 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Extraction from Charts via Single Deep Neural Network
Jun 06, 2019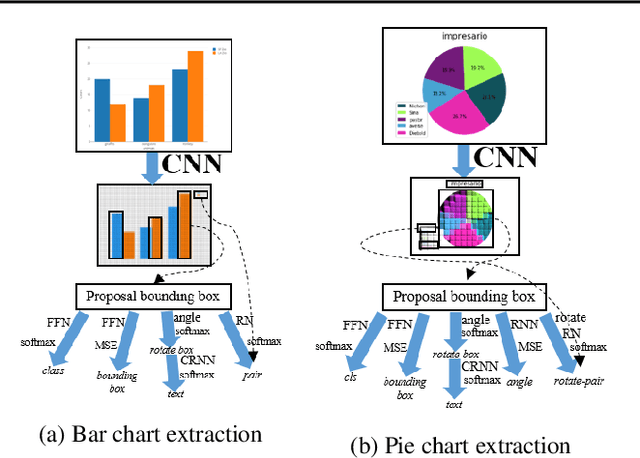
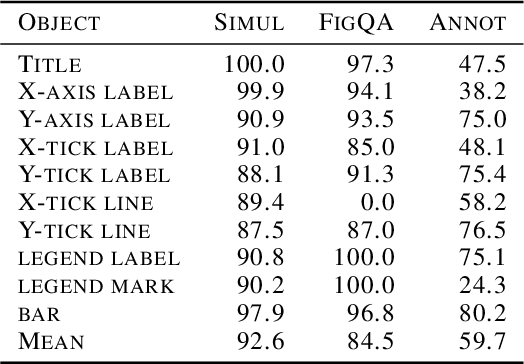
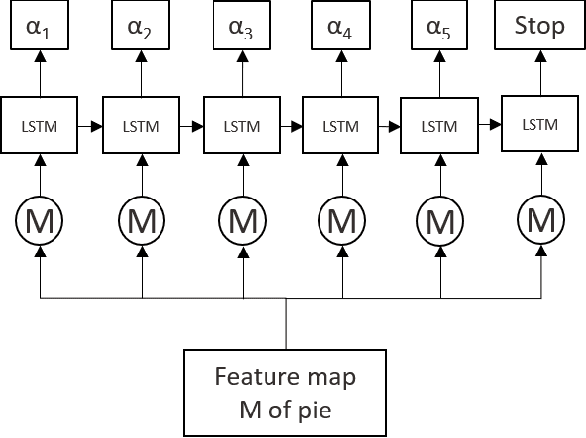
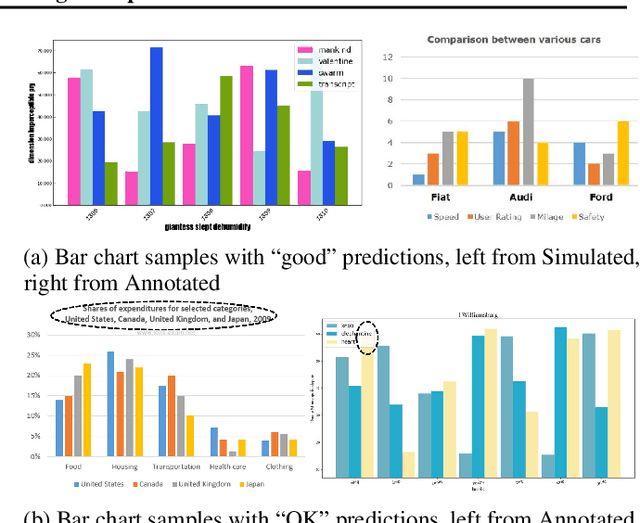
Automatic data extraction from charts is challenging for two reasons: there exist many relations among objects in a chart, which is not a common consideration in general computer vision problems; and different types of charts may not be processed by the same model. To address these problems, we propose a framework of a single deep neural network, which consists of object detection, text recognition and object matching modules. The framework handles both bar and pie charts, and it may also be extended to other types of charts by slight revisions and by augmenting the training data. Our model performs successfully on 79.4% of test simulated bar charts and 88.0% of test simulated pie charts, while for charts outside of the training domain it degrades for 57.5% and 62.3%, respectively.
