 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne Diffusion to Generate Them All
Nov 25, 2024



We introduce OneDiffusion, a versatile, large-scale diffusion model that seamlessly supports bidirectional image synthesis and understanding across diverse tasks. It enables conditional generation from inputs such as text, depth, pose, layout, and semantic maps, while also handling tasks like image deblurring, upscaling, and reverse processes such as depth estimation and segmentation. Additionally, OneDiffusion allows for multi-view generation, camera pose estimation, and instant personalization using sequential image inputs. Our model takes a straightforward yet effective approach by treating all tasks as frame sequences with varying noise scales during training, allowing any frame to act as a conditioning image at inference time. Our unified training framework removes the need for specialized architectures, supports scalable multi-task training, and adapts smoothly to any resolution, enhancing both generalization and scalability. Experimental results demonstrate competitive performance across tasks in both generation and prediction such as text-to-image, multiview generation, ID preservation, depth estimation and camera pose estimation despite relatively small training dataset. Our code and checkpoint are freely available at https://github.com/lehduong/OneDiffusion
Preserving Identity with Variational Score for General-purpose 3D Editing
Jun 13, 2024



We present Piva (Preserving Identity with Variational Score Distillation), a novel optimization-based method for editing images and 3D models based on diffusion models. Specifically, our approach is inspired by the recently proposed method for 2D image editing - Delta Denoising Score (DDS). We pinpoint the limitations in DDS for 2D and 3D editing, which causes detail loss and over-saturation. To address this, we propose an additional score distillation term that enforces identity preservation. This results in a more stable editing process, gradually optimizing NeRF models to match target prompts while retaining crucial input characteristics. We demonstrate the effectiveness of our approach in zero-shot image and neural field editing. Our method successfully alters visual attributes, adds both subtle and substantial structural elements, translates shapes, and achieves competitive results on standard 2D and 3D editing benchmarks. Additionally, our method imposes no constraints like masking or pre-training, making it compatible with a wide range of pre-trained diffusion models. This allows for versatile editing without needing neural field-to-mesh conversion, offering a more user-friendly experience.
POODLE: Improving Few-shot Learning via Penalizing Out-of-Distribution Samples
Jun 08, 2022
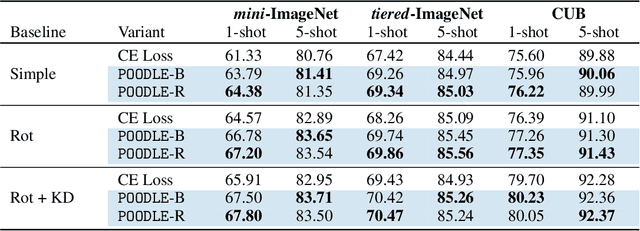
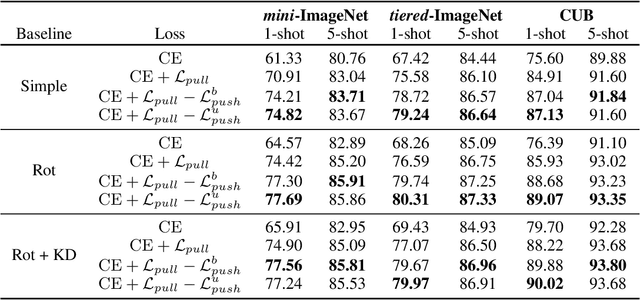
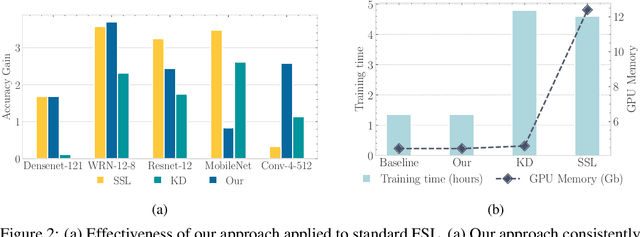
In this work, we propose to use out-of-distribution samples, i.e., unlabeled samples coming from outside the target classes, to improve few-shot learning. Specifically, we exploit the easily available out-of-distribution samples to drive the classifier to avoid irrelevant features by maximizing the distance from prototypes to out-of-distribution samples while minimizing that of in-distribution samples (i.e., support, query data). Our approach is simple to implement, agnostic to feature extractors, lightweight without any additional cost for pre-training, and applicable to both inductive and transductive settings. Extensive experiments on various standard benchmarks demonstrate that the proposed method consistently improves the performance of pretrained networks with different architectures.
Network Pruning That Matters: A Case Study on Retraining Variants
May 07, 2021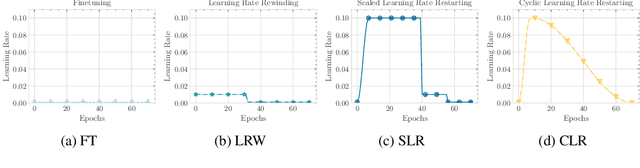
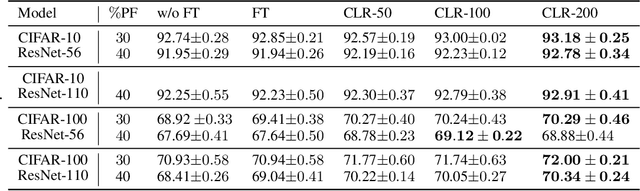

