 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecalling The Forgotten Class Memberships: Unlearned Models Can Be Noisy Labelers to Leak Privacy
Jun 24, 2025



Machine Unlearning (MU) technology facilitates the removal of the influence of specific data instances from trained models on request. Despite rapid advancements in MU technology, its vulnerabilities are still underexplored, posing potential risks of privacy breaches through leaks of ostensibly unlearned information. Current limited research on MU attacks requires access to original models containing privacy data, which violates the critical privacy-preserving objective of MU. To address this gap, we initiate an innovative study on recalling the forgotten class memberships from unlearned models (ULMs) without requiring access to the original one. Specifically, we implement a Membership Recall Attack (MRA) framework with a teacher-student knowledge distillation architecture, where ULMs serve as noisy labelers to transfer knowledge to student models. Then, it is translated into a Learning with Noisy Labels (LNL) problem for inferring the correct labels of the forgetting instances. Extensive experiments on state-of-the-art MU methods with multiple real datasets demonstrate that the proposed MRA strategy exhibits high efficacy in recovering class memberships of unlearned instances. As a result, our study and evaluation have established a benchmark for future research on MU vulnerabilities.
An Approach to Ensure Fairness in News Articles
Jul 08, 2022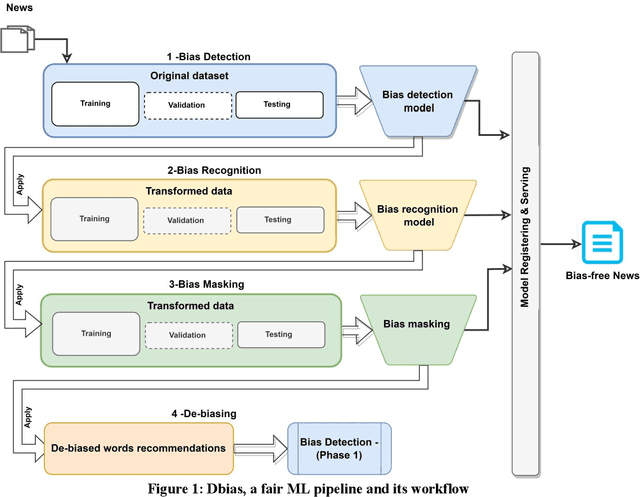
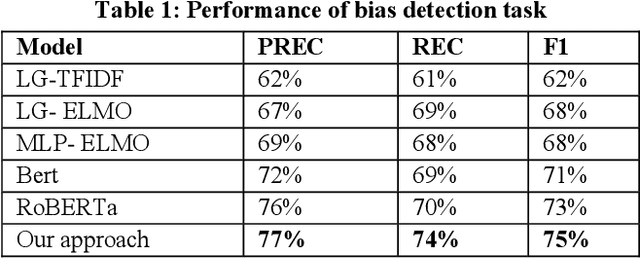
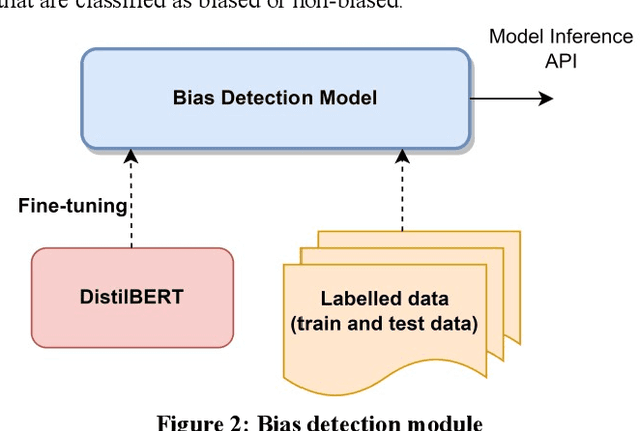
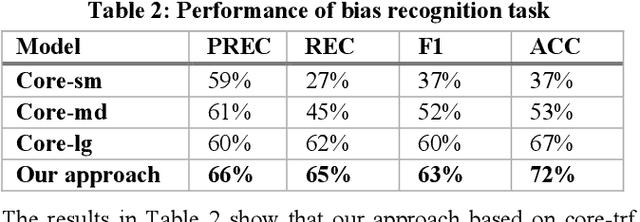
Recommender systems, information retrieval, and other information access systems present unique challenges for examining and applying concepts of fairness and bias mitigation in unstructured text. This paper introduces Dbias, which is a Python package to ensure fairness in news articles. Dbias is a trained Machine Learning (ML) pipeline that can take a text (e.g., a paragraph or news story) and detects if the text is biased or not. Then, it detects the biased words in the text, masks them, and recommends a set of sentences with new words that are bias-free or at least less biased. We incorporate the elements of data science best practices to ensure that this pipeline is reproducible and usable. We show in experiments that this pipeline can be effective for mitigating biases and outperforms the common neural network architectures in ensuring fairness in the news articles.