 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluation of Human-Understandability of Global Model Explanations using Decision Tree
Sep 18, 2023In explainable artificial intelligence (XAI) research, the predominant focus has been on interpreting models for experts and practitioners. Model agnostic and local explanation approaches are deemed interpretable and sufficient in many applications. However, in domains like healthcare, where end users are patients without AI or domain expertise, there is an urgent need for model explanations that are more comprehensible and instil trust in the model's operations. We hypothesise that generating model explanations that are narrative, patient-specific and global(holistic of the model) would enable better understandability and enable decision-making. We test this using a decision tree model to generate both local and global explanations for patients identified as having a high risk of coronary heart disease. These explanations are presented to non-expert users. We find a strong individual preference for a specific type of explanation. The majority of participants prefer global explanations, while a smaller group prefers local explanations. A task based evaluation of mental models of these participants provide valuable feedback to enhance narrative global explanations. This, in turn, guides the design of health informatics systems that are both trustworthy and actionable.
Missing Information, Unresponsive Authors, Experimental Flaws: The Impossibility of Assessing the Reproducibility of Previous Human Evaluations in NLP
May 02, 2023



We report our efforts in identifying a set of previous human evaluations in NLP that would be suitable for a coordinated study examining what makes human evaluations in NLP more/less reproducible. We present our results and findings, which include that just 13\% of papers had (i) sufficiently low barriers to reproduction, and (ii) enough obtainable information, to be considered for reproduction, and that all but one of the experiments we selected for reproduction was discovered to have flaws that made the meaningfulness of conducting a reproduction questionable. As a result, we had to change our coordinated study design from a reproduce approach to a standardise-then-reproduce-twice approach. Our overall (negative) finding that the great majority of human evaluations in NLP is not repeatable and/or not reproducible and/or too flawed to justify reproduction, paints a dire picture, but presents an opportunity for a rethink about how to design and report human evaluations in NLP.
Consultation Checklists: Standardising the Human Evaluation of Medical Note Generation
Nov 17, 2022



Evaluating automatically generated text is generally hard due to the inherently subjective nature of many aspects of the output quality. This difficulty is compounded in automatic consultation note generation by differing opinions between medical experts both about which patient statements should be included in generated notes and about their respective importance in arriving at a diagnosis. Previous real-world evaluations of note-generation systems saw substantial disagreement between expert evaluators. In this paper we propose a protocol that aims to increase objectivity by grounding evaluations in Consultation Checklists, which are created in a preliminary step and then used as a common point of reference during quality assessment. We observed good levels of inter-annotator agreement in a first evaluation study using the protocol; further, using Consultation Checklists produced in the study as reference for automatic metrics such as ROUGE or BERTScore improves their correlation with human judgements compared to using the original human note.
BLOOM: A 176B-Parameter Open-Access Multilingual Language Model
Nov 09, 2022Large language models (LLMs) have been shown to be able to perform new tasks based on a few demonstrations or natural language instructions. While these capabilities have led to widespread adoption, most LLMs are developed by resource-rich organizations and are frequently kept from the public. As a step towards democratizing this powerful technology, we present BLOOM, a 176B-parameter open-access language model designed and built thanks to a collaboration of hundreds of researchers. BLOOM is a decoder-only Transformer language model that was trained on the ROOTS corpus, a dataset comprising hundreds of sources in 46 natural and 13 programming languages (59 in total). We find that BLOOM achieves competitive performance on a wide variety of benchmarks, with stronger results after undergoing multitask prompted finetuning. To facilitate future research and applications using LLMs, we publicly release our models and code under the Responsible AI License.
