 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeoSAM: Fine-tuning SAM with Sparse and Dense Visual Prompting for Automated Segmentation of Mobility Infrastructure
Nov 19, 2023



The Segment Anything Model (SAM) has shown impressive performance when applied to natural image segmentation. However, it struggles with geographical images like aerial and satellite imagery, especially when segmenting mobility infrastructure including roads, sidewalks, and crosswalks. This inferior performance stems from the narrow features of these objects, their textures blending into the surroundings, and interference from objects like trees, buildings, vehicles, and pedestrians - all of which can disorient the model to produce inaccurate segmentation maps. To address these challenges, we propose Geographical SAM (GeoSAM), a novel SAM-based framework that implements a fine-tuning strategy using the dense visual prompt from zero-shot learning, and the sparse visual prompt from a pre-trained CNN segmentation model. The proposed GeoSAM outperforms existing approaches for geographical image segmentation, specifically by 20%, 14.29%, and 17.65% for road infrastructure, pedestrian infrastructure, and on average, respectively, representing a momentous leap in leveraging foundation models to segment mobility infrastructure including both road and pedestrian infrastructure in geographical images.
Hijacking Large Language Models via Adversarial In-Context Learning
Nov 16, 2023



In-context learning (ICL) has emerged as a powerful paradigm leveraging LLMs for specific tasks by utilizing labeled examples as demonstrations in the precondition prompts. Despite its promising performance, ICL suffers from instability with the choice and arrangement of examples. Additionally, crafted adversarial attacks pose a notable threat to the robustness of ICL. However, existing attacks are either easy to detect, rely on external models, or lack specificity towards ICL. To address these issues, this work introduces a novel transferable attack for ICL, aiming to hijack LLMs to generate the targeted response. The proposed LLM hijacking attack leverages a gradient-based prompt search method to learn and append imperceptible adversarial suffixes to the in-context demonstrations. Extensive experimental results on various tasks and datasets demonstrate the effectiveness of our LLM hijacking attack, resulting in a distracted attention towards adversarial tokens, consequently leading to the targeted unwanted outputs.
Empirical Evaluation of the Segment Anything Model (SAM) for Brain Tumor Segmentation
Oct 09, 2023



Brain tumor segmentation presents a formidable challenge in the field of Medical Image Segmentation. While deep-learning models have been useful, human expert segmentation remains the most accurate method. The recently released Segment Anything Model (SAM) has opened up the opportunity to apply foundation models to this difficult task. However, SAM was primarily trained on diverse natural images. This makes applying SAM to biomedical segmentation, such as brain tumors with less defined boundaries, challenging. In this paper, we enhanced SAM's mask decoder using transfer learning with the Decathlon brain tumor dataset. We developed three methods to encapsulate the four-dimensional data into three dimensions for SAM. An on-the-fly data augmentation approach has been used with a combination of rotations and elastic deformations to increase the size of the training dataset. Two key metrics: the Dice Similarity Coefficient (DSC) and the Hausdorff Distance 95th Percentile (HD95), have been applied to assess the performance of our segmentation models. These metrics provided valuable insights into the quality of the segmentation results. In our evaluation, we compared this improved model to two benchmarks: the pretrained SAM and the widely used model, nnUNetv2. We find that the improved SAM shows considerable improvement over the pretrained SAM, while nnUNetv2 outperformed the improved SAM in terms of overall segmentation accuracy. Nevertheless, the improved SAM demonstrated slightly more consistent results than nnUNetv2, especially on challenging cases that can lead to larger Hausdorff distances. In the future, more advanced techniques can be applied in order to further improve the performance of SAM on brain tumor segmentation.
Interpretability-Aware Vision Transformer
Sep 14, 2023



Vision Transformers (ViTs) have become prominent models for solving various vision tasks. However, the interpretability of ViTs has not kept pace with their promising performance. While there has been a surge of interest in developing {\it post hoc} solutions to explain ViTs' outputs, these methods do not generalize to different downstream tasks and various transformer architectures. Furthermore, if ViTs are not properly trained with the given data and do not prioritize the region of interest, the {\it post hoc} methods would be less effective. Instead of developing another {\it post hoc} approach, we introduce a novel training procedure that inherently enhances model interpretability. Our interpretability-aware ViT (IA-ViT) draws inspiration from a fresh insight: both the class patch and image patches consistently generate predicted distributions and attention maps. IA-ViT is composed of a feature extractor, a predictor, and an interpreter, which are trained jointly with an interpretability-aware training objective. Consequently, the interpreter simulates the behavior of the predictor and provides a faithful explanation through its single-head self-attention mechanism. Our comprehensive experimental results demonstrate the effectiveness of IA-ViT in several image classification tasks, with both qualitative and quantitative evaluations of model performance and interpretability. Source code is available from: https://github.com/qiangyao1988/IA-ViT.
Auto-Prompting SAM for Mobile Friendly 3D Medical Image Segmentation
Aug 28, 2023



