 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Policy Learning via Language Dynamics Distillation
Sep 30, 2022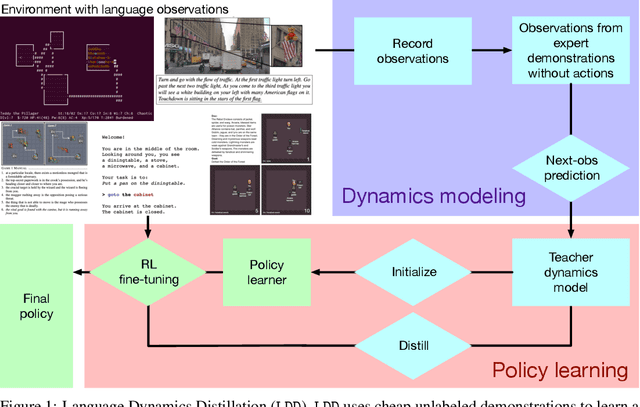
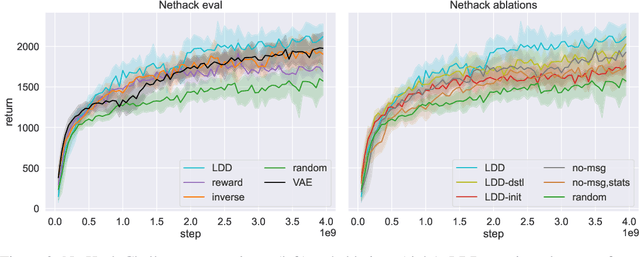
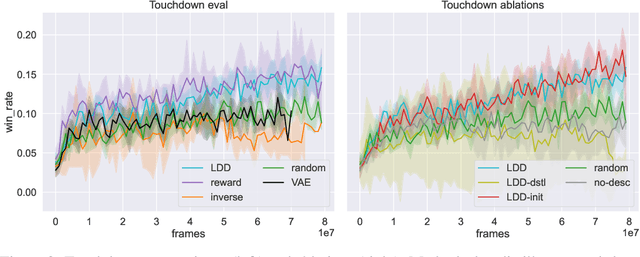
Recent work has shown that augmenting environments with language descriptions improves policy learning. However, for environments with complex language abstractions, learning how to ground language to observations is difficult due to sparse, delayed rewards. We propose Language Dynamics Distillation (LDD), which pretrains a model to predict environment dynamics given demonstrations with language descriptions, and then fine-tunes these language-aware pretrained representations via reinforcement learning (RL). In this way, the model is trained to both maximize expected reward and retain knowledge about how language relates to environment dynamics. On SILG, a benchmark of five tasks with language descriptions that evaluate distinct generalization challenges on unseen environments (NetHack, ALFWorld, RTFM, Messenger, and Touchdown), LDD outperforms tabula-rasa RL, VAE pretraining, and methods that learn from unlabeled demonstrations in inverse RL and reward shaping with pretrained experts. In our analyses, we show that language descriptions in demonstrations improve sample-efficiency and generalization across environments, and that dynamics modelling with expert demonstrations is more effective than with non-experts.
