 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoencoder for Synthetic to Real Generalization: From Simple to More Complex Scenes
Apr 01, 2022

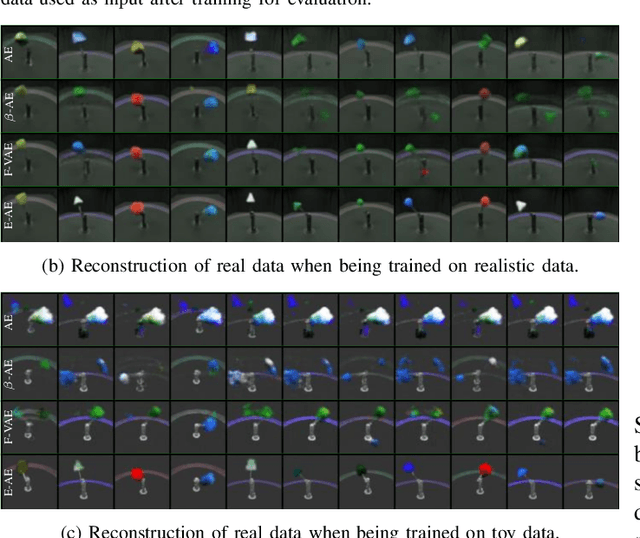
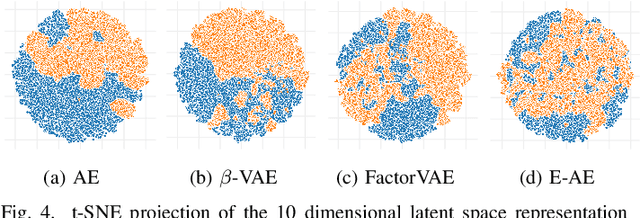
Learning on synthetic data and transferring the resulting properties to their real counterparts is an important challenge for reducing costs and increasing safety in machine learning. In this work, we focus on autoencoder architectures and aim at learning latent space representations that are invariant to inductive biases caused by the domain shift between simulated and real images showing the same scenario. We train on synthetic images only, present approaches to increase generalizability and improve the preservation of the semantics to real datasets of increasing visual complexity. We show that pre-trained feature extractors (e.g. VGG) can be sufficient for generalization on images of lower complexity, but additional improvements are required for visually more complex scenes. To this end, we demonstrate a new sampling technique, which matches semantically important parts of the image, while randomizing the other parts, leads to salient feature extraction and a neglection of unimportant parts. This helps the generalization to real data and we further show that our approach outperforms fine-tuned classification models.
Autoencoder Attractors for Uncertainty Estimation
Apr 01, 2022


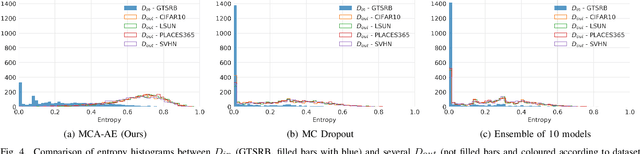
The reliability assessment of a machine learning model's prediction is an important quantity for the deployment in safety critical applications. Not only can it be used to detect novel sceneries, either as out-of-distribution or anomaly sample, but it also helps to determine deficiencies in the training data distribution. A lot of promising research directions have either proposed traditional methods like Gaussian processes or extended deep learning based approaches, for example, by interpreting them from a Bayesian point of view. In this work we propose a novel approach for uncertainty estimation based on autoencoder models: The recursive application of a previously trained autoencoder model can be interpreted as a dynamical system storing training examples as attractors. While input images close to known samples will converge to the same or similar attractor, input samples containing unknown features are unstable and converge to different training samples by potentially removing or changing characteristic features. The use of dropout during training and inference leads to a family of similar dynamical systems, each one being robust on samples close to the training distribution but unstable on new features. Either the model reliably removes these features or the resulting instability can be exploited to detect problematic input samples. We evaluate our approach on several dataset combinations as well as on an industrial application for occupant classification in the vehicle interior for which we additionally release a new synthetic dataset.
