 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Principal Assistance Games: Definition and Collegial Mechanisms
Dec 29, 2020We introduce the concept of a multi-principal assistance game (MPAG), and circumvent an obstacle in social choice theory, Gibbard's theorem, by using a sufficiently collegial preference inference mechanism. In an MPAG, a single agent assists N human principals who may have widely different preferences. MPAGs generalize assistance games, also known as cooperative inverse reinforcement learning games. We analyze in particular a generalization of apprenticeship learning in which the humans first perform some work to obtain utility and demonstrate their preferences, and then the robot acts to further maximize the sum of human payoffs. We show in this setting that if the game is sufficiently collegial, i.e. if the humans are responsible for obtaining a sufficient fraction of the rewards through their own actions, then their preferences are straightforwardly revealed through their work. This revelation mechanism is non-dictatorial, does not limit the possible outcomes to two alternatives, and is dominant-strategy incentive-compatible.
Multi-Principal Assistance Games
Jul 19, 2020
Assistance games (also known as cooperative inverse reinforcement learning games) have been proposed as a model for beneficial AI, wherein a robotic agent must act on behalf of a human principal but is initially uncertain about the humans payoff function. This paper studies multi-principal assistance games, which cover the more general case in which the robot acts on behalf of N humans who may have widely differing payoffs. Impossibility theorems in social choice theory and voting theory can be applied to such games, suggesting that strategic behavior by the human principals may complicate the robots task in learning their payoffs. We analyze in particular a bandit apprentice game in which the humans act first to demonstrate their individual preferences for the arms and then the robot acts to maximize the sum of human payoffs. We explore the extent to which the cost of choosing suboptimal arms reduces the incentive to mislead, a form of natural mechanism design. In this context we propose a social choice method that uses shared control of a system to combine preference inference with social welfare optimization.
Silly rules improve the capacity of agents to learn stable enforcement and compliance behaviors
Jan 25, 2020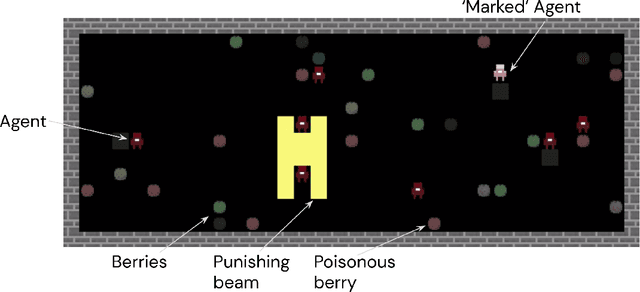
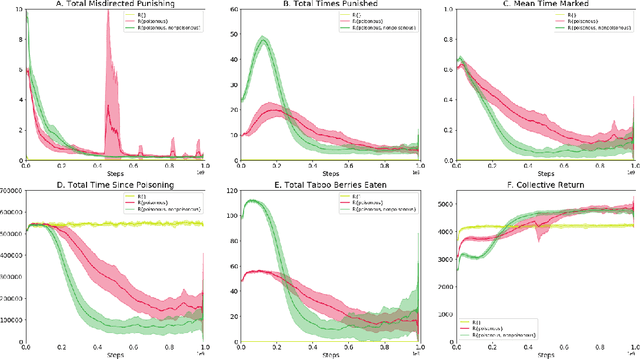
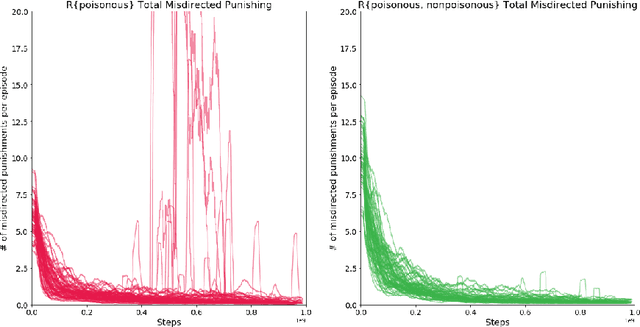

How can societies learn to enforce and comply with social norms? Here we investigate the learning dynamics and emergence of compliance and enforcement of social norms in a foraging game, implemented in a multi-agent reinforcement learning setting. In this spatiotemporally extended game, individuals are incentivized to implement complex berry-foraging policies and punish transgressions against social taboos covering specific berry types. We show that agents benefit when eating poisonous berries is taboo, meaning the behavior is punished by other agents, as this helps overcome a credit-assignment problem in discovering delayed health effects. Critically, however, we also show that introducing an additional taboo, which results in punishment for eating a harmless berry, improves the rate and stability with which agents learn to punish taboo violations and comply with taboos. Counterintuitively, our results show that an arbitrary taboo (a "silly rule") can enhance social learning dynamics and achieve better outcomes in the middle stages of learning. We discuss the results in the context of studying normativity as a group-level emergent phenomenon.
