 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRuSentEval: Linguistic Source, Encoder Force!
Mar 02, 2021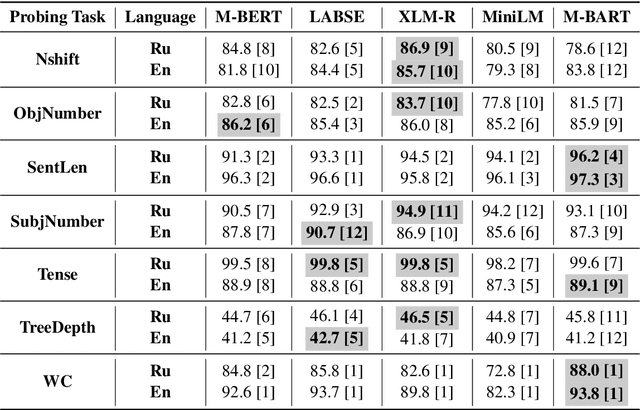
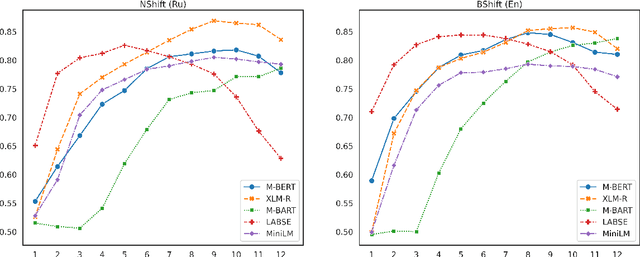
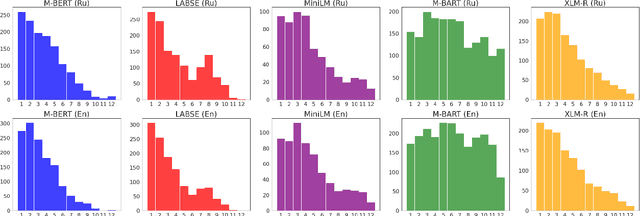
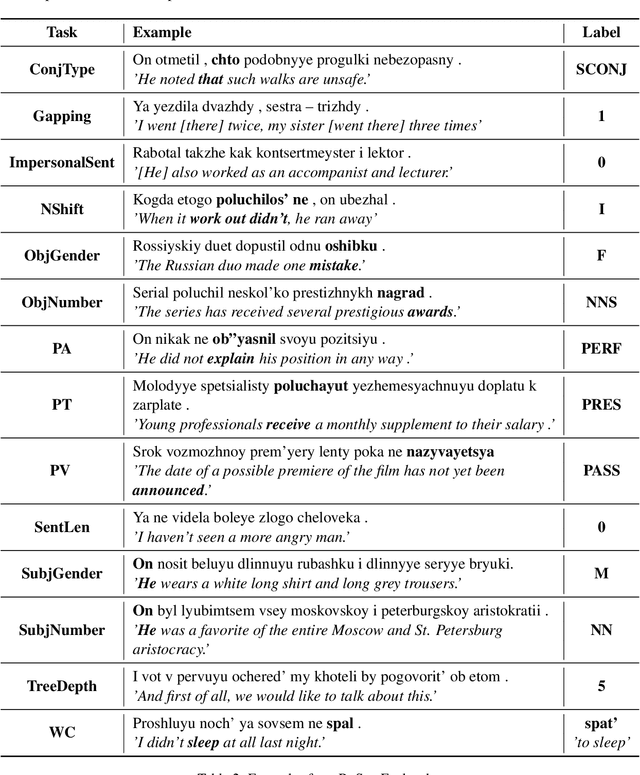
The success of pre-trained transformer language models has brought a great deal of interest on how these models work, and what they learn about language. However, prior research in the field is mainly devoted to English, and little is known regarding other languages. To this end, we introduce RuSentEval, an enhanced set of 14 probing tasks for Russian, including ones that have not been explored yet. We apply a combination of complementary probing methods to explore the distribution of various linguistic properties in five multilingual transformers for two typologically contrasting languages -- Russian and English. Our results provide intriguing findings that contradict the common understanding of how linguistic knowledge is represented, and demonstrate that some properties are learned in a similar manner despite the language differences.
