 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Complement Humans
May 01, 2020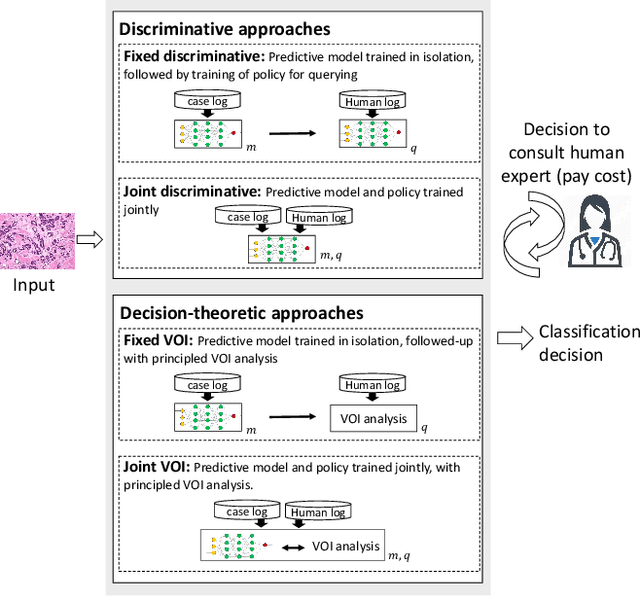
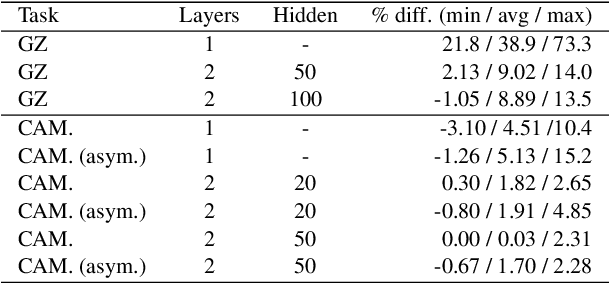
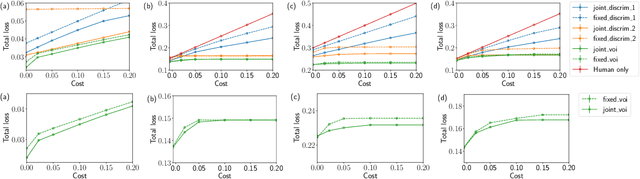
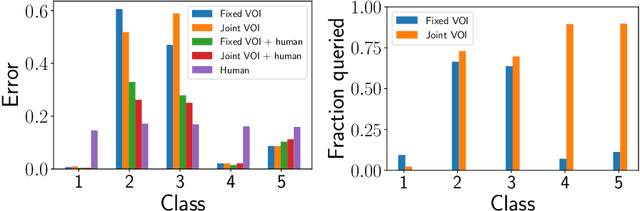
A rising vision for AI in the open world centers on the development of systems that can complement humans for perceptual, diagnostic, and reasoning tasks. To date, systems aimed at complementing the skills of people have employed models trained to be as accurate as possible in isolation. We demonstrate how an end-to-end learning strategy can be harnessed to optimize the combined performance of human-machine teams by considering the distinct abilities of people and machines. The goal is to focus machine learning on problem instances that are difficult for humans, while recognizing instances that are difficult for the machine and seeking human input on them. We demonstrate in two real-world domains (scientific discovery and medical diagnosis) that human-machine teams built via these methods outperform the individual performance of machines and people. We then analyze conditions under which this complementarity is strongest, and which training methods amplify it. Taken together, our work provides the first systematic investigation of how machine learning systems can be trained to complement human reasoning.