An Extensible Interactive Interface for Agent Design
Jun 10, 2019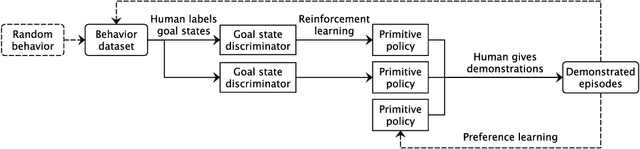
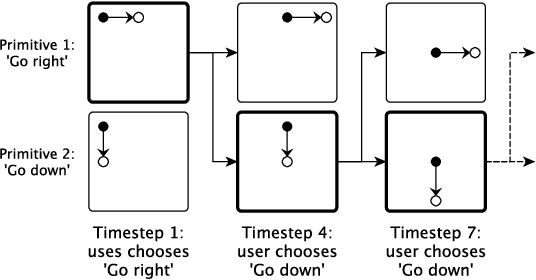
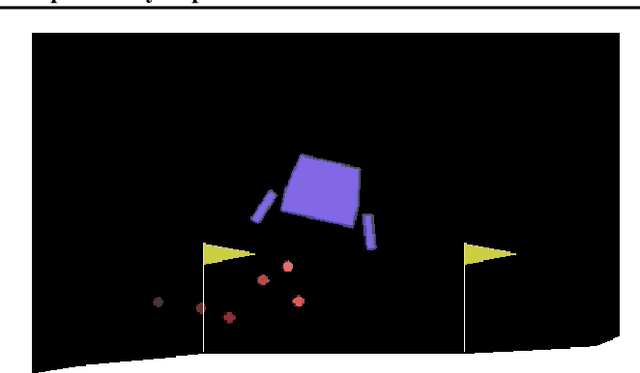
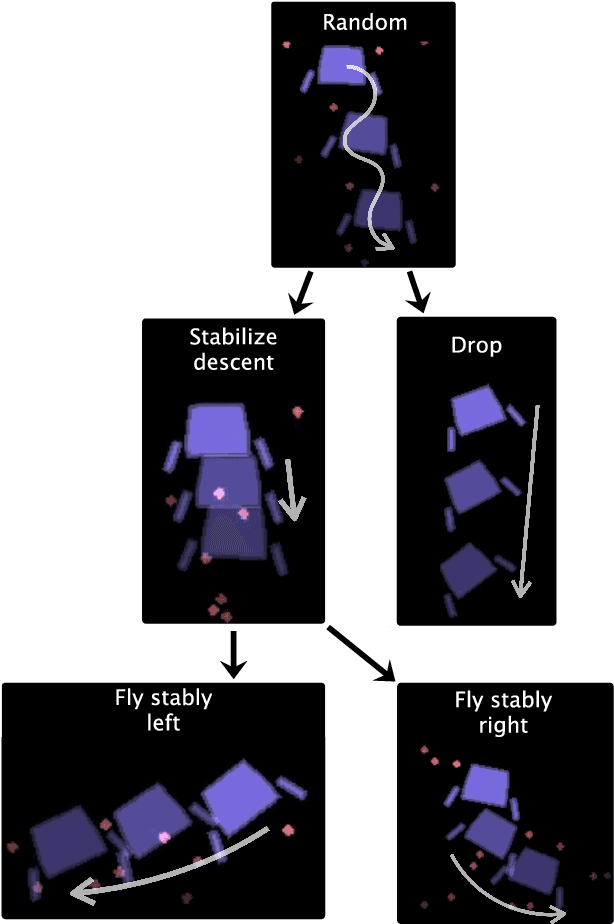
In artificial intelligence, we often specify tasks through a reward function. While this works well in some settings, many tasks are hard to specify this way. In deep reinforcement learning, for example, directly specifying a reward as a function of a high-dimensional observation is challenging. Instead, we present an interface for specifying tasks interactively using demonstrations. Our approach defines a set of increasingly complex policies. The interface allows the user to switch between these policies at fixed intervals to generate demonstrations of novel, more complex, tasks. We train new policies based on these demonstrations and repeat the process. We present a case study of our approach in the Lunar Lander domain, and show that this simple approach can quickly learn a successful landing policy and outperforms an existing comparison-based deep RL method.
