 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntegrative Experiments Identify How Punishment Impacts Welfare in Public Goods Games
Aug 23, 2025Punishment as a mechanism for promoting cooperation has been studied extensively for more than two decades, but its effectiveness remains a matter of dispute. Here, we examine how punishment's impact varies across cooperative settings through a large-scale integrative experiment. We vary 14 parameters that characterize public goods games, sampling 360 experimental conditions and collecting 147,618 decisions from 7,100 participants. Our results reveal striking heterogeneity in punishment effectiveness: while punishment consistently increases contributions, its impact on payoffs (i.e., efficiency) ranges from dramatically enhancing welfare (up to 43% improvement) to severely undermining it (up to 44% reduction) depending on the cooperative context. To characterize these patterns, we developed models that outperformed human forecasters (laypeople and domain experts) in predicting punishment outcomes in new experiments. Communication emerged as the most predictive feature, followed by contribution framing (opt-out vs. opt-in), contribution type (variable vs. all-or-nothing), game length (number of rounds), peer outcome visibility (whether participants can see others' earnings), and the availability of a reward mechanism. Interestingly, however, most of these features interact to influence punishment effectiveness rather than operating independently. For example, the extent to which longer games increase the effectiveness of punishment depends on whether groups can communicate. Together, our results refocus the debate over punishment from whether or not it "works" to the specific conditions under which it does and does not work. More broadly, our study demonstrates how integrative experiments can be combined with machine learning to uncover generalizable patterns, potentially involving interactions between multiple features, and help generate novel explanations in complex social phenomena.
Empirically evaluating commonsense intelligence in large language models with large-scale human judgments
May 15, 2025



Commonsense intelligence in machines is often assessed by static benchmarks that compare a model's output against human-prescribed correct labels. An important, albeit implicit, assumption of these labels is that they accurately capture what any human would think, effectively treating human common sense as homogeneous. However, recent empirical work has shown that humans vary enormously in what they consider commonsensical; thus what appears self-evident to one benchmark designer may not be so to another. Here, we propose a novel method for evaluating common sense in artificial intelligence (AI), specifically in large language models (LLMs), that incorporates empirically observed heterogeneity among humans by measuring the correspondence between a model's judgment and that of a human population. We first find that, when treated as independent survey respondents, most LLMs remain below the human median in their individual commonsense competence. Second, when used as simulators of a hypothetical population, LLMs correlate with real humans only modestly in the extent to which they agree on the same set of statements. In both cases, smaller, open-weight models are surprisingly more competitive than larger, proprietary frontier models. Our evaluation framework, which ties commonsense intelligence to its cultural basis, contributes to the growing call for adapting AI models to human collectivities that possess different, often incompatible, social stocks of knowledge.
Pre-registration for Predictive Modeling
Nov 30, 2023



Amid rising concerns of reproducibility and generalizability in predictive modeling, we explore the possibility and potential benefits of introducing pre-registration to the field. Despite notable advancements in predictive modeling, spanning core machine learning tasks to various scientific applications, challenges such as overlooked contextual factors, data-dependent decision-making, and unintentional re-use of test data have raised questions about the integrity of results. To address these issues, we propose adapting pre-registration practices from explanatory modeling to predictive modeling. We discuss current best practices in predictive modeling and their limitations, introduce a lightweight pre-registration template, and present a qualitative study with machine learning researchers to gain insight into the effectiveness of pre-registration in preventing biased estimates and promoting more reliable research outcomes. We conclude by exploring the scope of problems that pre-registration can address in predictive modeling and acknowledging its limitations within this context.
The diminishing state of shared reality on US television news
Oct 29, 2023The potential for a large, diverse population to coexist peacefully is thought to depend on the existence of a ``shared reality:'' a public sphere in which participants are exposed to similar facts about similar topics. A generation ago, broadcast television news was widely considered to serve this function; however, since the rise of cable news in the 1990s, critics and scholars have worried that the corresponding fragmentation and segregation of audiences along partisan lines has caused this shared reality to be lost. Here we examine this concern using a unique combination of data sets tracking the production (since 2012) and consumption (since 2016) of television news content on the three largest cable and broadcast networks respectively. With regard to production, we find strong evidence for the ``loss of shared reality hypothesis:'' while broadcast continues to cover similar topics with similar language, cable news networks have become increasingly distinct, both from broadcast news and each other, diverging both in terms of content and language. With regard to consumption, we find more mixed evidence: while broadcast news has indeed declined in popularity, it remains the dominant source of news for roughly 50\% more Americans than does cable; moreover, its decline, while somewhat attributable to cable, appears driven more by a shift away from news consumption altogether than a growth in cable consumption. We conclude that shared reality on US television news is indeed diminishing, but is more robust than previously thought and is declining for somewhat different reasons.
Split-door criterion: Identification of causal effects through auxiliary outcomes
Jun 14, 2018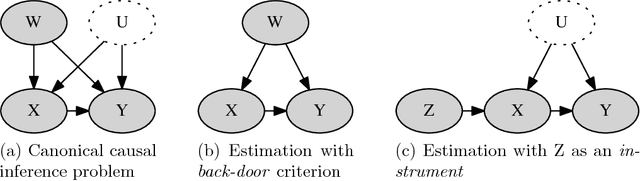
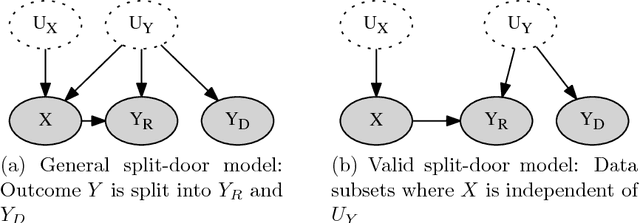
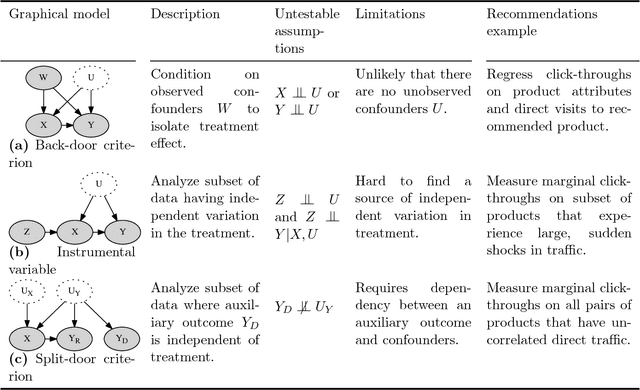

We present a method for estimating causal effects in time series data when fine-grained information about the outcome of interest is available. Specifically, we examine what we call the split-door setting, where the outcome variable can be split into two parts: one that is potentially affected by the cause being studied and another that is independent of it, with both parts sharing the same (unobserved) confounders. We show that under these conditions, the problem of identification reduces to that of testing for independence among observed variables, and present a method that uses this approach to automatically find subsets of the data that are causally identified. We demonstrate the method by estimating the causal impact of Amazon's recommender system on traffic to product pages, finding thousands of examples within the dataset that satisfy the split-door criterion. Unlike past studies based on natural experiments that were limited to a single product category, our method applies to a large and representative sample of products viewed on the site. In line with previous work, we find that the widely-used click-through rate (CTR) metric overestimates the causal impact of recommender systems; depending on the product category, we estimate that 50-80\% of the traffic attributed to recommender systems would have happened even without any recommendations. We conclude with guidelines for using the split-door criterion as well as a discussion of other contexts where the method can be applied.