 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Topic Modeling of Psychotherapy Sessions
Apr 13, 2022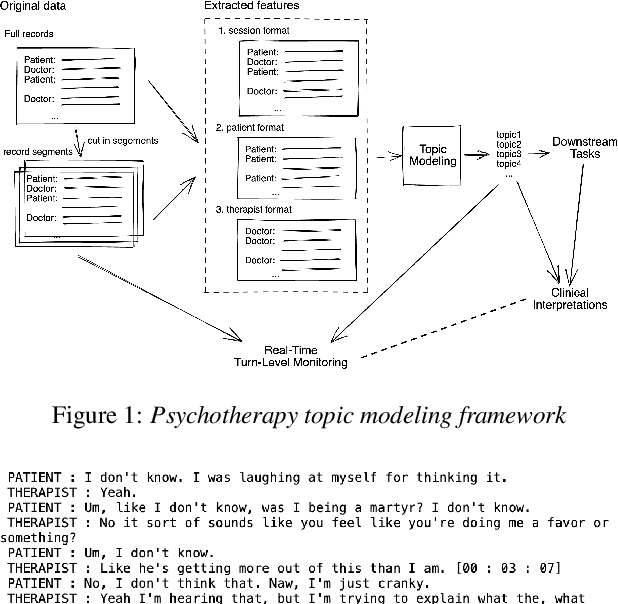


In this work, we compare different neural topic modeling methods in learning the topical propensities of different psychiatric conditions from the psychotherapy session transcripts parsed from speech recordings. We also incorporate temporal modeling to put this additional interpretability to action by parsing out topic similarities as a time series in a turn-level resolution. We believe this topic modeling framework can offer interpretable insights for the therapist to optimally decide his or her strategy and improve the psychotherapy effectiveness.
Deep Annotation of Therapeutic Working Alliance in Psychotherapy
Apr 12, 2022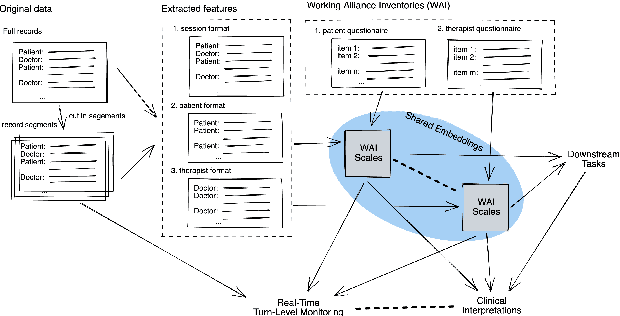



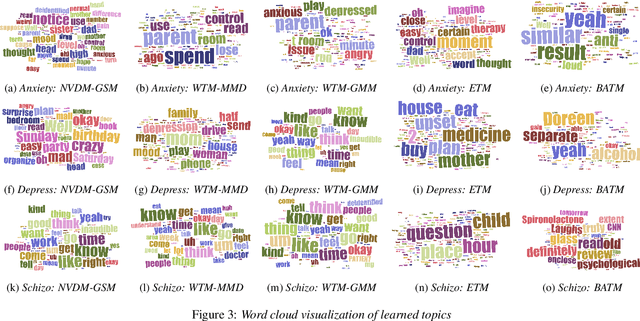
The therapeutic working alliance is an important predictor of the outcome of the psychotherapy treatment. In practice, the working alliance is estimated from a set of scoring questionnaires in an inventory that both the patient and the therapists fill out. In this work, we propose an analytical framework of directly inferring the therapeutic working alliance from the natural language within the psychotherapy sessions in a turn-level resolution with deep embeddings such as the Doc2Vec and SentenceBERT models. The transcript of each psychotherapy session can be transcribed and generated in real-time from the session speech recordings, and these embedded dialogues are compared with the distributed representations of the statements in the working alliance inventory. We demonstrate, in a real-world dataset with over 950 sessions of psychotherapy treatments in anxiety, depression, schizophrenia and suicidal patients, the effectiveness of this method in mapping out trajectories of patient-therapist alignment and the interpretability that can offer insights in clinical psychiatry. We believe such a framework can be provide timely feedback to the therapist regarding the quality of the conversation in interview sessions.