Adversarial Training with Voronoi Constraints
May 02, 2019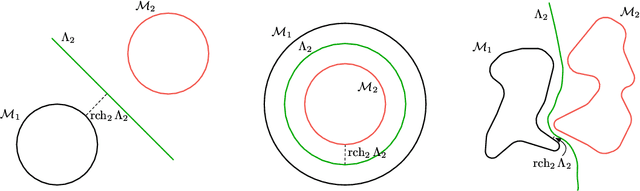
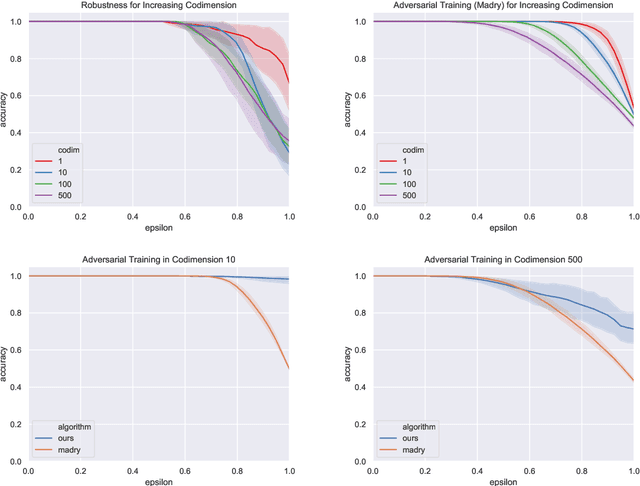
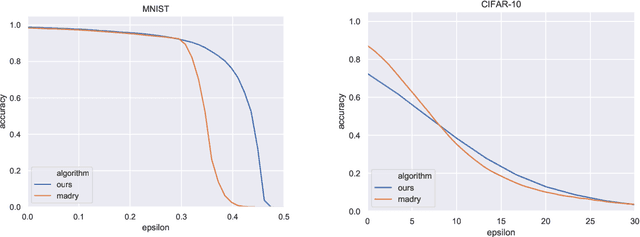
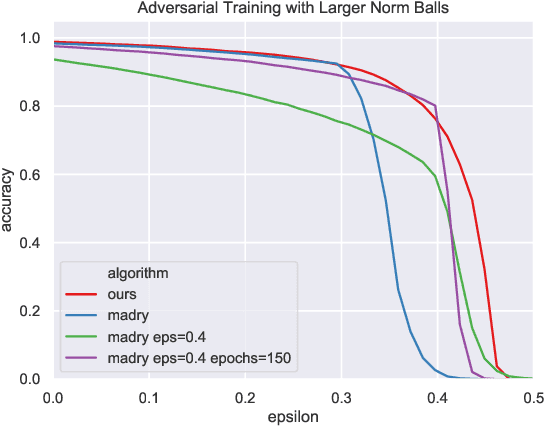
Adversarial examples are a pervasive phenomenon of machine learning models where seemingly imperceptible perturbations to the input lead to misclassifications for otherwise statistically accurate models. We propose a geometric framework, drawing on tools from the manifold reconstruction literature, to analyze the high-dimensional geometry of adversarial examples. In particular, we highlight the importance of codimension: for low-dimensional data manifolds embedded in high-dimensional space there are many directions off the manifold in which an adversary could construct adversarial examples. Adversarial examples are a natural consequence of learning a decision boundary that classifies the low-dimensional data manifold well, but classifies points near the manifold incorrectly. Using our geometric framework we prove that adversarial training is sample inefficient, and show sufficient sampling conditions under which nearest neighbor classifiers and ball-based adversarial training are robust. Finally we introduce adversarial training with Voronoi constraints, which replaces the norm ball constraint with the Voronoi cell for each point in the training set. We show that adversarial training with Voronoi constraints produces robust models which significantly improve over the state-of-the-art on MNIST and are competitive on CIFAR-10.