RMS-FlowNet: Efficient and Robust Multi-Scale Scene Flow Estimation for Large-Scale Point Clouds
Apr 01, 2022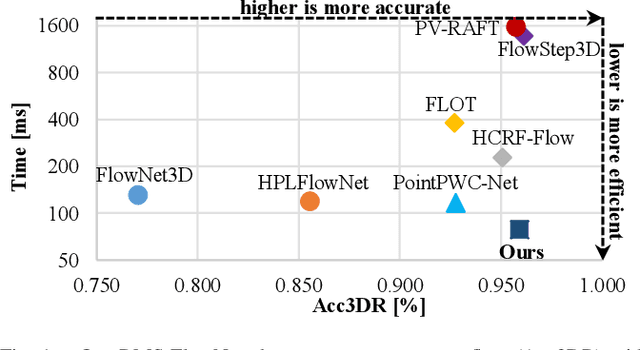
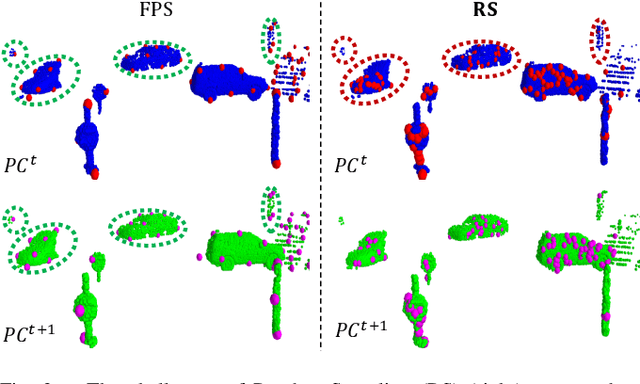
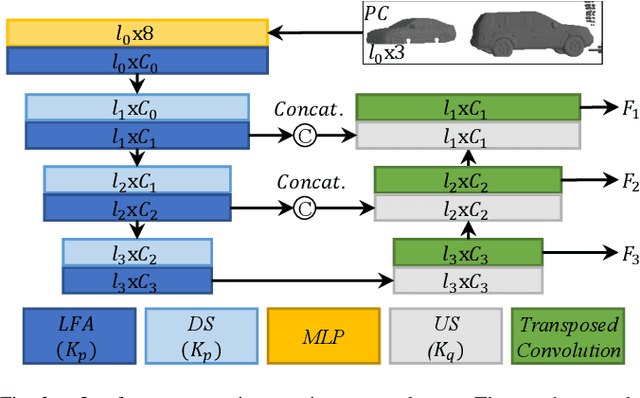
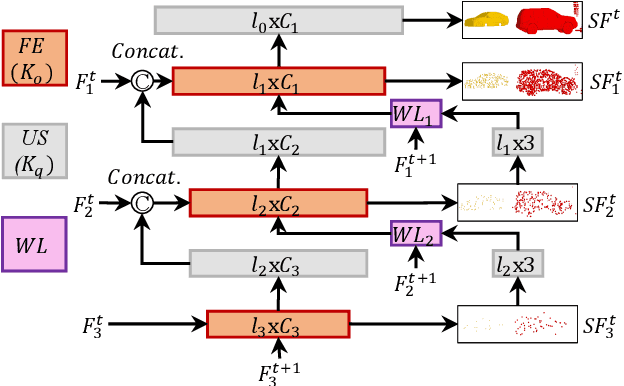
The proposed RMS-FlowNet is a novel end-to-end learning-based architecture for accurate and efficient scene flow estimation which can operate on point clouds of high density. For hierarchical scene flow estimation, the existing methods depend on either expensive Farthest-Point-Sampling (FPS) or structure-based scaling which decrease their ability to handle a large number of points. Unlike these methods, we base our fully supervised architecture on Random-Sampling (RS) for multiscale scene flow prediction. To this end, we propose a novel flow embedding design which can predict more robust scene flow in conjunction with RS. Exhibiting high accuracy, our RMS-FlowNet provides a faster prediction than state-of-the-art methods and works efficiently on consecutive dense point clouds of more than 250K points at once. Our comprehensive experiments verify the accuracy of RMS-FlowNet on the established FlyingThings3D data set with different point cloud densities and validate our design choices. Additionally, we show that our model presents a competitive ability to generalize towards the real-world scenes of KITTI data set without fine-tuning.
