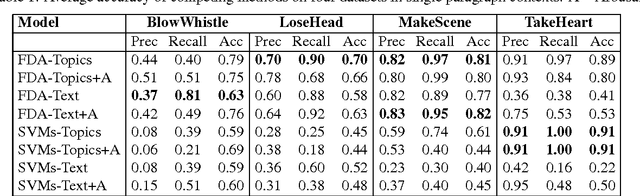
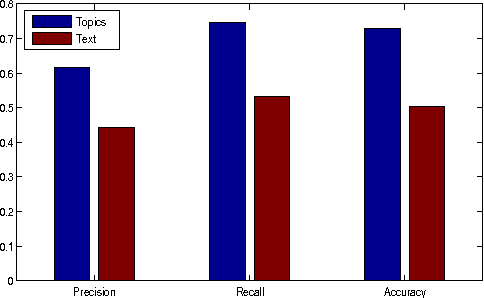
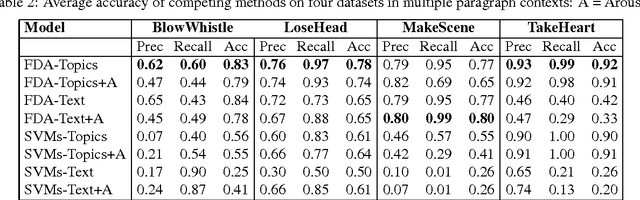
We describe an algorithm for automatic classification of idiomatic and literal expressions. Our starting point is that words in a given text segment, such as a paragraph, that are highranking representatives of a common topic of discussion are less likely to be a part of an idiomatic expression. Our additional hypothesis is that contexts in which idioms occur, typically, are more affective and therefore, we incorporate a simple analysis of the intensity of the emotions expressed by the contexts. We investigate the bag of words topic representation of one to three paragraphs containing an expression that should be classified as idiomatic or literal (a target phrase). We extract topics from paragraphs containing idioms and from paragraphs containing literals using an unsupervised clustering method, Latent Dirichlet Allocation (LDA) (Blei et al., 2003). Since idiomatic expressions exhibit the property of non-compositionality, we assume that they usually present different semantics than the words used in the local topic. We treat idioms as semantic outliers, and the identification of a semantic shift as outlier detection. Thus, this topic representation allows us to differentiate idioms from literals using local semantic contexts. Our results are encouraging.
Paradigm Completion for Derivational Morphology
Aug 30, 2017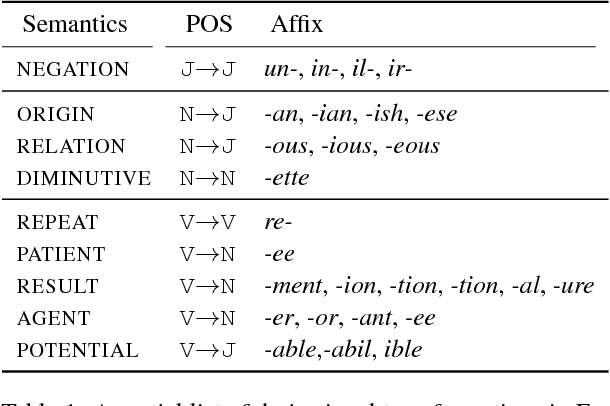
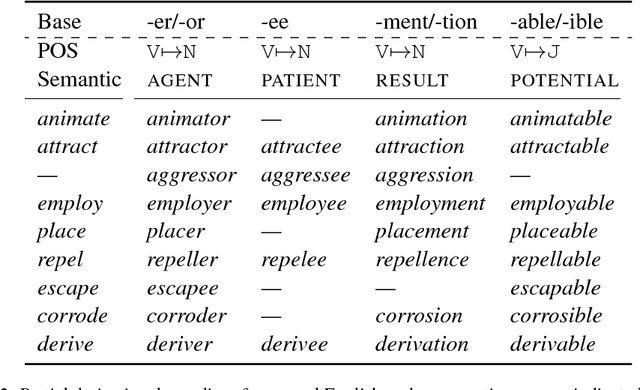