Dynamic Cell Structure via Recursive-Recurrent Neural Networks
May 25, 2019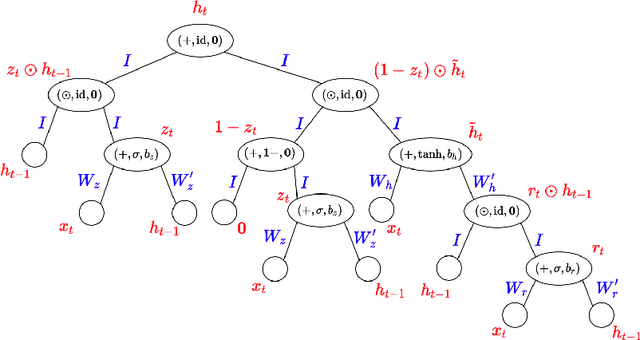
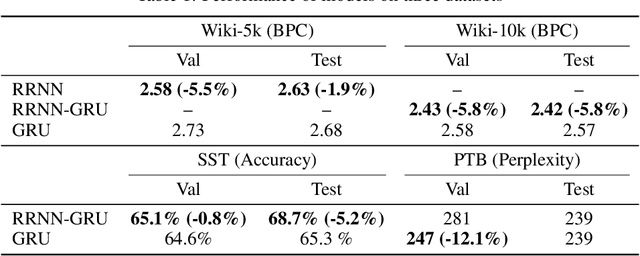

In a recurrent setting, conventional approaches to neural architecture search find and fix a general model for all data samples and time steps. We propose a novel algorithm that can dynamically search for the structure of cells in a recurrent neural network model. Based on a combination of recurrent and recursive neural networks, our algorithm is able to construct customized cell structures for each data sample and time step, allowing for a more efficient architecture search than existing models. Experiments on three common datasets show that the algorithm discovers high-performance cell architectures and achieves better prediction accuracy compared to the GRU structure for language modelling and sentiment analysis.
Scale Invariant Power Iteration
May 23, 2019
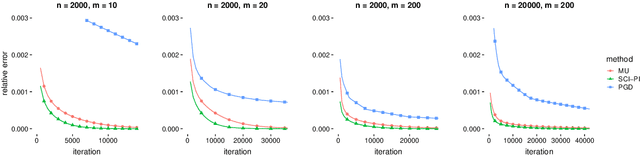
Power iteration has been generalized to solve many interesting problems in machine learning and statistics. Despite its striking success, theoretical understanding of when and how such an algorithm enjoys good convergence property is limited. In this work, we introduce a new class of optimization problems called scale invariant problems and prove that they can be efficiently solved by scale invariant power iteration (SCI-PI) with a generalized convergence guarantee of power iteration. By deriving that a stationary point is an eigenvector of the Hessian evaluated at the point, we show that scale invariant problems indeed resemble the leading eigenvector problem near a local optimum. Also, based on a novel reformulation, we geometrically derive SCI-PI which has a general form of power iteration. The convergence analysis shows that SCI-PI attains local linear convergence with a rate being proportional to the top two eigenvalues of the Hessian at the optimum. Moreover, we discuss some extended settings of scale invariant problems and provide similar convergence results for them. In numerical experiments, we introduce applications to independent component analysis, Gaussian mixtures, and non-negative matrix factorization. Experimental results demonstrate that SCI-PI is competitive to state-of-the-art benchmark algorithms and often yield better solutions.