Efficient Planning in a Compact Latent Action Space
Aug 25, 2022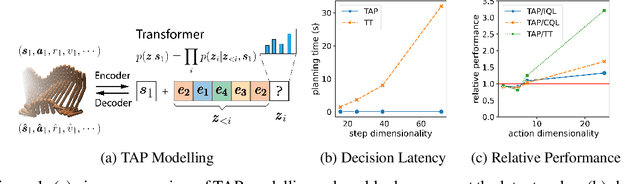
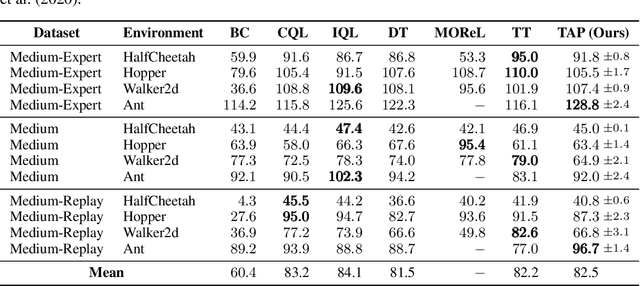
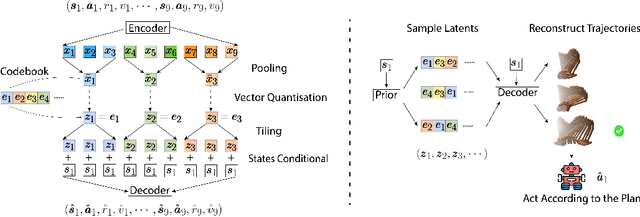
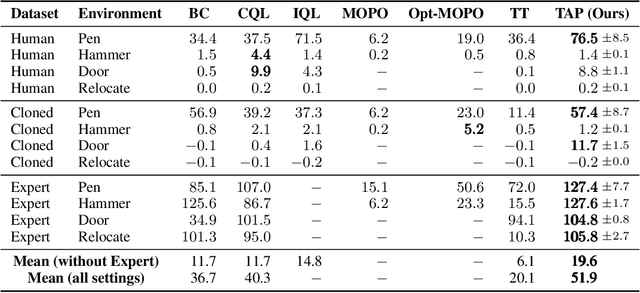
While planning-based sequence modelling methods have shown great potential in continuous control, scaling them to high-dimensional state-action sequences remains an open challenge due to the high computational complexity and innate difficulty of planning in high-dimensional spaces. We propose the Trajectory Autoencoding Planner (TAP), a planning-based sequence modelling RL method that scales to high state-action dimensionalities. Using a state-conditional Vector-Quantized Variational Autoencoder (VQ-VAE), TAP models the conditional distribution of the trajectories given the current state. When deployed as an RL agent, TAP avoids planning step-by-step in a high-dimensional continuous action space but instead looks for the optimal latent code sequences by beam search. Unlike $O(D^3)$ complexity of Trajectory Transformer, TAP enjoys constant $O(C)$ planning computational complexity regarding state-action dimensionality $D$. Our empirical evaluation also shows the increasingly strong performance of TAP with the growing dimensionality. For Adroit robotic hand manipulation tasks with high state and action dimensionality, TAP surpasses existing model-based methods, including TT, with a large margin and also beats strong model-free actor-critic baselines.
Hierarchical Kickstarting for Skill Transfer in Reinforcement Learning
Jul 23, 2022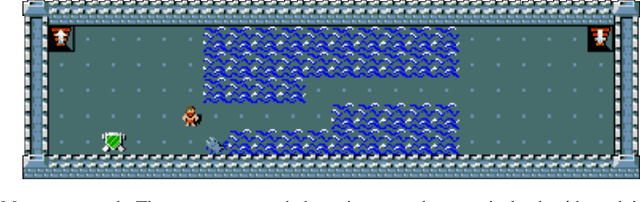

Practising and honing skills forms a fundamental component of how humans learn, yet artificial agents are rarely specifically trained to perform them. Instead, they are usually trained end-to-end, with the hope being that useful skills will be implicitly learned in order to maximise discounted return of some extrinsic reward function. In this paper, we investigate how skills can be incorporated into the training of reinforcement learning (RL) agents in complex environments with large state-action spaces and sparse rewards. To this end, we created SkillHack, a benchmark of tasks and associated skills based on the game of NetHack. We evaluate a number of baselines on this benchmark, as well as our own novel skill-based method Hierarchical Kickstarting (HKS), which is shown to outperform all other evaluated methods. Our experiments show that learning with a prior knowledge of useful skills can significantly improve the performance of agents on complex problems. We ultimately argue that utilising predefined skills provides a useful inductive bias for RL problems, especially those with large state-action spaces and sparse rewards.
