 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow-resource Bilingual Dialect Lexicon Induction with Large Language Models
Apr 19, 2023Bilingual word lexicons are crucial tools for multilingual natural language understanding and machine translation tasks, as they facilitate the mapping of words in one language to their synonyms in another language. To achieve this, numerous papers have explored bilingual lexicon induction (BLI) in high-resource scenarios, using a typical pipeline consisting of two unsupervised steps: bitext mining and word alignment, both of which rely on pre-trained large language models~(LLMs). In this paper, we present an analysis of the BLI pipeline for German and two of its dialects, Bavarian and Alemannic. This setup poses several unique challenges, including the scarcity of resources, the relatedness of the languages, and the lack of standardization in the orthography of dialects. To evaluate the BLI outputs, we analyze them with respect to word frequency and pairwise edit distance. Additionally, we release two evaluation datasets comprising 1,500 bilingual sentence pairs and 1,000 bilingual word pairs. They were manually judged for their semantic similarity for each Bavarian-German and Alemannic-German language pair.
Can BERT eat RuCoLA? Topological Data Analysis to Explain
Apr 04, 2023This paper investigates how Transformer language models (LMs) fine-tuned for acceptability classification capture linguistic features. Our approach uses the best practices of topological data analysis (TDA) in NLP: we construct directed attention graphs from attention matrices, derive topological features from them, and feed them to linear classifiers. We introduce two novel features, chordality, and the matching number, and show that TDA-based classifiers outperform fine-tuning baselines. We experiment with two datasets, CoLA and RuCoLA in English and Russian, typologically different languages. On top of that, we propose several black-box introspection techniques aimed at detecting changes in the attention mode of the LMs during fine-tuning, defining the LM's prediction confidences, and associating individual heads with fine-grained grammar phenomena. Our results contribute to understanding the behavior of monolingual LMs in the acceptability classification task, provide insights into the functional roles of attention heads, and highlight the advantages of TDA-based approaches for analyzing LMs. We release the code and the experimental results for further uptake.
RuCoLA: Russian Corpus of Linguistic Acceptability
Oct 23, 2022



Linguistic acceptability (LA) attracts the attention of the research community due to its many uses, such as testing the grammatical knowledge of language models and filtering implausible texts with acceptability classifiers. However, the application scope of LA in languages other than English is limited due to the lack of high-quality resources. To this end, we introduce the Russian Corpus of Linguistic Acceptability (RuCoLA), built from the ground up under the well-established binary LA approach. RuCoLA consists of $9.8$k in-domain sentences from linguistic publications and $3.6$k out-of-domain sentences produced by generative models. The out-of-domain set is created to facilitate the practical use of acceptability for improving language generation. Our paper describes the data collection protocol and presents a fine-grained analysis of acceptability classification experiments with a range of baseline approaches. In particular, we demonstrate that the most widely used language models still fall behind humans by a large margin, especially when detecting morphological and semantic errors. We release RuCoLA, the code of experiments, and a public leaderboard (rucola-benchmark.com) to assess the linguistic competence of language models for Russian.
TAPE: Assessing Few-shot Russian Language Understanding
Oct 23, 2022Recent advances in zero-shot and few-shot learning have shown promise for a scope of research and practical purposes. However, this fast-growing area lacks standardized evaluation suites for non-English languages, hindering progress outside the Anglo-centric paradigm. To address this line of research, we propose TAPE (Text Attack and Perturbation Evaluation), a novel benchmark that includes six more complex NLU tasks for Russian, covering multi-hop reasoning, ethical concepts, logic and commonsense knowledge. The TAPE's design focuses on systematic zero-shot and few-shot NLU evaluation: (i) linguistic-oriented adversarial attacks and perturbations for analyzing robustness, and (ii) subpopulations for nuanced interpretation. The detailed analysis of testing the autoregressive baselines indicates that simple spelling-based perturbations affect the performance the most, while paraphrasing the input has a more negligible effect. At the same time, the results demonstrate a significant gap between the neural and human baselines for most tasks. We publicly release TAPE (tape-benchmark.com) to foster research on robust LMs that can generalize to new tasks when little to no supervision is available.
