 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge$\textbf{A}^2\textbf{CiD}^2$: Accelerating Asynchronous Communication in Decentralized Deep Learning
Jun 14, 2023



Distributed training of Deep Learning models has been critical to many recent successes in the field. Current standard methods primarily rely on synchronous centralized algorithms which induce major communication bottlenecks and limit their usability to High-Performance Computing (HPC) environments with strong connectivity. Decentralized asynchronous algorithms are emerging as a potential alternative but their practical applicability still lags. In this work, we focus on peerto-peer asynchronous methods due to their flexibility and parallelization potentials. In order to mitigate the increase in bandwidth they require at large scale and in poorly connected contexts, we introduce a principled asynchronous, randomized, gossip-based algorithm which works thanks to a continuous momentum named $\textbf{A}^2\textbf{CiD}^2$. In addition to inducing a significant communication acceleration at no cost other than doubling the parameters, minimal adaptation is required to incorporate $\textbf{A}^2\textbf{CiD}^2$ to other asynchronous approaches. We demonstrate its efficiency theoretically and numerically. Empirically on the ring graph, adding $\textbf{A}^2\textbf{CiD}^2$ has the same effect as doubling the communication rate. In particular, we show consistent improvement on the ImageNet dataset using up to 64 asynchronous workers (A100 GPUs) and various communication network topologies.
Can Forward Gradient Match Backpropagation?
Jun 12, 2023Forward Gradients - the idea of using directional derivatives in forward differentiation mode - have recently been shown to be utilizable for neural network training while avoiding problems generally associated with backpropagation gradient computation, such as locking and memorization requirements. The cost is the requirement to guess the step direction, which is hard in high dimensions. While current solutions rely on weighted averages over isotropic guess vector distributions, we propose to strongly bias our gradient guesses in directions that are much more promising, such as feedback obtained from small, local auxiliary networks. For a standard computer vision neural network, we conduct a rigorous study systematically covering a variety of combinations of gradient targets and gradient guesses, including those previously presented in the literature. We find that using gradients obtained from a local loss as a candidate direction drastically improves on random noise in Forward Gradient methods.
Guiding The Last Layer in Federated Learning with Pre-Trained Models
Jun 06, 2023



Federated Learning (FL) is an emerging paradigm that allows a model to be trained across a number of participants without sharing data. Recent works have begun to consider the effects of using pre-trained models as an initialization point for existing FL algorithms; however, these approaches ignore the vast body of efficient transfer learning literature from the centralized learning setting. Here we revisit the problem of FL from a pre-trained model considered in prior work and expand it to a set of computer vision transfer learning problems. We first observe that simply fitting a linear classification head can be efficient and effective in many cases. We then show that in the FL setting, fitting a classifier using the Nearest Class Means (NCM) can be done exactly and orders of magnitude more efficiently than existing proposals, while obtaining strong performance. Finally, we demonstrate that using a two-phase approach of obtaining the classifier and then fine-tuning the model can yield rapid convergence and improved generalization in the federated setting. We demonstrate the potential our method has to reduce communication and compute costs while achieving better model performance.