Optimizing AI for Teamwork
Apr 27, 2020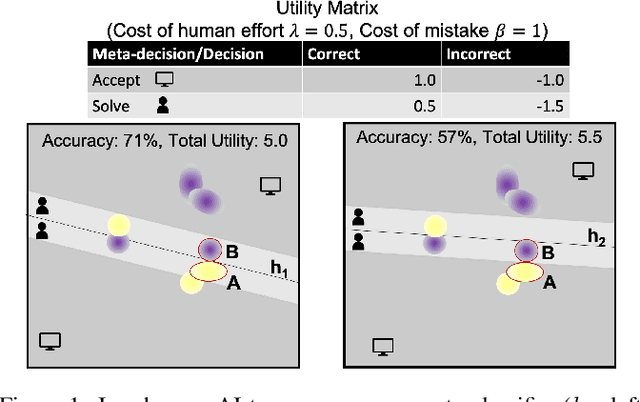
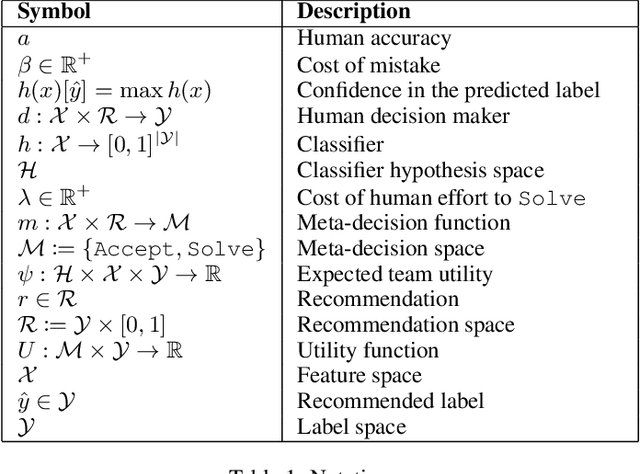
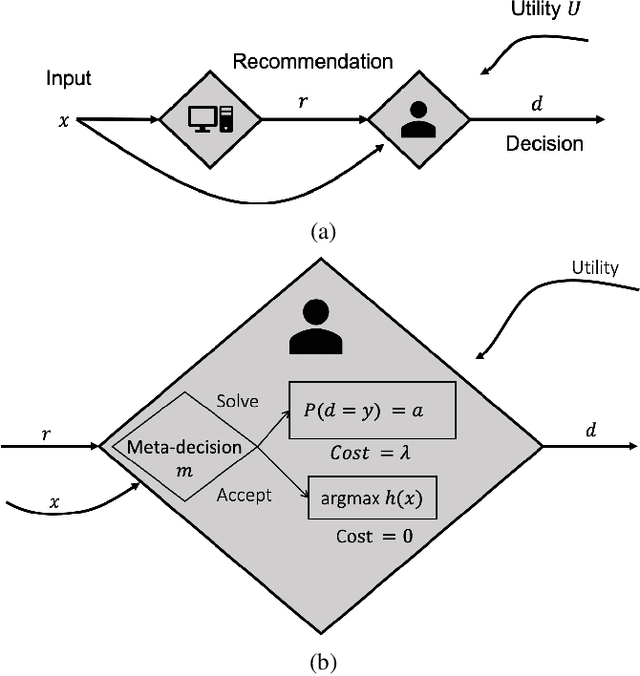
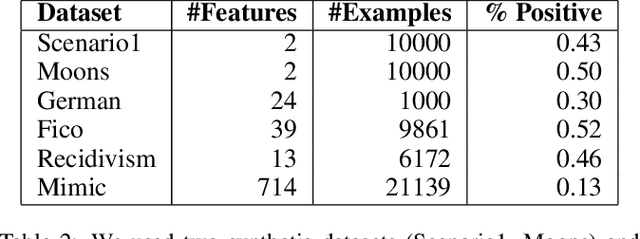
In many high-stakes domains such as criminal justice, finance, and healthcare, AI systems may recommend actions to a human expert responsible for final decisions, a context known as AI-advised decision making. When AI practitioners deploy the most accurate system in these domains, they implicitly assume that the system will function alone in the world. We argue that the most accurate AI team-mate is not necessarily the em best teammate; for example, predictable performance is worth a slight sacrifice in AI accuracy. So, we propose training AI systems in a human-centered manner and directly optimizing for team performance. We study this proposal for a specific type of human-AI team, where the human overseer chooses to accept the AI recommendation or solve the task themselves. To optimize the team performance we maximize the team's expected utility, expressed in terms of quality of the final decision, cost of verifying, and individual accuracies. Our experiments with linear and non-linear models on real-world, high-stakes datasets show that the improvements in utility while being small and varying across datasets and parameters (such as cost of mistake), are real and consistent with our definition of team utility. We discuss the shortcoming of current optimization approaches beyond well-studied loss functions such as log-loss, and encourage future work on human-centered optimization problems motivated by human-AI collaborations.