ZebraPose: Coarse to Fine Surface Encoding for 6DoF Object Pose Estimation
Mar 29, 2022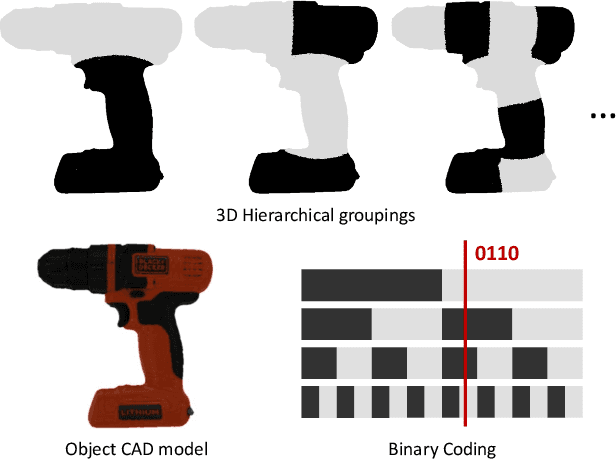
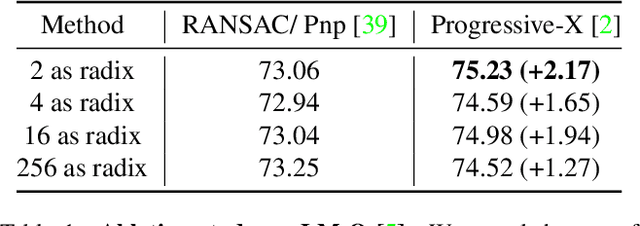
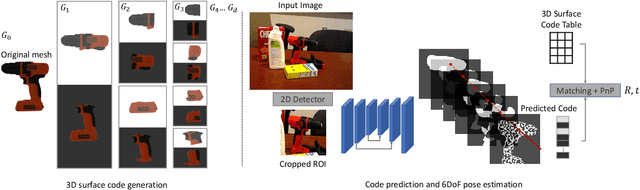

Establishing correspondences from image to 3D has been a key task of 6DoF object pose estimation for a long time. To predict pose more accurately, deeply learned dense maps replaced sparse templates. Dense methods also improved pose estimation in the presence of occlusion. More recently researchers have shown improvements by learning object fragments as segmentation. In this work, we present a discrete descriptor, which can represent the object surface densely. By incorporating a hierarchical binary grouping, we can encode the object surface very efficiently. Moreover, we propose a coarse to fine training strategy, which enables fine-grained correspondence prediction. Finally, by matching predicted codes with object surface and using a PnP solver, we estimate the 6DoF pose. Results on the public LM-O and YCB-V datasets show major improvement over the state of the art w.r.t. ADD(-S) metric, even surpassing RGB-D based methods in some cases.
Comparing Controller With the Hand Gestures Pinch and Grab for Picking Up and Placing Virtual Objects
Feb 22, 2022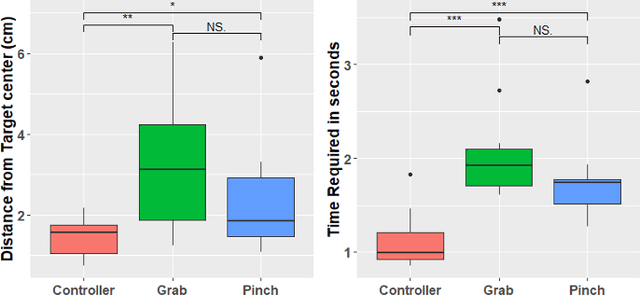
Grabbing virtual objects is one of the essential tasks for Augmented, Virtual, and Mixed Reality applications. Modern applications usually use a simple pinch gesture for grabbing and moving objects. However, picking up objects by pinching has disadvantages. It can be an unnatural gesture to pick up objects and prevents the implementation of other gestures which would be performed with thumb and index. Therefore it is not the optimal choice for many applications. In this work, different implementations for grabbing and placing virtual objects are proposed and compared. Performance and accuracy of the proposed techniques are measured and compared.