DADAO: Decoupled Accelerated Decentralized Asynchronous Optimization for Time-Varying Gossips
Jul 26, 2022
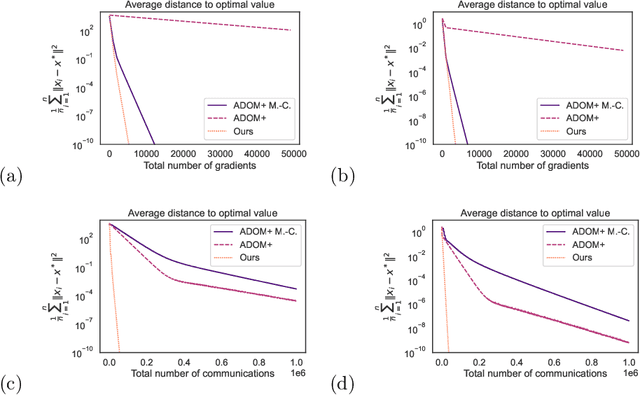

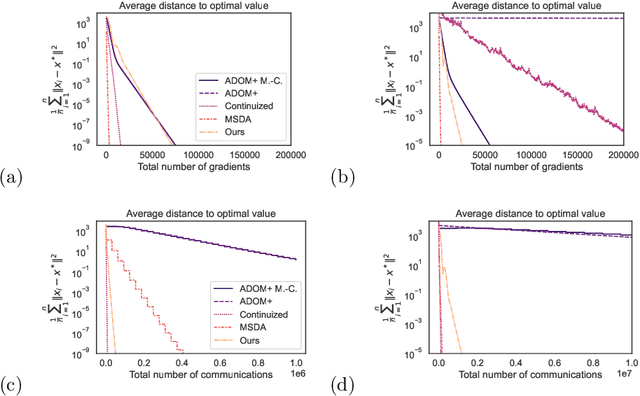
DADAO is a novel decentralized asynchronous stochastic algorithm to minimize a sum of $L$-smooth and $\mu$-strongly convex functions distributed over a time-varying connectivity network of size $n$. We model the local gradient updates and gossip communication procedures with separate independent Poisson Point Processes, decoupling the computation and communication steps in addition to making the whole approach completely asynchronous. Our method employs primal gradients and do not use a multi-consensus inner loop nor other ad-hoc mechanisms as Error Feedback, Gradient Tracking or a Proximal operator. By relating spatial quantities of our graphs $\chi^*_1,\chi_2^*$ to a necessary minimal communication rate between nodes of the network, we show that our algorithm requires $\mathcal{O}(n\sqrt{\frac{L}{\mu}}\log \epsilon)$ local gradients and only $\mathcal{O}(n\sqrt{\chi_1^*\chi_2^*}\sqrt{\frac{L}{\mu}}\log \epsilon)$ communications to reach a precision $\epsilon$. If SGD with uniform noise $\sigma^2$ is used, we reach a precision $\epsilon$ with same speed, up to a bias term in $\mathcal{O}(\frac{\sigma^2}{\sqrt{\mu L}})$. This improves upon the bounds obtained with current state-of-the-art approaches, our simulations validating the strength of our relatively unconstrained method. Our source-code is released on a public repository.
Why do tree-based models still outperform deep learning on tabular data?
Jul 18, 2022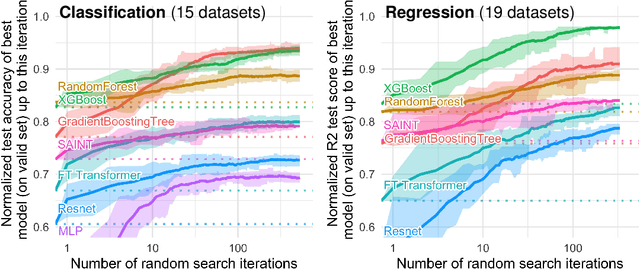
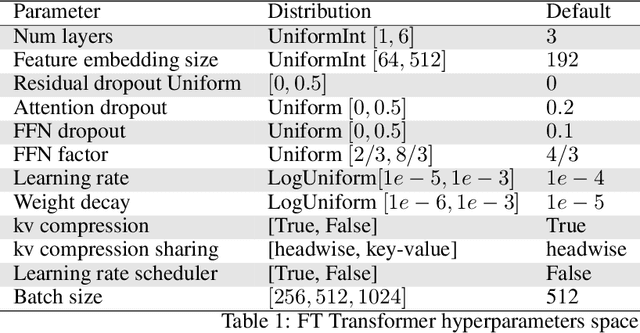
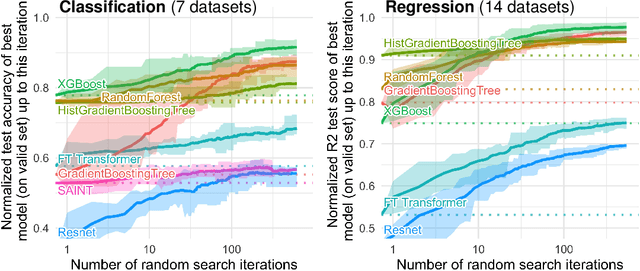
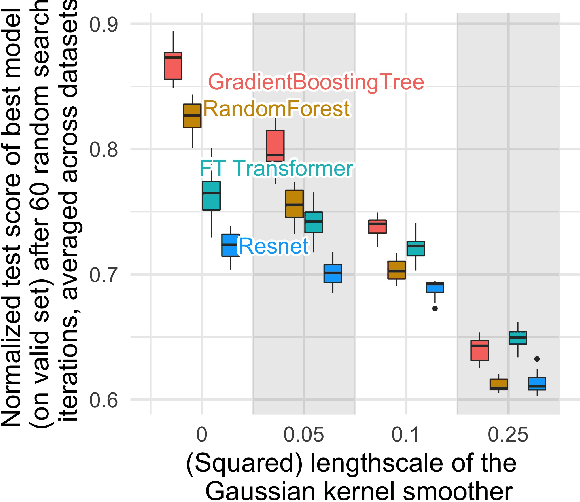