Convergence Analyses of Online ADAM Algorithm in Convex Setting and Two-Layer ReLU Neural Network
May 22, 2019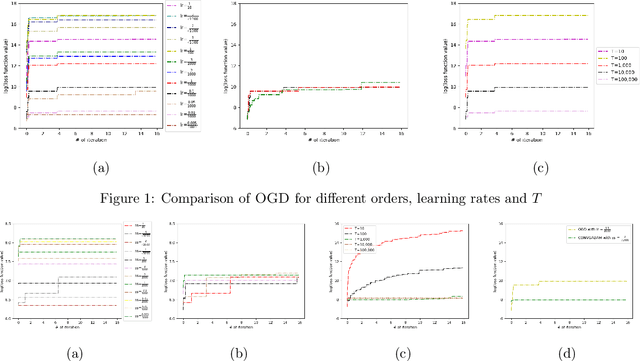

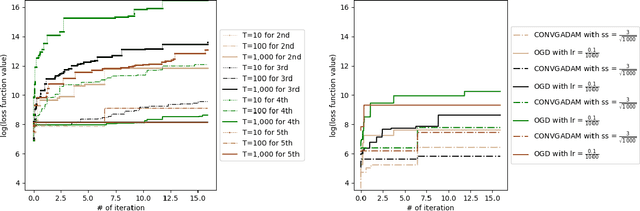
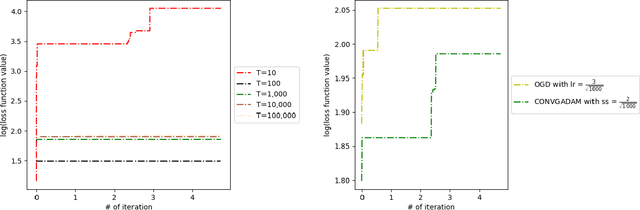
Nowadays, online learning is an appealing learning paradigm, which is of great interest in practice due to the recent emergence of large scale applications such as online advertising placement and online web ranking. Standard online learning assumes a finite number of samples while in practice data is streamed infinitely. In such a setting gradient descent with a diminishing learning rate does not work. We first introduce regret with rolling window, a new performance metric for online streaming learning, which measures the performance of an algorithm on every fixed number of contiguous samples. At the same time, we propose a family of algorithms based on gradient descent with a constant or adaptive learning rate and provide very technical analyses establishing regret bound properties of the algorithms. We cover the convex setting showing the regret of the order of the square root of the size of the window in the constant and dynamic learning rate scenarios. Our proof is applicable also to the standard online setting where we provide the first analysis of the same regret order (the previous proofs have flaws). We also study a two layer neural network setting with ReLU activation. In this case we establish that if initial weights are close to a stationary point, the same square root regret bound is attainable. We conduct computational experiments demonstrating a superior performance of the proposed algorithms.
Automatic Ontology Learning from Domain-Specific Short Unstructured Text Data
Mar 07, 2019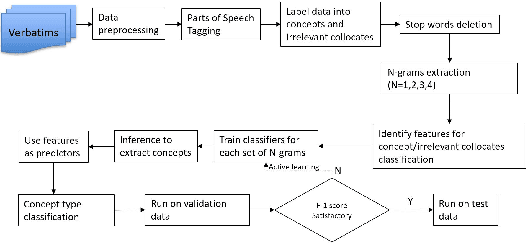
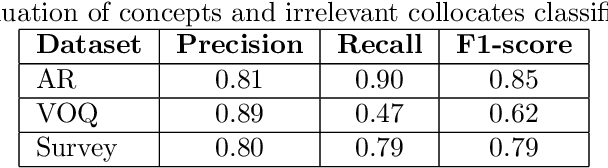
Ontology learning is a critical task in industry, dealing with identifying and extracting concepts captured in text data such that these concepts can be used in different tasks, e.g. information retrieval. Ontology learning is non-trivial due to several reasons with limited amount of prior research work that automatically learns a domain specific ontology from data. In our work, we propose a two-stage classification system to automatically learn an ontology from unstructured text data. We first collect candidate concepts, which are classified into concepts and irrelevant collocates by our first classifier. The concepts from the first classifier are further classified by the second classifier into different concept types. The proposed system is deployed as a prototype at a company and its performance is validated by using complaint and repair verbatim data collected in automotive industry from different data sources.
