 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplaining, Verifying, and Aligning Semantic Hierarchies in Vision-Language Model Embeddings
Mar 26, 2026Vision-language model (VLM) encoders such as CLIP enable strong retrieval and zero-shot classification in a shared image-text embedding space, yet the semantic organization of this space is rarely inspected. We present a post-hoc framework to explain, verify, and align the semantic hierarchies induced by a VLM over a given set of child classes. First, we extract a binary hierarchy by agglomerative clustering of class centroids and name internal nodes by dictionary-based matching to a concept bank. Second, we quantify plausibility by comparing the extracted tree against human ontologies using efficient tree- and edge-level consistency measures, and we evaluate utility via explainable hierarchical tree-traversal inference with uncertainty-aware early stopping (UAES). Third, we propose an ontology-guided post-hoc alignment method that learns a lightweight embedding-space transformation, using UMAP to generate target neighborhoods from a desired hierarchy. Across 13 pretrained VLMs and 4 image datasets, our method finds systematic modality differences: image encoders are more discriminative, while text encoders induce hierarchies that better match human taxonomies. Overall, the results reveal a persistent trade-off between zero-shot accuracy and ontological plausibility and suggest practical routes to improve semantic alignment in shared embedding spaces.
Orthologics for Cones
Aug 07, 2020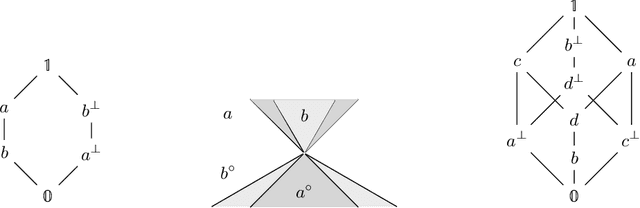
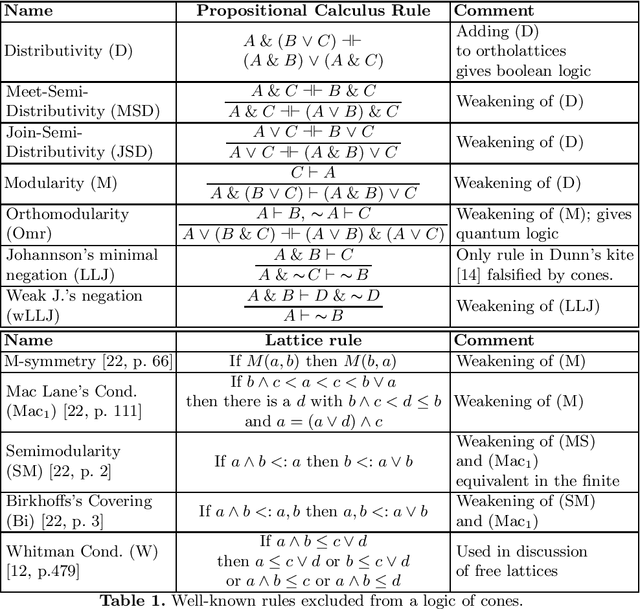
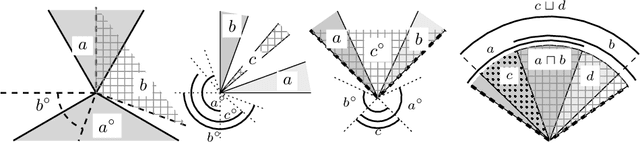
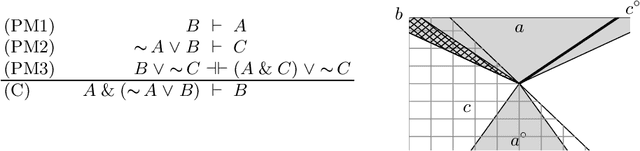
In applications that use knowledge representation (KR) techniques, in particular those that combine data-driven and logic methods, the domain of objects is not an abstract unstructured domain, but it exhibits a dedicated, deep structure of geometric objects. One example is the class of convex sets used to model natural concepts in conceptual spaces, which also links via convex optimization techniques to machine learning. In this paper we study logics for such geometric structures. Using the machinery of lattice theory, we describe an extension of minimal orthologic with a partial modularity rule that holds for closed convex cones. This logic combines a feasible data structure (exploiting convexity/conicity) with sufficient expressivity, including full orthonegation (exploiting conicity).