IKEA Object State Dataset: A 6DoF object pose estimation dataset and benchmark for multi-state assembly objects
Nov 16, 2021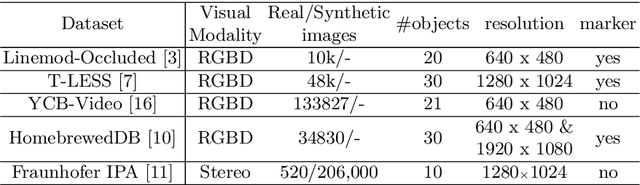


Utilizing 6DoF(Degrees of Freedom) pose information of an object and its components is critical for object state detection tasks. We present IKEA Object State Dataset, a new dataset that contains IKEA furniture 3D models, RGBD video of the assembly process, the 6DoF pose of furniture parts and their bounding box. The proposed dataset will be available at https://github.com/mxllmx/IKEAObjectStateDataset.
Multi-scale Iterative Residuals for Fast and Scalable Stereo Matching
Oct 25, 2021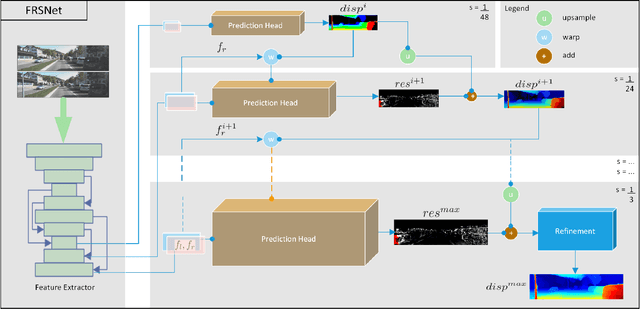

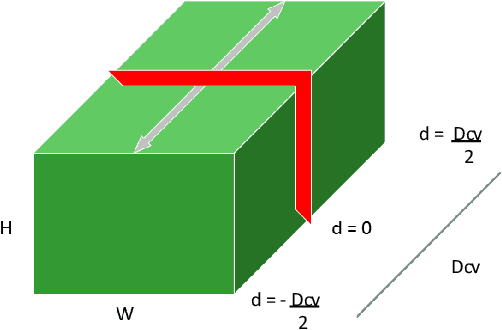
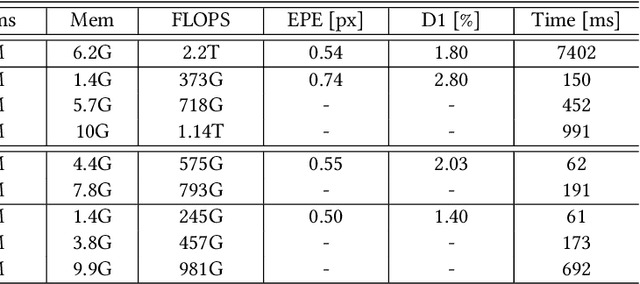
Despite the remarkable progress of deep learning in stereo matching, there exists a gap in accuracy between real-time models and slower state-of-the-art models which are suitable for practical applications. This paper presents an iterative multi-scale coarse-to-fine refinement (iCFR) framework to bridge this gap by allowing it to adopt any stereo matching network to make it fast, more efficient and scalable while keeping comparable accuracy. To reduce the computational cost of matching, we use multi-scale warped features to estimate disparity residuals and push the disparity search range in the cost volume to a minimum limit. Finally, we apply a refinement network to recover the loss of precision which is inherent in multi-scale approaches. We test our iCFR framework by adopting the matching networks from state-of-the art GANet and AANet. The result is 49$\times$ faster inference time compared to GANetdeep and 4$\times$ less memory consumption, with comparable error. Our best performing network, which we call FRSNet is scalable even up to an input resolution of 6K on a GTX 1080Ti, with inference time still below one second and comparable accuracy to AANet+. It out-performs all real-time stereo methods and achieves competitive accuracy on the KITTI benchmark.