Grounding Aleatoric Uncertainty in Unsupervised Environment Design
Jul 11, 2022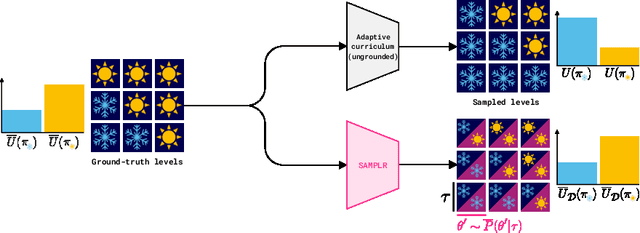
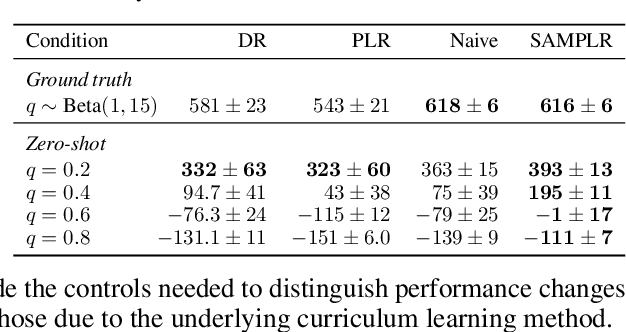
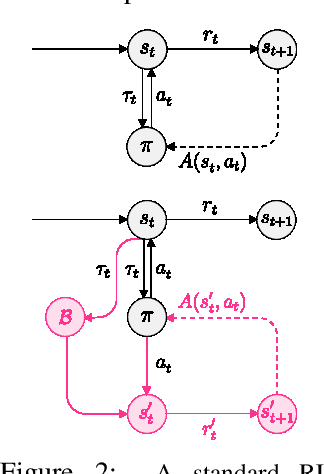
Adaptive curricula in reinforcement learning (RL) have proven effective for producing policies robust to discrepancies between the train and test environment. Recently, the Unsupervised Environment Design (UED) framework generalized RL curricula to generating sequences of entire environments, leading to new methods with robust minimax regret properties. Problematically, in partially-observable or stochastic settings, optimal policies may depend on the ground-truth distribution over aleatoric parameters of the environment in the intended deployment setting, while curriculum learning necessarily shifts the training distribution. We formalize this phenomenon as curriculum-induced covariate shift (CICS), and describe how its occurrence in aleatoric parameters can lead to suboptimal policies. Directly sampling these parameters from the ground-truth distribution avoids the issue, but thwarts curriculum learning. We propose SAMPLR, a minimax regret UED method that optimizes the ground-truth utility function, even when the underlying training data is biased due to CICS. We prove, and validate on challenging domains, that our approach preserves optimality under the ground-truth distribution, while promoting robustness across the full range of environment settings.
Graph Backup: Data Efficient Backup Exploiting Markovian Transitions
May 31, 2022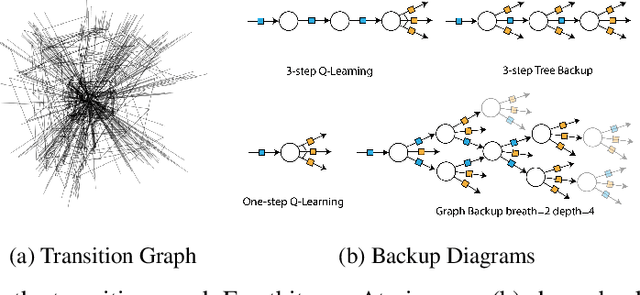
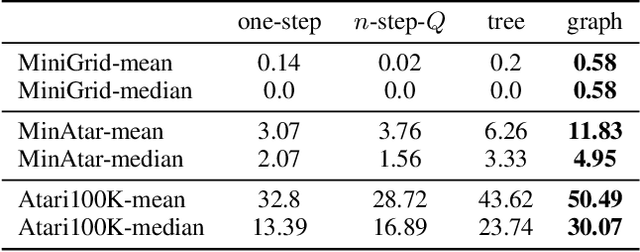
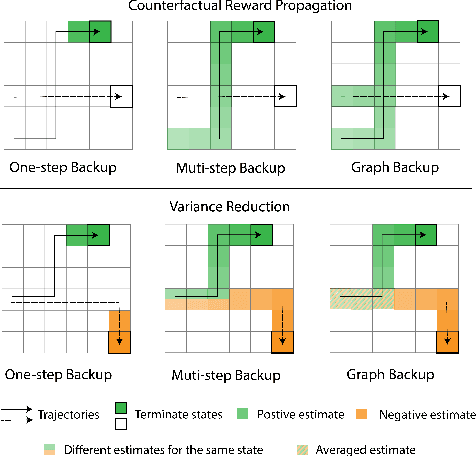
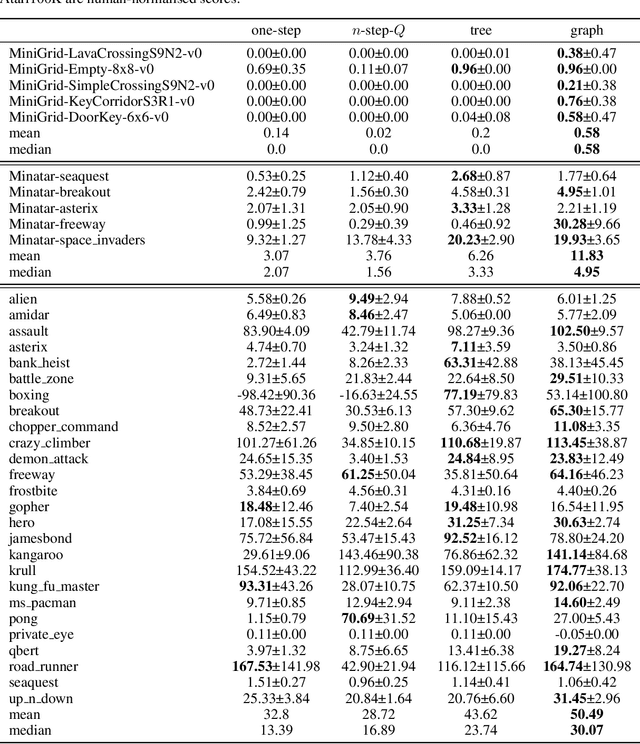