Optimal Epidemic Control as a Contextual Combinatorial Bandit with Budget
Jun 30, 2021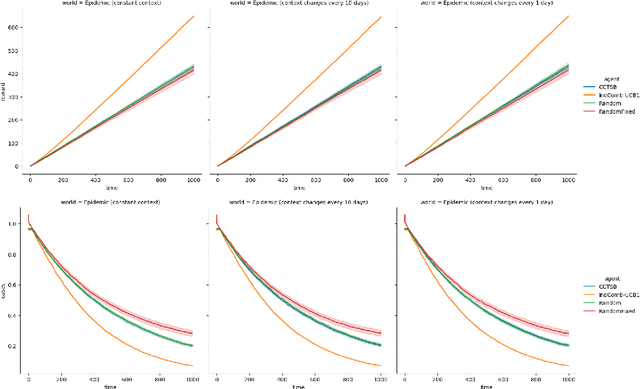
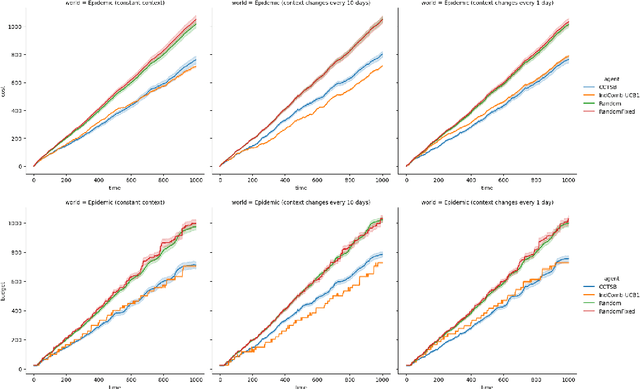
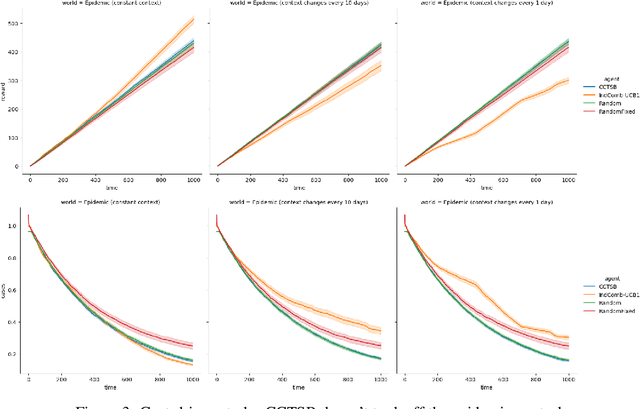
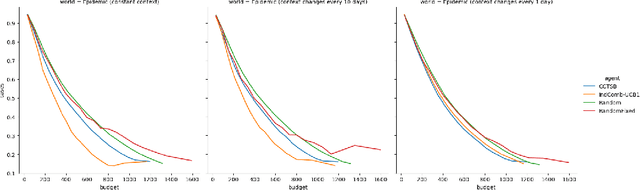
In light of the COVID-19 pandemic, it is an open challenge and critical practical problem to find a optimal way to dynamically prescribe the best policies that balance both the governmental resources and epidemic control in different countries and regions. To solve this multi-dimensional tradeoff of exploitation and exploration, we formulate this technical challenge as a contextual combinatorial bandit problem that jointly optimizes a multi-criteria reward function. Given the historical daily cases in a region and the past intervention plans in place, the agent should generate useful intervention plans that policy makers can implement in real time to minimizing both the number of daily COVID-19 cases and the stringency of the recommended interventions. We prove this concept with simulations of multiple realistic policy making scenarios.
Reinforcement Learning with Algorithms from Probabilistic Structure Estimation
Mar 15, 2021



Reinforcement learning (RL) algorithms aim to learn optimal decisions in unknown environments through experience of taking actions and observing the rewards gained. In some cases, the environment is not influenced by the actions of the RL agent, in which case the problem can be modeled as a contextual multi-armed bandit and lightweight \emph{myopic} algorithms can be employed. On the other hand, when the RL agent's actions affect the environment, the problem must be modeled as a Markov decision process and more complex RL algorithms are required which take the future effects of actions into account. Moreover, in many modern RL settings, it is unknown from the outset whether or not the agent's actions will impact the environment and it is often not possible to determine which RL algorithm is most fitting. In this work, we propose to avoid this dilemma entirely and incorporate a choice mechanism into our RL framework. Rather than assuming a specific problem structure, we use a probabilistic structure estimation procedure based on a likelihood-ratio (LR) test to make a more informed selection of learning algorithm. We derive a sufficient condition under which myopic policies are optimal, present an LR test for this condition, and derive a bound on the regret of our framework. We provide examples of real-world scenarios where our framework is needed and provide extensive simulations to validate our approach.