The Segment Anything Model (SAM) has rapidly been adopted for segmenting a wide range of natural images. However, recent studies have indicated that SAM exhibits subpar performance on 3D medical image segmentation tasks. In addition to the domain gaps between natural and medical images, disparities in the spatial arrangement between 2D and 3D images, the substantial computational burden imposed by powerful GPU servers, and the time-consuming manual prompt generation impede the extension of SAM to a broader spectrum of medical image segmentation applications. To address these challenges, in this work, we introduce a novel method, AutoSAM Adapter, designed specifically for 3D multi-organ CT-based segmentation. We employ parameter-efficient adaptation techniques in developing an automatic prompt learning paradigm to facilitate the transformation of the SAM model's capabilities to 3D medical image segmentation, eliminating the need for manually generated prompts. Furthermore, we effectively transfer the acquired knowledge of the AutoSAM Adapter to other lightweight models specifically tailored for 3D medical image analysis, achieving state-of-the-art (SOTA) performance on medical image segmentation tasks. Through extensive experimental evaluation, we demonstrate the AutoSAM Adapter as a critical foundation for effectively leveraging the emerging ability of foundation models in 2D natural image segmentation for 3D medical image segmentation.
Fairness-aware Vision Transformer via Debiased Self-Attention
Jan 31, 2023



Vision Transformer (ViT) has recently gained significant interest in solving computer vision (CV) problems due to its capability of extracting informative features and modeling long-range dependencies through the self-attention mechanism. To fully realize the advantages of ViT in real-world applications, recent works have explored the trustworthiness of ViT, including its robustness and explainability. However, another desiderata, fairness has not yet been adequately addressed in the literature. We establish that the existing fairness-aware algorithms (primarily designed for CNNs) do not perform well on ViT. This necessitates the need for developing our novel framework via Debiased Self-Attention (DSA). DSA is a fairness-through-blindness approach that enforces ViT to eliminate spurious features correlated with the sensitive attributes for bias mitigation. Notably, adversarial examples are leveraged to locate and mask the spurious features in the input image patches. In addition, DSA utilizes an attention weights alignment regularizer in the training objective to encourage learning informative features for target prediction. Importantly, our DSA framework leads to improved fairness guarantees over prior works on multiple prediction tasks without compromising target prediction performance
Negative Flux Aggregation to Estimate Feature Attributions
Jan 17, 2023



There are increasing demands for understanding deep neural networks' (DNNs) behavior spurred by growing security and/or transparency concerns. Due to multi-layer nonlinearity of the deep neural network architectures, explaining DNN predictions still remains as an open problem, preventing us from gaining a deeper understanding of the mechanisms. To enhance the explainability of DNNs, we estimate the input feature's attributions to the prediction task using divergence and flux. Inspired by the divergence theorem in vector analysis, we develop a novel Negative Flux Aggregation (NeFLAG) formulation and an efficient approximation algorithm to estimate attribution map. Unlike the previous techniques, ours doesn't rely on fitting a surrogate model nor need any path integration of gradients. Both qualitative and quantitative experiments demonstrate a superior performance of NeFLAG in generating more faithful attribution maps than the competing methods.
Learning Compact Features via In-Training Representation Alignment
Nov 23, 2022