Vote'n'Rank: Revision of Benchmarking with Social Choice Theory
Oct 13, 2022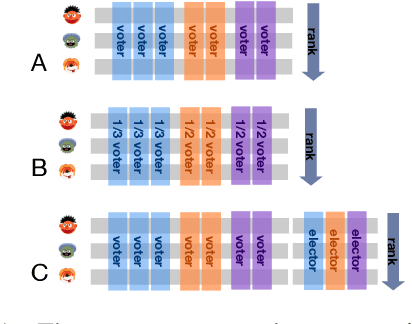
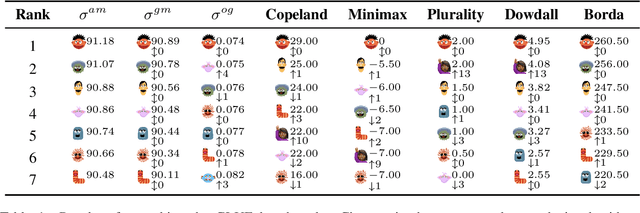
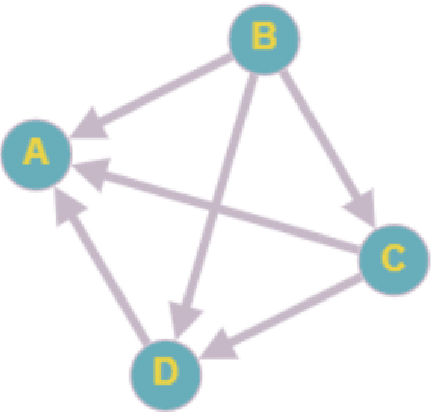
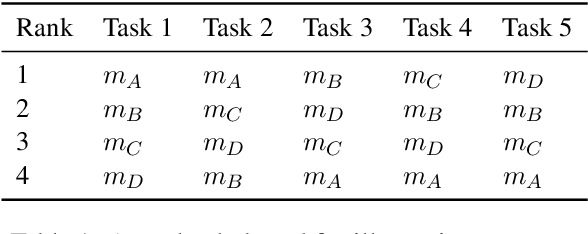
The development of state-of-the-art systems in different applied areas of machine learning (ML) is driven by benchmarks, which have shaped the paradigm of evaluating generalisation capabilities from multiple perspectives. Although the paradigm is shifting towards more fine-grained evaluation across diverse tasks, the delicate question of how to aggregate the performances has received particular interest in the community. In general, benchmarks follow the unspoken utilitarian principles, where the systems are ranked based on their mean average score over task-specific metrics. Such aggregation procedure has been viewed as a sub-optimal evaluation protocol, which may have created the illusion of progress. This paper proposes Vote'n'Rank, a framework for ranking systems in multi-task benchmarks under the principles of the social choice theory. We demonstrate that our approach can be efficiently utilised to draw new insights on benchmarking in several ML sub-fields and identify the best-performing systems in research and development case studies. The Vote'n'Rank's procedures are more robust than the mean average while being able to handle missing performance scores and determine conditions under which the system becomes the winner.
Template-based Approach to Zero-shot Intent Recognition
Jun 22, 2022
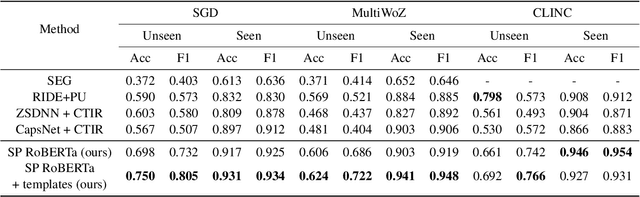
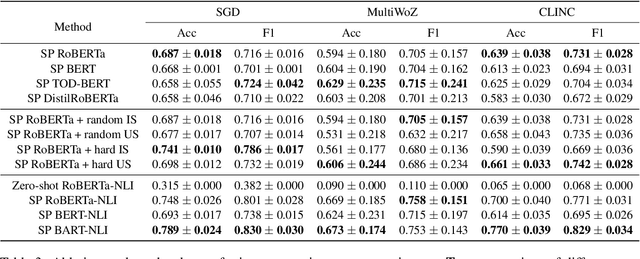

The recent advances in transfer learning techniques and pre-training of large contextualized encoders foster innovation in real-life applications, including dialog assistants. Practical needs of intent recognition require effective data usage and the ability to constantly update supported intents, adopting new ones, and abandoning outdated ones. In particular, the generalized zero-shot paradigm, in which the model is trained on the seen intents and tested on both seen and unseen intents, is taking on new importance. In this paper, we explore the generalized zero-shot setup for intent recognition. Following best practices for zero-shot text classification, we treat the task with a sentence pair modeling approach. We outperform previous state-of-the-art f1-measure by up to 16\% for unseen intents, using intent labels and user utterances and without accessing external sources (such as knowledge bases). Further enhancement includes lexicalization of intent labels, which improves performance by up to 7\%. By using task transferring from other sentence pair tasks, such as Natural Language Inference, we gain additional improvements.
