 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCOMPASS: Computational Mapping of Patient-Therapist Alliance Strategies with Language Modeling
Feb 22, 2024The therapeutic working alliance is a critical factor in predicting the success of psychotherapy treatment. Traditionally, working alliance assessment relies on questionnaires completed by both therapists and patients. In this paper, we present COMPASS, a novel framework to directly infer the therapeutic working alliance from the natural language used in psychotherapy sessions. Our approach utilizes advanced large language models to analyze transcripts of psychotherapy sessions and compare them with distributed representations of statements in the working alliance inventory. Analyzing a dataset of over 950 sessions covering diverse psychiatric conditions, we demonstrate the effectiveness of our method in microscopically mapping patient-therapist alignment trajectories and providing interpretability for clinical psychiatry and in identifying emerging patterns related to the condition being treated. By employing various neural topic modeling techniques in combination with generative language prompting, we analyze the topical characteristics of different psychiatric conditions and incorporate temporal modeling to capture the evolution of topics at a turn-level resolution. This combined framework enhances the understanding of therapeutic interactions, enabling timely feedback for therapists regarding conversation quality and providing interpretable insights to improve the effectiveness of psychotherapy.
Interpolating Item and User Fairness in Recommendation Systems
Jun 12, 2023Online platforms employ recommendation systems to enhance customer engagement and drive revenue. However, in a multi-sided platform where the platform interacts with diverse stakeholders such as sellers (items) and customers (users), each with their own desired outcomes, finding an appropriate middle ground becomes a complex operational challenge. In this work, we investigate the ``price of fairness'', which captures the platform's potential compromises when balancing the interests of different stakeholders. Motivated by this, we propose a fair recommendation framework where the platform maximizes its revenue while interpolating between item and user fairness constraints. We further examine the fair recommendation problem in a more realistic yet challenging online setting, where the platform lacks knowledge of user preferences and can only observe binary purchase decisions. To address this, we design a low-regret online optimization algorithm that preserves the platform's revenue while achieving fairness for both items and users. Finally, we demonstrate the effectiveness of our framework and proposed method via a case study on MovieLens data.
Utterance Classification with Logical Neural Network: Explainable AI for Mental Disorder Diagnosis
Jun 06, 2023In response to the global challenge of mental health problems, we proposes a Logical Neural Network (LNN) based Neuro-Symbolic AI method for the diagnosis of mental disorders. Due to the lack of effective therapy coverage for mental disorders, there is a need for an AI solution that can assist therapists with the diagnosis. However, current Neural Network models lack explainability and may not be trusted by therapists. The LNN is a Recurrent Neural Network architecture that combines the learning capabilities of neural networks with the reasoning capabilities of classical logic-based AI. The proposed system uses input predicates from clinical interviews to output a mental disorder class, and different predicate pruning techniques are used to achieve scalability and higher scores. In addition, we provide an insight extraction method to aid therapists with their diagnosis. The proposed system addresses the lack of explainability of current Neural Network models and provides a more trustworthy solution for mental disorder diagnosis.
Towards Healthy AI: Large Language Models Need Therapists Too
Apr 02, 2023


Recent advances in large language models (LLMs) have led to the development of powerful AI chatbots capable of engaging in natural and human-like conversations. However, these chatbots can be potentially harmful, exhibiting manipulative, gaslighting, and narcissistic behaviors. We define Healthy AI to be safe, trustworthy and ethical. To create healthy AI systems, we present the SafeguardGPT framework that uses psychotherapy to correct for these harmful behaviors in AI chatbots. The framework involves four types of AI agents: a Chatbot, a "User," a "Therapist," and a "Critic." We demonstrate the effectiveness of SafeguardGPT through a working example of simulating a social conversation. Our results show that the framework can improve the quality of conversations between AI chatbots and humans. Although there are still several challenges and directions to be addressed in the future, SafeguardGPT provides a promising approach to improving the alignment between AI chatbots and human values. By incorporating psychotherapy and reinforcement learning techniques, the framework enables AI chatbots to learn and adapt to human preferences and values in a safe and ethical way, contributing to the development of a more human-centric and responsible AI.
Psychotherapy AI Companion with Reinforcement Learning Recommendations and Interpretable Policy Dynamics
Mar 16, 2023



We introduce a Reinforcement Learning Psychotherapy AI Companion that generates topic recommendations for therapists based on patient responses. The system uses Deep Reinforcement Learning (DRL) to generate multi-objective policies for four different psychiatric conditions: anxiety, depression, schizophrenia, and suicidal cases. We present our experimental results on the accuracy of recommended topics using three different scales of working alliance ratings: task, bond, and goal. We show that the system is able to capture the real data (historical topics discussed by the therapists) relatively well, and that the best performing models vary by disorder and rating scale. To gain interpretable insights into the learned policies, we visualize policy trajectories in a 2D principal component analysis space and transition matrices. These visualizations reveal distinct patterns in the policies trained with different reward signals and trained on different clinical diagnoses. Our system's success in generating DIsorder-Specific Multi-Objective Policies (DISMOP) and interpretable policy dynamics demonstrates the potential of DRL in providing personalized and efficient therapeutic recommendations.
TherapyView: Visualizing Therapy Sessions with Temporal Topic Modeling and AI-Generated Arts
Feb 21, 2023