Deep neural networks (DNNs) for supervised learning can be viewed as a pipeline of the feature extractor (i.e., last hidden layer) and a linear classifier (i.e., output layer) that are trained jointly with stochastic gradient descent (SGD) on the loss function (e.g., cross-entropy). In each epoch, the true gradient of the loss function is estimated using a mini-batch sampled from the training set and model parameters are then updated with the mini-batch gradients. Although the latter provides an unbiased estimation of the former, they are subject to substantial variances derived from the size and number of sampled mini-batches, leading to noisy and jumpy updates. To stabilize such undesirable variance in estimating the true gradients, we propose In-Training Representation Alignment (ITRA) that explicitly aligns feature distributions of two different mini-batches with a matching loss in the SGD training process. We also provide a rigorous analysis of the desirable effects of the matching loss on feature representation learning: (1) extracting compact feature representation; (2) reducing over-adaption on mini-batches via an adaptive weighting mechanism; and (3) accommodating to multi-modalities. Finally, we conduct large-scale experiments on both image and text classifications to demonstrate its superior performance to the strong baselines.
Coupling User Preference with External Rewards to Enable Driver-centered and Resource-aware EV Charging Recommendation
Oct 23, 2022Electric Vehicle (EV) charging recommendation that both accommodates user preference and adapts to the ever-changing external environment arises as a cost-effective strategy to alleviate the range anxiety of private EV drivers. Previous studies focus on centralized strategies to achieve optimized resource allocation, particularly useful for privacy-indifferent taxi fleets and fixed-route public transits. However, private EV driver seeks a more personalized and resource-aware charging recommendation that is tailor-made to accommodate the user preference (when and where to charge) yet sufficiently adaptive to the spatiotemporal mismatch between charging supply and demand. Here we propose a novel Regularized Actor-Critic (RAC) charging recommendation approach that would allow each EV driver to strike an optimal balance between the user preference (historical charging pattern) and the external reward (driving distance and wait time). Experimental results on two real-world datasets demonstrate the unique features and superior performance of our approach to the competing methods.
FocalUNETR: A Focal Transformer for Boundary-aware Segmentation of CT Images
Oct 06, 2022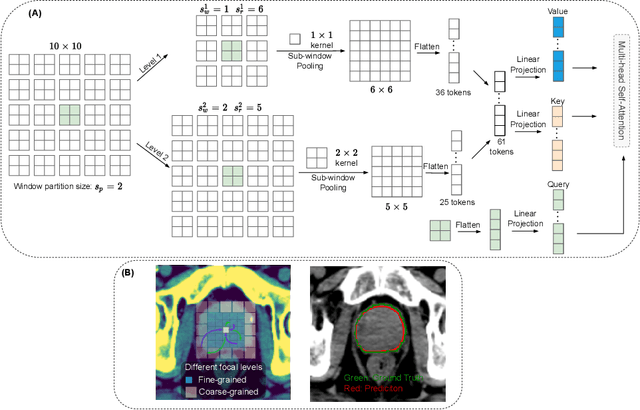
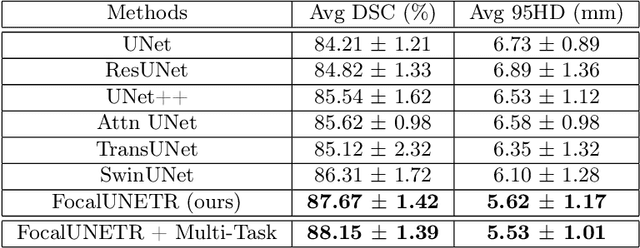
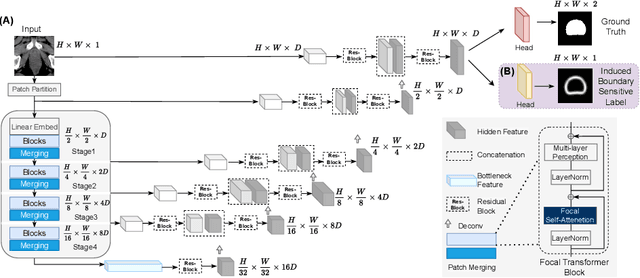

Computed Tomography (CT) based precise prostate segmentation for treatment planning is challenging due to (1) the unclear boundary of prostate derived from CTs poor soft tissue contrast, and (2) the limitation of convolutional neural network based models in capturing long-range global context. Here we propose a focal transformer based image segmentation architecture to effectively and efficiently extract local visual features and global context from CT images. Furthermore, we design a main segmentation task and an auxiliary boundary-induced label regression task as regularization to simultaneously optimize segmentation results and mitigate the unclear boundary effect, particularly in unseen data set. Extensive experiments on a large data set of 400 prostate CT scans demonstrate the superior performance of our focal transformer to the competing methods on the prostate segmentation task.