 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-Shot Anomaly Detection in Battery Thermal Images Using Visual Question Answering with Prior Knowledge
May 22, 2025



Batteries are essential for various applications, including electric vehicles and renewable energy storage, making safety and efficiency critical concerns. Anomaly detection in battery thermal images helps identify failures early, but traditional deep learning methods require extensive labeled data, which is difficult to obtain, especially for anomalies due to safety risks and high data collection costs. To overcome this, we explore zero-shot anomaly detection using Visual Question Answering (VQA) models, which leverage pretrained knowledge and textbased prompts to generalize across vision tasks. By incorporating prior knowledge of normal battery thermal behavior, we design prompts to detect anomalies without battery-specific training data. We evaluate three VQA models (ChatGPT-4o, LLaVa-13b, and BLIP-2) analyzing their robustness to prompt variations, repeated trials, and qualitative outputs. Despite the lack of finetuning on battery data, our approach demonstrates competitive performance compared to state-of-the-art models that are trained with the battery data. Our findings highlight the potential of VQA-based zero-shot learning for battery anomaly detection and suggest future directions for improving its effectiveness.
Face-GCN: A Graph Convolutional Network for 3D Dynamic Face Identification/Recognition
Apr 20, 2021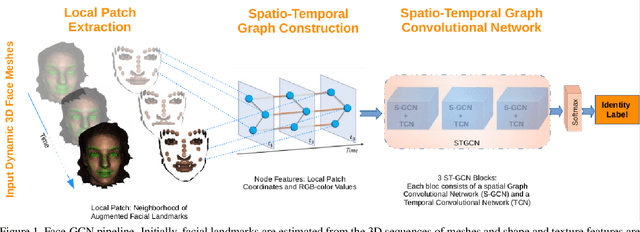
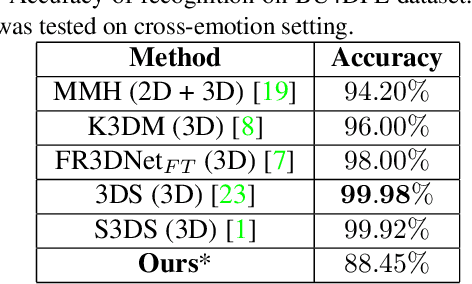


Face identification/recognition has significantly advanced over the past years. However, most of the proposed approaches rely on static RGB frames and on neutral facial expressions. This has two disadvantages. First, important facial shape cues are ignored. Second, facial deformations due to expressions can have an impact on the performance of such a method. In this paper, we propose a novel framework for dynamic 3D face identification/recognition based on facial keypoints. Each dynamic sequence of facial expressions is represented as a spatio-temporal graph, which is constructed using 3D facial landmarks. Each graph node contains local shape and texture features that are extracted from its neighborhood. For the classification/identification of faces, a Spatio-temporal Graph Convolutional Network (ST-GCN) is used. Finally, we evaluate our approach on a challenging dynamic 3D facial expression dataset.