 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeO2D2: Out-Of-Distribution Detector to Capture Undecidable Trials in Authorship Verification
Jul 30, 2021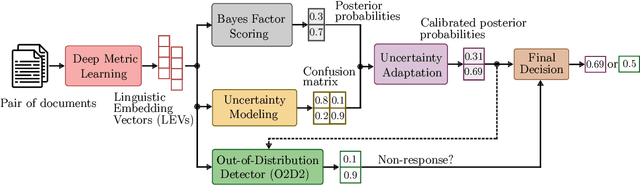
The PAN 2021 authorship verification (AV) challenge is part of a three-year strategy, moving from a cross-topic/closed-set AV task to a cross-topic/open-set AV task over a collection of fanfiction texts. In this work, we present a novel hybrid neural-probabilistic framework that is designed to tackle the challenges of the 2021 task. Our system is based on our 2020 winning submission, with updates to significantly reduce sensitivities to topical variations and to further improve the system's calibration by means of an uncertainty-adaptation layer. Our framework additionally includes an out-of-distribution detector (O2D2) for defining non-responses. Our proposed system outperformed all other systems that participated in the PAN 2021 AV task.
Self-Calibrating Neural-Probabilistic Model for Authorship Verification Under Covariate Shift
Jun 21, 2021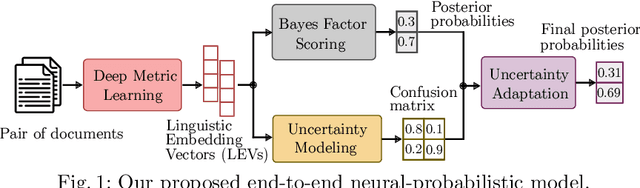
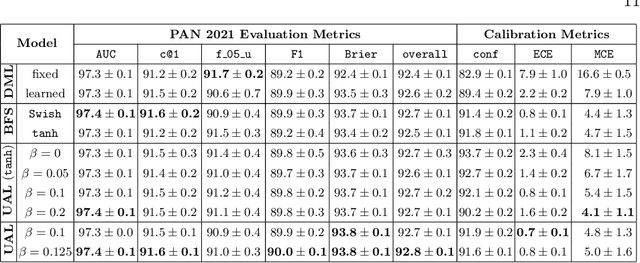
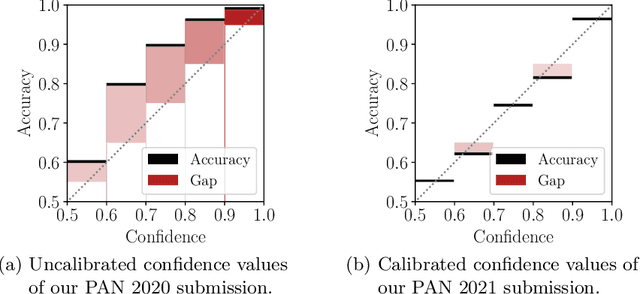
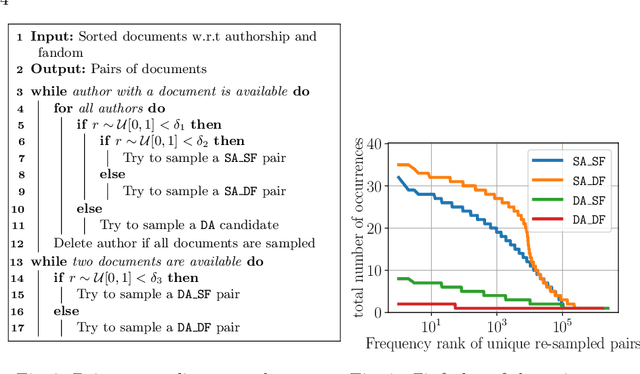
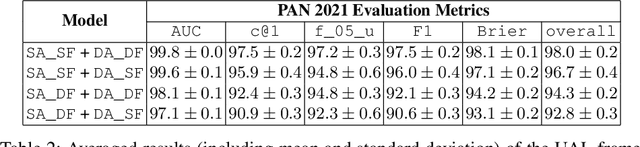
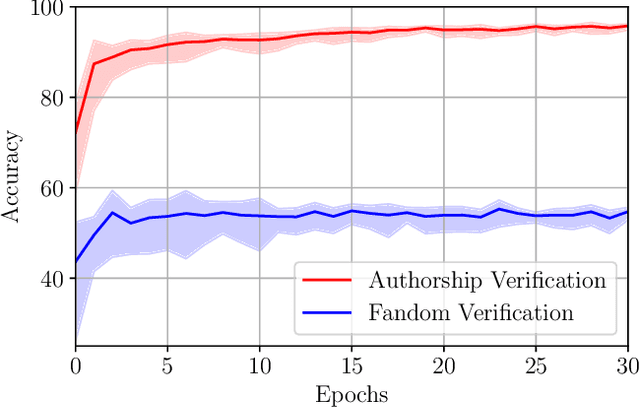
We are addressing two fundamental problems in authorship verification (AV): Topic variability and miscalibration. Variations in the topic of two disputed texts are a major cause of error for most AV systems. In addition, it is observed that the underlying probability estimates produced by deep learning AV mechanisms oftentimes do not match the actual case counts in the respective training data. As such, probability estimates are poorly calibrated. We are expanding our framework from PAN 2020 to include Bayes factor scoring (BFS) and an uncertainty adaptation layer (UAL) to address both problems. Experiments with the 2020/21 PAN AV shared task data show that the proposed method significantly reduces sensitivities to topical variations and significantly improves the system's calibration.