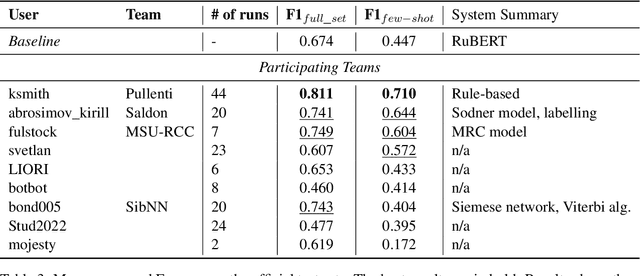
Findings of the The RuATD Shared Task 2022 on Artificial Text Detection in Russian
Jun 03, 2022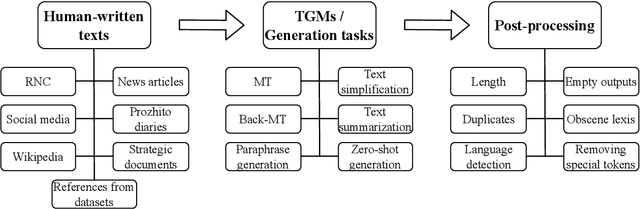
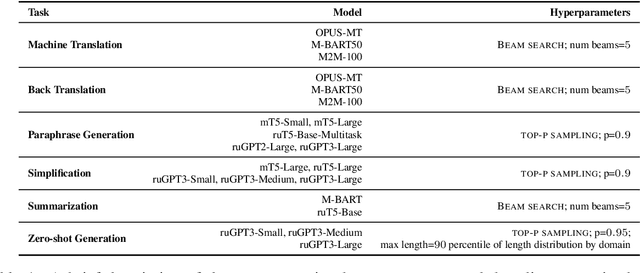
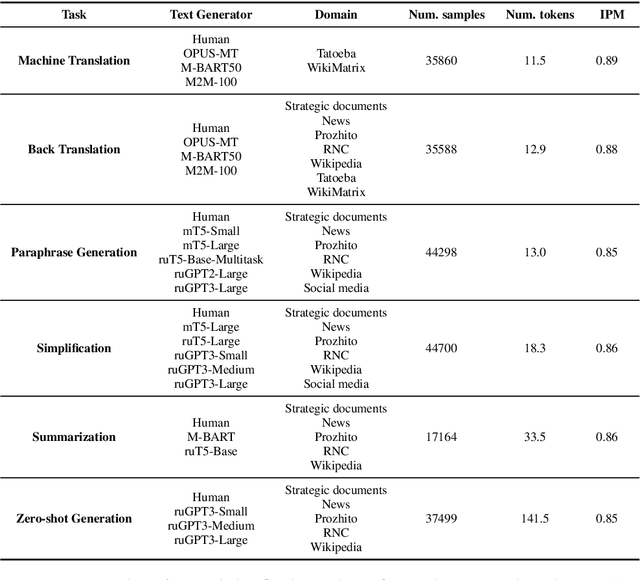
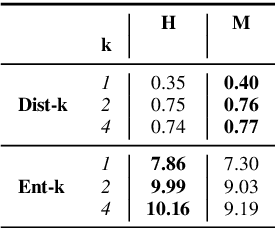
We present the shared task on artificial text detection in Russian, which is organized as a part of the Dialogue Evaluation initiative, held in 2022. The shared task dataset includes texts from 14 text generators, i.e., one human writer and 13 text generative models fine-tuned for one or more of the following generation tasks: machine translation, paraphrase generation, text summarization, text simplification. We also consider back-translation and zero-shot generation approaches. The human-written texts are collected from publicly available resources across multiple domains. The shared task consists of two sub-tasks: (i) to determine if a given text is automatically generated or written by a human; (ii) to identify the author of a given text. The first task is framed as a binary classification problem. The second task is a multi-class classification problem. We provide count-based and BERT-based baselines, along with the human evaluation on the first sub-task. A total of 30 and 8 systems have been submitted to the binary and multi-class sub-tasks, correspondingly. Most teams outperform the baselines by a wide margin. We publicly release our codebase, human evaluation results, and other materials in our GitHub repository (https://github.com/dialogue-evaluation/RuATD).