Active Learning for Sequence Tagging with Deep Pre-trained Models and Bayesian Uncertainty Estimates
Feb 18, 2021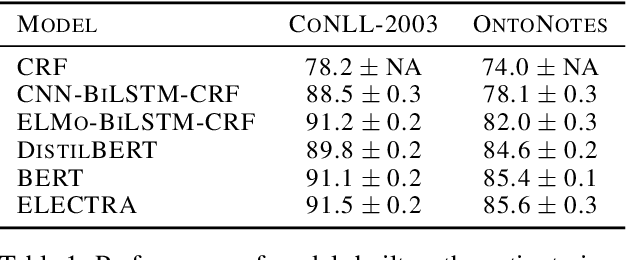
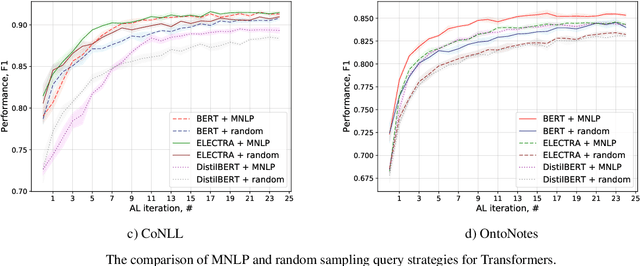
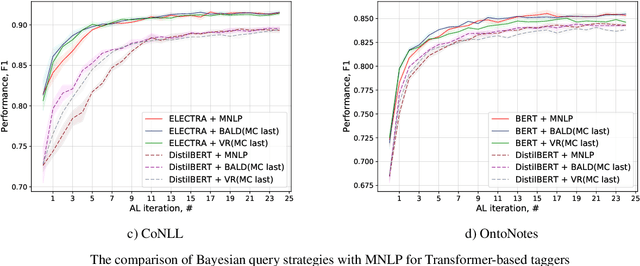
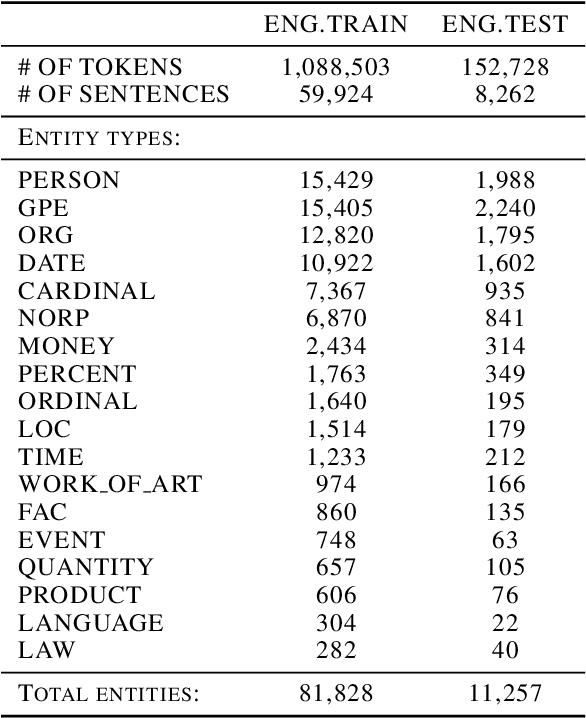
Annotating training data for sequence tagging of texts is usually very time-consuming. Recent advances in transfer learning for natural language processing in conjunction with active learning open the possibility to significantly reduce the necessary annotation budget. We are the first to thoroughly investigate this powerful combination for the sequence tagging task. We conduct an extensive empirical study of various Bayesian uncertainty estimation methods and Monte Carlo dropout options for deep pre-trained models in the active learning framework and find the best combinations for different types of models. Besides, we also demonstrate that to acquire instances during active learning, a full-size Transformer can be substituted with a distilled version, which yields better computational performance and reduces obstacles for applying deep active learning in practice.
Revisiting Mahalanobis Distance for Transformer-Based Out-of-Domain Detection
Jan 11, 2021Real-life applications, heavily relying on machine learning, such as dialog systems, demand out-of-domain detection methods. Intent classification models should be equipped with a mechanism to distinguish seen intents from unseen ones so that the dialog agent is capable of rejecting the latter and avoiding undesired behavior. However, despite increasing attention paid to the task, the best practices for out-of-domain intent detection have not yet been fully established. This paper conducts a thorough comparison of out-of-domain intent detection methods. We prioritize the methods, not requiring access to out-of-domain data during training, gathering of which is extremely time- and labor-consuming due to lexical and stylistic variation of user utterances. We evaluate multiple contextual encoders and methods, proven to be efficient, on three standard datasets for intent classification, expanded with out-of-domain utterances. Our main findings show that fine-tuning Transformer-based encoders on in-domain data leads to superior results. Mahalanobis distance, together with utterance representations, derived from Transformer-based encoders, outperforms other methods by a wide margin and establishes new state-of-the-art results for all datasets. The broader analysis shows that the reason for success lies in the fact that the fine-tuned Transformer is capable of constructing homogeneous representations of in-domain utterances, revealing geometrical disparity to out of domain utterances. In turn, the Mahalanobis distance captures this disparity easily.