PILOT: Introducing Transformers for Probabilistic Sound Event Localization
Jun 07, 2021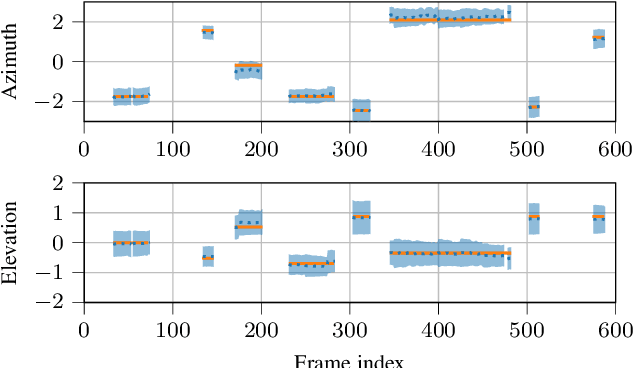
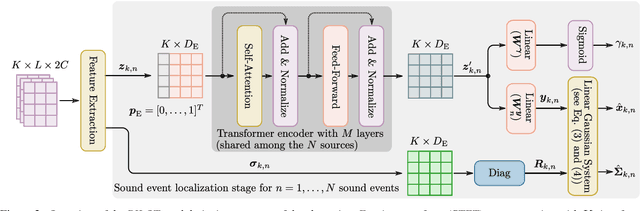
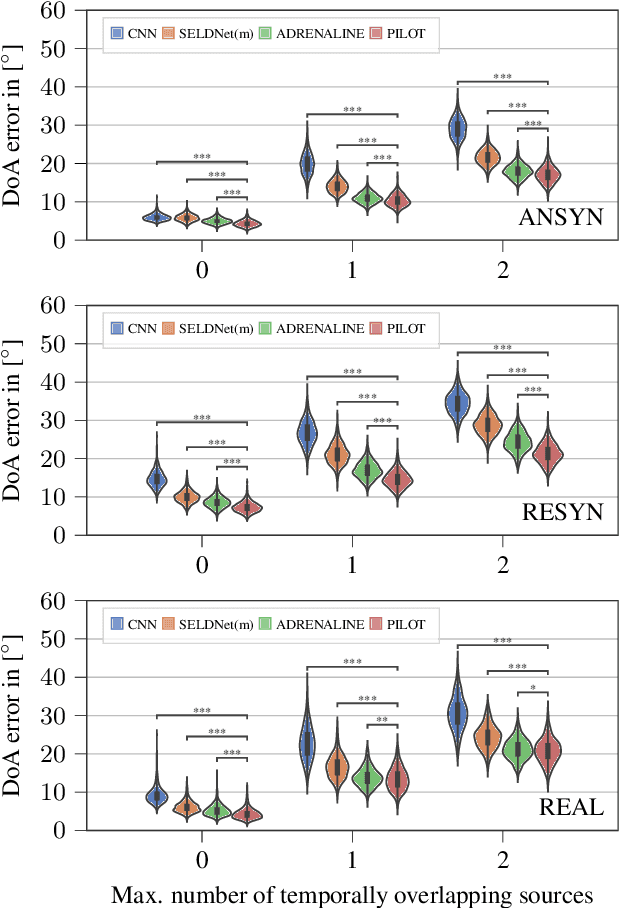
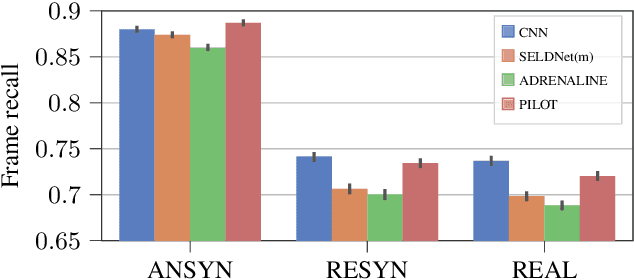
Sound event localization aims at estimating the positions of sound sources in the environment with respect to an acoustic receiver (e.g. a microphone array). Recent advances in this domain most prominently focused on utilizing deep recurrent neural networks. Inspired by the success of transformer architectures as a suitable alternative to classical recurrent neural networks, this paper introduces a novel transformer-based sound event localization framework, where temporal dependencies in the received multi-channel audio signals are captured via self-attention mechanisms. Additionally, the estimated sound event positions are represented as multivariate Gaussian variables, yielding an additional notion of uncertainty, which many previously proposed deep learning-based systems designed for this application do not provide. The framework is evaluated on three publicly available multi-source sound event localization datasets and compared against state-of-the-art methods in terms of localization error and event detection accuracy. It outperforms all competing systems on all datasets with statistical significant differences in performance.
