 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferentiable Frequency-based Disentanglement for Aerial Video Action Recognition
Sep 15, 2022
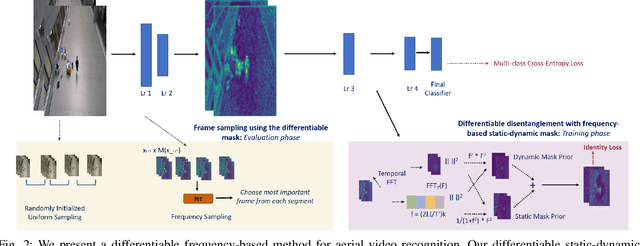

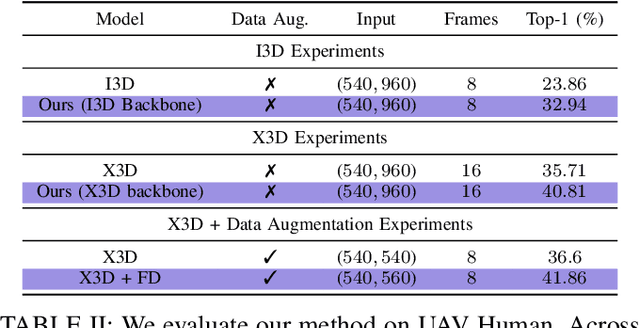
We present a learning algorithm for human activity recognition in videos. Our approach is designed for UAV videos, which are mainly acquired from obliquely placed dynamic cameras that contain a human actor along with background motion. Typically, the human actors occupy less than one-tenth of the spatial resolution. Our approach simultaneously harnesses the benefits of frequency domain representations, a classical analysis tool in signal processing, and data driven neural networks. We build a differentiable static-dynamic frequency mask prior to model the salient static and dynamic pixels in the video, crucial for the underlying task of action recognition. We use this differentiable mask prior to enable the neural network to intrinsically learn disentangled feature representations via an identity loss function. Our formulation empowers the network to inherently compute disentangled salient features within its layers. Further, we propose a cost-function encapsulating temporal relevance and spatial content to sample the most important frame within uniformly spaced video segments. We conduct extensive experiments on the UAV Human dataset and the NEC Drone dataset and demonstrate relative improvements of 5.72% - 13.00% over the state-of-the-art and 14.28% - 38.05% over the corresponding baseline model.
Placing Human Animations into 3D Scenes by Learning Interaction- and Geometry-Driven Keyframes
Sep 13, 2022
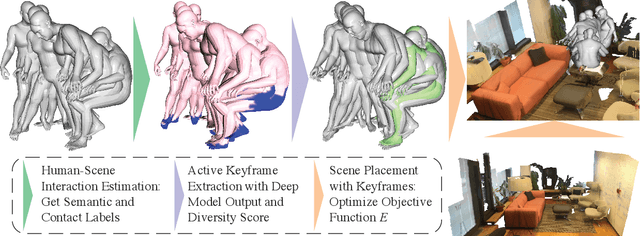
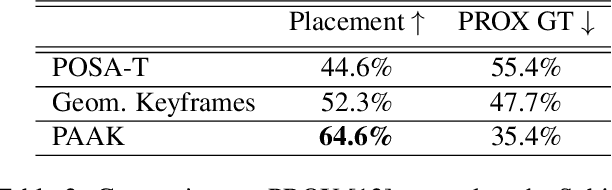
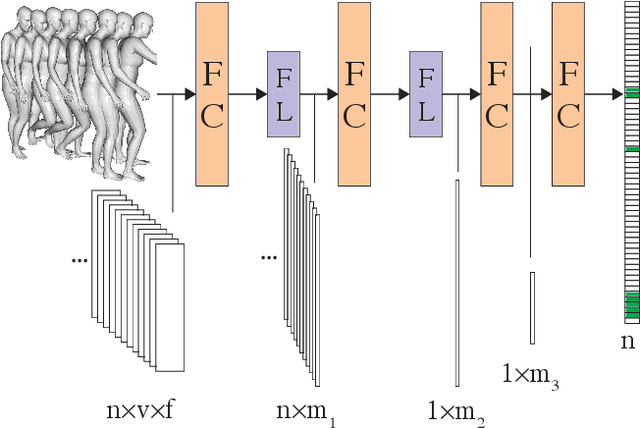
We present a novel method for placing a 3D human animation into a 3D scene while maintaining any human-scene interactions in the animation. We use the notion of computing the most important meshes in the animation for the interaction with the scene, which we call "keyframes." These keyframes allow us to better optimize the placement of the animation into the scene such that interactions in the animations (standing, laying, sitting, etc.) match the affordances of the scene (e.g., standing on the floor or laying in a bed). We compare our method, which we call PAAK, with prior approaches, including POSA, PROX ground truth, and a motion synthesis method, and highlight the benefits of our method with a perceptual study. Human raters preferred our PAAK method over the PROX ground truth data 64.6\% of the time. Additionally, in direct comparisons, the raters preferred PAAK over competing methods including 61.5\% compared to POSA.