Comparing informativeness of an NLG chatbot vs graphical app in diet-information domain
Jul 02, 2022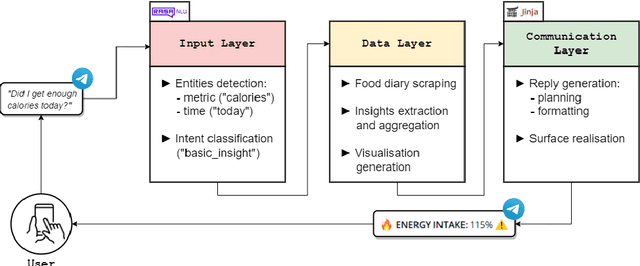
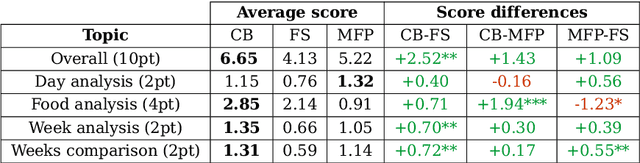
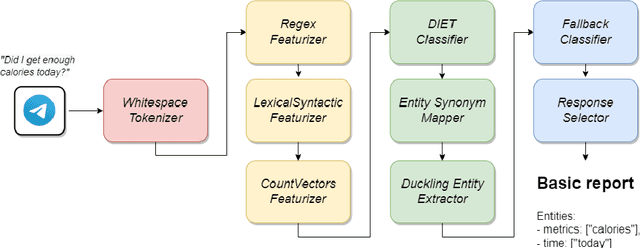
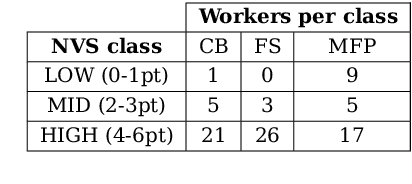
Visual representation of data like charts and tables can be challenging to understand for readers. Previous work showed that combining visualisations with text can improve the communication of insights in static contexts, but little is known about interactive ones. In this work we present an NLG chatbot that processes natural language queries and provides insights through a combination of charts and text. We apply it to nutrition, a domain communication quality is critical. Through crowd-sourced evaluation we compare the informativeness of our chatbot against traditional, static diet-apps. We find that the conversational context significantly improved users' understanding of dietary data in various tasks, and that users considered the chatbot as more useful and quick to use than traditional apps.
User-Driven Research of Medical Note Generation Software
May 06, 2022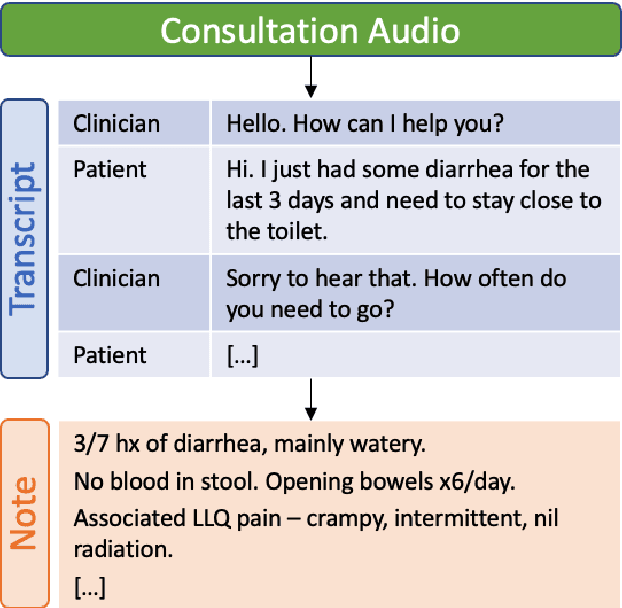
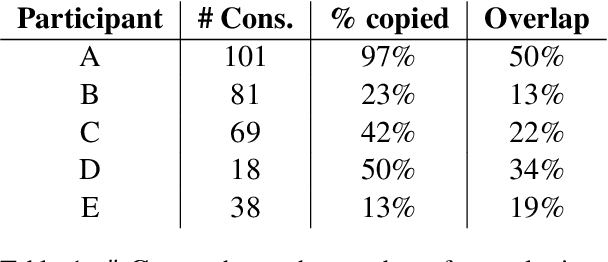

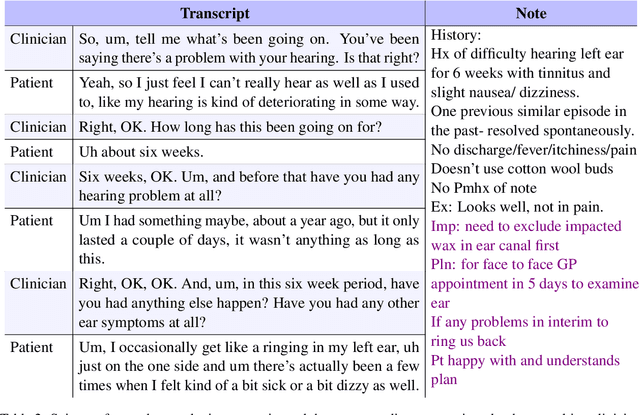
A growing body of work uses Natural Language Processing (NLP) methods to automatically generate medical notes from audio recordings of doctor-patient consultations. However, there are very few studies on how such systems could be used in clinical practice, how clinicians would adjust to using them, or how system design should be influenced by such considerations. In this paper, we present three rounds of user studies, carried out in the context of developing a