Etat de l'art sur l'application des bandits multi-bras
Jan 04, 2021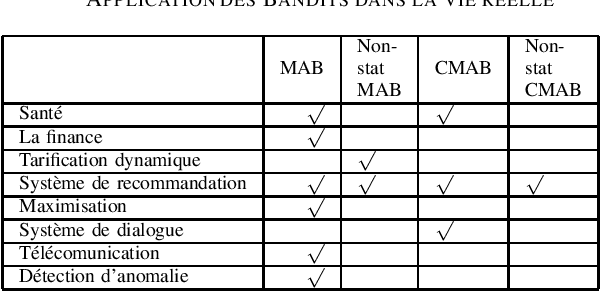
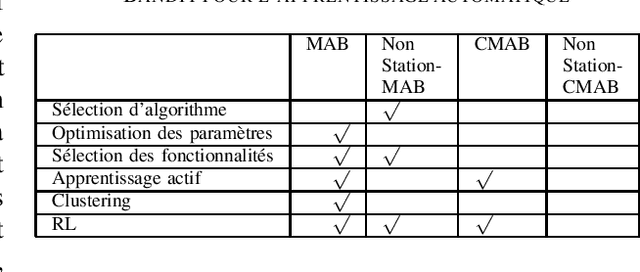
The Multi-armed bandit offer the advantage to learn and exploit the already learnt knowledge at the same time. This capability allows this approach to be applied in different domains, going from clinical trials where the goal is investigating the effects of different experimental treatments while minimizing patient losses, to adaptive routing where the goal is to minimize the delays in a network. This article provides a review of the recent results on applying bandit to real-life scenario and summarize the state of the art for each of these fields. Different techniques has been proposed to solve this problem setting, like epsilon-greedy, Upper confident bound (UCB) and Thompson Sampling (TS). We are showing here how this algorithms were adapted to solve the different problems of exploration exploitation.
Predicting Human Decision Making in Psychological Tasks with Recurrent Neural Networks
Oct 22, 2020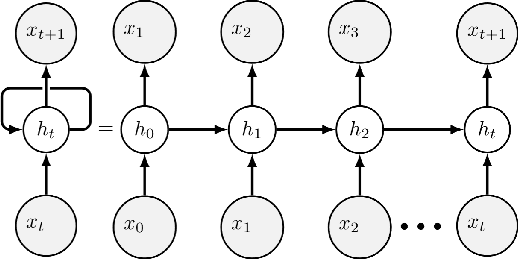
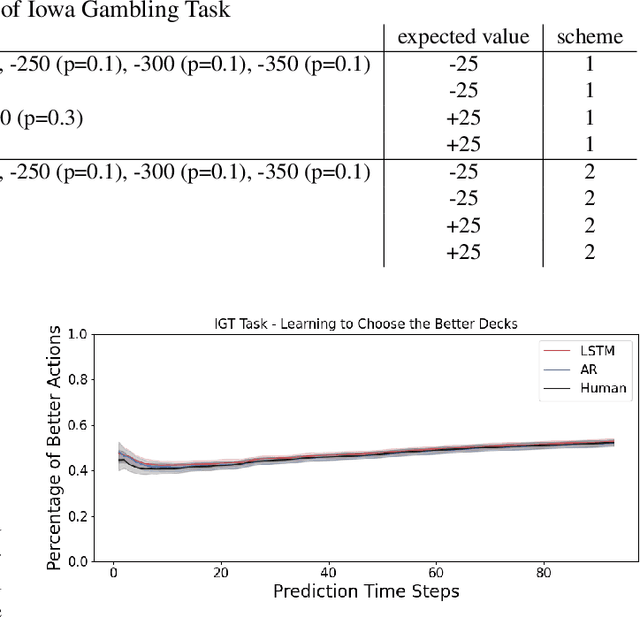
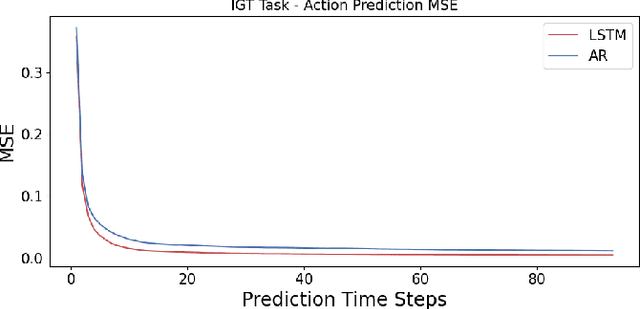
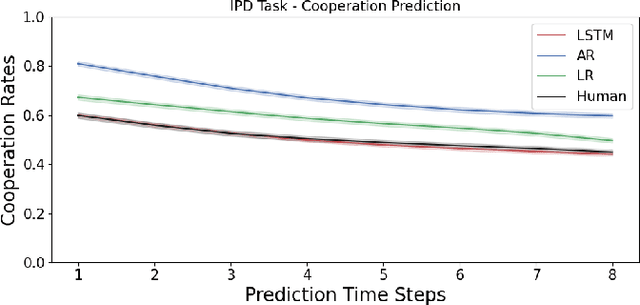
Unlike traditional time series, the action sequences of human decision making usually involve many cognitive processes such as beliefs, desires, intentions and theory of mind, i.e. what others are thinking. This makes predicting human decision making challenging to be treated agnostically to the underlying psychological mechanisms. We propose to use a recurrent neural network architecture based on long short-term memory networks (LSTM) to predict the time series of the actions taken by the human subjects at each step of their decision making, the first application of such methods in this research domain. We trained our prediction networks on the behavioral data from