Fusing information streams in end-to-end audio-visual speech recognition
Apr 19, 2021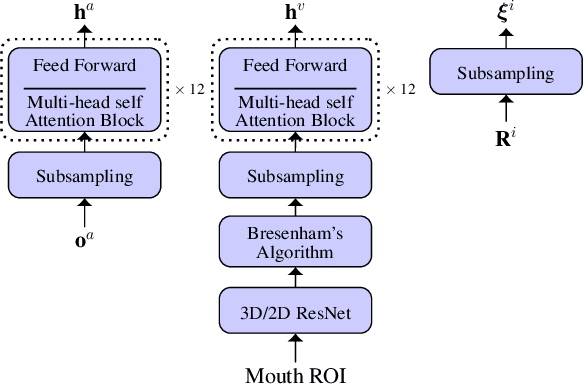
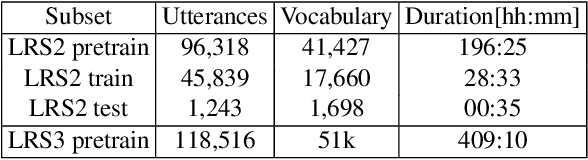
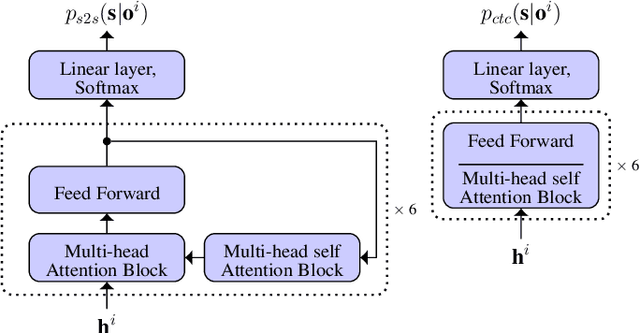
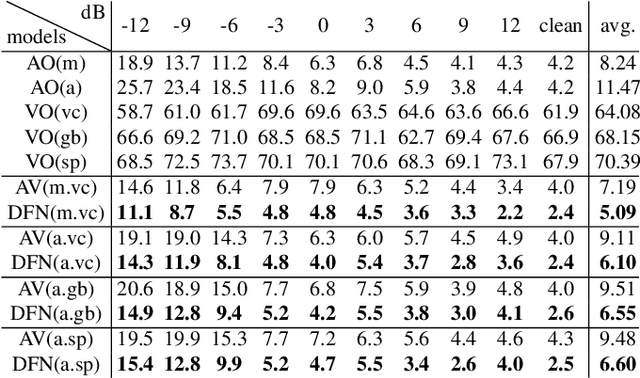
End-to-end acoustic speech recognition has quickly gained widespread popularity and shows promising results in many studies. Specifically the joint transformer/CTC model provides very good performance in many tasks. However, under noisy and distorted conditions, the performance still degrades notably. While audio-visual speech recognition can significantly improve the recognition rate of end-to-end models in such poor conditions, it is not obvious how to best utilize any available information on acoustic and visual signal quality and reliability in these models. We thus consider the question of how to optimally inform the transformer/CTC model of any time-variant reliability of the acoustic and visual information streams. We propose a new fusion strategy, incorporating reliability information in a decision fusion net that considers the temporal effects of the attention mechanism. This approach yields significant improvements compared to a state-of-the-art baseline model on the Lip Reading Sentences 2 and 3 (LRS2 and LRS3) corpus. On average, the new system achieves a relative word error rate reduction of 43% compared to the audio-only setup and 31% compared to the audiovisual end-to-end baseline.