Autoencoders and Generative Adversarial Networks for Anomaly Detection for Sequences
Jan 15, 2019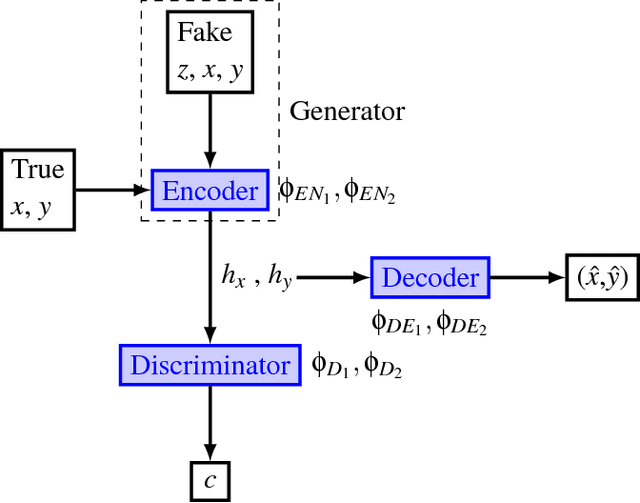
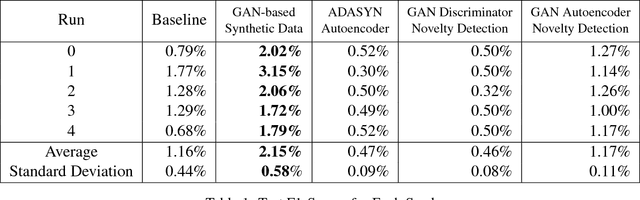
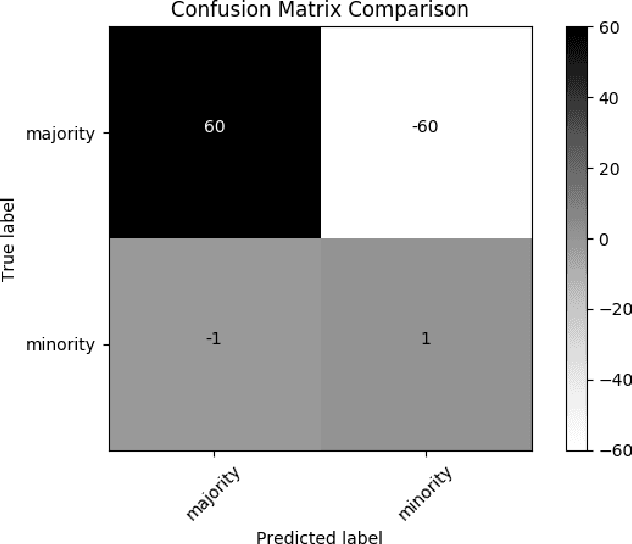

We introduce synthetic oversampling in anomaly detection for multi-feature sequence datasets based on autoencoders and generative adversarial networks. The first approach considers the use of an autoencoder in conjunction with standard oversampling methods to generate synthetic data that captures the sequential nature of the data. A different model uses generative adversarial networks to generate structure preserving synthetic data for the minority class. We also use generative adversarial networks on the majority class as an outlier detection method for novelty detection. We show that the use of generative adversarial network based synthetic data improves classification model performance on a variety of sequence data sets.
Layer Flexible Adaptive Computational Time for Recurrent Neural Networks
Dec 14, 2018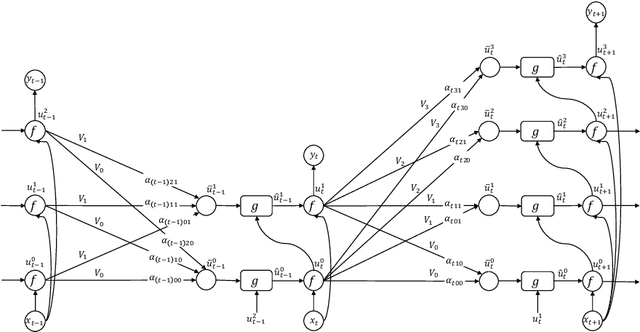
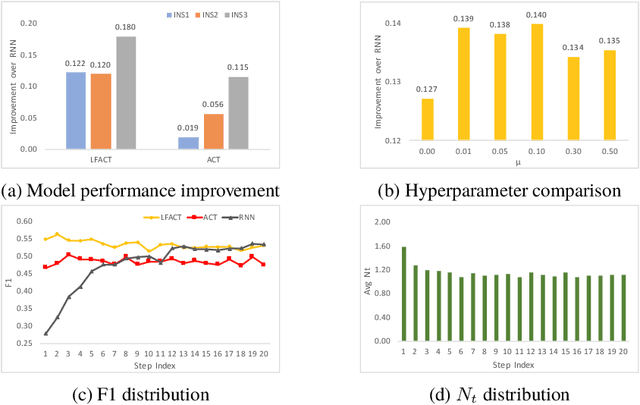
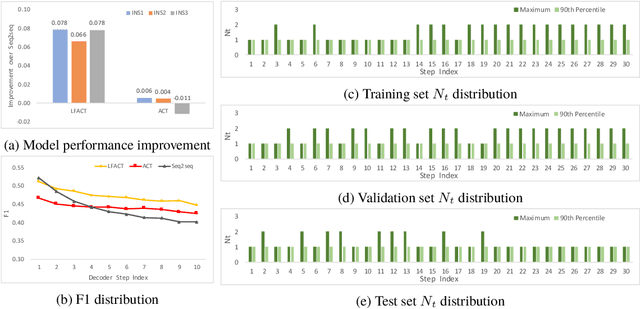
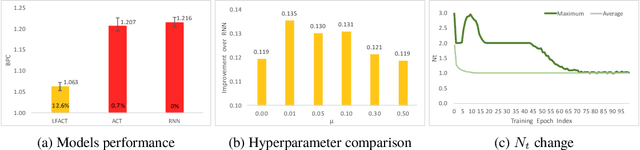
Deep recurrent neural networks perform well on sequence data and are the model of choice. It is a daunting task to decide the number of layers, especially considering different computational needs for tasks within a sequence of different difficulties. We propose a layer