medical note generation system. We present, analyse and discuss the participating clinicians' impressions and views of how the system ought to be adapted to be of value to them. Next, we describe a three-week test run of the system in a live telehealth clinical practice. Major findings include (i) the emergence of five different note-taking behaviours; (ii) the importance of the system generating notes in real time during the consultation; and (iii) the identification of a number of clinical use cases that could prove challenging for automatic note generation systems.
Human Evaluation and Correlation with Automatic Metrics in Consultation Note Generation
Apr 01, 2022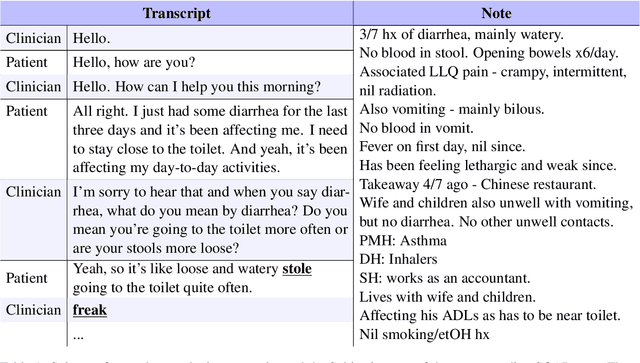
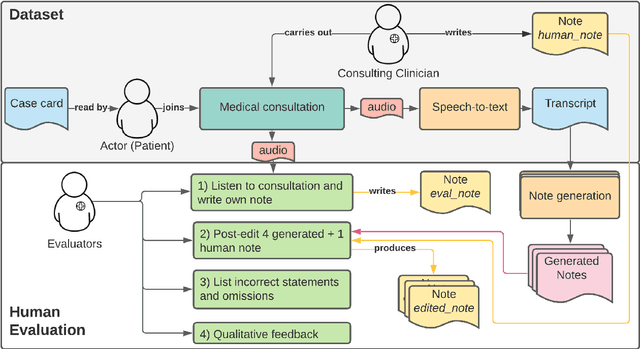
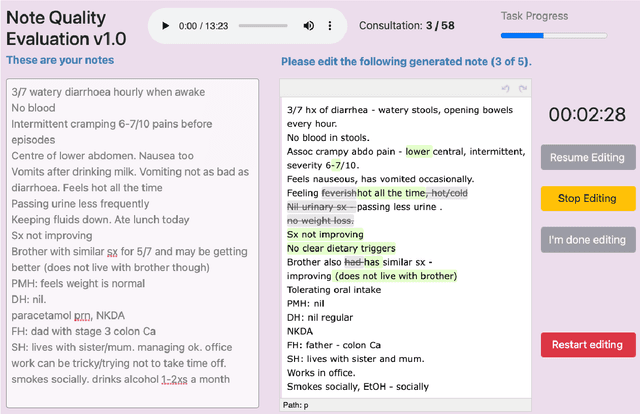
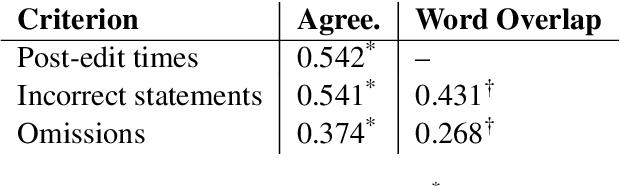
In recent years, machine learning models have rapidly become better at generating clinical consultation notes; yet, there is little work on how to properly evaluate the generated consultation notes to understand the impact they may have on both the clinician using them and the patient's clinical safety. To address this we present an extensive human evaluation study of consultation notes where 5 clinicians (i) listen to 57 mock consultations, (ii) write their own notes, (iii) post-edit a number of automatically generated notes, and (iv) extract all the errors, both quantitative and qualitative. We then carry out a correlation study with 18 automatic quality metrics and the human judgements. We find that a simple, character-based Levenshtein distance metric performs on par if not better than common model-based metrics like BertScore. All our findings and annotations are open-sourced.