Personalization in Human-AI Teams: Improving the Compatibility-Accuracy Tradeoff
Apr 05, 2020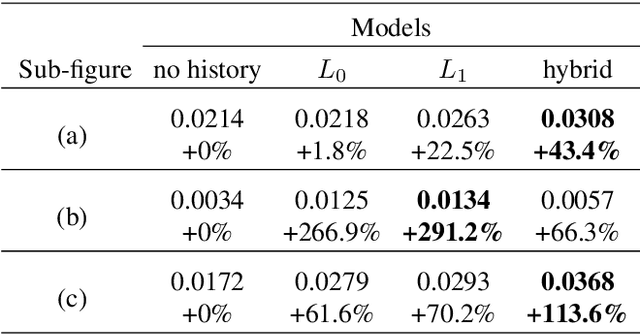
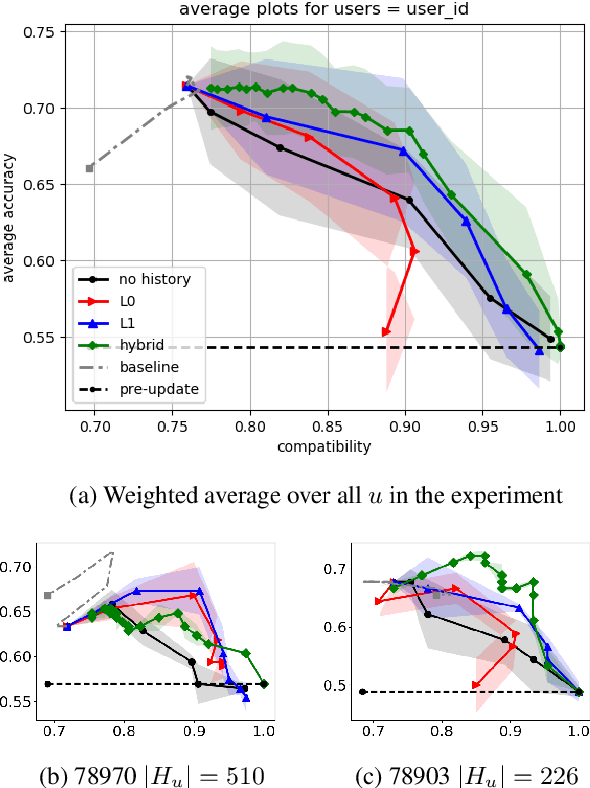
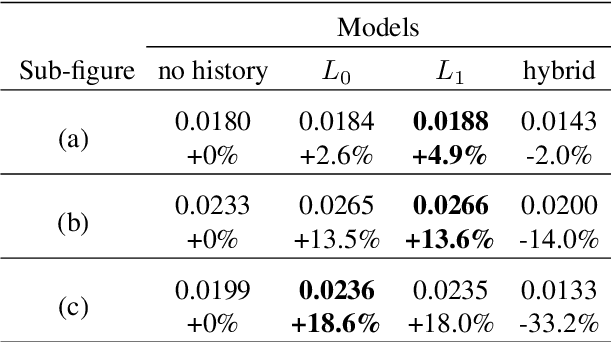
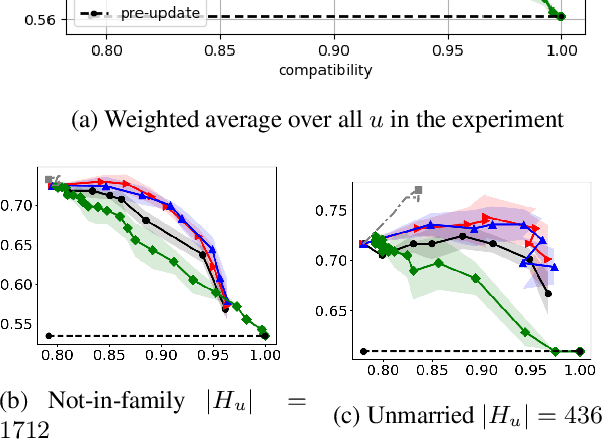
AI systems that model and interact with users can update their models over time to reflect new information and changes in the environment. Although these updates can improve the performance of the AI system, they may actually hurt the performance for individual users. Prior work has studied the trade-off between improving the system accuracy following an update and the compatibility of the update with prior user experience. The more the model is forced to be compatible with prior updates, the higher loss in accuracy it will incur. In this paper, we show that in some cases it is possible to improve this compatibility-accuracy trade-off relative to a specific user by employing new error functions for the AI updates that personalize the weight updates to be compatible with the user's history of interaction with the system and present experimental results indicating that this approach provides major improvements to certain users.