Conservative Agency via Attainable Utility Preservation
Feb 26, 2019
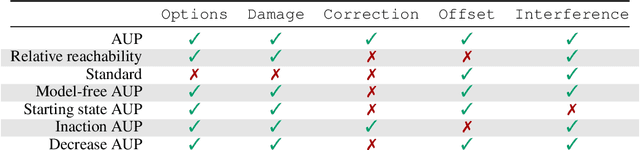
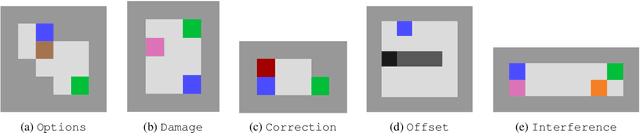
Reward functions are often misspecified. An agent optimizing an incorrect reward function can change its environment in large, undesirable, and potentially irreversible ways. Work on impact measurement seeks a means of identifying (and thereby avoiding) large changes to the environment. We propose a novel impact measure which induces conservative, effective behavior across a range of situations. The approach attempts to preserve the attainable utility of auxiliary objectives. We evaluate our proposal on an array of benchmark tasks and show that it matches or outperforms relative reachability, the state-of-the-art in impact measurement.
The Assistive Multi-Armed Bandit
Jan 24, 2019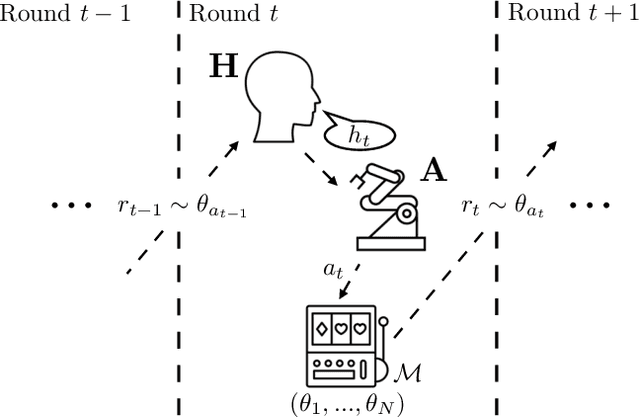
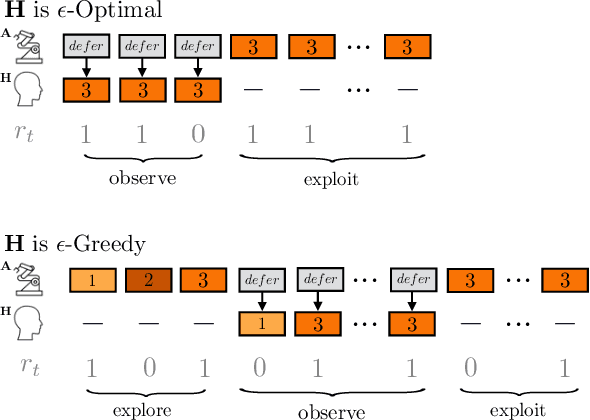
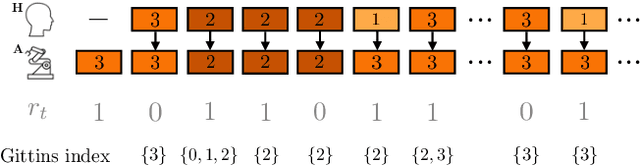
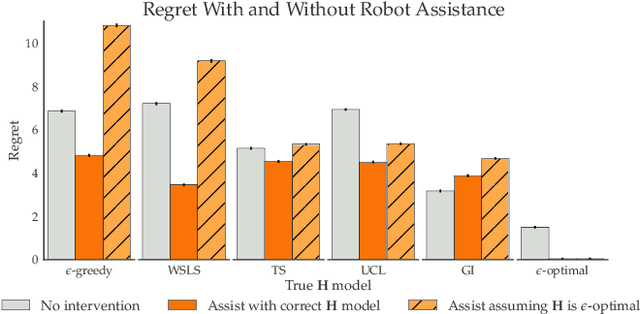
Learning preferences implicit in the choices humans make is a well studied problem in both economics and computer science. However, most work makes the assumption that humans are acting (noisily) optimally with respect to their preferences. Such approaches can fail when people are themselves learning about what they want. In this work, we introduce the assistive multi-armed bandit, where a robot assists a human playing a bandit task to maximize cumulative reward. In this problem, the human does not know the reward function but can learn it through the rewards received from arm pulls; the robot only observes which arms the human pulls but not the reward associated