RussianSuperGLUE: A Russian Language Understanding Evaluation Benchmark
Nov 02, 2020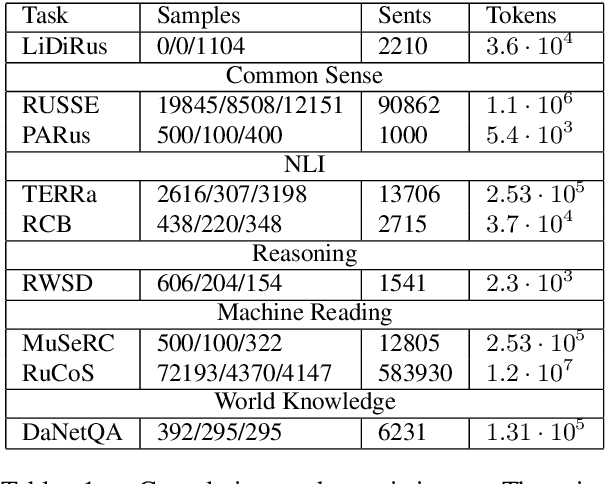

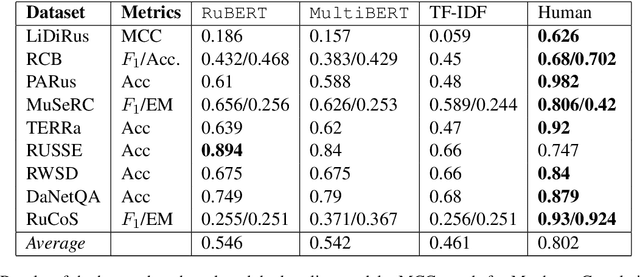

In this paper, we introduce an advanced Russian general language understanding evaluation benchmark -- RussianGLUE. Recent advances in the field of universal language models and transformers require the development of a methodology for their broad diagnostics and testing for general intellectual skills - detection of natural language inference, commonsense reasoning, ability to perform simple logical operations regardless of text subject or lexicon. For the first time, a benchmark of nine tasks, collected and organized analogically to the SuperGLUE methodology, was developed from scratch for the Russian language. We provide baselines, human level evaluation, an open-source framework for evaluating models (https://github.com/RussianNLP/RussianSuperGLUE), and an overall leaderboard of transformer models for the Russian language. Besides, we present the first results of comparing multilingual models in the adapted diagnostic test set and offer the first steps to further expanding or assessing state-of-the-art models independently of language.
RuREBus: a Case Study of Joint Named Entity Recognition and Relation Extraction from e-Government Domain
Oct 29, 2020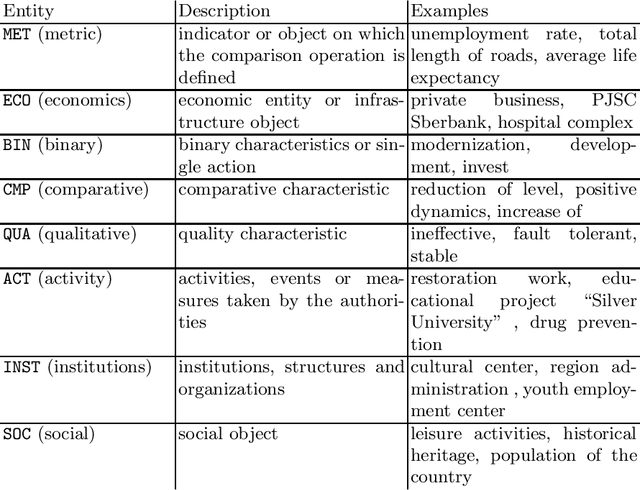
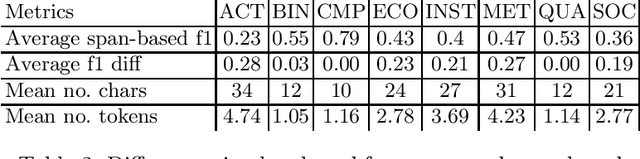
We show-case an application of information extraction methods, such as named entity recognition (NER) and relation extraction (RE) to a novel corpus, consisting of documents, issued by a state agency. The main challenges of this corpus are: 1) the annotation scheme differs greatly from the one used for the general domain corpora, and 2) the documents are written in a language other than English. Unlike expectations, the state-of-the-art transformer-based models show modest performance for both tasks, either when approached sequentially, or in an end-to-end fashion. Our experiments have demonstrated that fine-tuning on a large unlabeled corpora does not automatically yield significant improvement and thus we may conclude that more sophisticated strategies of leveraging unlabelled texts are demanded. In this paper, we describe the whole developed pipeline, starting from text annotation, baseline development, and designing a shared task in hopes of improving the baseline. Eventually, we realize that the current NER and RE technologies are far from being mature and do not overcome so far challenges like ours.