SQuINTing at VQA Models: Interrogating VQA Models with Sub-Questions
Jan 20, 2020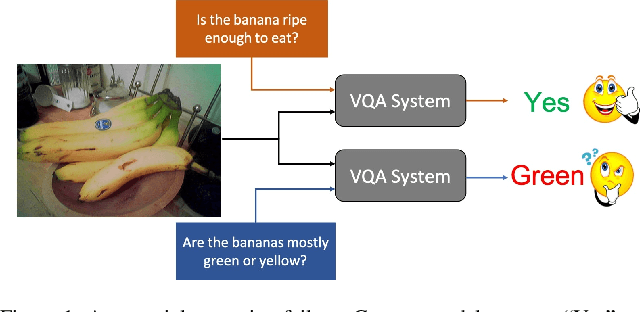

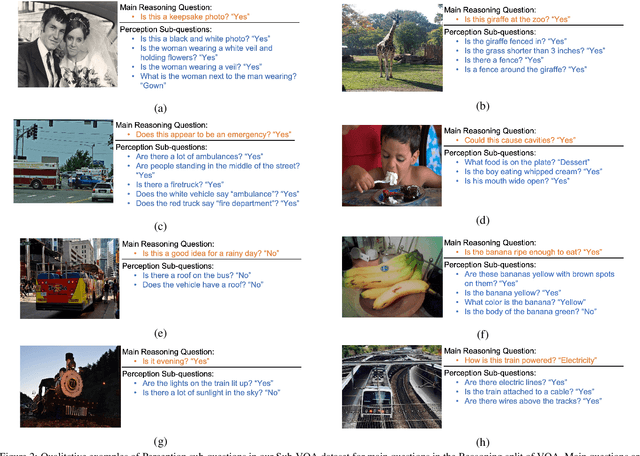
Existing VQA datasets contain questions with varying levels of complexity. While the majority of questions in these datasets require perception for recognizing existence, properties, and spatial relationships of entities, a significant portion of questions pose challenges that correspond to reasoning tasks -- tasks that can only be answered through a synthesis of perception and knowledge about the world, logic and / or reasoning. This distinction allows us to notice when existing VQA models have consistency issues -- they answer the reasoning question correctly but fail on associated low-level perception questions. For example, models answer the complex reasoning question "Is the banana ripe enough to eat?" correctly, but fail on the associated perception question "Are the bananas mostly green or yellow?" indicating that the model likely answered the reasoning question correctly but for the wrong reason. We quantify the extent to which this phenomenon occurs by creating a new Reasoning split of the VQA dataset and collecting Sub-VQA, a new dataset consisting of 200K new perception questions which serve as sub questions corresponding to the set of perceptual tasks needed to effectively answer the complex reasoning questions in the Reasoning split. Additionally, we propose an approach called Sub-Question Importance-aware Network Tuning (SQuINT), which encourages the model to attend do the same parts of the image when answering the reasoning question and the perception sub questions. We show that SQuINT improves model consistency by 7.8%, also marginally improving its performance on the Reasoning questions in VQA, while also displaying qualitatively better attention maps.