PlaneRecNet: Multi-Task Learning with Cross-Task Consistency for Piece-Wise Plane Detection and Reconstruction from a Single RGB Image
Oct 21, 2021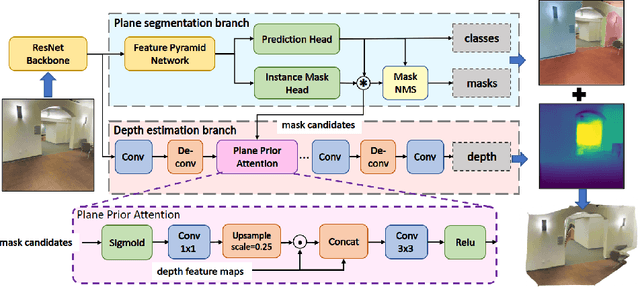

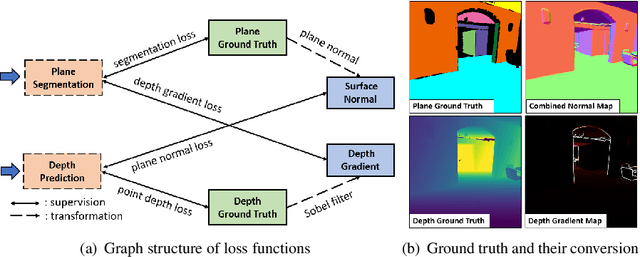

Piece-wise 3D planar reconstruction provides holistic scene understanding of man-made environments, especially for indoor scenarios. Most recent approaches focused on improving the segmentation and reconstruction results by introducing advanced network architectures but overlooked the dual characteristics of piece-wise planes as objects and geometric models. Different from other existing approaches, we start from enforcing cross-task consistency for our multi-task convolutional neural network, PlaneRecNet, which integrates a single-stage instance segmentation network for piece-wise planar segmentation and a depth decoder to reconstruct the scene from a single RGB image. To achieve this, we introduce several novel loss functions (geometric constraint) that jointly improve the accuracy of piece-wise planar segmentation and depth estimation. Meanwhile, a novel Plane Prior Attention module is used to guide depth estimation with the awareness of plane instances. Exhaustive experiments are conducted in this work to validate the effectiveness and efficiency of our method.