DistillAdapt: Source-Free Active Visual Domain Adaptation
May 24, 2022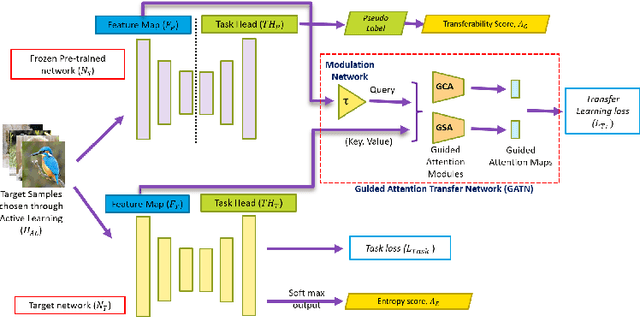

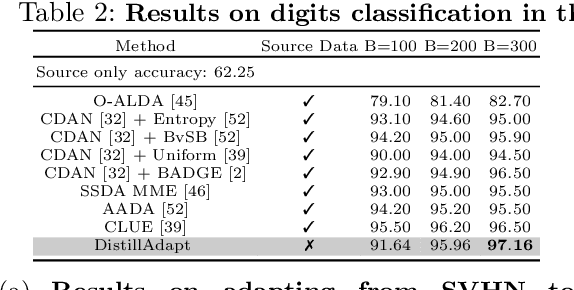
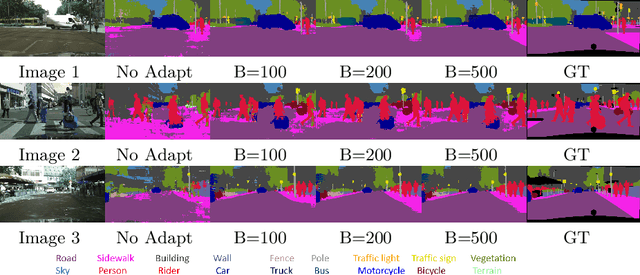
We present a novel method, DistillAdapt, for the challenging problem of Source-Free Active Domain Adaptation (SF-ADA). The problem requires adapting a pretrained source domain network to a target domain, within a provided budget for acquiring labels in the target domain, while assuming that the source data is not available for adaptation due to privacy concerns or otherwise. DistillAdapt is one of the first approaches for SF-ADA, and holistically addresses the challenges of SF-ADA via a novel Guided Attention Transfer Network (GATN) and an active learning heuristic, H_AL. The GATN enables selective distillation of features from the pre-trained network to the target network using a small subset of annotated target samples mined by H_AL. H_AL acquires samples at batch-level and balances transfer-ability from the pre-trained network and uncertainty of the target network. DistillAdapt is task-agnostic, and can be applied across visual tasks such as classification, segmentation and detection. Moreover, DistillAdapt can handle shifts in output label space. We conduct experiments and extensive ablation studies across 3 visual tasks, viz. digits classification (MNIST, SVHN), synthetic (GTA5) to real (CityScapes) image segmentation, and document layout detection (PubLayNet to DSSE). We show that our source-free approach, DistillAdapt, results in an improvement of 0.5% - 31.3% (across datasets and tasks) over prior adaptation methods that assume access to large amounts of annotated source data for adaptation.