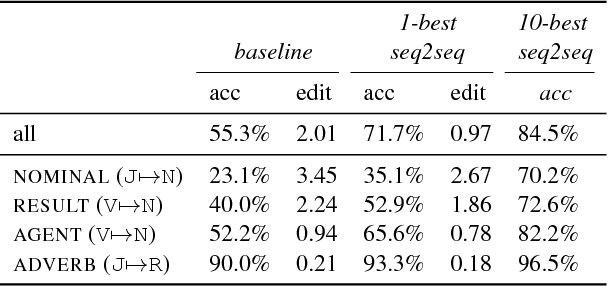
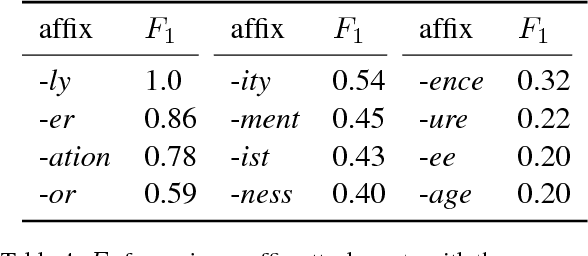
The generation of complex derived word forms has been an overlooked problem in NLP; we fill this gap by applying neural sequence-to-sequence models to the task. We overview the theoretical motivation for a paradigmatic treatment of derivational morphology, and introduce the task of derivational paradigm completion as a parallel to inflectional paradigm completion. State-of-the-art neural models, adapted from the inflection task, are able to learn a range of derivation patterns, and outperform a non-neural baseline by 16.4%. However, due to semantic, historical, and lexical considerations involved in derivational morphology, future work will be needed to achieve performance parity with inflection-generating systems.
Men Are from Mars, Women Are from Venus: Evaluation and Modelling of Verbal Associations
Jul 26, 2017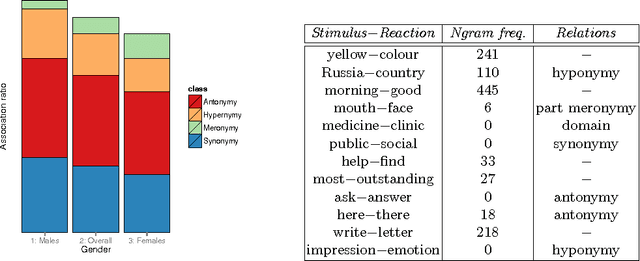
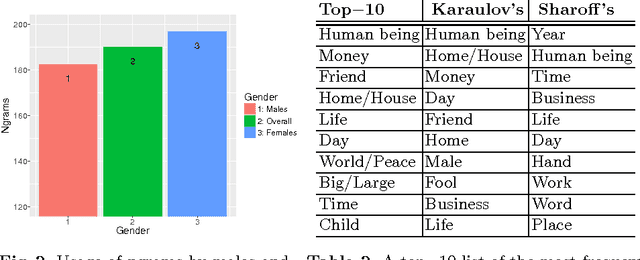
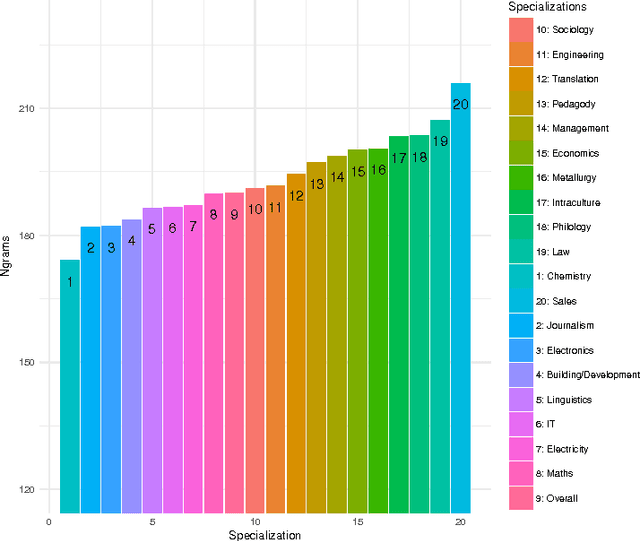
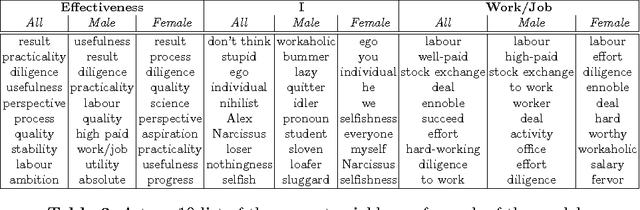
We present a quantitative analysis of human word association pairs and study the types of relations presented in the associations. We put our main focus on the correlation between response types and respondent characteristics such as occupation and gender by contrasting syntagmatic and paradigmatic associations. Finally, we propose a personalised distributed word association model and show the importance of incorporating demographic factors into the models commonly used in natural language processing.