While deep learning has enabled tremendous progress on text and image datasets, its superiority on tabular data is not clear. We contribute extensive benchmarks of standard and novel deep learning methods as well as tree-based models such as XGBoost and Random Forests, across a large number of datasets and hyperparameter combinations. We define a standard set of 45 datasets from varied domains with clear characteristics of tabular data and a benchmarking methodology accounting for both fitting models and finding good hyperparameters. Results show that tree-based models remain state-of-the-art on medium-sized data ($\sim$10K samples) even without accounting for their superior speed. To understand this gap, we conduct an empirical investigation into the differing inductive biases of tree-based models and Neural Networks (NNs). This leads to a series of challenges which should guide researchers aiming to build tabular-specific NNs: 1. be robust to uninformative features, 2. preserve the orientation of the data, and 3. be able to easily learn irregular functions. To stimulate research on tabular architectures, we contribute a standard benchmark and raw data for baselines: every point of a 20 000 compute hours hyperparameter search for each learner.
On Non-Linear operators for Geometric Deep Learning
Jul 06, 2022This work studies operators mapping vector and scalar fields defined over a manifold $\mathcal{M}$, and which commute with its group of diffeomorphisms $\text{Diff}(\mathcal{M})$. We prove that in the case of scalar fields $L^p_\omega(\mathcal{M,\mathbb{R}})$, those operators correspond to point-wise non-linearities, recovering and extending known results on $\mathbb{R}^d$. In the context of Neural Networks defined over $\mathcal{M}$, it indicates that point-wise non-linear operators are the only universal family that commutes with any group of symmetries, and justifies their systematic use in combination with dedicated linear operators commuting with specific symmetries. In the case of vector fields $L^p_\omega(\mathcal{M},T\mathcal{M})$, we show that those operators are solely the scalar multiplication. It indicates that $\text{Diff}(\mathcal{M})$ is too rich and that there is no universal class of non-linear operators to motivate the design of Neural Networks over the symmetries of $\mathcal{M}$.