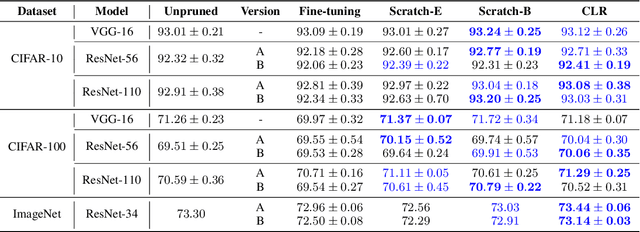
Network pruning is an effective method to reduce the computational expense of over-parameterized neural networks for deployment on low-resource systems. Recent state-of-the-art techniques for retraining pruned networks such as weight rewinding and learning rate rewinding have been shown to outperform the traditional fine-tuning technique in recovering the lost accuracy (Renda et al., 2020), but so far it is unclear what accounts for such performance. In this work, we conduct extensive experiments to verify and analyze the uncanny effectiveness of learning rate rewinding. We find that the reason behind the success of learning rate rewinding is the usage of a large learning rate. Similar phenomenon can be observed in other learning rate schedules that involve large learning rates, e.g., the 1-cycle learning rate schedule (Smith et al., 2019). By leveraging the right learning rate schedule in retraining, we demonstrate a counter-intuitive phenomenon in that randomly pruned networks could even achieve better performance than methodically pruned networks (fine-tuned with the conventional approach). Our results emphasize the cruciality of the learning rate schedule in pruned network retraining - a detail often overlooked by practitioners during the implementation of network pruning. One-sentence Summary: We study the effective of different retraining mechanisms while doing pruning
Paying more attention to snapshots of Iterative Pruning: Improving Model Compression via Ensemble Distillation
Jun 20, 2020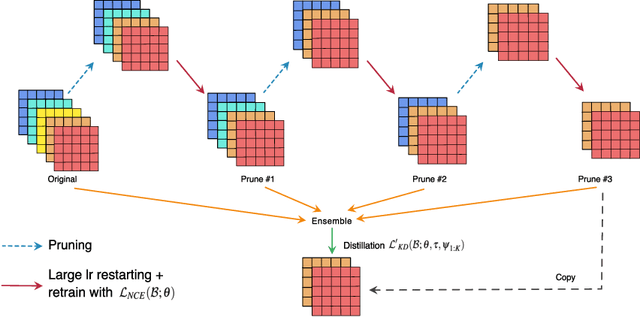
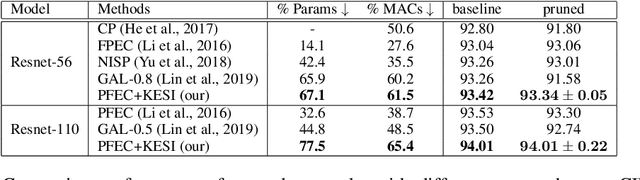
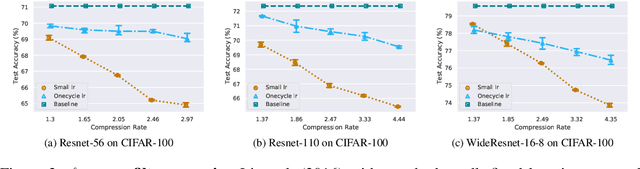
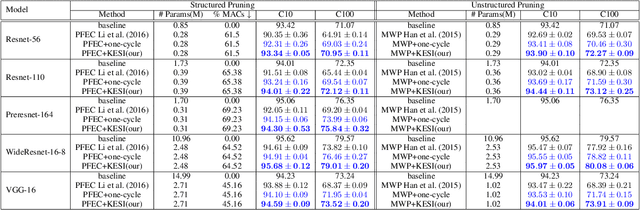
Network pruning is one of the most dominant methods for reducing the heavy inference cost of deep neural networks. Existing methods often iteratively prune networks to attain high compression ratio without incurring significant loss in performance. However, we argue that conventional methods for retraining pruned networks (i.e., using small, fixed learning rate) are inadequate as they completely ignore the benefits from snapshots of iterative pruning. In this work, we show that strong ensembles can be constructed from snapshots of iterative pruning, which achieve competitive performance and vary in network structure. Furthermore, we present simple, general and effective pipeline that generates strong ensembles of networks during pruning with large learning rate restarting, and utilizes knowledge distillation with those ensembles to improve the predictive power of compact models. In standard image classification benchmarks such as CIFAR and Tiny-Imagenet, we advance state-of-the-art pruning ratio of structured pruning by integrating simple l1-norm filters pruning into our pipeline. Specifically, we reduce 75-80% of total parameters and 65-70% MACs of numerous variants of ResNet architectures while having comparable or better performance than that of original networks. Code associate with this paper is made publicly available at https://github.com/lehduong/ginp.