Fourier Disentangled Space-Time Attention for Aerial Video Recognition
Mar 21, 2022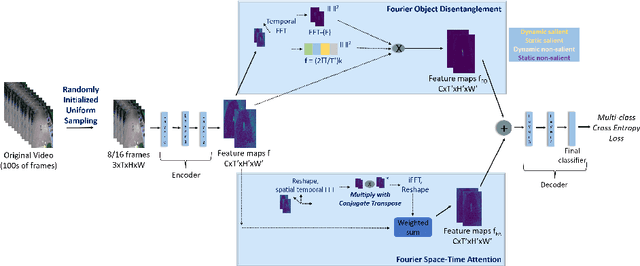


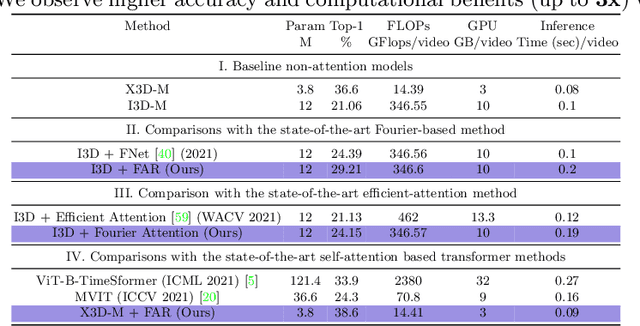
We present an algorithm, Fourier Activity Recognition (FAR), for UAV video activity recognition. Our formulation uses a novel Fourier object disentanglement method to innately separate out the human agent (which is typically small) from the background. Our disentanglement technique operates in the frequency domain to characterize the extent of temporal change of spatial pixels, and exploits convolution-multiplication properties of Fourier transform to map this representation to the corresponding object-background entangled features obtained from the network. To encapsulate contextual information and long-range space-time dependencies, we present a novel Fourier Attention algorithm, which emulates the benefits of self-attention by modeling the weighted outer product in the frequency domain. Our Fourier attention formulation uses much fewer computations than self-attention. We have evaluated our approach on multiple UAV datasets including UAV Human RGB, UAV Human Night, Drone Action, and NEC Drone. We demonstrate a relative improvement of 8.02% - 38.69% in top-1 accuracy and up to 3 times faster over prior works.
GANav: Group-wise Attention Network for Classifying Navigable Regions in Unstructured Outdoor Environments
Mar 07, 2021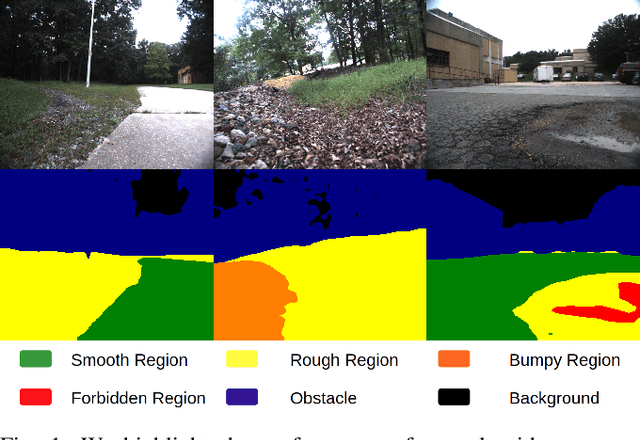
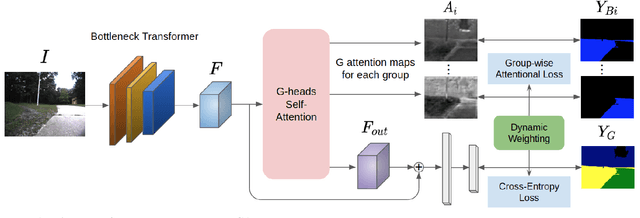

We present a new learning-based method for identifying safe and navigable regions in off-road terrains and unstructured environments from RGB images. Our approach consists of classifying groups of terrain classes based on their navigability levels using coarse-grained semantic segmentation. We propose a bottleneck transformer-based deep neural network architecture that uses a novel group-wise attention mechanism to distinguish between navigability levels of different terrains.Our group-wise attention heads enable the network to explicitly focus on the different groups and improve the accuracy. In addition, we propose a dynamic weighted cross entropy loss function to handle the long-tailed nature of the dataset. We show through extensive evaluations on the RUGD and RELLIS-3D datasets that our learning algorithm improves the accuracy of visual perception in off-road terrains for navigation. We compare our approach with prior work on these datasets and achieve an improvement over the state-of-the-art mIoU by 6.74-39.1% on RUGD and 3.82-10.64% on RELLIS-3D.