DaNetQA: a yes/no Question Answering Dataset for the Russian Language
Oct 15, 2020

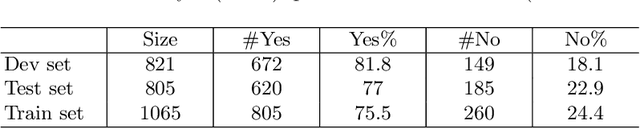

DaNetQA, a new question-answering corpus, follows (Clark et. al, 2019) design: it comprises natural yes/no questions. Each question is paired with a paragraph from Wikipedia and an answer, derived from the paragraph. The task is to take both the question and a paragraph as input and come up with a yes/no answer, i.e. to produce a binary output. In this paper, we present a reproducible approach to DaNetQA creation and investigate transfer learning methods for task and language transferring. For task transferring we leverage three similar sentence modelling tasks: 1) a corpus of paraphrases, Paraphraser, 2) an NLI task, for which we use the Russian part of XNLI, 3) another question answering task, SberQUAD. For language transferring we use English to Russian translation together with multilingual language fine-tuning.
ELMo and BERT in semantic change detection for Russian
Oct 07, 2020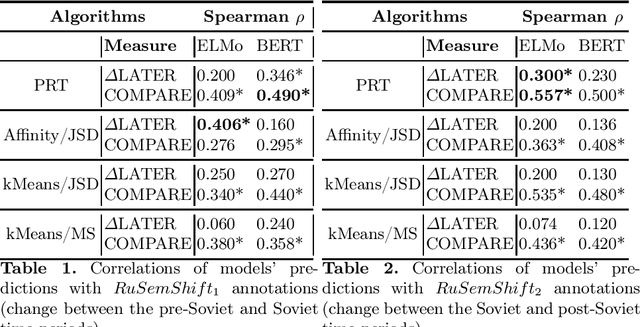
We study the effectiveness of contextualized embeddings for the task of diachronic semantic change detection for Russian language data. Evaluation test sets consist of Russian nouns and adjectives annotated based on their occurrences in texts created in pre-Soviet, Soviet and post-Soviet time periods. ELMo and BERT architectures are compared on the task of ranking Russian words according to the degree of their semantic change over time. We use several methods for aggregation of contextualized embeddings from these architectures and evaluate their performance. Finally, we compare unsupervised and supervised techniques in this task.
So What's the Plan? Mining Strategic Planning Documents
Jul 07, 2020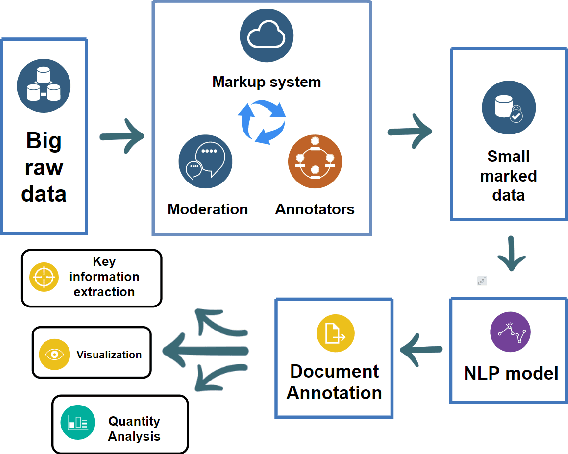

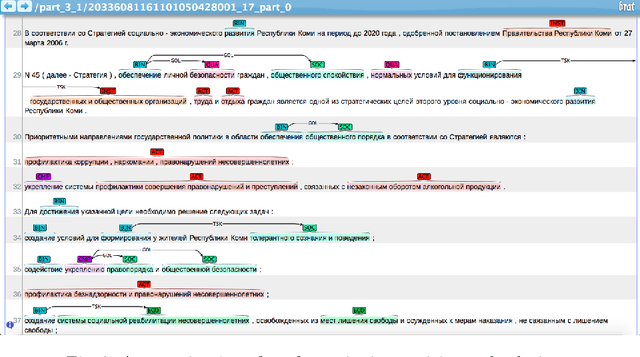
In this paper we present a corpus of Russian strategic planning documents, RuREBus. This project is grounded both from language technology and e-government perspectives. Not only new language sources and tools are being developed, but also their applications to e-goverment research. We demonstrate the pipeline for creating a text corpus from scratch. First, the annotation schema is designed. Next texts are marked up using human-in-the-loop strategy, so that preliminary annotations are derived from a machine learning model and are manually corrected. The amount of annotated texts is large enough to showcase what insights can be gained from RuREBus.