several published psychological experiments of human decision making, and demonstrated a clear advantage over the state-of-the-art methods in predicting human decision making trajectories in both single-agent scenarios such as Iowa Gambling Task and multi-agent scenarios such as Iterated Prisoner's Dilemma.
Learned Fine-Tuner for Incongruous Few-Shot Learning
Oct 20, 2020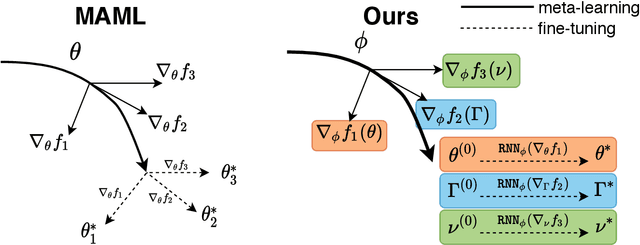
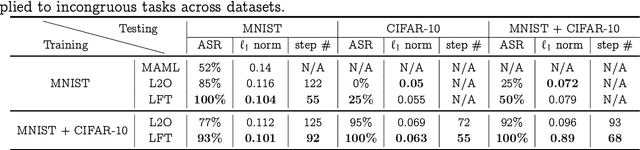
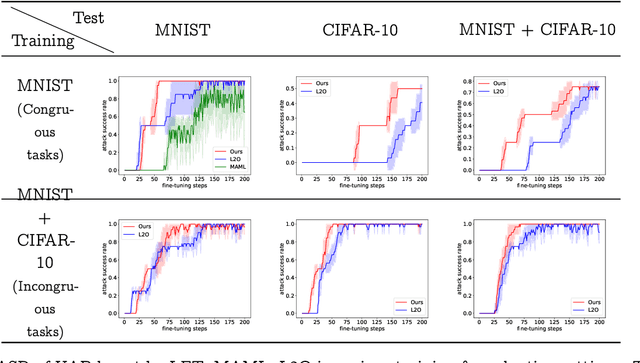
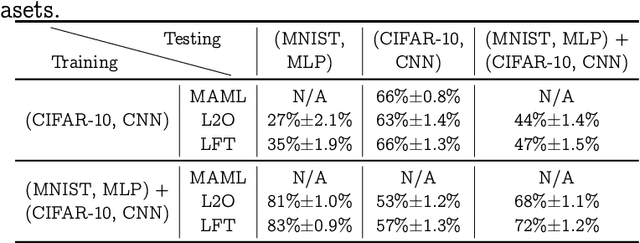
Model-agnostic meta-learning (MAML) effectively meta-learns an initialization of model parameters for few-shot learning where all learning problems share the same format of model parameters -- congruous meta-learning. We extend MAML to incongruous meta-learning where different yet related few-shot learning problems may not share any model parameters. A Learned Fine Tuner (LFT) is used to replace hand-designed optimizers such as SGD for the task-specific fine-tuning. Here, MAML instead meta-learns the parameters of this LFT across incongruous tasks leveraging the learning-to-optimize (L2O) framework such that models fine-tuned with LFT (even from random initializations) adapt quickly to new tasks. As novel contributions, we show that the use of LFT within MAML (i) offers the capability to tackle few-shot learning tasks by meta-learning across incongruous yet related problems (e.g., classification over images of different sizes and model architectures), and (ii) can efficiently work with first-order and derivative-free few-shot learning problems. Theoretically, we quantify the difference between LFT (for MAML) and L2O. Empirically, we demonstrate the effectiveness of LFT through both synthetic and real problems and a novel application of generating universal adversarial attacks across different image sources in the few-shot learning regime.