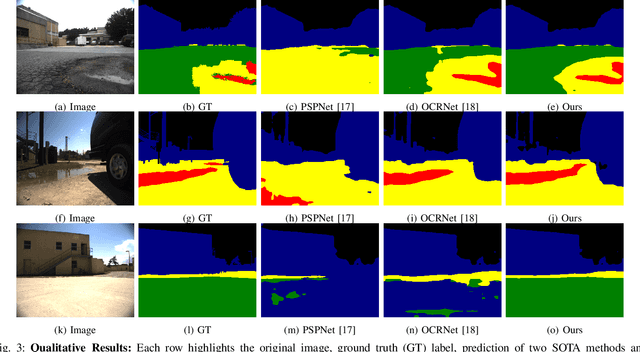
SAfE: Self-Attention Based Unsupervised Road Safety Classification in Hazardous Environments
Nov 27, 2020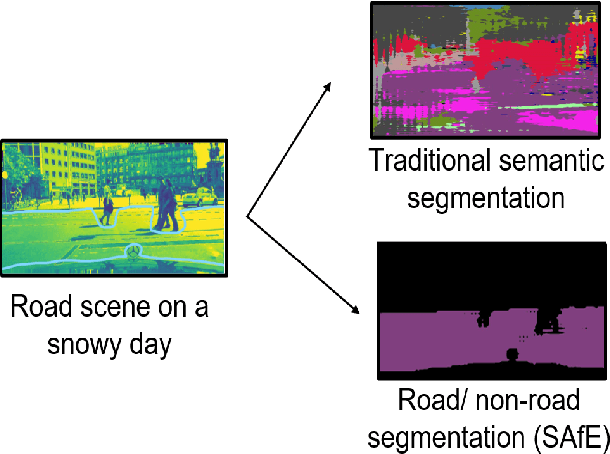
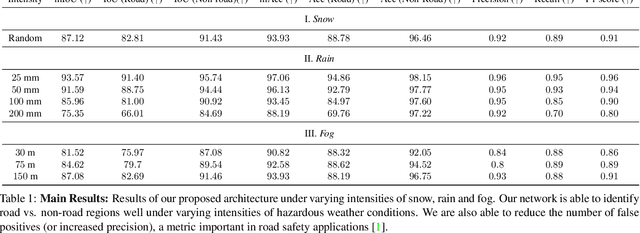


We present a novel approach SAfE that can identify parts of an outdoor scene that are safe for driving, based on attention models. Our formulation is designed for hazardous weather conditions that can impair the visibility of human drivers as well as autonomous vehicles, increasing the risk of accidents. Our approach is unsupervised and uses domain adaptation, with entropy minimization and attention transfer discriminators, to leverage the large amounts of labeled data corresponding to clear weather conditions. Our attention transfer discriminator uses attention maps from the clear weather image to help the network learn relevant regions to attend to, on the images from the hazardous weather dataset. We conduct experiments on CityScapes simulated datasets depicting various weather conditions such as rain, fog and snow under different intensities, and additionally on Berkeley Deep Drive. Our result show that using attention models improves the standard unsupervised domain adaptation performance by 29.29%. Furthermore, we also compare with unsupervised domain adaptation methods and show an improvement of at least 12.02% (mIoU) over the state-of-the-art.