* 5 pages
Unsupervised Classification of Voiced Speech and Pitch Tracking Using Forward-Backward Kalman Filtering
Mar 01, 2021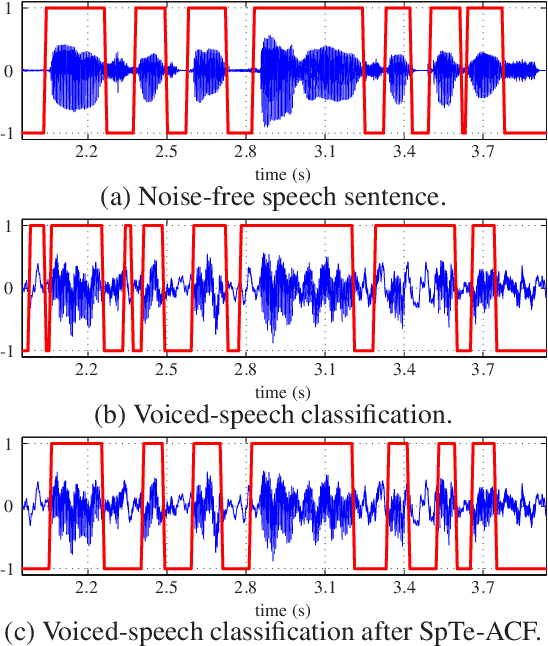
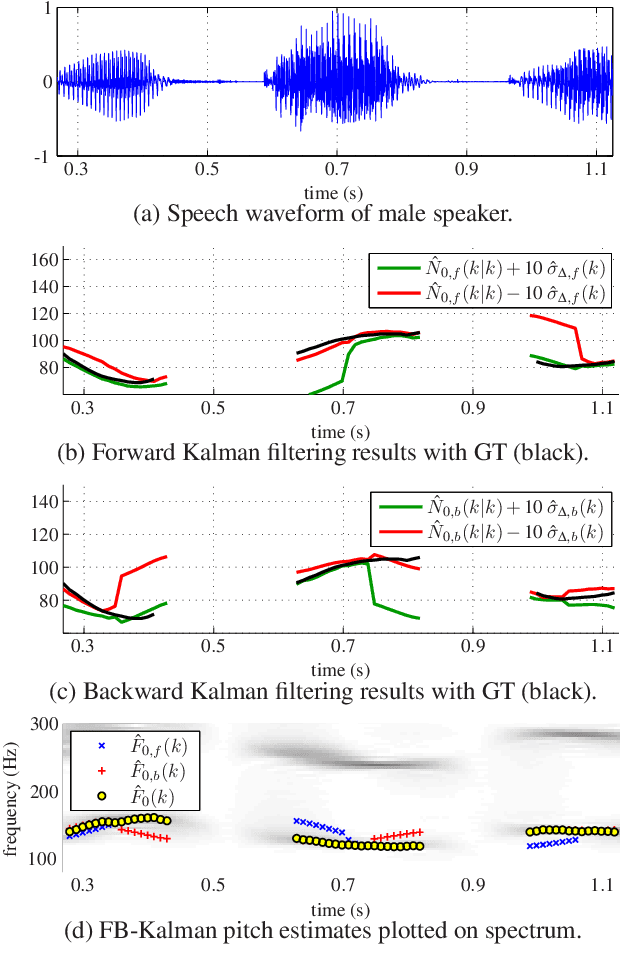
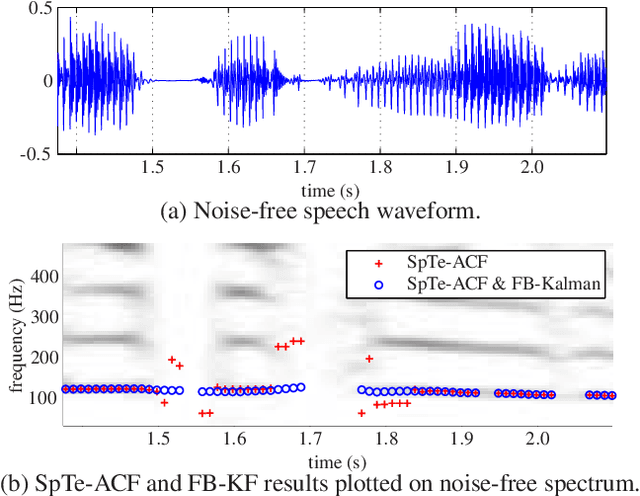
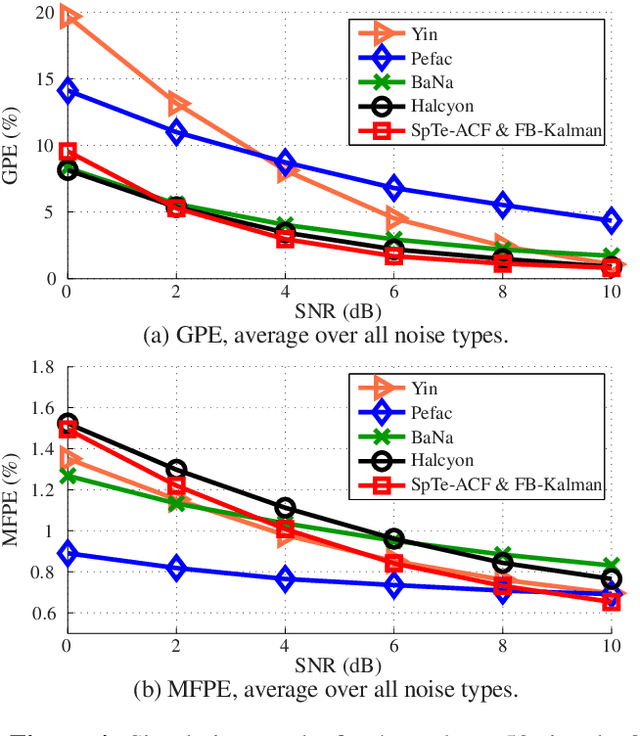
The detection of voiced speech, the estimation of the fundamental frequency, and the tracking of pitch values over time are crucial subtasks for a variety of speech processing techniques. Many different algorithms have been developed for each of the three subtasks. We present a new algorithm that integrates the three subtasks into a single procedure. The algorithm can be applied to pre-recorded speech utterances in the presence of considerable amounts of background noise. We combine a collection of standard metrics, such as the zero-crossing rate, for example, to formulate an unsupervised voicing classifier. The estimation of pitch values is accomplished with a hybrid autocorrelation-based technique. We propose a forward-backward Kalman filter to smooth the estimated pitch contour. In experiments, we are able to show that the proposed method compares favorably with current, state-of-the-art pitch detection algorithms.