CoNLL-SIGMORPHON 2017 Shared Task: Universal Morphological Reinflection in 52 Languages
Jul 04, 2017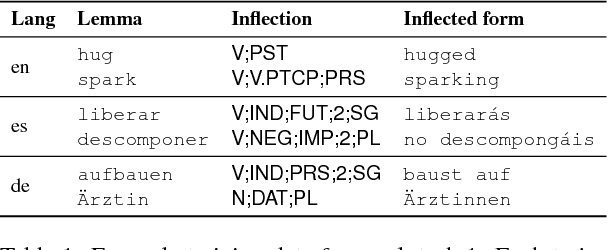
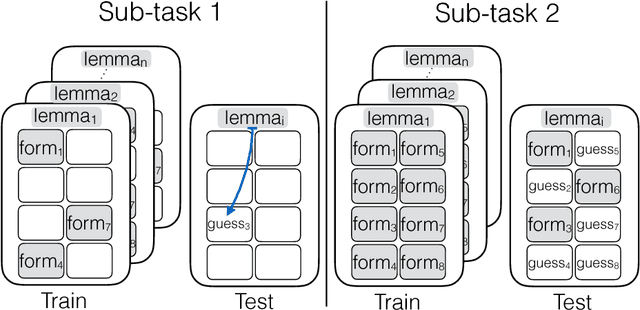
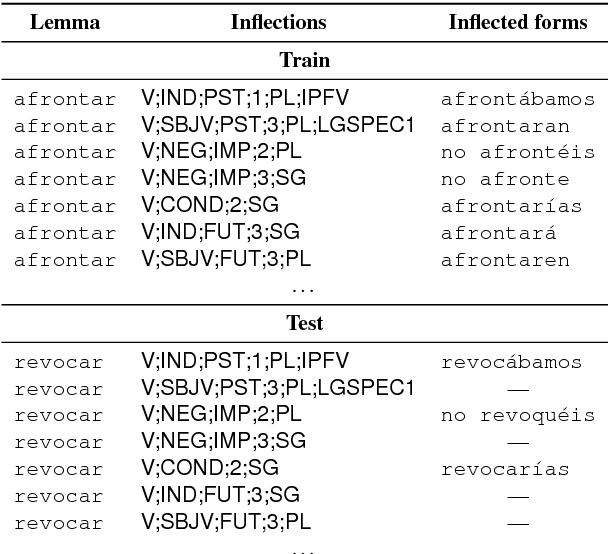
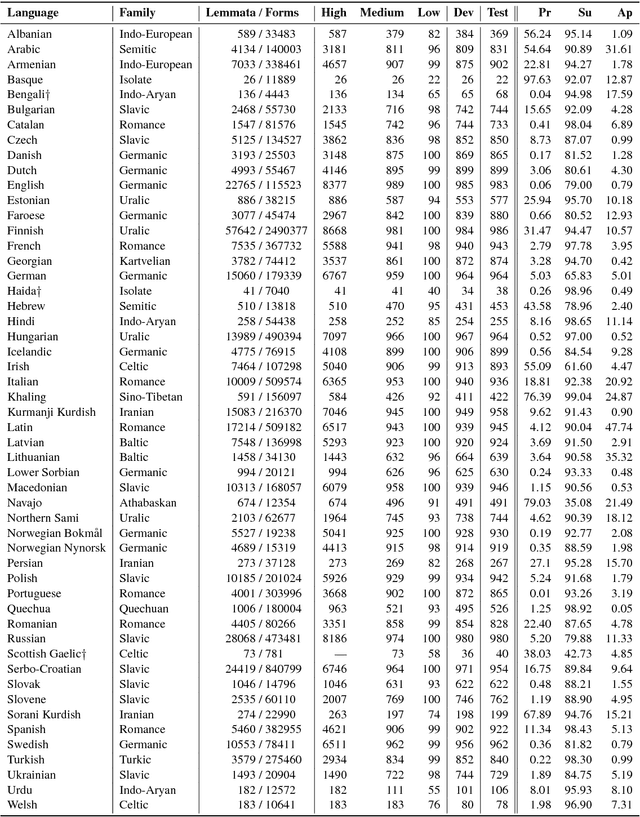
The CoNLL-SIGMORPHON 2017 shared task on supervised morphological generation required systems to be trained and tested in each of 52 typologically diverse languages. In sub-task 1, submitted systems were asked to predict a specific inflected form of a given lemma. In sub-task 2, systems were given a lemma and some of its specific inflected forms, and asked to complete the inflectional paradigm by predicting all of the remaining inflected forms. Both sub-tasks included high, medium, and low-resource conditions. Sub-task 1 received 24 system submissions, while sub-task 2 received 3 system submissions. Following the success of neural sequence-to-sequence models in the SIGMORPHON 2016 shared task, all but one of the submissions included a neural component. The results show that high performance can be achieved