 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Scale-out Deep Learning Training for Cloud and HPC
Jan 24, 2018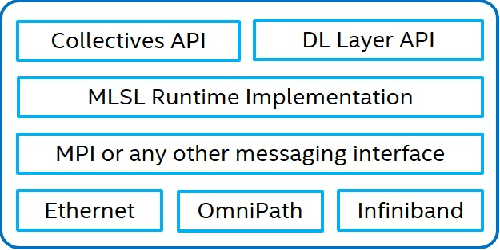
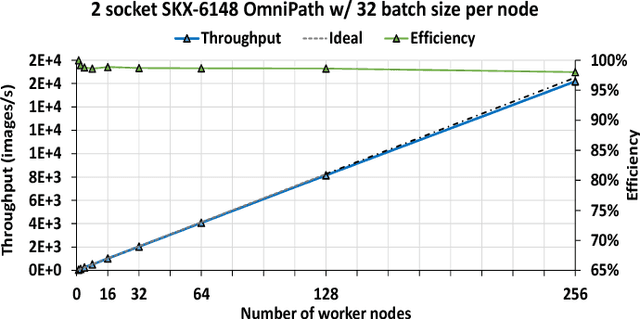
The exponential growth in use of large deep neural networks has accelerated the need for training these deep neural networks in hours or even minutes. This can only be achieved through scalable and efficient distributed training, since a single node/card cannot satisfy the compute, memory, and I/O requirements of today's state-of-the-art deep neural networks. However, scaling synchronous Stochastic Gradient Descent (SGD) is still a challenging problem and requires continued research/development. This entails innovations spanning algorithms, frameworks, communication libraries, and system design. In this paper, we describe the philosophy, design, and implementation of Intel Machine Learning Scalability Library (MLSL) and present proof-points demonstrating scaling DL training on 100s to 1000s of nodes across Cloud and HPC systems.
RAIL: Risk-Averse Imitation Learning
Nov 29, 2017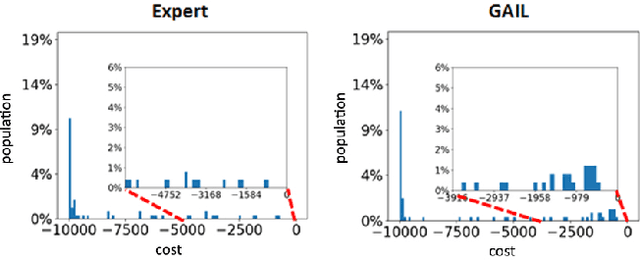
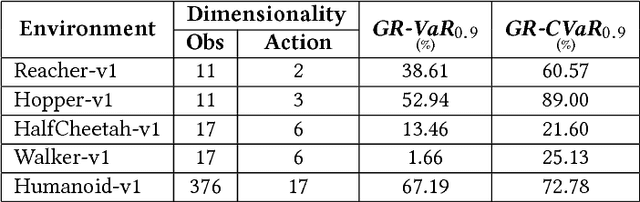
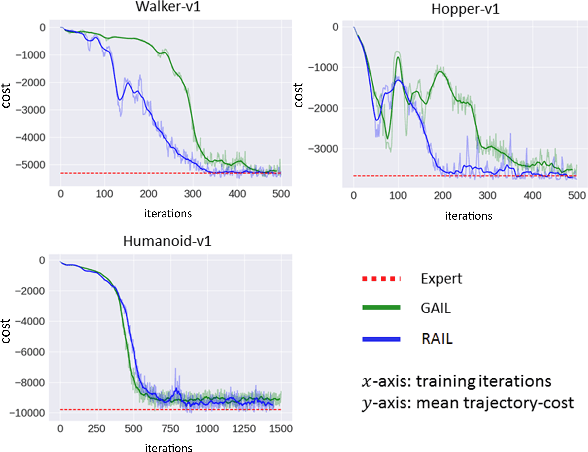
Imitation learning algorithms learn viable policies by imitating an expert's behavior when reward signals are not available. Generative Adversarial Imitation Learning (GAIL) is a state-of-the-art algorithm for learning policies when the expert's behavior is available as a fixed set of trajectories. We evaluate in terms of the expert's cost function and observe that the distribution of trajectory-costs is often more heavy-tailed for GAIL-agents than the expert at a number of benchmark continuous-control tasks. Thus, high-cost trajectories, corresponding to tail-end events of catastrophic failure, are more likely to be encountered by the GAIL-agents than the expert. This makes the reliability of GAIL-agents questionable when it comes to deployment in risk-sensitive applications like robotic surgery and autonomous driving. In this work, we aim to minimize the occurrence of tail-end events by minimizing tail risk within the GAIL framework. We quantify tail risk by the Conditional-Value-at-Risk (CVaR) of trajectories and develop the Risk-Averse Imitation Learning (RAIL) algorithm. We observe that the policies learned with RAIL show lower tail-end risk than those of vanilla GAIL. Thus the proposed RAIL algorithm appears as a potent alternative to GAIL for improved reliability in risk-sensitive applications.