with each pull. We offer sufficient and necessary conditions for successfully assisting the human in this framework. Surprisingly, better human performance in isolation does not necessarily lead to better performance when assisted by the robot: a human policy can do better by effectively communicating its observed rewards to the robot. We conduct proof-of-concept experiments that support these results. We see this work as contributing towards a theory behind algorithms for human-robot interaction.
On the Utility of Model Learning in HRI
Jan 04, 2019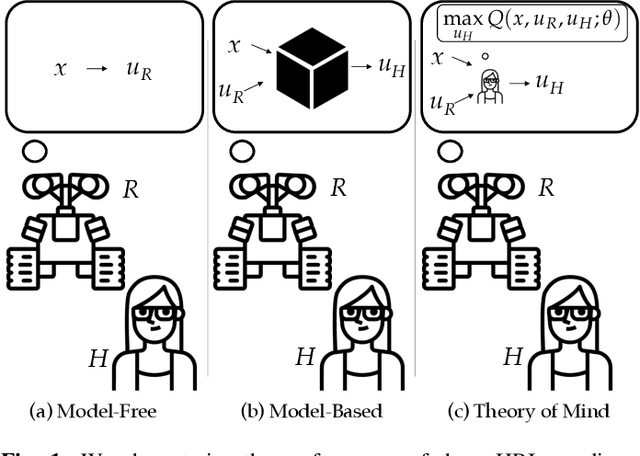
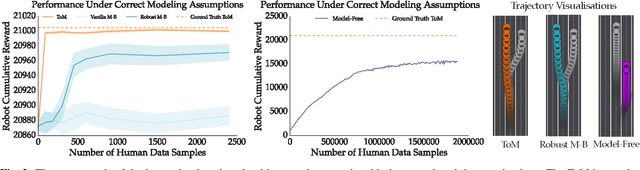
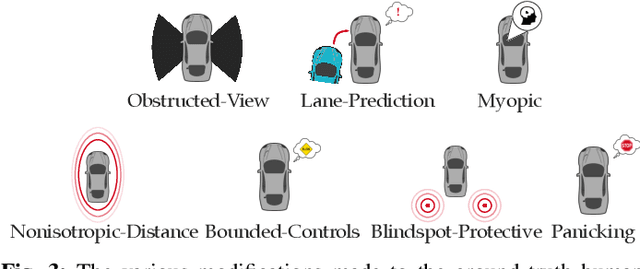
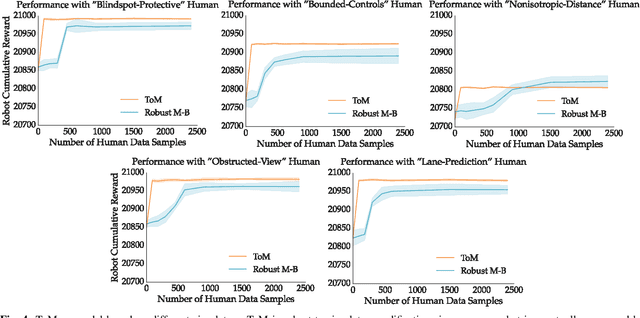
Fundamental to robotics is the debate between model-based and model-free learning: should the robot build an explicit model of the world, or learn a policy directly? In the context of HRI, part of the world to be modeled is the human. One option is for the robot to treat the human as a black box and learn a policy for how they act directly. But it can also model the human as an agent, and rely on a "theory of mind" to guide or bias the learning (grey box). We contribute a characterization of the performance of these methods under the optimistic case of having an ideal theory of mind, as well as under different scenarios in which the assumptions behind the robot's theory of mind for the human are wrong, as they inevitably will be in practice. We find that there is a significant sample complexity advantage to theory of mind methods and that they are more robust to covariate shift, but that when enough interaction data is available, black box approaches eventually dominate.