Unsupervised Domain Adaptive Knowledge Distillation for Semantic Segmentation
Nov 03, 2020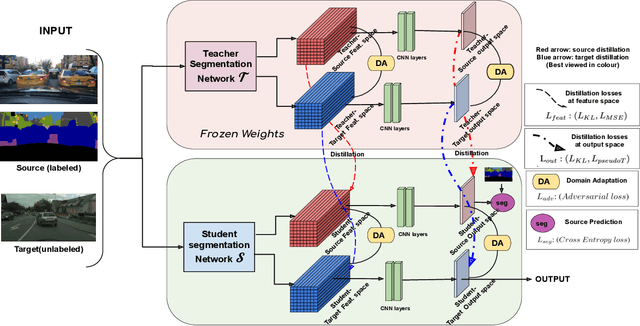

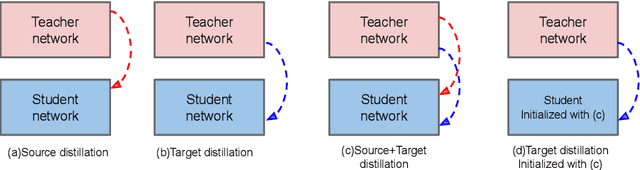

Practical autonomous driving systems face two crucial challenges: memory constraints and domain gap issues. We present an approach to learn domain adaptive knowledge in models with limited memory, thus bestowing the model with the ability to deal with these issues in a comprehensive manner. We delve into this in the context of unsupervised domain-adaptive semantic segmentation and propose a multi-level distillation strategy to effectively distil knowledge at different levels. Further, we introduce a cross entropy loss that leverages pseudo labels from the teacher. These pseudo teacher labels play a multifaceted role towards: (i) knowledge distillation from the teacher network to the student network & (ii) serving as a proxy for the ground truth for target domain images, where the problem is completely unsupervised. We introduce four paradigms for distilling domain adaptive knowledge and carry out extensive experiments and ablation studies on real-to-real and synthetic-to-real scenarios. Our experiments demonstrate the profound success of our proposed method.
BoMuDA: Boundless Multi-Source Domain Adaptive Segmentation in Unconstrained Environments
Oct 13, 2020

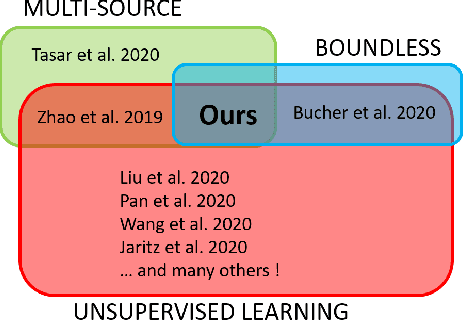
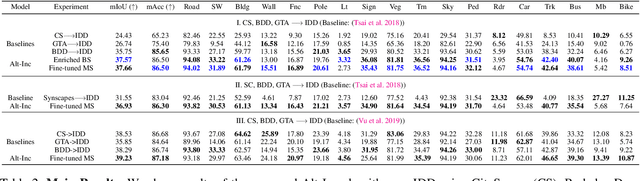
We present an unsupervised multi-source domain adaptive semantic segmentation approach in unstructured and unconstrained traffic environments. We propose a novel training strategy that alternates between single-source domain adaptation (DA) and multi-source distillation, and also between setting up an improvised cost function and optimizing it. In each iteration, the single-source DA first learns a neural network on a selected source, which is followed by a multi-source fine-tuning step using the remaining sources. We call this training routine the Alternating-Incremental ("Alt-Inc") algorithm. Furthermore, our approach is also boundless i.e. it can explicitly classify categories that do not belong to the training dataset (as opposed to labeling such objects as "unknown"). We have conducted extensive experiments and ablation studies using the Indian Driving Dataset, CityScapes, Berkeley DeepDrive, GTA V, and the Synscapes datasets, and we show that our unsupervised approach outperforms other unsupervised and semi-supervised SOTA benchmarks by 5.17% - 42.9% with a reduced model size by up to 5.2x.