Gradient Masked Averaging for Federated Learning
Jan 28, 2022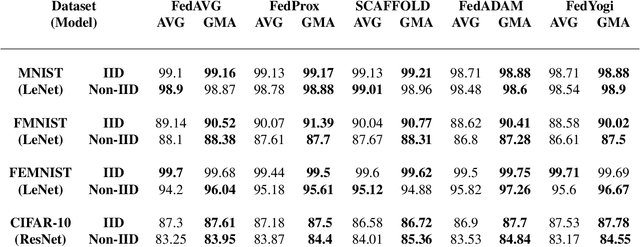
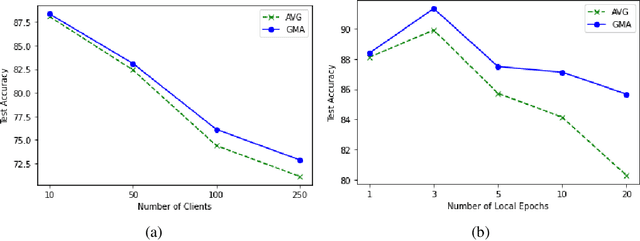
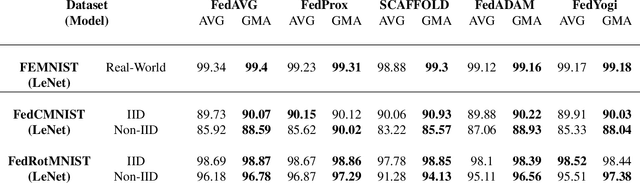
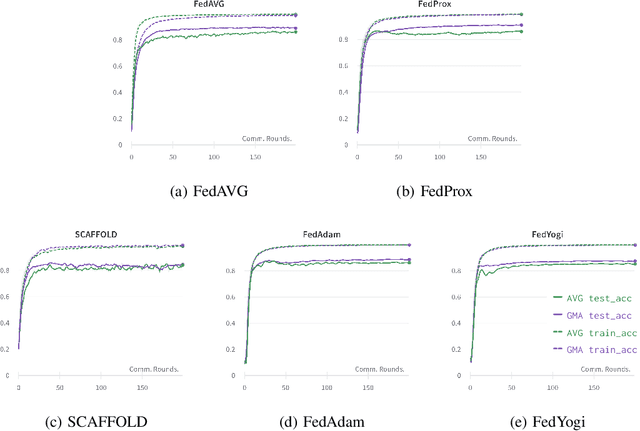
Federated learning is an emerging paradigm that permits a large number of clients with heterogeneous data to coordinate learning of a unified global model without the need to share data amongst each other. Standard federated learning algorithms involve averaging of model parameters or gradient updates to approximate the global model at the server. However, in heterogeneous settings averaging can result in information loss and lead to poor generalization due to the bias induced by dominant clients. We hypothesize that to generalize better across non-i.i.d datasets as in FL settings, the algorithms should focus on learning the invariant mechanism that is constant while ignoring spurious mechanisms that differ across clients. Inspired from recent work in the Out-of-Distribution literature, we propose a gradient masked averaging approach for federated learning as an alternative to the standard averaging of client updates. This client update aggregation technique can be adapted as a drop-in replacement in most existing federated algorithms. We perform extensive experiments with gradient masked approach on multiple FL algorithms with in-distribution, real-world, and out-of-distribution (as the worst case scenario) test dataset and show that it provides consistent improvements, particularly in the case of heterogeneous clients.
Deep Reinforcement Learning for L3 Slice Localization in Sarcopenia Assessment
Aug 13, 2021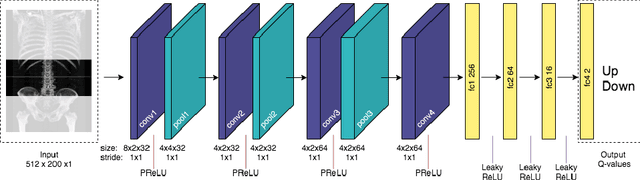
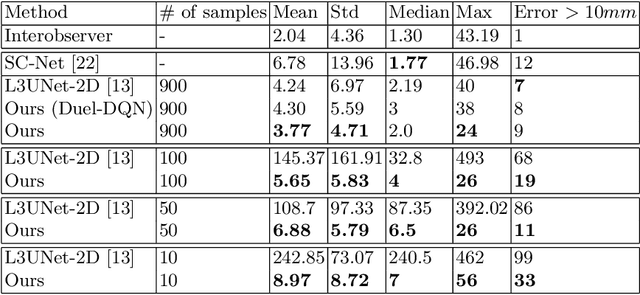
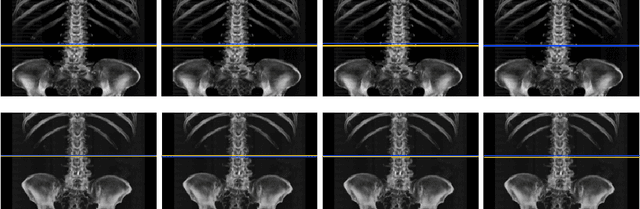
Sarcopenia is a medical condition characterized by a reduction in muscle mass and function. A quantitative diagnosis technique consists of localizing the CT slice passing through the middle of the third lumbar area (L3) and segmenting muscles at this level. In this paper, we propose a deep reinforcement learning method for accurate localization of the L3 CT slice. Our method trains a reinforcement learning agent by incentivizing it to discover the right position. Specifically, a Deep Q-Network is trained to find the best policy to follow for this problem. Visualizing the training process shows that the agent mimics the scrolling of an experienced radiologist. Extensive experiments against other state-of-the-art deep learning based methods for L3 localization prove the superiority of our technique which performs well even with a limited amount of data and annotations.