We present the TherapyView, a demonstration system to help therapists visualize the dynamic contents of past treatment sessions, enabled by the state-of-the-art neural topic modeling techniques to analyze the topical tendencies of various psychiatric conditions and deep learning-based image generation engine to provide a visual summary. The system incorporates temporal modeling to provide a time-series representation of topic similarities at a turn-level resolution and AI-generated artworks given the dialogue segments to provide a concise representations of the contents covered in the session, offering interpretable insights for therapists to optimize their strategies and enhance the effectiveness of psychotherapy. This system provides a proof of concept of AI-augmented therapy tools with e in-depth understanding of the patient's mental state and enabling more effective treatment.
A Survey on Compositional Generalization in Applications
Feb 02, 2023The field of compositional generalization is currently experiencing a renaissance in AI, as novel problem settings and algorithms motivated by various practical applications are being introduced, building on top of the classical compositional generalization problem. This article aims to provide a comprehensive review of top recent developments in multiple real-life applications of the compositional generalization. Specifically, we introduce a taxonomy of common applications and summarize the state-of-the-art for each of those domains. Furthermore, we identify important current trends and provide new perspectives pertaining to the future of this burgeoning field.
Dynamic Bandits with an Auto-Regressive Temporal Structure
Oct 28, 2022



Multi-armed bandit (MAB) problems are mainly studied under two extreme settings known as stochastic and adversarial. These two settings, however, do not capture realistic environments such as search engines and marketing and advertising, in which rewards stochastically change in time. Motivated by that, we introduce and study a dynamic MAB problem with stochastic temporal structure, where the expected reward of each arm is governed by an auto-regressive (AR) model. Due to the dynamic nature of the rewards, simple "explore and commit" policies fail, as all arms have to be explored continuously over time. We formalize this by characterizing a per-round regret lower bound, where the regret is measured against a strong (dynamic) benchmark. We then present an algorithm whose per-round regret almost matches our regret lower bound. Our algorithm relies on two mechanisms: (i) alternating between recently pulled arms and unpulled arms with potential, and (ii) restarting. These mechanisms enable the algorithm to dynamically adapt to changes and discard irrelevant past information at a suitable rate. In numerical studies, we further demonstrate the strength of our algorithm under different types of non-stationary settings.
Working Alliance Transformer for Psychotherapy Dialogue Classification
Oct 27, 2022

As a predictive measure of the treatment outcome in psychotherapy, the working alliance measures the agreement of the patient and the therapist in terms of their bond, task and goal. Long been a clinical quantity estimated by the patients' and therapists' self-evaluative reports, we believe that the working alliance can be better characterized using natural language processing technique directly in the dialogue transcribed in each therapy session. In this work, we propose the Working Alliance Transformer (WAT), a Transformer-based classification model that has a psychological state encoder which infers the working alliance scores by projecting the embedding of the dialogues turns onto the embedding space of the clinical inventory for working alliance. We evaluate our method in a real-world dataset with over 950 therapy sessions with anxiety, depression, schizophrenia and suicidal patients and demonstrate an empirical advantage of using information about the therapeutic states in this sequence classification task of psychotherapy dialogues.
Targeted Advertising on Social Networks Using Online Variational Tensor Regression
Aug 25, 2022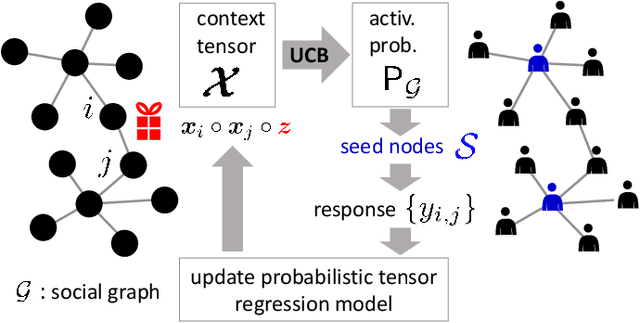

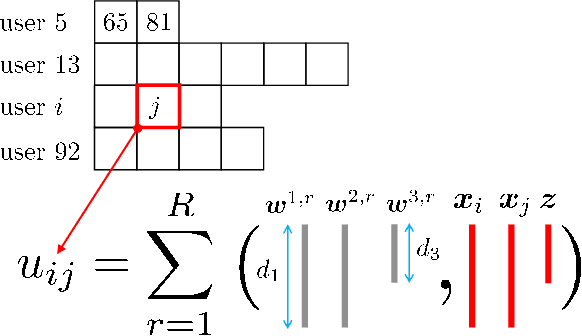
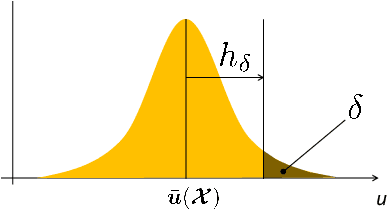
This paper is concerned with online targeted advertising on social networks. The main technical task we address is to estimate the activation probability for user pairs, which quantifies the influence one user may have on another towards purchasing decisions. This is a challenging task because one marketing episode typically involves a multitude of marketing campaigns/strategies of different products for highly diverse customers. In this paper, we propose what we believe is the first tensor-based contextual bandit framework for online targeted advertising. The proposed framework is designed to accommodate any number of feature vectors in the form of multi-mode tensor, thereby enabling to capture the heterogeneity that may exist over user preferences, products, and campaign strategies in a unified manner. To handle inter-dependency of tensor modes, we introduce an online variational algorithm with a mean-field approximation. We empirically confirm that the proposed TensorUCB algorithm achieves a significant improvement in influence maximization tasks over the benchmarks, which is attributable to its capability of capturing the user-product heterogeneity.