Human-AI Learning Performance in Multi-Armed Bandits
Dec 21, 2018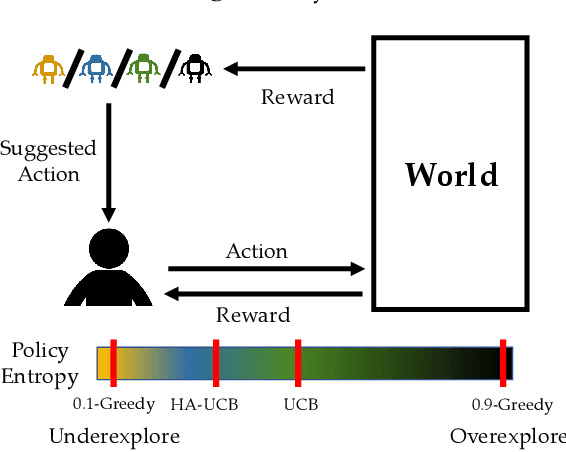
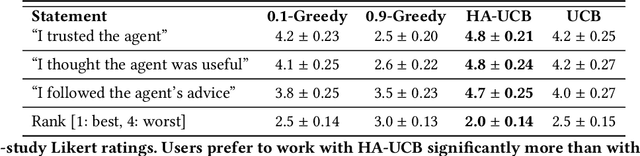
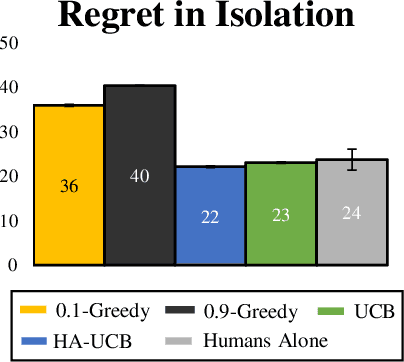
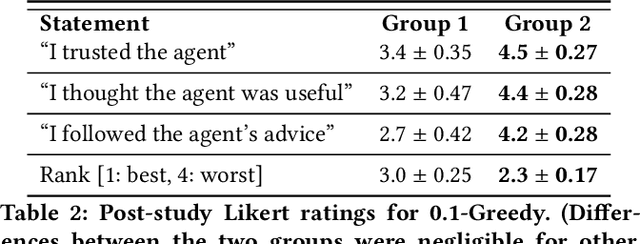
People frequently face challenging decision-making problems in which outcomes are uncertain or unknown. Artificial intelligence (AI) algorithms exist that can outperform humans at learning such tasks. Thus, there is an opportunity for AI agents to assist people in learning these tasks more effectively. In this work, we use a multi-armed bandit as a controlled setting in which to explore this direction. We pair humans with a selection of agents and observe how well each human-agent team performs. We find that team performance can beat both human and agent performance in isolation. Interestingly, we also find that an agent's performance in isolation does not necessarily correlate with the human-agent team's performance. A drop in agent performance can lead to a disproportionately large drop in team performance, or in some settings can even improve team performance. Pairing a human with an agent that performs slightly better than them can make them perform much better, while pairing them with an agent that performs the same can make them them perform much worse. Further, our results suggest that people have different exploration strategies and might perform better with agents that match their strategy. Overall, optimizing human-agent team performance requires going beyond optimizing agent performance, to understanding how the agent's suggestions will influence human decision-making.