What You See Is What You Get? The Impact of Representation Criteria on Human Bias in Hiring
Sep 08, 2019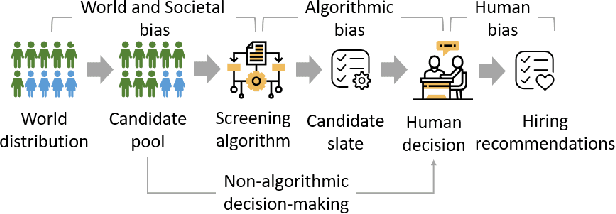
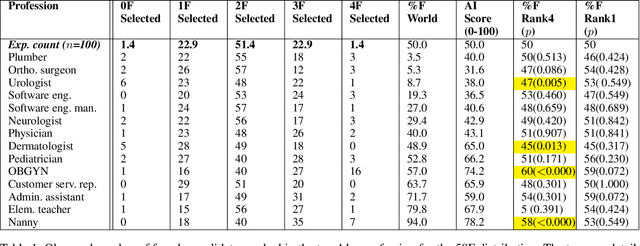
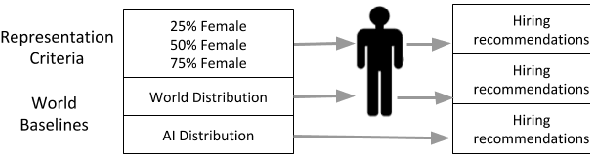
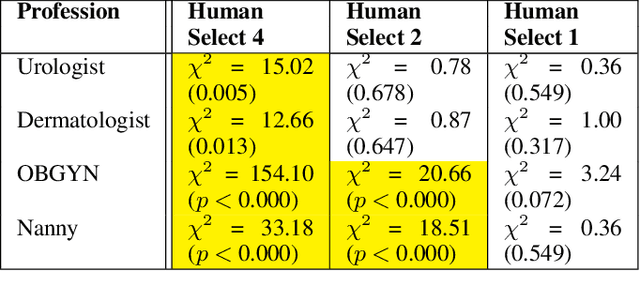
Although systematic biases in decision-making are widely documented, the ways in which they emerge from different sources is less understood. We present a controlled experimental platform to study gender bias in hiring by decoupling the effect of world distribution (the gender breakdown of candidates in a specific profession) from bias in human decision-making. We explore the effectiveness of \textit{representation criteria}, fixed proportional display of candidates, as an intervention strategy for mitigation of gender bias by conducting experiments measuring human decision-makers' rankings for who they would recommend as potential hires. Experiments across professions with varying gender proportions show that balancing gender representation in candidate slates can correct biases for some professions where the world distribution is skewed, although doing so has no impact on other professions where human persistent preferences are at play. We show that the gender of the decision-maker, complexity of the decision-making task and over- and under-representation of genders in the candidate slate can all impact the final decision. By decoupling sources of bias, we can better isolate strategies for bias mitigation in human-in-the-loop systems.
Toward Fairness in AI for People with Disabilities: A Research Roadmap
Aug 02, 2019AI technologies have the potential to dramatically impact the lives of people with disabilities (PWD). Indeed, improving the lives of PWD is a motivator for many state-of-the-art AI systems, such as automated speech recognition tools that can caption videos for people who are deaf and hard of hearing, or language prediction algorithms that can augment communication for people with speech or cognitive disabilities. However, widely deployed AI systems may not work properly for PWD, or worse, may actively discriminate against them. These considerations regarding fairness in AI for PWD have thus far received little attention. In this position paper, we identify potential areas of concern regarding how several AI technology categories may impact particular disability constituencies if care is not taken in their design, development, and testing. We intend for this risk assessment of how various classes of AI might interact with various classes of disability to provide a roadmap for future research that is needed to gather data, test these hypotheses, and build more inclusive algorithms.