The successes of deep Reinforcement Learning (RL) are limited to settings where we have a large stream of online experiences, but applying RL in the data-efficient setting with limited access to online interactions is still challenging. A key to data-efficient RL is good value estimation, but current methods in this space fail to fully utilise the structure of the trajectory data gathered from the environment. In this paper, we treat the transition data of the MDP as a graph, and define a novel backup operator, Graph Backup, which exploits this graph structure for better value estimation. Compared to multi-step backup methods such as $n$-step $Q$-Learning and TD($\lambda$), Graph Backup can perform counterfactual credit assignment and gives stable value estimates for a state regardless of which trajectory the state is sampled from. Our method, when combined with popular value-based methods, provides improved performance over one-step and multi-step methods on a suite of data-efficient RL benchmarks including MiniGrid, Minatar and Atari100K. We further analyse the reasons for this performance boost through a novel visualisation of the transition graphs of Atari games.
Insights From the NeurIPS 2021 NetHack Challenge
Mar 22, 2022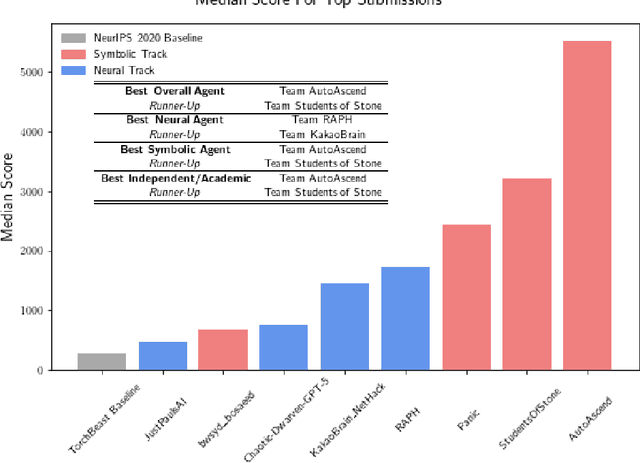

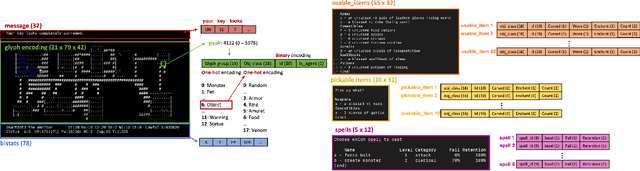
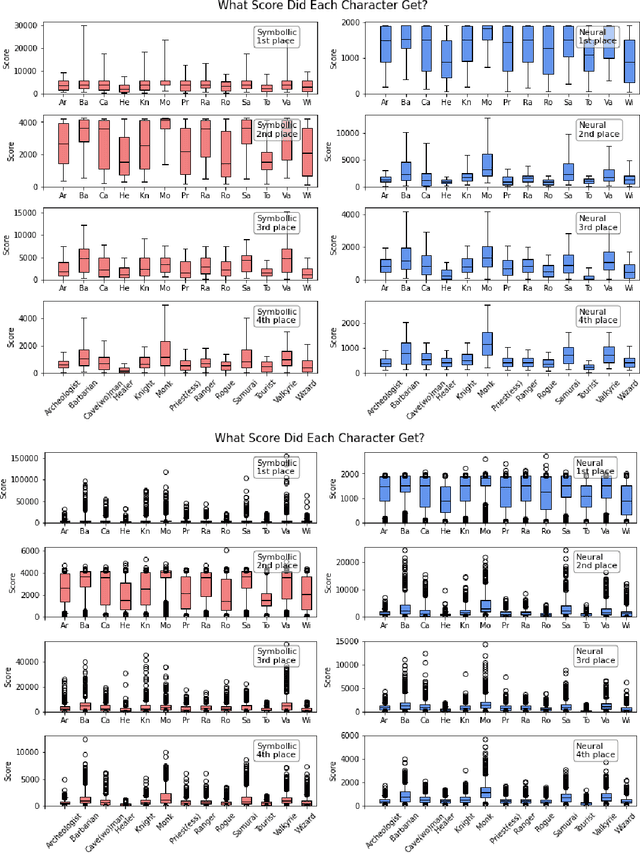
In this report, we summarize the takeaways from the first NeurIPS 2021 NetHack Challenge. Participants were tasked with developing a program or agent that can win (i.e., 'ascend' in) the popular dungeon-crawler game of NetHack by interacting with the NetHack Learning Environment (NLE), a scalable, procedurally generated, and challenging Gym environment for reinforcement learning (RL). The challenge showcased community-driven progress in AI with many diverse approaches significantly beating the previously best results on NetHack. Furthermore, it served as a direct comparison