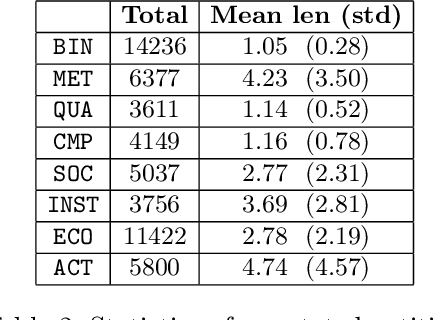
NAS-Bench-NLP: Neural Architecture Search Benchmark for Natural Language Processing
Jun 12, 2020

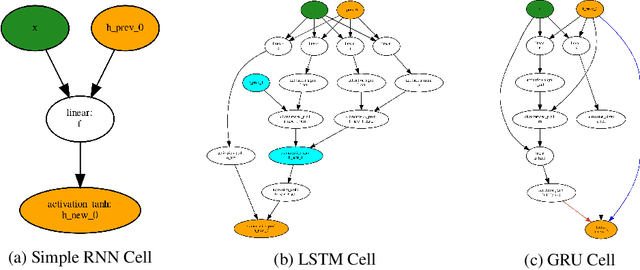
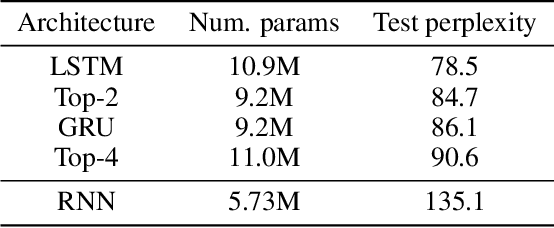
Neural Architecture Search (NAS) is a promising and rapidly evolving research area. Training a large number of neural networks requires an exceptional amount of computational power, which makes NAS unreachable for those researchers who have limited or no access to high-performance clusters and supercomputers. A few benchmarks with precomputed neural architectures performances have been recently introduced to overcome this problem and ensure more reproducible experiments. However, these benchmarks are only for the computer vision domain and, thus, are built from the image datasets and convolution-derived architectures. In this work, we step outside the computer vision domain by leveraging the language modeling task, which is the core of natural language processing (NLP). Our main contribution is as follows: we have provided search space of recurrent neural networks on the text datasets and trained 14k architectures within it; we have conducted both intrinsic and extrinsic evaluation of the trained models using datasets for semantic relatedness and language understanding evaluation; finally, we have tested several NAS algorithms to demonstrate how the precomputed results can be utilized. We believe that our results have high potential of usage for both NAS and NLP communities.
Data-driven models and computational tools for neurolinguistics: a language technology perspective
Mar 23, 2020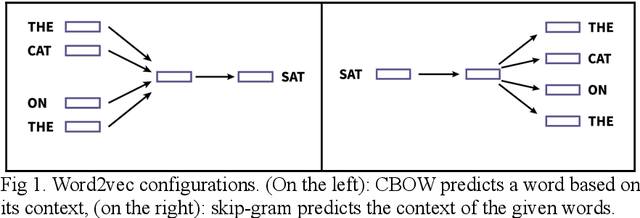
In this paper, our focus is the connection and influence of language technologies on the research in neurolinguistics. We present a review of brain imaging-based neurolinguistic studies with a focus on the natural language representations, such as word embeddings and pre-trained language models. Mutual enrichment of neurolinguistics and language technologies leads to development of brain-aware natural language representations. The importance of this research area is emphasized by medical applications.
* 37 pages, 1 figure