 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoulX-FlashHead: Oracle-guided Generation of Infinite Real-time Streaming Talking Heads
Feb 07, 2026Achieving a balance between high-fidelity visual quality and low-latency streaming remains a formidable challenge in audio-driven portrait generation. Existing large-scale models often suffer from prohibitive computational costs, while lightweight alternatives typically compromise on holistic facial representations and temporal stability. In this paper, we propose SoulX-FlashHead, a unified 1.3B-parameter framework designed for real-time, infinite-length, and high-fidelity streaming video generation. To address the instability of audio features in streaming scenarios, we introduce Streaming-Aware Spatiotemporal Pre-training equipped with a Temporal Audio Context Cache mechanism, which ensures robust feature extraction from short audio fragments. Furthermore, to mitigate the error accumulation and identity drift inherent in long-sequence autoregressive generation, we propose Oracle-Guided Bidirectional Distillation, leveraging ground-truth motion priors to provide precise physical guidance. We also present VividHead, a large-scale, high-quality dataset containing 782 hours of strictly aligned footage to support robust training. Extensive experiments demonstrate that SoulX-FlashHead achieves state-of-the-art performance on HDTF and VFHQ benchmarks. Notably, our Lite variant achieves an inference speed of 96 FPS on a single NVIDIA RTX 4090, facilitating ultra-fast interaction without sacrificing visual coherence.
BrainSegNet: A Novel Framework for Whole-Brain MRI Parcellation Enhanced by Large Models
Jan 14, 2026Whole-brain parcellation from MRI is a critical yet challenging task due to the complexity of subdividing the brain into numerous small, irregular shaped regions. Traditionally, template-registration methods were used, but recent advances have shifted to deep learning for faster workflows. While large models like the Segment Anything Model (SAM) offer transferable feature representations, they are not tailored for the high precision required in brain parcellation. To address this, we propose BrainSegNet, a novel framework that adapts SAM for accurate whole-brain parcellation into 95 regions. We enhance SAM by integrating U-Net skip connections and specialized modules into its encoder and decoder, enabling fine-grained anatomical precision. Key components include a hybrid encoder combining U-Net skip connections with SAM's transformer blocks, a multi-scale attention decoder with pyramid pooling for varying-sized structures, and a boundary refinement module to sharpen edges. Experimental results on the Human Connectome Project (HCP) dataset demonstrate that BrainSegNet outperforms several state-of-the-art methods, achieving higher accuracy and robustness in complex, multi-label parcellation.
Convolutional neural networks with fractional order gradient method
May 14, 2019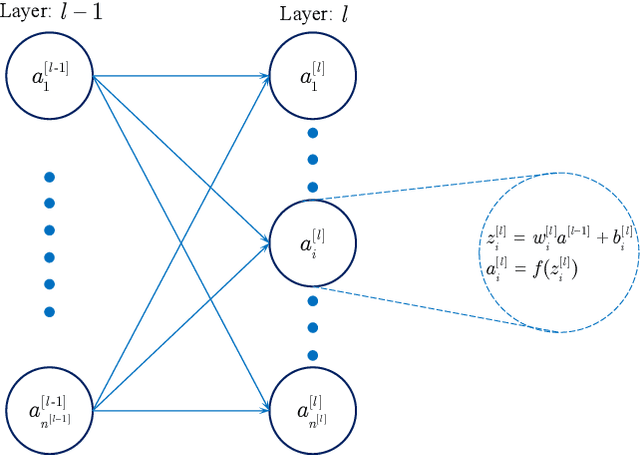
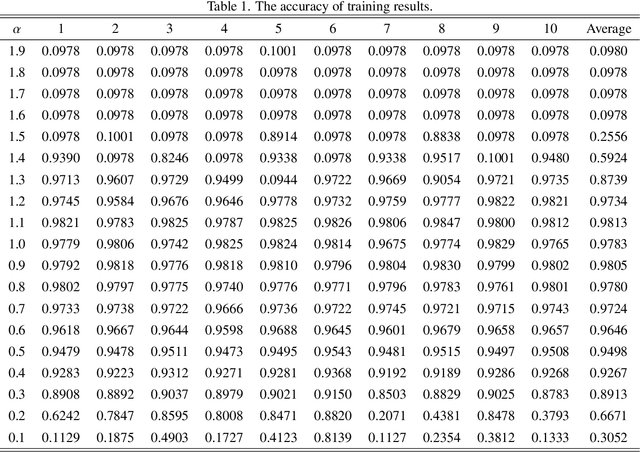
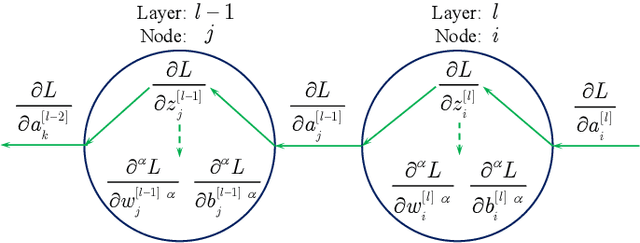
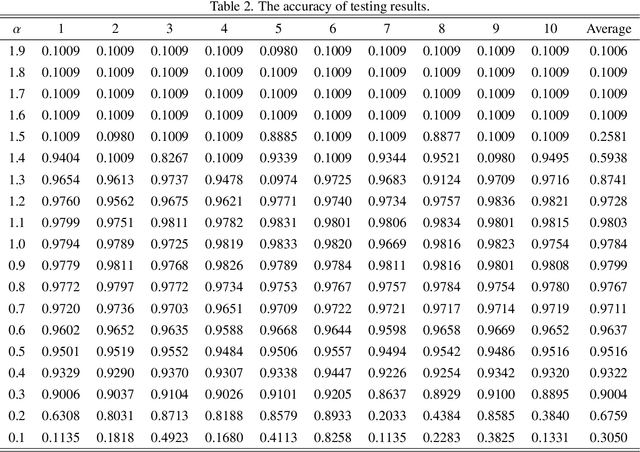
This paper proposes a fractional order gradient method for the backward propagation of convolutional neural networks. To overcome the problem that fractional order gradient method cannot converge to real extreme point, a simplified fractional order gradient method is designed based on Caputo's definition. The parameters within layers are updated by the designed gradient method, but the propagations between layers still use integer order gradients, and thus the complicated derivatives of composite functions are avoided and the chain rule will be kept. By connecting every layers in series and adding loss functions, the proposed convolutional neural networks can be trained smoothly according to various tasks. Some practical experiments are carried out in order to demonstrate the effectiveness of neural networks at last.