A Case for Backward Compatibility for Human-AI Teams
Jun 04, 2019
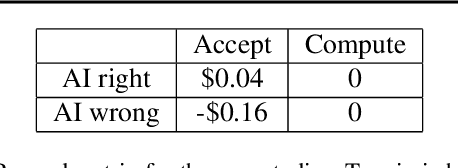
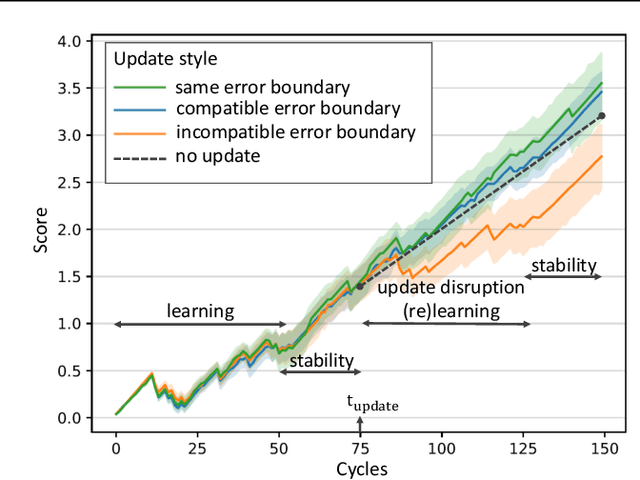
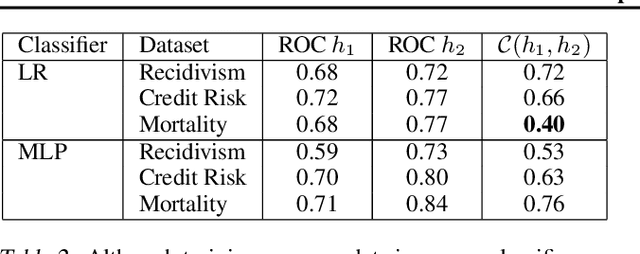
AI systems are being deployed to support human decision making in high-stakes domains. In many cases, the human and AI form a team, in which the human makes decisions after reviewing the AI's inferences. A successful partnership requires that the human develops insights into the performance of the AI system, including its failures. We study the influence of updates to an AI system in this setting. While updates can increase the AI's predictive performance, they may also lead to changes that are at odds with the user's prior experiences and confidence in the AI's inferences, hurting therefore the overall team performance. We introduce the notion of the compatibility of an AI update with prior user experience and present methods for studying the role of compatibility in human-AI teams. Empirical results on three high-stakes domains show that current machine learning algorithms do not produce compatible updates. We propose a re-training objective to improve the compatibility of an update by penalizing new errors. The objective offers full leverage of the performance/compatibility tradeoff, enabling more compatible yet accurate updates.
Towards Accountable AI: Hybrid Human-Machine Analyses for Characterizing System Failure
Sep 19, 2018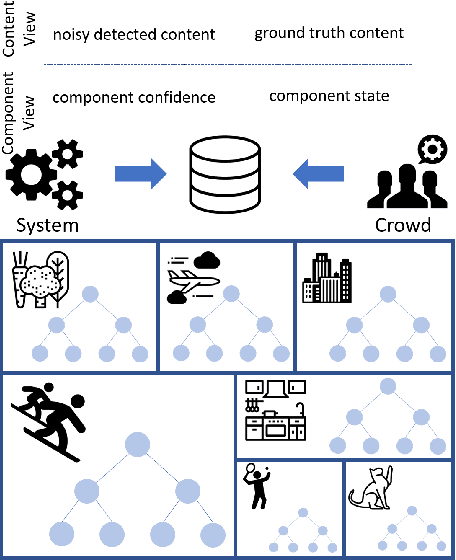


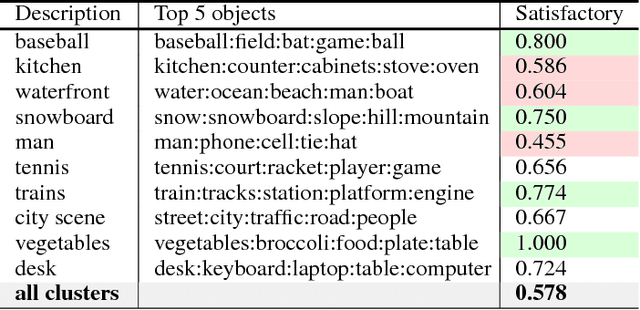
As machine learning systems move from computer-science laboratories into the open world, their accountability becomes a high priority problem. Accountability requires deep understanding of system behavior and its failures. Current evaluation methods such as single-score error metrics and confusion matrices provide aggregate views of system performance that hide important shortcomings. Understanding details about failures is important for identifying pathways for refinement, communicating the reliability of systems in different settings, and for specifying appropriate human oversight and engagement. Characterization of failures and shortcomings is particularly complex for systems composed of multiple machine learned components. For such systems, existing evaluation methods have limited expressiveness in describing and explaining the relationship among input content, the internal states of system components, and final output quality. We present Pandora, a set of hybrid human-machine methods and tools for describing and explaining system failures. Pandora leverages both human and system-generated observations to summarize conditions of system malfunction with respect to the input content and system architecture. We share results of a case study with a machine learning pipeline for image captioning that show how detailed performance views can be beneficial for analysis and debugging.