A Survey of Qualitative Spatial and Temporal Calculi -- Algebraic and Computational Properties
Jun 01, 2016
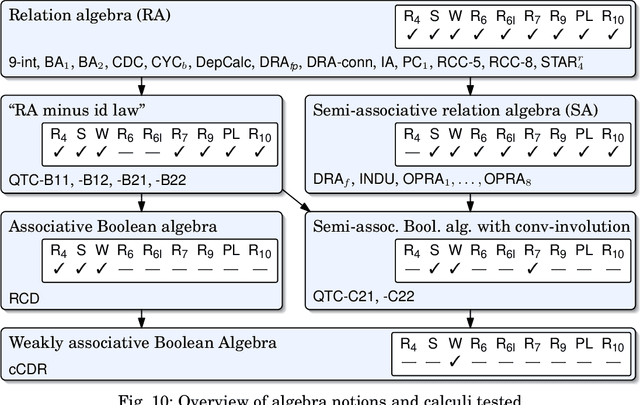
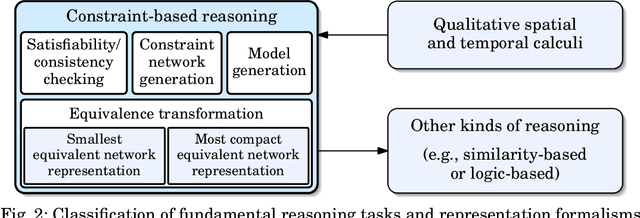
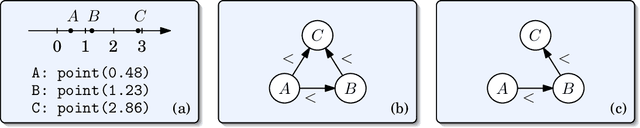
Qualitative Spatial and Temporal Reasoning (QSTR) is concerned with symbolic knowledge representation, typically over infinite domains. The motivations for employing QSTR techniques range from exploiting computational properties that allow efficient reasoning to capture human cognitive concepts in a computational framework. The notion of a qualitative calculus is one of the most prominent QSTR formalisms. This article presents the first overview of all qualitative calculi developed to date and their computational properties, together with generalized definitions of the fundamental concepts and methods, which now encompass all existing calculi. Moreover, we provide a classification of calculi according to their algebraic properties.
Algebraic Properties of Qualitative Spatio-Temporal Calculi
Sep 13, 2013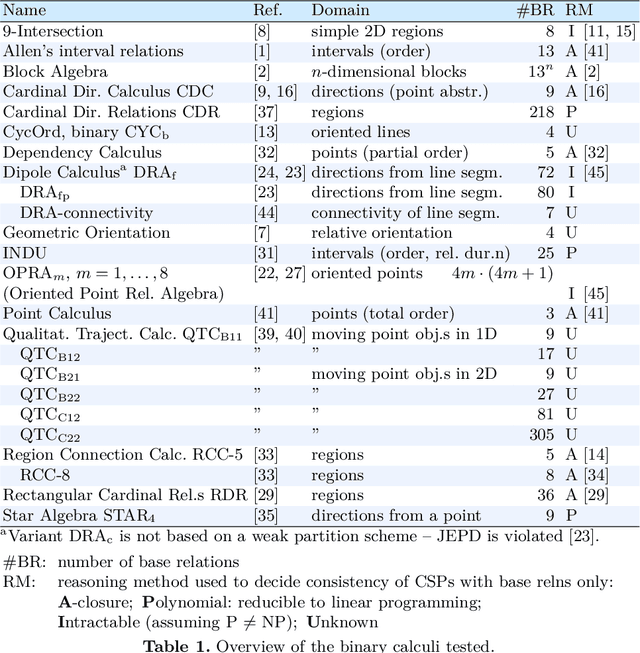
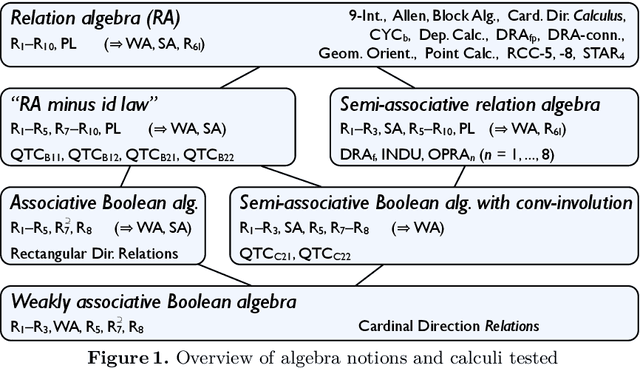

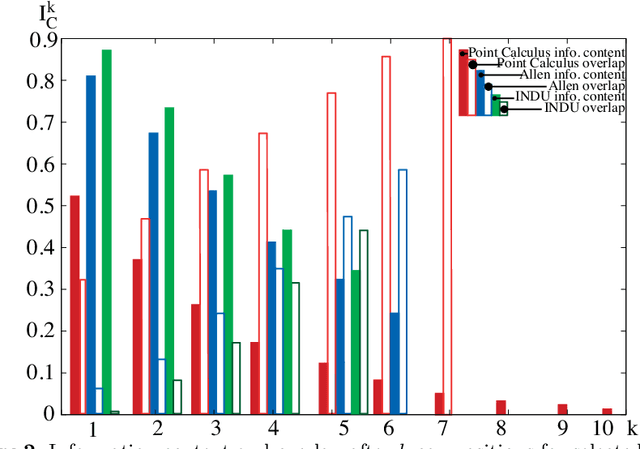
Qualitative spatial and temporal reasoning is based on so-called qualitative calculi. Algebraic properties of these calculi have several implications on reasoning algorithms. But what exactly is a qualitative calculus? And to which extent do the qualitative calculi proposed meet these demands? The literature provides various answers to the first question but only few facts about the second. In this paper we identify the minimal requirements to binary spatio-temporal calculi and we discuss the relevance of the according axioms for representation and reasoning. We also analyze existing qualitative calculi and provide a classification involving different notions of a relation algebra.