between neural (e.g., deep RL) and symbolic AI, as well as hybrid systems, demonstrating that on NetHack symbolic bots currently outperform deep RL by a large margin. Lastly, no agent got close to winning the game, illustrating NetHack's suitability as a long-term benchmark for AI research.
Evolving Curricula with Regret-Based Environment Design
Mar 08, 2022

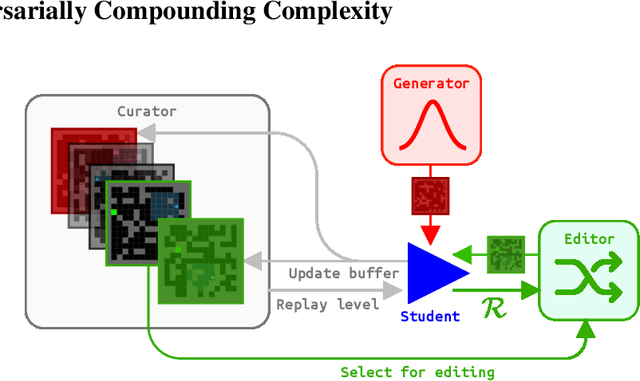
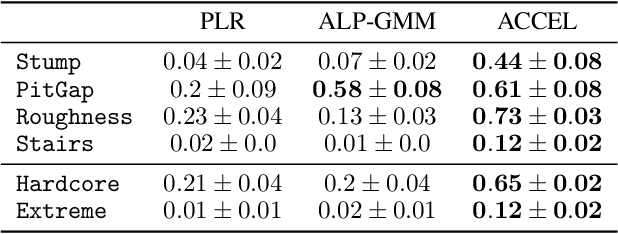
It remains a significant challenge to train generally capable agents with reinforcement learning (RL). A promising avenue for improving the robustness of RL agents is through the use of curricula. One such class of methods frames environment design as a game between a student and a teacher, using regret-based objectives to produce environment instantiations (or levels) at the frontier of the student agent's capabilities. These methods benefit from their generality, with theoretical guarantees at equilibrium, yet they often struggle to find effective levels in challenging design spaces. By contrast, evolutionary approaches seek to incrementally alter environment complexity, resulting in potentially open-ended learning, but often rely on domain-specific heuristics and vast amounts of computational resources. In this paper we propose to harness the power of evolution in a principled, regret-based curriculum. Our approach, which we call Adversarially Compounding Complexity by Editing Levels (ACCEL), seeks to constantly produce levels at the frontier of an agent's capabilities, resulting in curricula that start simple but become increasingly complex. ACCEL maintains the theoretical benefits of prior regret-based methods, while providing significant empirical gains in a diverse set of environments. An interactive version of the paper is available at accelagent.github.io.