flexible recurrent neural network with adaptive computational time, and expand it to a sequence to sequence model. Contrary to the adaptive computational time model, our model has a dynamic number of transmission states which vary by step and sequence. We evaluate the model on a financial dataset. Experimental results show the performance improvement and indicate the model's ability to dynamically change the number of layers.
Combined convolutional and recurrent neural networks for hierarchical classification of images
Oct 03, 2018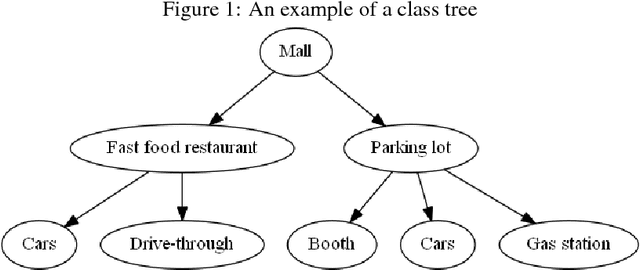

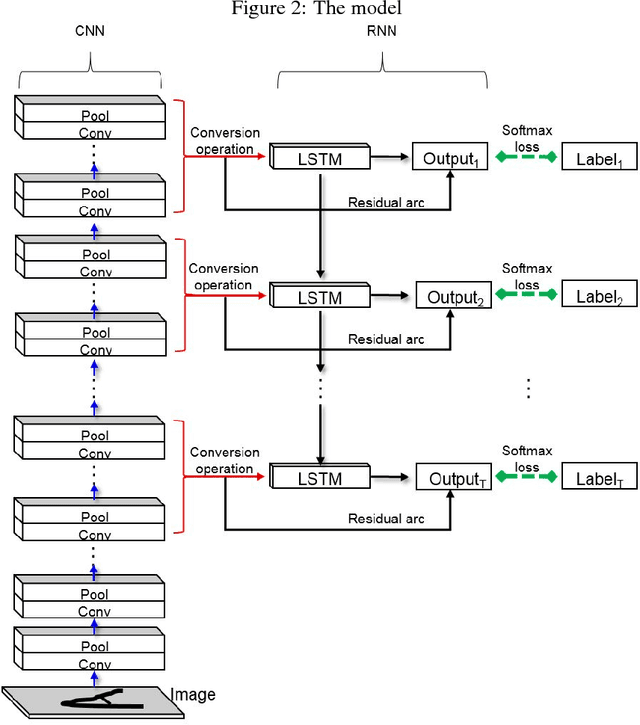

Deep learning models based on CNNs are predominantly used in image classification tasks. Such approaches, assuming independence of object categories, normally use a CNN as a feature learner and apply a flat classifier on top of it. Object classes in many settings have hierarchical relations, and classifiers exploiting these relations should perform better. We propose hierarchical classification models combining a CNN to extract hierarchical representations of images, and an RNN or sequence-to-sequence model to capture a hierarchical tree of classes. In addition, we apply residual learning to the RNN part in oder to facilitate training our compound model and improve generalization of the model. Experimental results on a real world proprietary dataset of images show that our hierarchical networks perform better than state-of-the-art CNNs.
