 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCASSL: Curriculum Accelerated Self-Supervised Learning
Feb 12, 2018

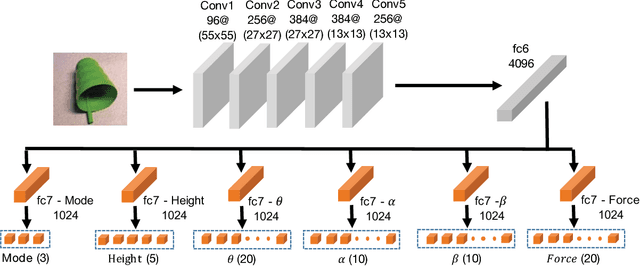

Recent self-supervised learning approaches focus on using a few thousand data points to learn policies for high-level, low-dimensional action spaces. However, scaling this framework for high-dimensional control require either scaling up the data collection efforts or using a clever sampling strategy for training. We present a novel approach - Curriculum Accelerated Self-Supervised Learning (CASSL) - to train policies that map visual information to high-level, higher- dimensional action spaces. CASSL orders the sampling of training data based on control dimensions: the learning and sampling are focused on few control parameters before other parameters. The right curriculum for learning is suggested by variance-based global sensitivity analysis of the control space. We apply our CASSL framework to learning how to grasp using an adaptive, underactuated multi-fingered gripper, a challenging system to control. Our experimental results indicate that CASSL provides significant improvement and generalization compared to baseline methods such as staged curriculum learning (8% increase) and complete end-to-end learning with random exploration (14% improvement) tested on a set of novel objects.
Learning to Fly by Crashing
Apr 27, 2017


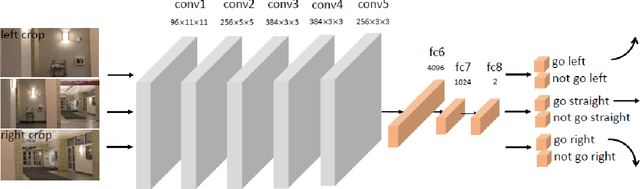
How do you learn to navigate an Unmanned Aerial Vehicle (UAV) and avoid obstacles? One approach is to use a small dataset collected by human experts: however, high capacity learning algorithms tend to overfit when trained with little data. An alternative is to use simulation. But the gap between simulation and real world remains large especially for perception problems. The reason most research avoids using large-scale real data is the fear of crashes! In this paper, we propose to bite the bullet and collect a dataset of crashes itself! We build a drone whose sole purpose is to crash into objects: it samples naive trajectories and crashes into random objects. We crash our drone 11,500 times to create one of the biggest UAV crash dataset. This dataset captures the different ways in which a UAV can crash. We use all this negative flying data in conjunction with positive data sampled from the same trajectories to learn a simple yet powerful policy for UAV navigation. We show that this simple self-supervised model is quite effective in navigating the UAV even in extremely cluttered environments with dynamic obstacles including humans. For supplementary video see: https://youtu.be/u151hJaGKUo
The Curious Robot: Learning Visual Representations via Physical Interactions
Jul 26, 2016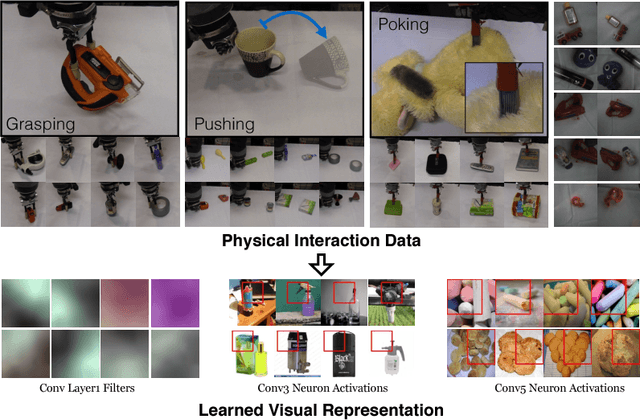



What is the right supervisory signal to train visual representations? Current approaches in computer vision use category labels from datasets such as ImageNet to train ConvNets. However, in case of biological agents, visual representation learning does not require millions of semantic labels. We argue that biological agents use physical interactions with the world to learn visual representations unlike current vision systems which just use passive observations (images and videos downloaded from web). For example, babies push objects, poke them, put them in their mouth and throw them to learn representations. Towards this goal, we build one of the first systems on a Baxter platform that pushes, pokes, grasps and observes objects in a tabletop environment. It uses four different types of physical interactions to collect more than 130K datapoints, with each datapoint providing supervision to a shared ConvNet architecture allowing us to learn visual representations. We show the quality of learned representations by observing neuron activations and performing nearest neighbor retrieval on this learned representation. Quantitatively, we evaluate our learned ConvNet on image classification tasks and show improvements compared to learning without external data. Finally, on the task of instance retrieval, our network outperforms the ImageNet network on recall@1 by 3%