Double-Linear Thompson Sampling for Context-Attentive Bandits
Oct 15, 2020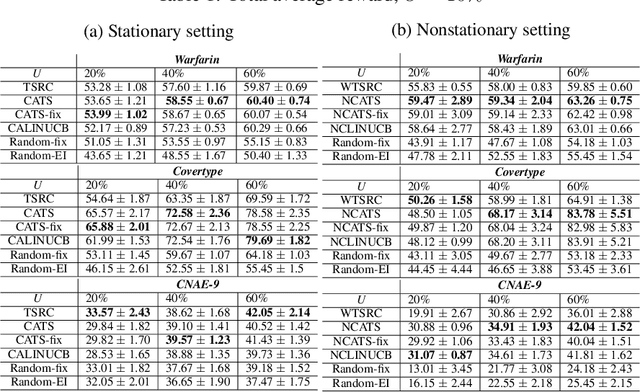
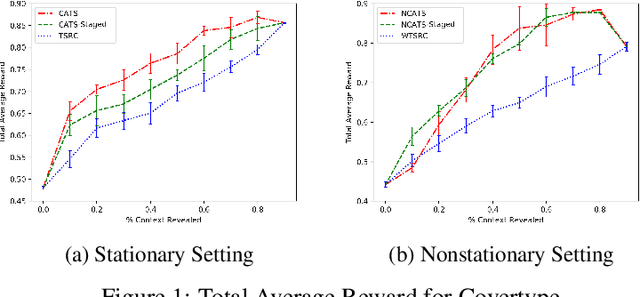
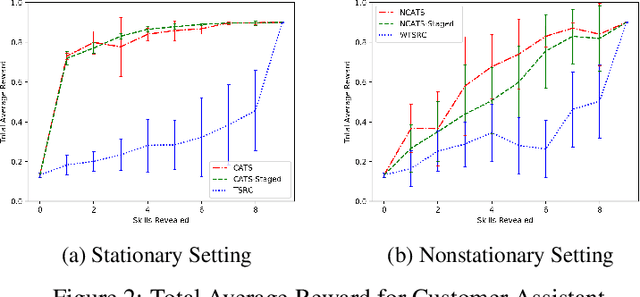
In this paper, we analyze and extend an online learning framework known as Context-Attentive Bandit, motivated by various practical applications, from medical diagnosis to dialog systems, where due to observation costs only a small subset of a potentially large number of context variables can be observed at each iteration;however, the agent has a freedom to choose which variables to observe. We derive a novel algorithm, called Context-Attentive Thompson Sampling (CATS), which builds upon the Linear Thompson Sampling approach, adapting it to Context-Attentive Bandit setting. We provide a theoretical regret analysis and an extensive empirical evaluation demonstrating advantages of the proposed approach over several baseline methods on a variety of real-life datasets
Spectral Clustering using Eigenspectrum Shape Based Nystrom Sampling
Jul 21, 2020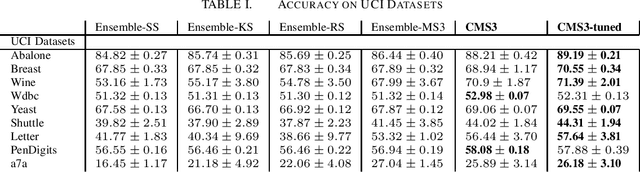
Spectral clustering has shown a superior performance in analyzing the cluster structure. However, its computational complexity limits its application in analyzing large-scale data. To address this problem, many low-rank matrix approximating algorithms are proposed, including the Nystrom method - an approach with proven approximate error bounds. There are several algorithms that