RuNNE-2022 Shared Task: Recognizing Nested Named Entities
May 23, 2022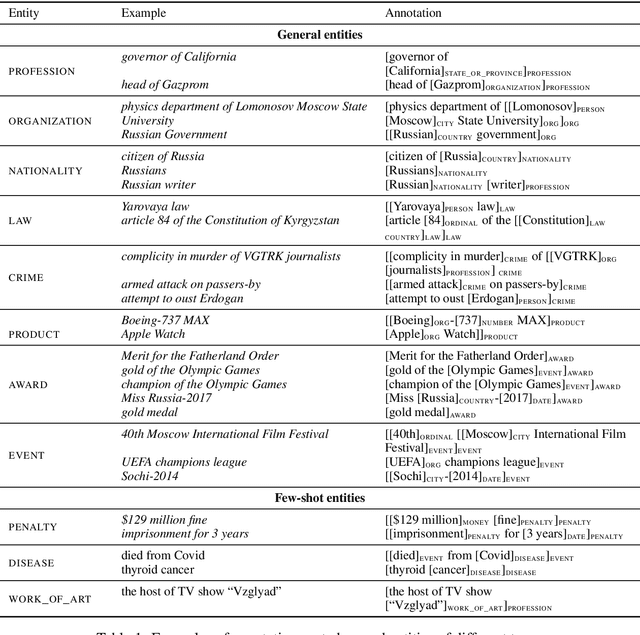
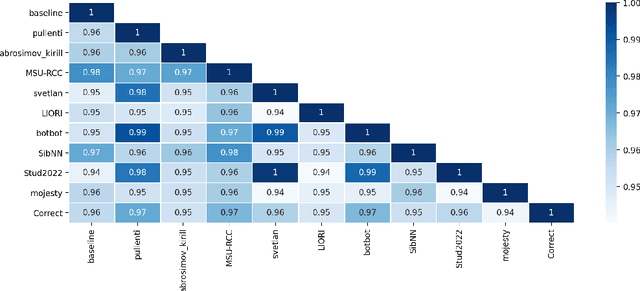
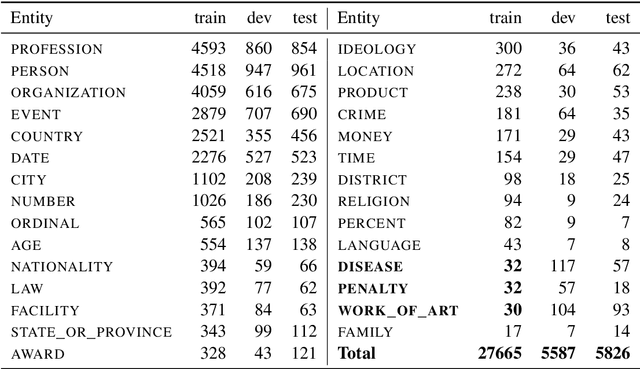
The RuNNE Shared Task approaches the problem of nested named entity recognition. The annotation schema is designed in such a way, that an entity may partially overlap or even be nested into another entity. This way, the named entity "The Yermolova Theatre" of type "organization" houses another entity "Yermolova" of type "person". We adopt the Russian NEREL dataset for the RuNNE Shared Task. NEREL comprises news texts written in the Russian language and collected from the Wikinews portal. The annotation schema includes 29 entity types. The nestedness of named entities in NEREL reaches up to six levels. The RuNNE Shared Task explores two setups. (i) In the general setup all entities occur more or less with the same frequency. (ii) In the few-shot setup the majority of entity types occur often in the training set. However, some of the entity types are have lower frequency, being thus challenging to recognize. In the test set the frequency of all entity types is even. This paper reports on the results of the RuNNE Shared Task. Overall the shared task has received 156 submissions from nine teams. Half of the submissions outperform a straightforward BERT-based baseline in both setups. This paper overviews the shared task setup and discusses the submitted systems, discovering meaning insights for the problem of nested NER. The links to the evaluation platform and the data from the shared task are available in our github repository: https://github.com/dialogue-evaluation/RuNNE.