Exploiting Attention-based Sequence-to-Sequence Architectures for Sound Event Localization
Feb 28, 2021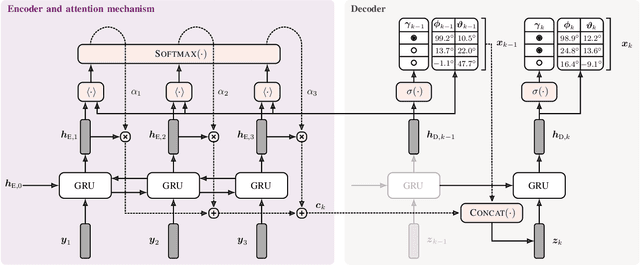
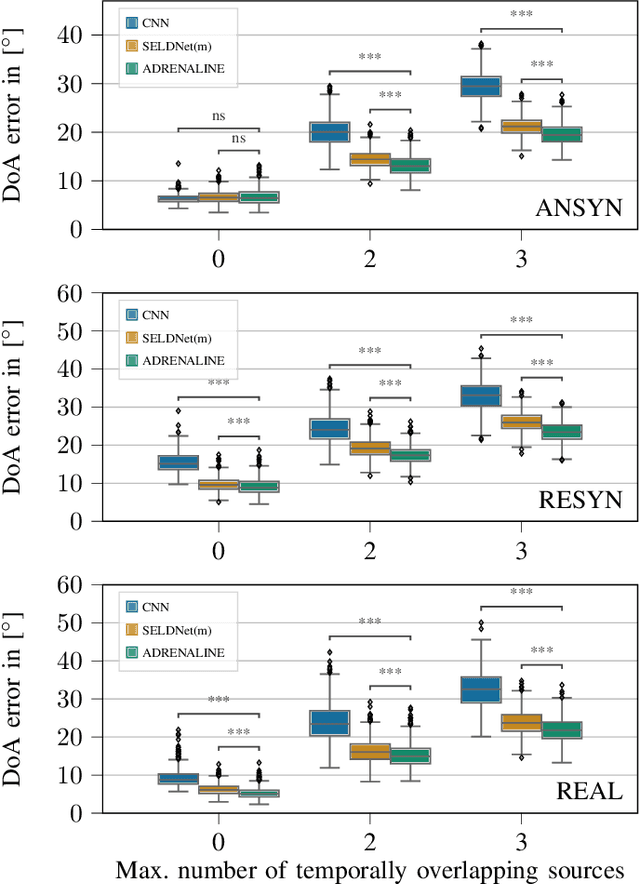
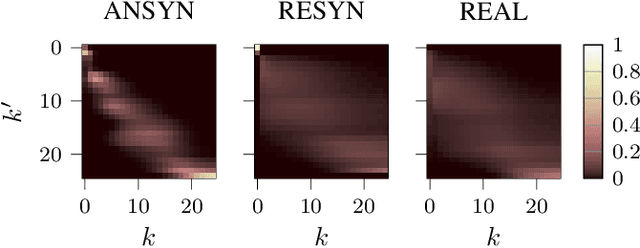
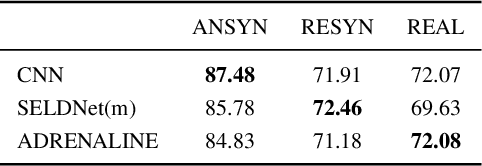
Sound event localization frameworks based on deep neural networks have shown increased robustness with respect to reverberation and noise in comparison to classical parametric approaches. In particular, recurrent architectures that incorporate temporal context into the estimation process seem to be well-suited for this task. This paper proposes a novel approach to sound event localization by utilizing an attention-based sequence-to-sequence model. These types of models have been successfully applied to problems in natural language processing and automatic speech recognition. In this work, a multi-channel audio signal is encoded to a latent representation, which is subsequently decoded to a sequence of estimated directions-of-arrival. Herein, attentions allow for capturing temporal dependencies in the audio signal by focusing on specific frames that are relevant for estimating the activity and direction-of-arrival of sound events at the current time-step. The framework is evaluated on three publicly available datasets for sound event localization. It yields superior localization performance compared to state-of-the-art methods in both anechoic and reverberant conditions.