Improving Intrinsic Exploration with Language Abstractions
Feb 17, 2022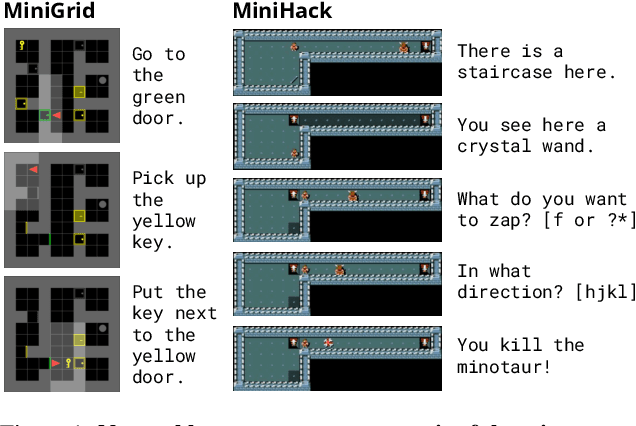
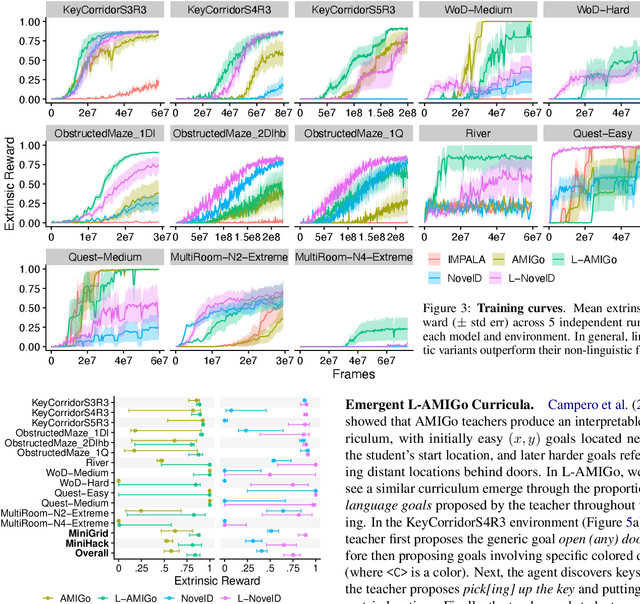
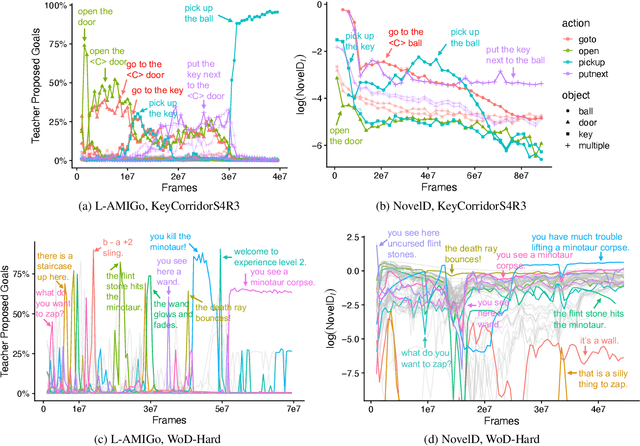
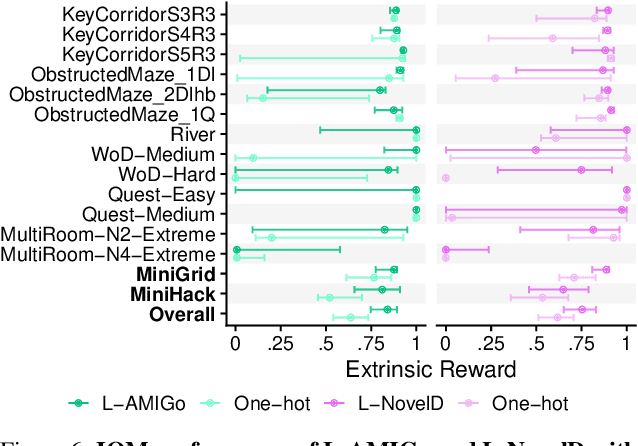
Reinforcement learning (RL) agents are particularly hard to train when rewards are sparse. One common solution is to use intrinsic rewards to encourage agents to explore their environment. However, recent intrinsic exploration methods often use state-based novelty measures which reward low-level exploration and may not scale to domains requiring more abstract skills. Instead, we explore natural language as a general medium for highlighting relevant abstractions in an environment. Unlike previous work, we evaluate whether language can improve over existing exploration methods by directly extending (and comparing to) competitive intrinsic exploration baselines: AMIGo (Campero et al., 2021) and NovelD (Zhang et al., 2021). These language-based variants outperform their non-linguistic forms by 45-85% across 13 challenging tasks from the MiniGrid and MiniHack environment suites.