Deep Atrous Guided Filter for Image Restoration in Under Display Cameras
Sep 01, 2020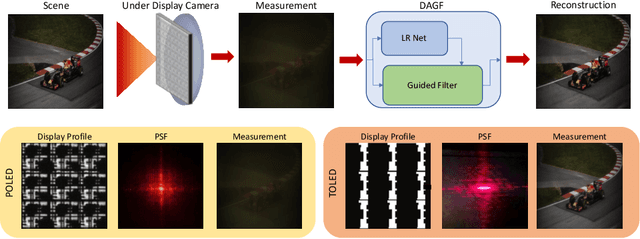
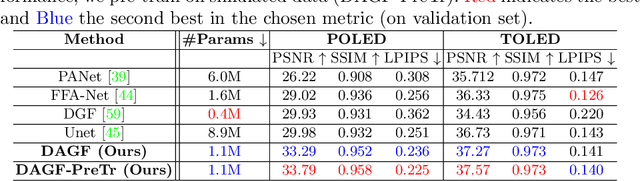
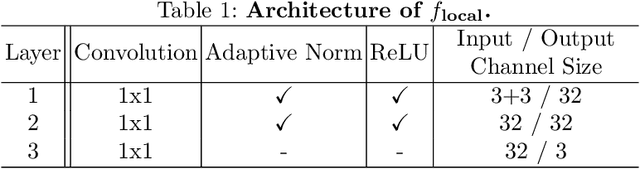

Under Display Cameras present a promising opportunity for phone manufacturers to achieve bezel-free displays by positioning the camera behind semi-transparent OLED screens. Unfortunately, such imaging systems suffer from severe image degradation due to light attenuation and diffraction effects. In this work, we present Deep Atrous Guided Filter (DAGF), a two-stage, end-to-end approach for image restoration in UDC systems. A Low-Resolution Network first restores image quality at low-resolution, which is subsequently used by the Guided Filter Network as a filtering input to produce a high-resolution output. Besides the initial downsampling, our low-resolution network uses multiple, parallel atrous convolutions to preserve spatial resolution and emulates multi-scale processing. Our approach's ability to directly train on megapixel images results in significant performance improvement. We additionally propose a simple simulation scheme to pre-train our model and boost performance. Our overall framework ranks 2nd and 5th in the RLQ-TOD'20 UDC Challenge for POLED and TOLED displays, respectively.
UDC 2020 Challenge on Image Restoration of Under-Display Camera: Methods and Results
Aug 18, 2020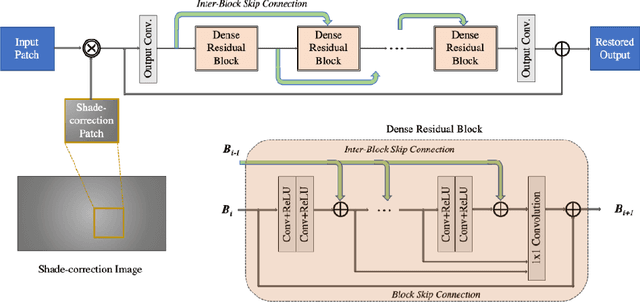
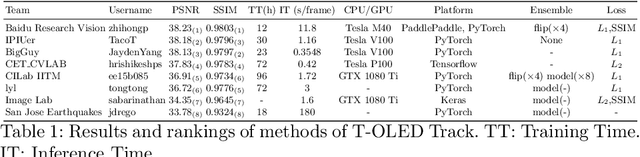
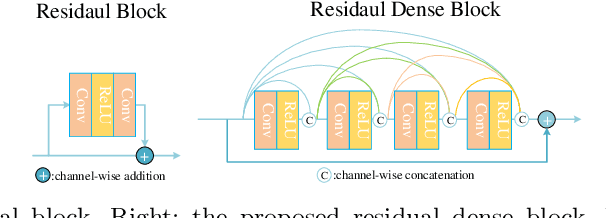
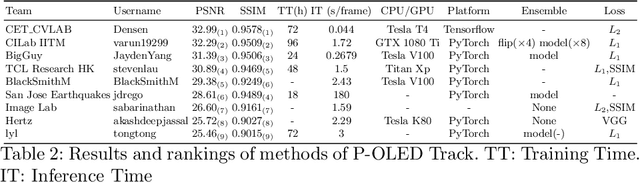
This paper is the report of the first Under-Display Camera (UDC) image restoration challenge in conjunction with the RLQ workshop at ECCV 2020. The challenge is based on a newly-collected database of Under-Display Camera. The challenge tracks correspond to two types of display: a 4k Transparent OLED (T-OLED) and a phone Pentile OLED (P-OLED). Along with about 150 teams registered the challenge, eight and nine teams submitted the results during the testing phase for each track. The results in the paper are state-of-the-art restoration performance of Under-Display Camera Restoration. Datasets and paper are available at https://yzhouas.github.io/projects/UDC/udc.html.