provide recipes to construct Nystrom approximations with variable accuracies and computing times. This paper proposes a scalable Nystrom-based clustering algorithm with a new sampling procedure, Centroid Minimum Sum of Squared Similarities (CMS3), and a heuristic on when to use it. Our heuristic depends on the eigen spectrum shape of the dataset, and yields competitive low-rank approximations in test datasets compared to the other state-of-the-art methods
Contextual Bandit with Missing Rewards
Jul 19, 2020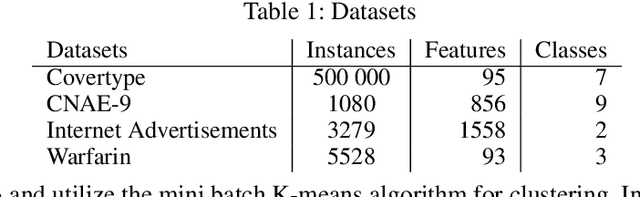
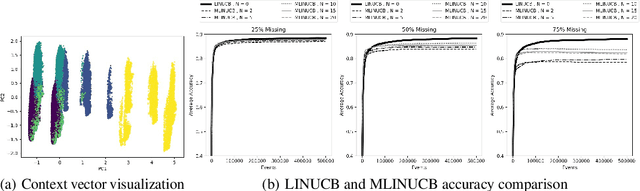
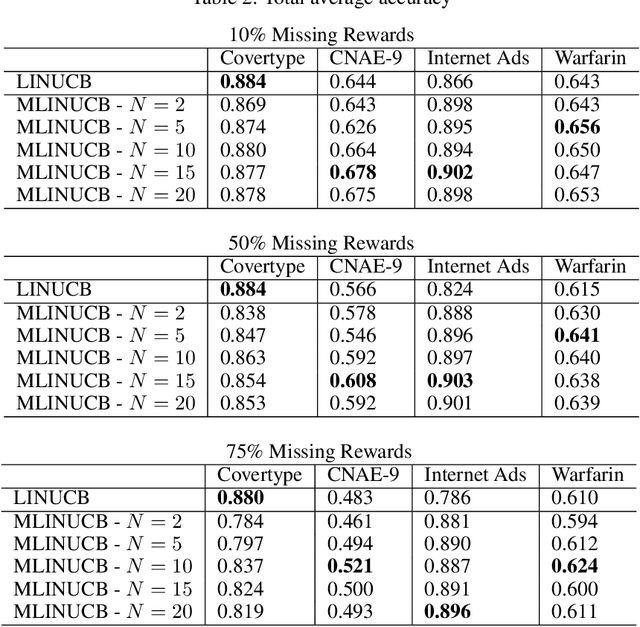
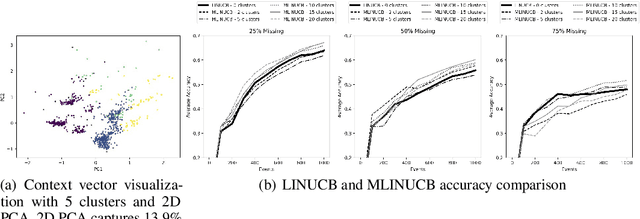
We consider a novel variant of the contextual bandit problem (i.e., the multi-armed bandit with side-information, or context, available to a decision-maker) where the reward associated with each context-based decision may not always be observed("missing rewards"). This new problem is motivated by certain online settings including clinical trial and ad recommendation applications. In order to address the missing rewards setting, we propose to combine the standard contextual bandit approach with an unsupervised learning mechanism such as clustering. Unlike standard contextual bandit methods, by leveraging clustering to estimate missing reward, we are able to learn from each incoming event, even those with missing rewards. Promising empirical results are obtained on several real-life datasets.