A Survey of Generalisation in Deep Reinforcement Learning
Nov 18, 2021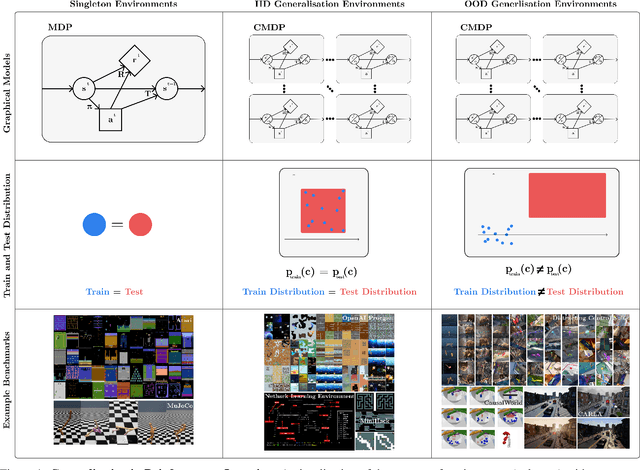
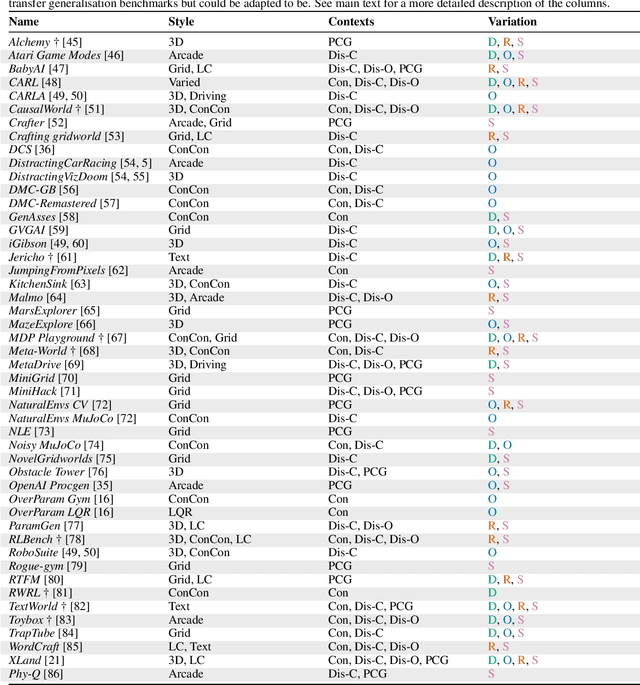
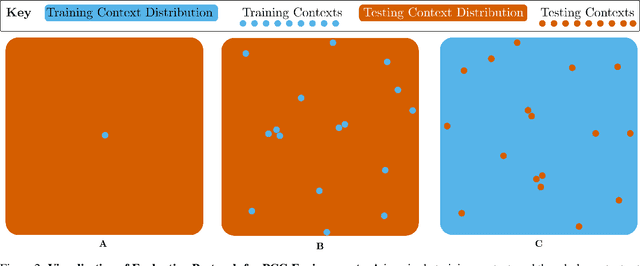
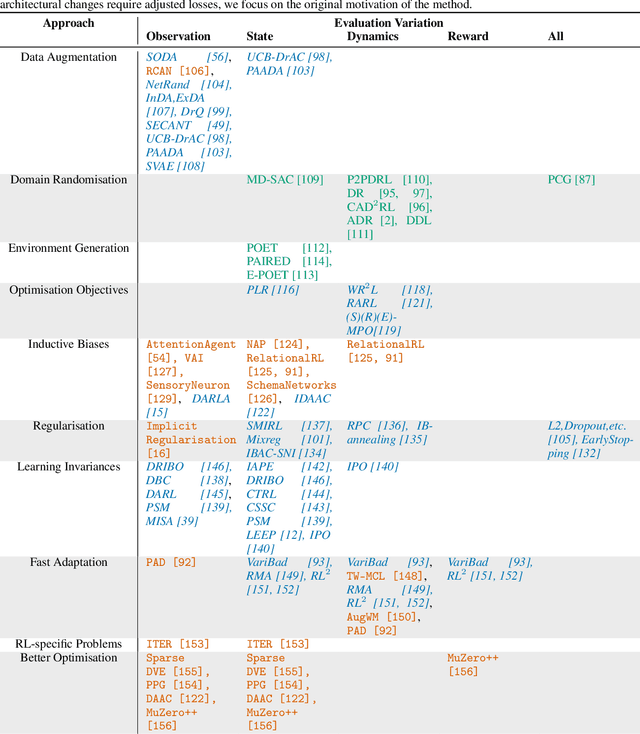
The study of generalisation in deep Reinforcement Learning (RL) aims to produce RL algorithms whose policies generalise well to novel unseen situations at deployment time, avoiding overfitting to their training environments. Tackling this is vital if we are to deploy reinforcement learning algorithms in real world scenarios, where the environment will be diverse, dynamic and unpredictable. This survey is an overview of this nascent field. We provide a unifying formalism and terminology for discussing different generalisation problems, building upon previous works. We go on to categorise existing benchmarks for generalisation, as well as current methods for tackling the generalisation problem. Finally, we provide a critical discussion of the current state of the field, including recommendations for future work. Among other conclusions, we argue that taking a purely procedural content generation approach to benchmark design is not conducive to progress in generalisation, we suggest fast online adaptation and tackling RL-specific problems as some areas for future work on methods for generalisation, and we recommend building benchmarks in underexplored problem settings such as offline RL generalisation and reward-function variation.
Replay-Guided Adversarial Environment Design
Oct 06, 2021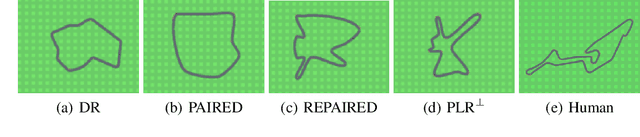
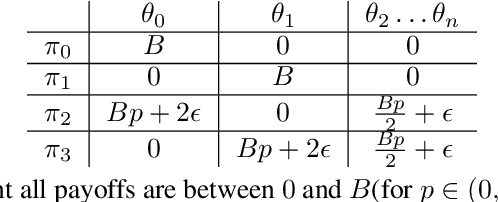
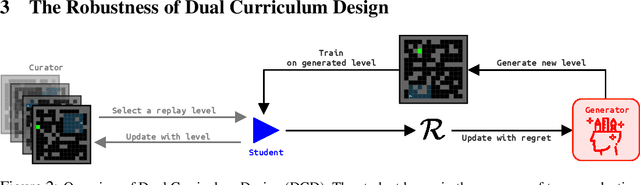