with small training datasets, so long as models have appropriate inductive bias or make use of additional unlabeled data or synthetic data. However, different biasing and data augmentation resulted in disjoint sets of inflected forms being predicted correctly, suggesting that there is room for future improvement.
Context-Aware Prediction of Derivational Word-forms
Feb 22, 2017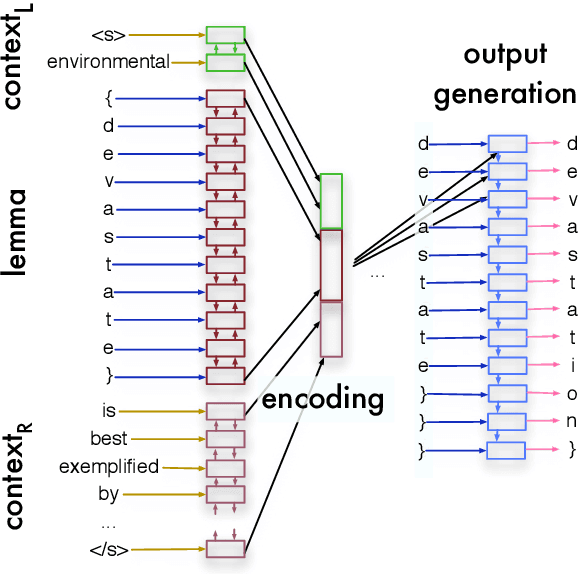
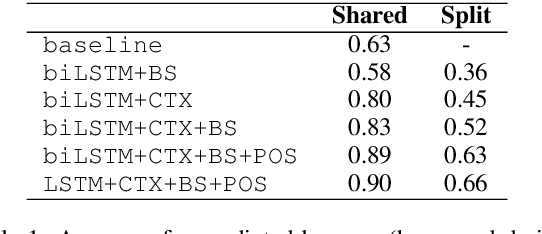

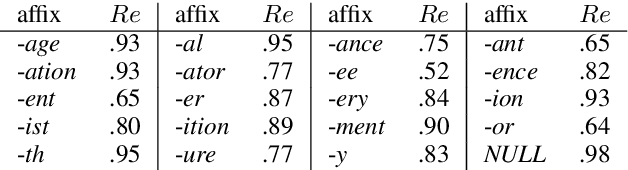
Derivational morphology is a fundamental and complex characteristic of language. In this paper we propose the new task of predicting the derivational form of a given base-form lemma that is appropriate for a given context. We present an encoder--decoder style neural network to produce a derived form character-by-character, based on its corresponding character-level representation of the base form and the context. We demonstrate that our model is able to generate valid context-sensitive derivations from known base forms, but is less accurate under a lexicon agnostic setting.