Legible Normativity for AI Alignment: The Value of Silly Rules
Nov 03, 2018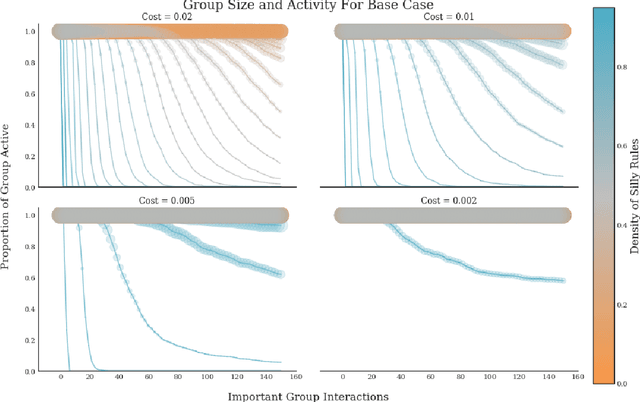
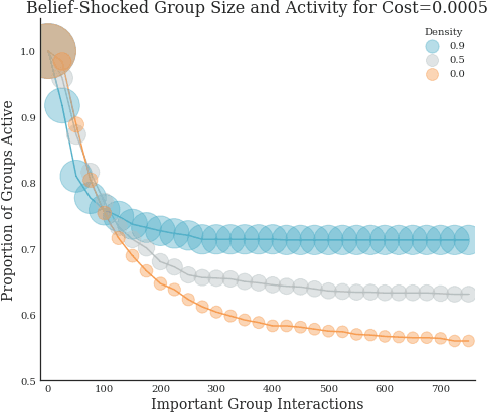
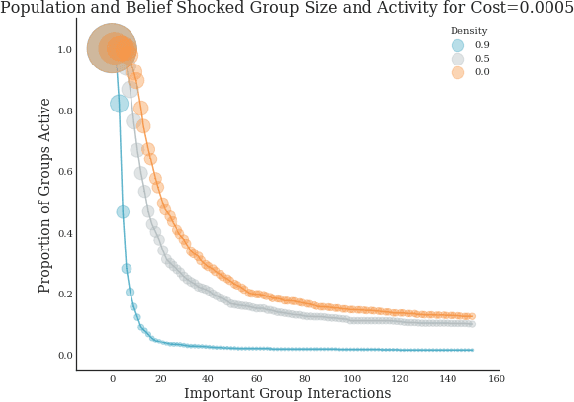
It has become commonplace to assert that autonomous agents will have to be built to follow human rules of behavior--social norms and laws. But human laws and norms are complex and culturally varied systems, in many cases agents will have to learn the rules. This requires autonomous agents to have models of how human rule systems work so that they can make reliable predictions about rules. In this paper we contribute to the building of such models by analyzing an overlooked distinction between important rules and what we call silly rules--rules with no discernible direct impact on welfare. We show that silly rules render a normative system both more robust and more adaptable in response to shocks to perceived stability. They make normativity more legible for humans, and can increase legibility for AI systems as well. For AI systems to integrate into human normative systems, we suggest, it may be important for them to have models that include representations of silly rules.