Acceptability Judgements via Examining the Topology of Attention Maps
May 19, 2022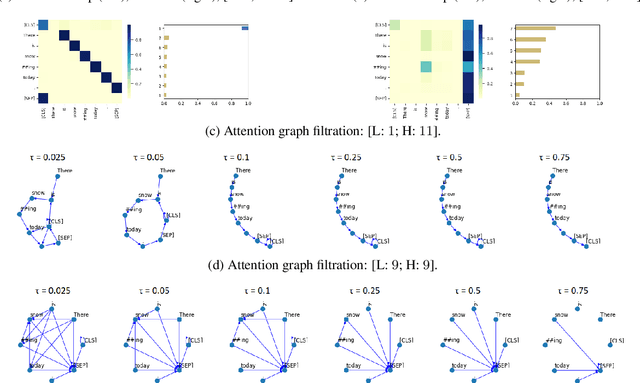
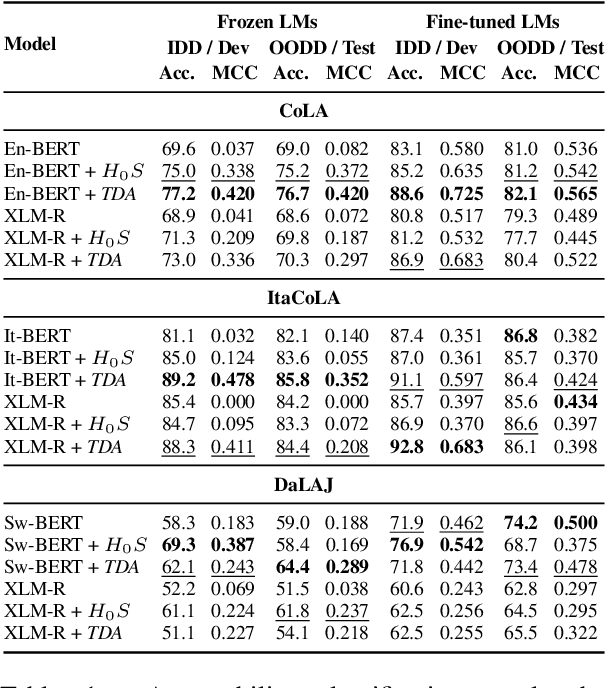
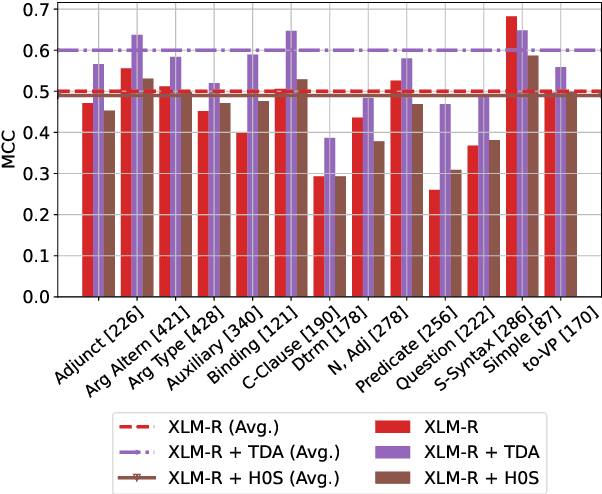
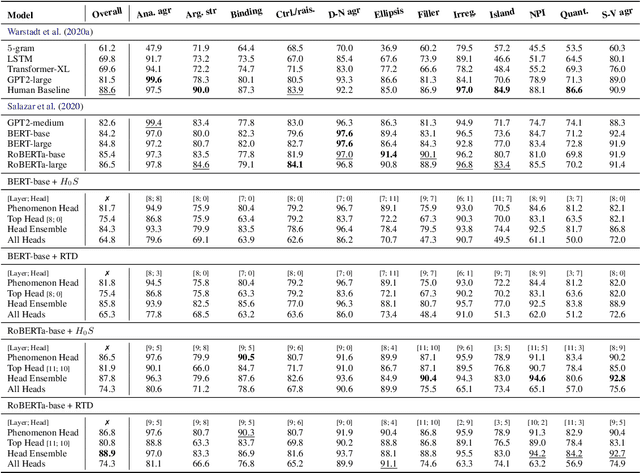
The role of the attention mechanism in encoding linguistic knowledge has received special interest in NLP. However, the ability of the attention heads to judge the grammatical acceptability of a sentence has been underexplored. This paper approaches the paradigm of acceptability judgments with topological data analysis (TDA), showing that the geometric properties of the attention graph can be efficiently exploited for two standard practices in linguistics: binary judgments and linguistic minimal pairs. Topological features enhance the BERT-based acceptability classifier scores by $8$%-$24$% on CoLA in three languages (English, Italian, and Swedish). By revealing the topological discrepancy between attention maps of minimal pairs, we achieve the human-level performance on the BLiMP benchmark, outperforming nine statistical and Transformer LM baselines. At the same time, TDA provides the foundation for analyzing the linguistic functions of attention heads and interpreting the correspondence between the graph features and grammatical phenomena.