Data Fusion for Audiovisual Speaker Localization: Extending Dynamic Stream Weights to the Spatial Domain
Feb 24, 2021
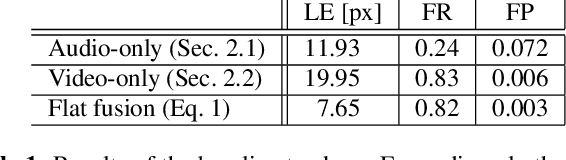
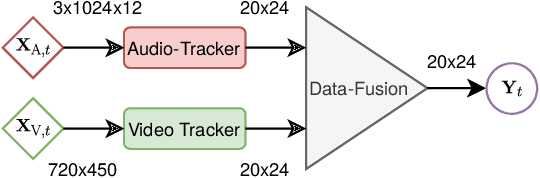
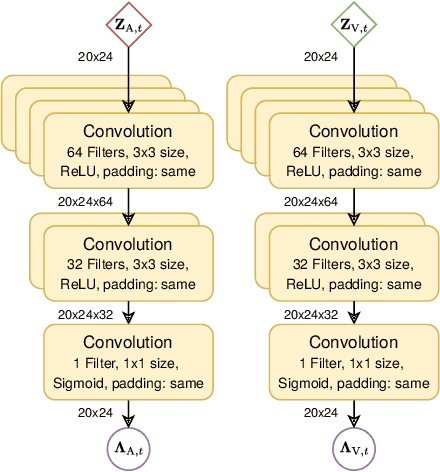
Estimating the positions of multiple speakers can be helpful for tasks like automatic speech recognition or speaker diarization. Both applications benefit from a known speaker position when, for instance, applying beamforming or assigning unique speaker identities. Recently, several approaches utilizing acoustic signals augmented with visual data have been proposed for this task. However, both the acoustic and the visual modality may be corrupted in specific spatial regions, for instance due to poor lighting conditions or to the presence of background noise. This paper proposes a novel audiovisual data fusion framework for speaker localization by assigning individual dynamic stream weights to specific regions in the localization space. This fusion is achieved via a neural network, which combines the predictions of individual audio and video trackers based on their time- and location-dependent reliability. A performance evaluation using audiovisual recordings yields promising results, with the proposed fusion approach outperforming all baseline models.
Dompteur: Taming Audio Adversarial Examples
Feb 10, 2021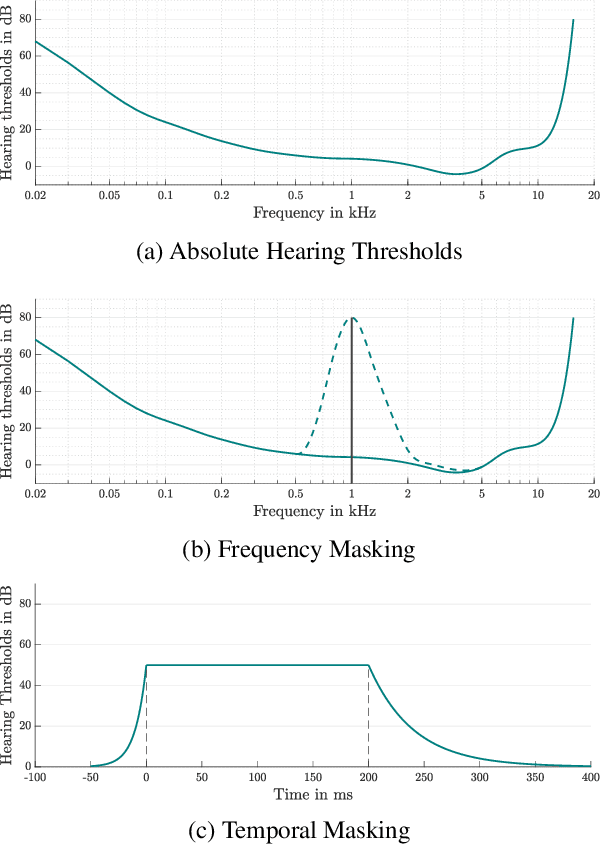

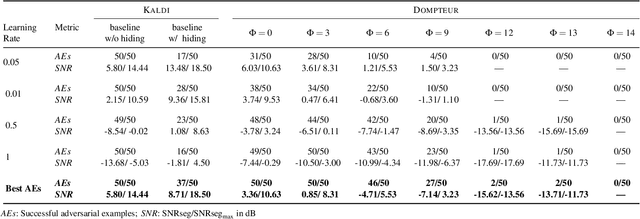

Adversarial examples seem to be inevitable. These specifically crafted inputs allow attackers to arbitrarily manipulate machine learning systems. Even worse, they often seem harmless to human observers. In our digital society, this poses a significant threat. For example, Automatic Speech Recognition (ASR) systems, which serve as hands-free interfaces to many kinds of systems, can be attacked with inputs incomprehensible for human listeners. The research community has unsuccessfully tried several approaches to tackle this problem. In this paper we propose a different perspective: We accept the presence of adversarial examples against ASR systems, but we require them to be perceivable by human listeners. By applying the principles of psychoacoustics, we can remove semantically irrelevant information from the ASR input and train a model that resembles human perception more closely. We implement our idea in a tool named Dompteur and demonstrate that our augmented system, in contrast to an unmodified baseline, successfully focuses on perceptible ranges of the input signal. This change forces adversarial examples into the audible range, while using minimal computational overhead and preserving benign performance. To evaluate our approach, we construct an adaptive attacker, which actively tries to avoid our augmentations and demonstrate that adversarial examples from this attacker remain clearly perceivable. Finally, we substantiate our claims by performing a hearing test with crowd-sourced human listeners.