Unified recurrent neural network for many feature types
Sep 24, 2018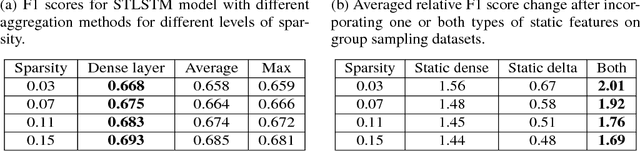
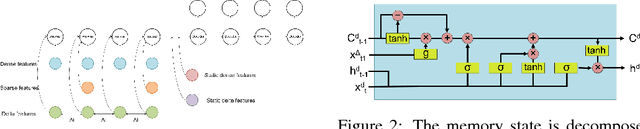
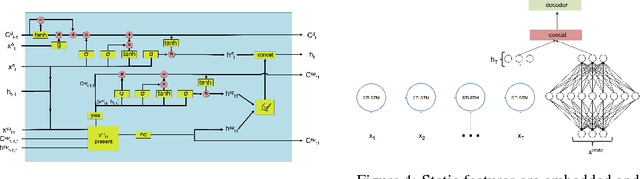

There are time series that are amenable to recurrent neural network (RNN) solutions when treated as sequences, but some series, e.g. asynchronous time series, provide a richer variation of feature types than current RNN cells take into account. In order to address such situations, we introduce a unified RNN that handles five different feature types, each in a different manner. Our RNN framework separates sequential features into two groups dependent on their frequency, which we call sparse and dense features, and which affect cell updates differently. Further, we also incorporate time features at the sequential level that relate to the time between specified events in the sequence and are used to modify the cell's memory state. We also include two types of static (whole sequence level) features, one related to time and one not, which are combined with the encoder output. The experiments show that the modeling framework proposed does increase performance compared to standard cells.
Nested multi-instance classification
Aug 30, 2018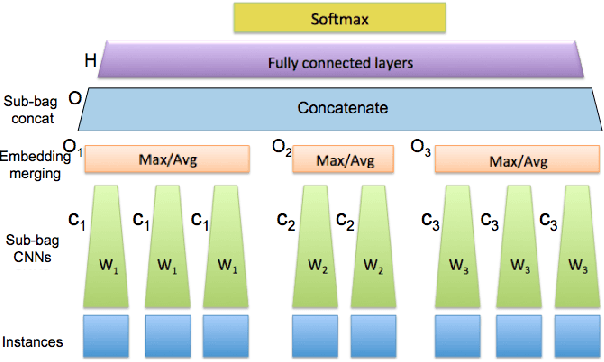

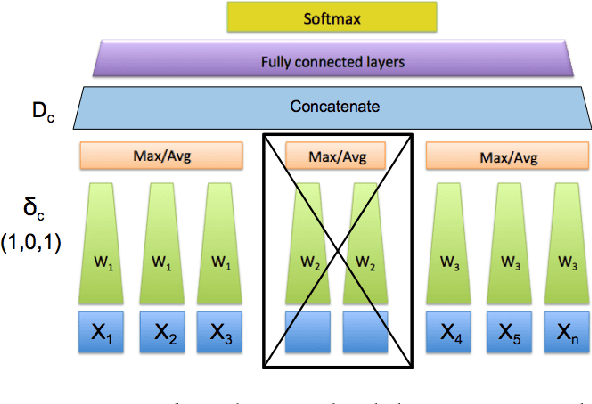

There are classification tasks that take as inputs groups of images rather than single images. In order to address such situations, we introduce a nested multi-instance deep network. The approach is generic in that it is applicable to general data instances, not just images. The network has several convolutional neural networks grouped together at different stages. This primarily differs from other previous works in that we organize instances into relevant groups that are treated differently. We also introduce a method to replace instances that are missing which successfully creates neutral input instances and consistently outperforms standard fill-in methods in real world use cases. In addition, we propose a method for manual dropout when a whole group of instances is missing that allows us to use richer training data and obtain higher accuracy at the end of training. With specific pretraining, we find that the model works to great effect on our real world and pub-lic datasets in comparison to baseline methods, justifying the different treatment among groups of instances.