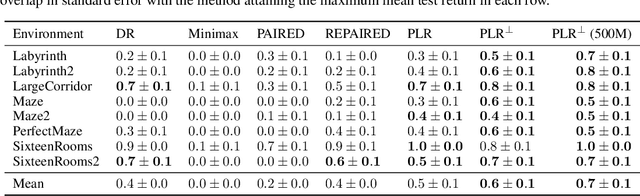
Deep reinforcement learning (RL) agents may successfully generalize to new settings if trained on an appropriately diverse set of environment and task configurations. Unsupervised Environment Design (UED) is a promising self-supervised RL paradigm, wherein the free parameters of an underspecified environment are automatically adapted during training to the agent's capabilities, leading to the emergence of diverse training environments. Here, we cast Prioritized Level Replay (PLR), an empirically successful but theoretically unmotivated method that selectively samples randomly-generated training levels, as UED. We argue that by curating completely random levels, PLR, too, can generate novel and complex levels for effective training. This insight reveals a natural class of UED methods we call Dual Curriculum Design (DCD). Crucially, DCD includes both PLR and a popular UED algorithm, PAIRED, as special cases and inherits similar theoretical guarantees. This connection allows us to develop novel theory for PLR, providing a version with a robustness guarantee at Nash equilibria. Furthermore, our theory suggests a highly counterintuitive improvement to PLR: by stopping the agent from updating its policy on uncurated levels (training on less data), we can improve the convergence to Nash equilibria. Indeed, our experiments confirm that our new method, PLR$^{\perp}$, obtains better results on a suite of out-of-distribution, zero-shot transfer tasks, in addition to demonstrating that PLR$^{\perp}$ improves the performance of PAIRED, from which it inherited its theoretical framework.