 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHiExpan: Task-Guided Taxonomy Construction by Hierarchical Tree Expansion
Oct 17, 2019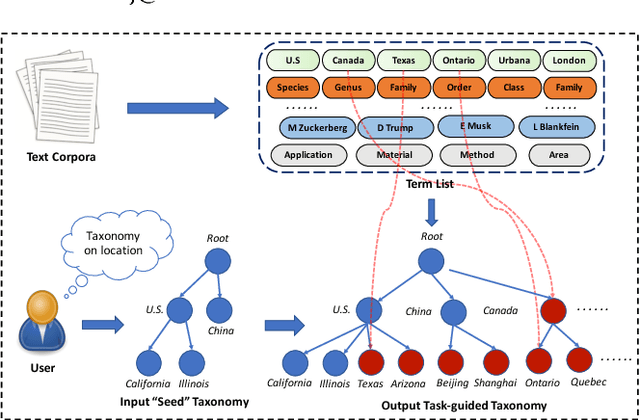
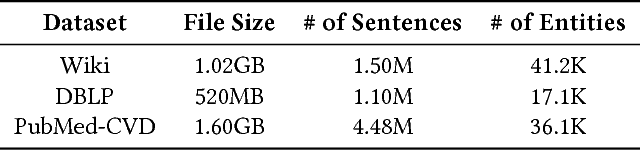
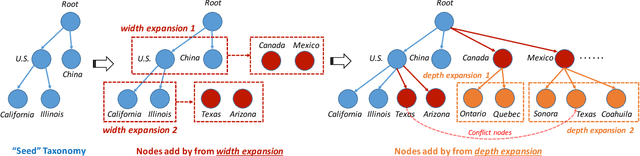
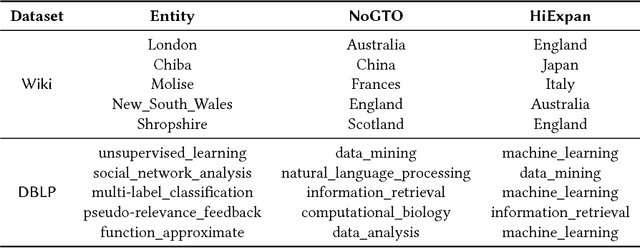
Taxonomies are of great value to many knowledge-rich applications. As the manual taxonomy curation costs enormous human effects, automatic taxonomy construction is in great demand. However, most existing automatic taxonomy construction methods can only build hypernymy taxonomies wherein each edge is limited to expressing the "is-a" relation. Such a restriction limits their applicability to more diverse real-world tasks where the parent-child may carry different relations. In this paper, we aim to construct a task-guided taxonomy from a domain-specific corpus and allow users to input a "seed" taxonomy, serving as the task guidance. We propose an expansion-based taxonomy construction framework, namely HiExpan, which automatically generates key term list from the corpus and iteratively grows the seed taxonomy. Specifically, HiExpan views all children under each taxonomy node forming a coherent set and builds the taxonomy by recursively expanding all these sets. Furthermore, HiExpan incorporates a weakly-supervised relation extraction module to extract the initial children of a newly-expanded node and adjusts the taxonomy tree by optimizing its global structure. Our experiments on three real datasets from different domains demonstrate the effectiveness of HiExpan for building task-guided taxonomies.
SetExpan: Corpus-Based Set Expansion via Context Feature Selection and Rank Ensemble
Oct 17, 2019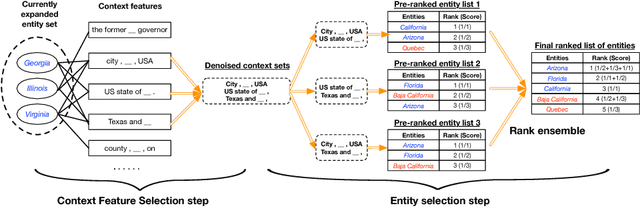
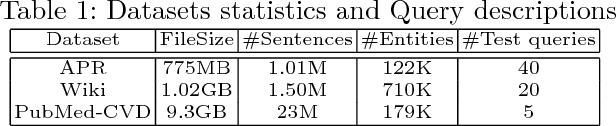
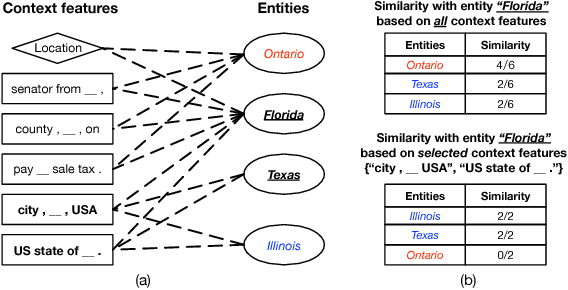
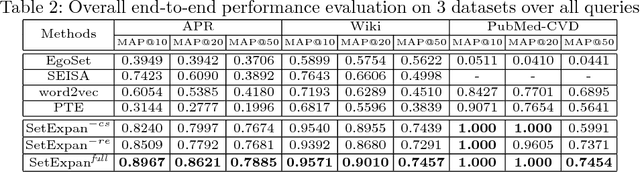
Corpus-based set expansion (i.e., finding the "complete" set of entities belonging to the same semantic class, based on a given corpus and a tiny set of seeds) is a critical task in knowledge discovery. It may facilitate numerous downstream applications, such as information extraction, taxonomy induction, question answering, and web search. To discover new entities in an expanded set, previous approaches either make one-time entity ranking based on distributional similarity, or resort to iterative pattern-based bootstrapping. The core challenge for these methods is how to deal with noisy context features derived from free-text corpora, which may lead to entity intrusion and semantic drifting. In this study, we propose a novel framework, SetExpan, which tackles this problem, with two techniques: (1) a context feature selection method that selects clean context features for calculating entity-entity distributional similarity, and (2) a ranking-based unsupervised ensemble method for expanding entity set based on denoised context features. Experiments on three datasets show that SetExpan is robust and outperforms previous state-of-the-art methods in terms of mean average precision.