Generation Challenges: Results of the Accuracy Evaluation Shared Task
Aug 15, 2021


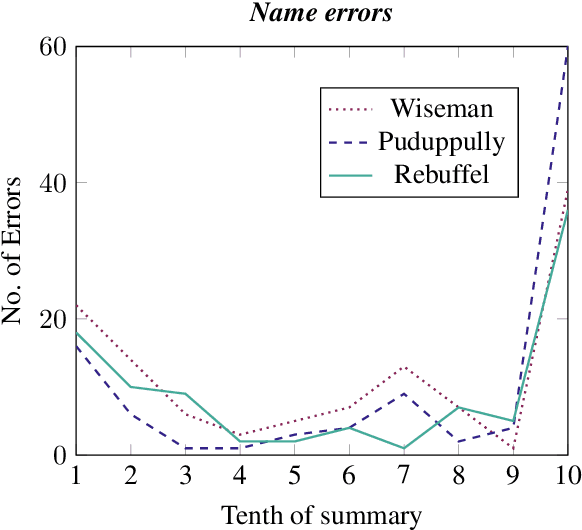
The Shared Task on Evaluating Accuracy focused on techniques (both manual and automatic) for evaluating the factual accuracy of texts produced by neural NLG systems, in a sports-reporting domain. Four teams submitted evaluation techniques for this task, using very different approaches and techniques. The best-performing submissions did encouragingly well at this difficult task. However, all automatic submissions struggled to detect factual errors which are semantically or pragmatically complex (for example, based on incorrect computation or inference).
Towards objectively evaluating the quality of generated medical summaries
Apr 09, 2021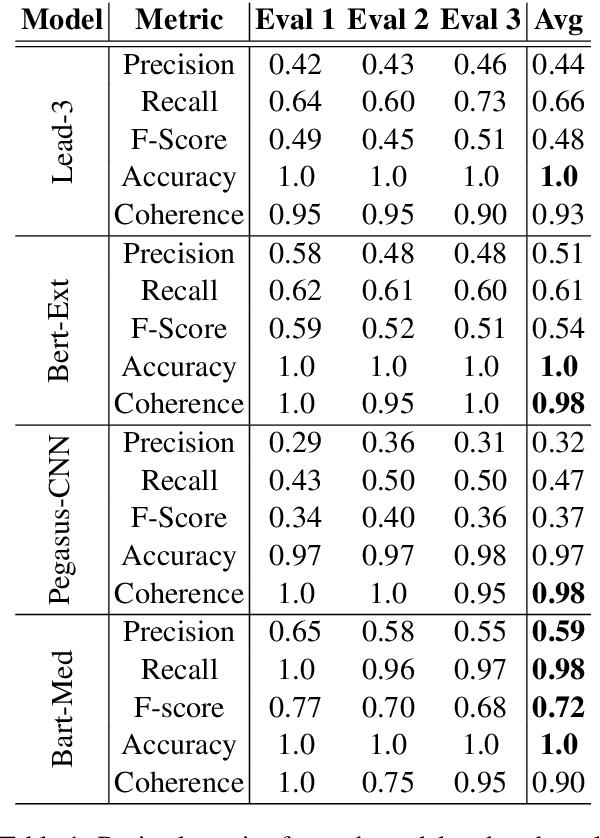

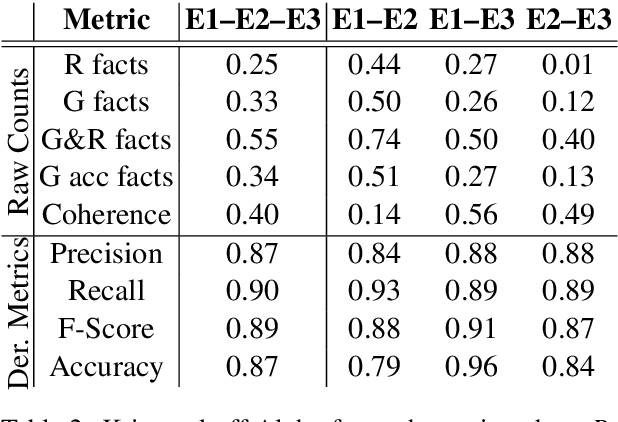

We propose a method for evaluating the quality of generated text by asking evaluators to count facts, and computing precision, recall, f-score, and accuracy from the raw counts. We believe this approach leads to a