VENOMAVE: Clean-Label Poisoning Against Speech Recognition
Oct 21, 2020

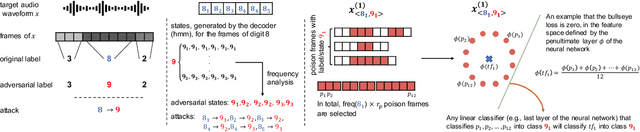
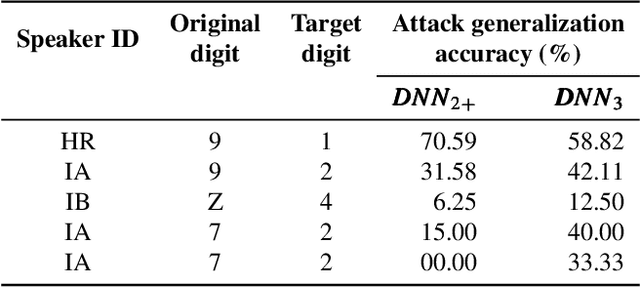
In the past few years, we observed a wide adoption of practical systems that use Automatic Speech Recognition (ASR) systems to improve human-machine interaction. Modern ASR systems are based on neural networks and prior research demonstrated that these systems are susceptible to adversarial examples, i.e., malicious audio inputs that lead to misclassification by the victim's network during the system's run time. The research question if ASR systems are also vulnerable to data poisoning attacks is still unanswered. In such an attack, a manipulation happens during the training phase of the neural network: an adversary injects malicious inputs into the training set such that the neural network's integrity and performance are compromised. In this paper, we present the first data poisoning attack in the audio domain, called VENOMAVE. Prior work in the image domain demonstrated several types of data poisoning attacks, but they cannot be applied to the audio domain. The main challenge is that we need to attack a time series of inputs. To enforce a targeted misclassification in an ASR system, we need to carefully generate a specific sequence of disturbed inputs for the target utterance, which will eventually be decoded to the desired sequence of words. More specifically, the adversarial goal is to produce a series of misclassification tasks and in each of them, we need to poison the system to misrecognize each frame of the target file. To demonstrate the practical feasibility of our attack, we evaluate VENOMAVE on an ASR system that detects sequences of digits from 0 to 9. When poisoning only 0.94% of the dataset on average, we achieve an attack success rate of 83.33%. We conclude that data poisoning attacks against ASR systems represent a real threat that needs to be considered.
Deep Bayes Factor Scoring for Authorship Verification
Aug 23, 2020
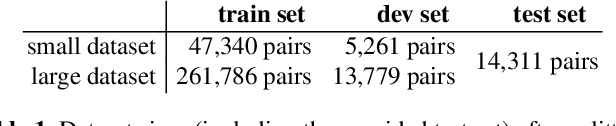
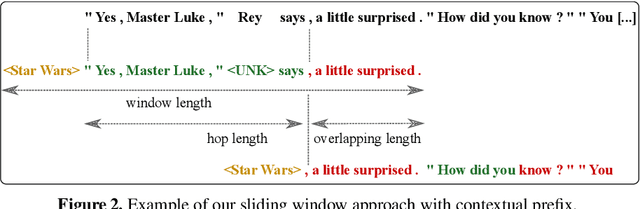

The PAN 2020 authorship verification (AV) challenge focuses on a cross-topic/closed-set AV task over a collection of fanfiction texts. Fanfiction is a fan-written extension of a storyline in which a so-called fandom topic describes the principal subject of the document. The data provided in the PAN 2020 AV task is quite challenging because authors of texts across multiple/different fandom topics are included. In this work, we present a hierarchical fusion of two well-known approaches into a single end-to-end learning procedure: A deep metric learning framework at the bottom aims to learn a pseudo-metric that maps a document of variable length onto a fixed-sized feature vector. At the top, we incorporate a probabilistic layer to perform Bayes factor scoring in the learned metric space. We also provide text preprocessing strategies to deal with the cross-topic issue.