Investigating Human + Machine Complementarity for Recidivism Predictions
Aug 28, 2018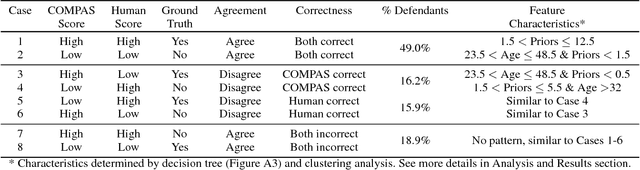

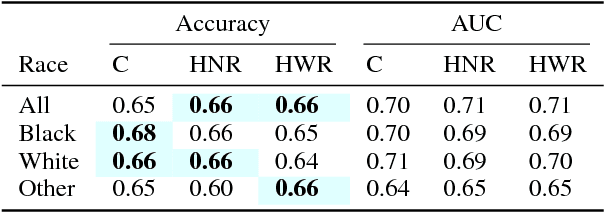
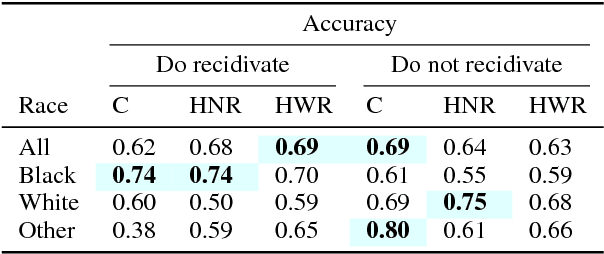
When might human input help (or not) when assessing risk in fairness-related domains? Dressel and Farid asked Mechanical Turk workers to evaluate a subset of individuals in the ProPublica COMPAS data set for risk of recidivism, and concluded that COMPAS predictions were no more accurate or fair than predictions made by humans. We delve deeper into this claim in this paper. We construct a Human Risk Score based on the predictions made by multiple Mechanical Turk workers on the same individual, study the agreement and disagreement between COMPAS and Human Scores on subgroups of individuals, and construct hybrid Human+AI models to predict recidivism. Our key finding is that on this data set, human and COMPAS decision making differed, but not in ways that could be leveraged to significantly improve ground truth prediction. We present the results of our analyses and suggestions for how machine and human input may have complementary strengths to address challenges in the fairness domain.
Discovering Blind Spots in Reinforcement Learning
May 23, 2018



Agents trained in simulation may make errors in the real world due to mismatches between training and execution environments. These mistakes can be dangerous and difficult to discover because the agent cannot predict them a priori. We propose using oracle feedback to learn a predictive model of these blind spots to reduce costly errors in real-world applications. We focus on blind spots in reinforcement learning (RL) that occur due to incomplete state representation: The agent does not have the appropriate features to represent the true state of the world and thus cannot distinguish among numerous states. We formalize the problem of discovering blind spots in RL as a noisy supervised learning problem with class imbalance. We learn models to predict blind spots in unseen regions of the state space by combining techniques for label aggregation, calibration, and supervised learning. The models take into consideration noise emerging from different forms of oracle feedback, including demonstrations and corrections. We evaluate our approach on two domains and show that it achieves higher predictive performance than baseline methods, and that the learned model can be used to selectively query an oracle at execution time to prevent errors. We also empirically analyze the biases of various feedback types and how they influence the discovery of blind spots.