Take and Took, Gaggle and Goose, Book and Read: Evaluating the Utility of Vector Differences for Lexical Relation Learning
Aug 13, 2016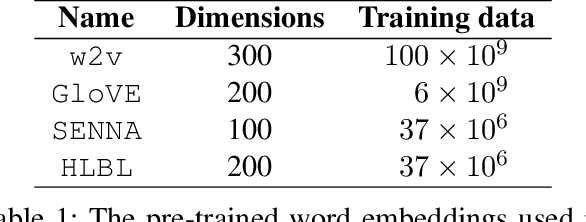
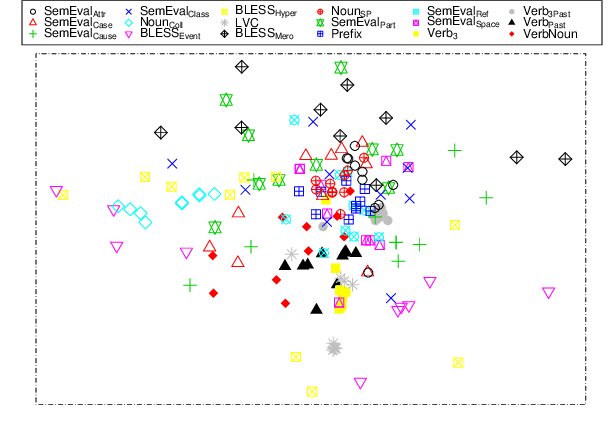

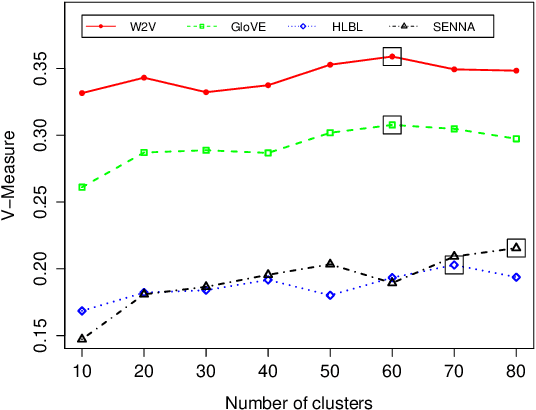
Recent work on word embeddings has shown that simple vector subtraction over pre-trained embeddings is surprisingly effective at capturing different lexical relations, despite lacking explicit supervision. Prior work has evaluated this intriguing result using a word analogy prediction formulation and hand-selected relations, but the generality of the finding over a broader range of lexical relation types and different learning settings has not been evaluated. In this paper, we carry out such an evaluation in two learning settings: (1) spectral clustering to induce word relations, and (2) supervised learning to classify vector differences into relation types. We find that word embeddings capture a surprising amount of information, and that, under suitable supervised training, vector subtraction generalises well to a broad range of relations, including over unseen lexical items.
Word Representation Models for Morphologically Rich Languages in Neural Machine Translation
Jun 14, 2016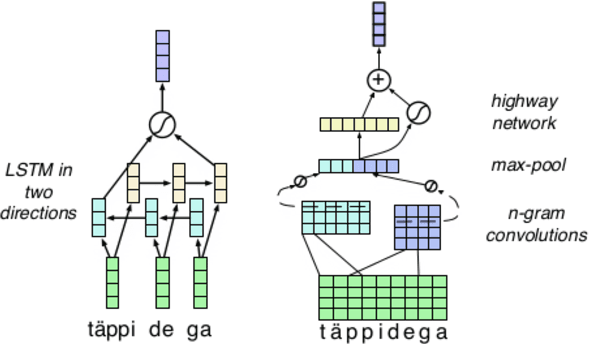

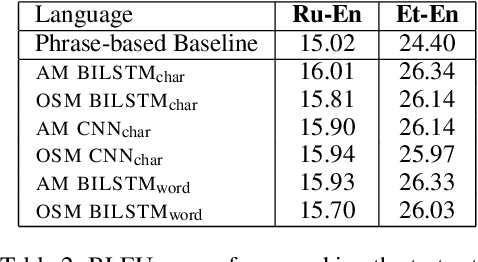
Dealing with the complex word forms in morphologically rich languages is an open problem in language processing, and is particularly important in translation. In contrast to most modern neural systems of translation, which discard the identity for rare words, in this paper we propose several architectures for learning word representations from character and morpheme level word decompositions. We incorporate these representations in a novel machine translation model which jointly learns word alignments and translations via a hard attention mechanism. Evaluating on translating from several morphologically rich languages into English, we show consistent improvements over strong baseline methods, of between 1 and 1.5 BLEU points.