Decoupled Greedy Learning of CNNs for Synchronous and Asynchronous Distributed Learning
Jun 11, 2021



A commonly cited inefficiency of neural network training using back-propagation is the update locking problem: each layer must wait for the signal to propagate through the full network before updating. Several alternatives that can alleviate this issue have been proposed. In this context, we consider a simple alternative based on minimal feedback, which we call Decoupled Greedy Learning (DGL). It is based on a classic greedy relaxation of the joint training objective, recently shown to be effective in the context of Convolutional Neural Networks (CNNs) on large-scale image classification. We consider an optimization of this objective that permits us to decouple the layer training, allowing for layers or modules in networks to be trained with a potentially linear parallelization. With the use of a replay buffer we show that this approach can be extended to asynchronous settings, where modules can operate and continue to update with possibly large communication delays. To address bandwidth and memory issues we propose an approach based on online vector quantization. This allows to drastically reduce the communication bandwidth between modules and required memory for replay buffers. We show theoretically and empirically that this approach converges and compare it to the sequential solvers. We demonstrate the effectiveness of DGL against alternative approaches on the CIFAR-10 dataset and on the large-scale ImageNet dataset.
Interferometric Graph Transform for Community Labeling
Jun 04, 2021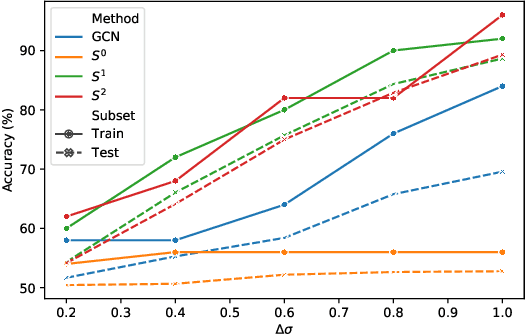
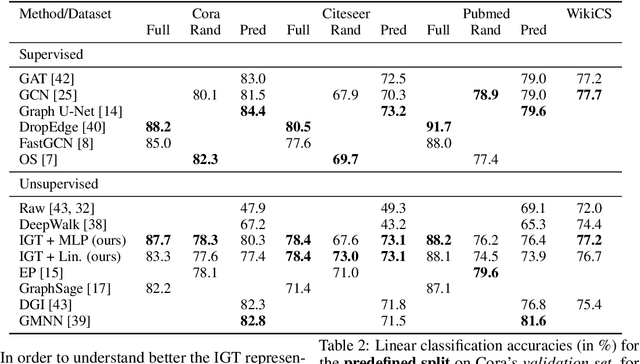

We present a new approach for learning unsupervised node representations in community graphs. We significantly extend the Interferometric Graph Transform (IGT) to community labeling: this non-linear operator iteratively extracts features that take advantage of the graph topology through demodulation operations. An unsupervised feature extraction step cascades modulus non-linearity with linear operators that aim at building relevant invariants for community labeling. Via a simplified model, we show that the IGT concentrates around the E-IGT: those two representations are related through some ergodicity properties. Experiments on community labeling tasks show that this unsupervised representation achieves performances at the level of the state of the art on the standard and challenging datasets Cora, Citeseer, Pubmed and WikiCS.