Russian SuperGLUE 1.1: Revising the Lessons not Learned by Russian NLP models
Feb 15, 2022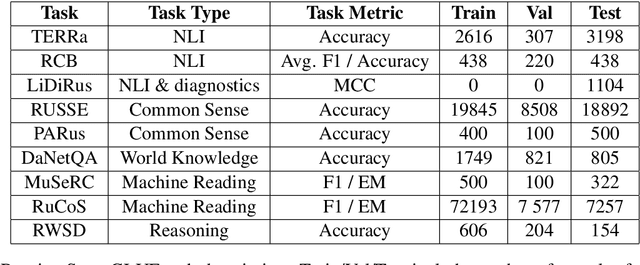
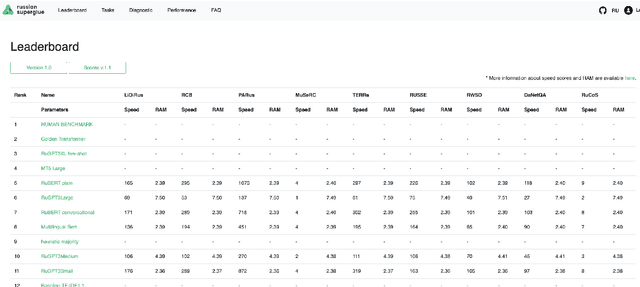
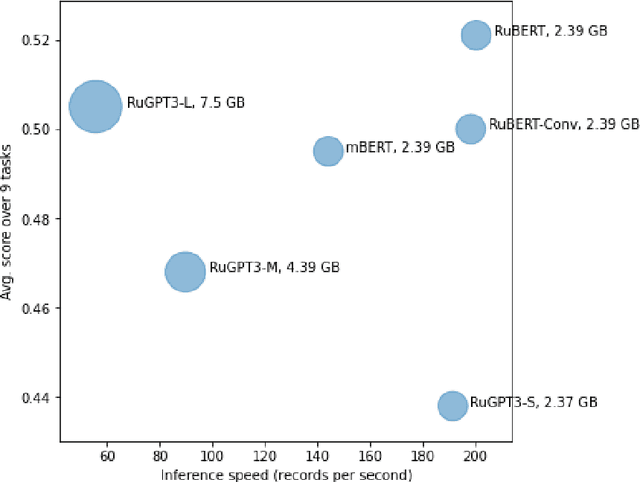
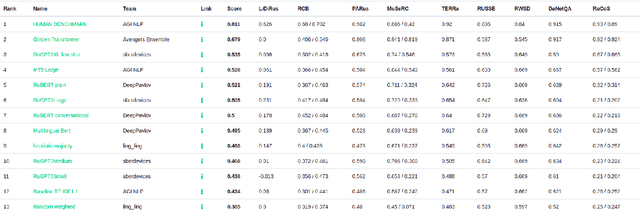
In the last year, new neural architectures and multilingual pre-trained models have been released for Russian, which led to performance evaluation problems across a range of language understanding tasks. This paper presents Russian SuperGLUE 1.1, an updated benchmark styled after GLUE for Russian NLP models. The new version includes a number of technical, user experience and methodological improvements, including fixes of the benchmark vulnerabilities unresolved in the previous version: novel and improved tests for understanding the meaning of a word in context (RUSSE) along with reading comprehension and common sense reasoning (DaNetQA, RuCoS, MuSeRC). Together with the release of the updated datasets, we improve the benchmark toolkit based on \texttt{jiant} framework for consistent training and evaluation of NLP-models of various architectures which now supports the most recent models for Russian. Finally, we provide the integration of Russian SuperGLUE with a framework for industrial evaluation of the open-source models, MOROCCO (MOdel ResOurCe COmparison), in which the models are evaluated according to the weighted average metric over all tasks, the inference speed, and the occupied amount of RAM. Russian SuperGLUE is publicly available at https://russiansuperglue.com/.