more objective and easier to reproduce evaluation. We apply this to the task of medical report summarisation, where measuring objective quality and accuracy is of paramount importance.
A preliminary study on evaluating Consultation Notes with Post-Editing
Apr 09, 2021

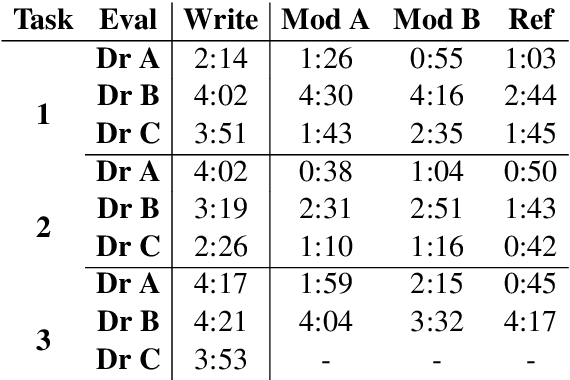
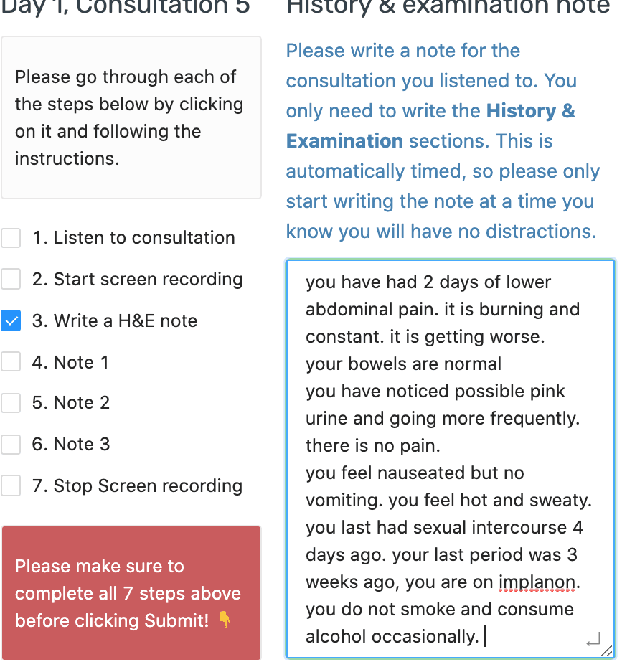
Automatic summarisation has the potential to aid physicians in streamlining clerical tasks such as note taking. But it is notoriously difficult to evaluate these systems and demonstrate that they are safe to be used in a clinical setting. To circumvent this issue, we propose a semi-automatic approach whereby physicians post-edit generated notes before submitting them. We conduct a preliminary study on the time saving of automatically generated consultation notes with post-editing. Our evaluators are asked to listen to mock consultations and to post-edit three generated notes. We time this and find that it is faster than writing the note from scratch. We present insights and lessons learnt from this experiment.