TIMo -- A Dataset for Indoor Building Monitoring with a Time-of-Flight Camera
Aug 27, 2021
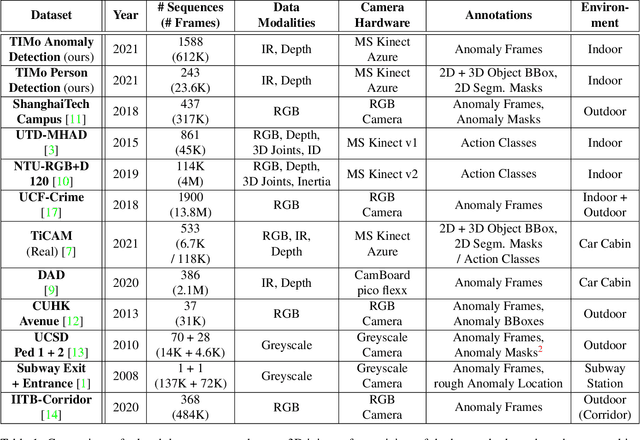

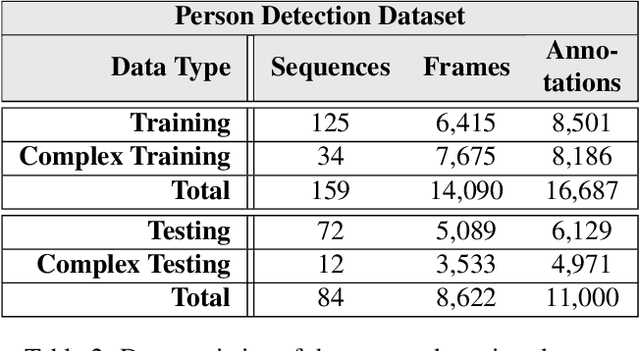
We present TIMo (Time-of-flight Indoor Monitoring), a dataset for video-based monitoring of indoor spaces captured using a time-of-flight (ToF) camera. The resulting depth videos feature people performing a set of different predefined actions, for which we provide detailed annotations. Person detection for people counting and anomaly detection are the two targeted applications. Most existing surveillance video datasets provide either grayscale or RGB videos. Depth information, on the other hand, is still a rarity in this class of datasets in spite of being popular and much more common in other research fields within computer vision. Our dataset addresses this gap in the landscape of surveillance video datasets. The recordings took place at two different locations with the ToF camera set up either in a top-down or a tilted perspective on the scene. The dataset is publicly available at https://vizta-tof.kl.dfki.de/timo-dataset-overview/.
Deployment of Deep Neural Networks for Object Detection on Edge AI Devices with Runtime Optimization
Aug 18, 2021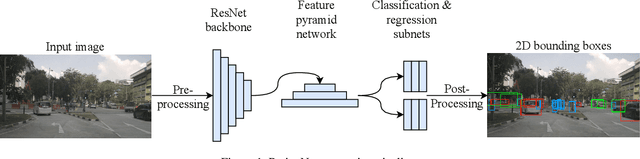

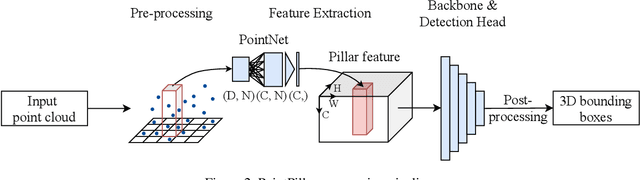
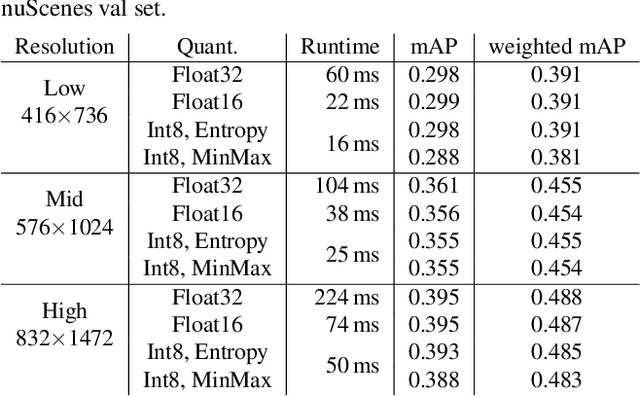
Deep neural networks have proven increasingly important for automotive scene understanding with new algorithms offering constant improvements of the detection performance. However, there is little emphasis on experiences and needs for deployment in embedded environments. We therefore perform a case study of the deployment of two representative object detection networks on an edge AI platform. In particular, we consider RetinaNet for image-based 2D object detection and PointPillars for LiDAR-based 3D object detection. We describe the modifications necessary to convert the algorithms from a PyTorch training environment to the deployment environment taking into account the available tools. We evaluate the runtime of the deployed DNN using two different libraries, TensorRT and TorchScript. In our experiments, we observe slight advantages of TensorRT for convolutional layers and TorchScript for fully connected layers. We also study the trade-off between runtime and performance, when selecting an optimized setup for deployment, and observe that quantization significantly reduces the runtime while having only little impact on the detection performance.