Ternary Residual Networks
Oct 31, 2017


Sub-8-bit representation of DNNs incur some discernible loss of accuracy despite rigorous (re)training at low-precision. Such loss of accuracy essentially makes them equivalent to a much shallower counterpart, diminishing the power of being deep networks. To address this problem of accuracy drop we introduce the notion of \textit{residual networks} where we add more low-precision edges to sensitive branches of the sub-8-bit network to compensate for the lost accuracy. Further, we present a perturbation theory to identify such sensitive edges. Aided by such an elegant trade-off between accuracy and compute, the 8-2 model (8-bit activations, ternary weights), enhanced by ternary residual edges, turns out to be sophisticated enough to achieve very high accuracy ($\sim 1\%$ drop from our FP-32 baseline), despite $\sim 1.6\times$ reduction in model size, $\sim 26\times$ reduction in number of multiplications, and potentially $\sim 2\times$ power-performance gain comparing to 8-8 representation, on the state-of-the-art deep network ResNet-101 pre-trained on ImageNet dataset. Moreover, depending on the varying accuracy requirements in a dynamic environment, the deployed low-precision model can be upgraded/downgraded on-the-fly by partially enabling/disabling residual connections. For example, disabling the least important residual connections in the above enhanced network, the accuracy drop is $\sim 2\%$ (from FP32), despite $\sim 1.9\times$ reduction in model size, $\sim 32\times$ reduction in number of multiplications, and potentially $\sim 2.3\times$ power-performance gain comparing to 8-8 representation. Finally, all the ternary connections are sparse in nature, and the ternary residual conversion can be done in a resource-constraint setting with no low-precision (re)training.
Ternary Neural Networks with Fine-Grained Quantization
May 30, 2017
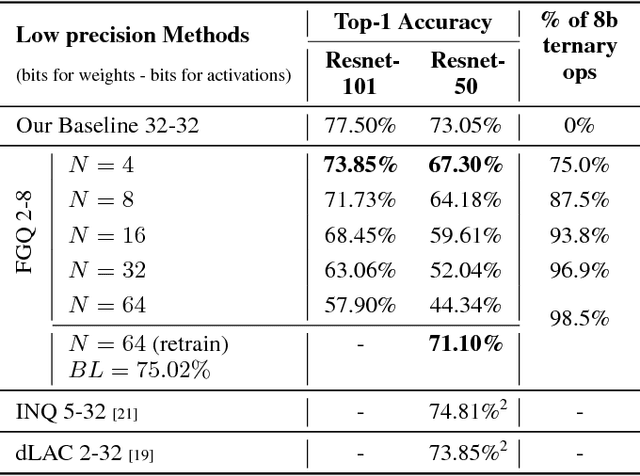
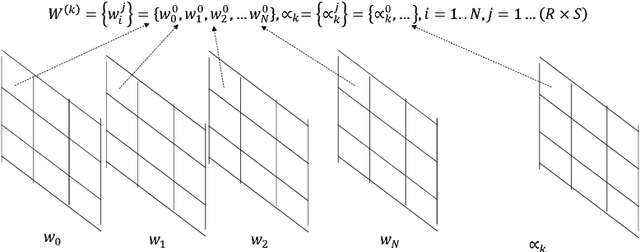
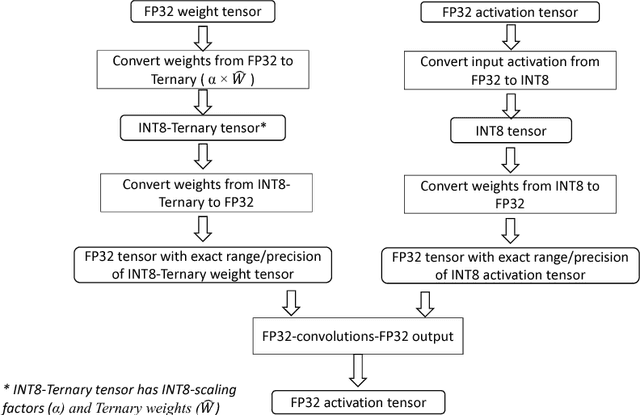
We propose a novel fine-grained quantization (FGQ) method to ternarize pre-trained full precision models, while also constraining activations to 8 and 4-bits. Using this method, we demonstrate a minimal loss in classification accuracy on state-of-the-art topologies without additional training. We provide an improved theoretical formulation that forms the basis for a higher quality solution using FGQ. Our method involves ternarizing the original weight tensor in groups of $N$ weights. Using $N=4$, we achieve Top-1 accuracy within $3.7\%$ and $4.2\%$ of the baseline full precision result for Resnet-101 and Resnet-50 respectively, while eliminating $75\%$ of all multiplications. These results enable a full 8/4-bit inference pipeline, with best-reported accuracy using ternary weights on ImageNet dataset, with a potential of $9\times$ improvement in performance. Also, for smaller networks like AlexNet, FGQ achieves state-of-the-art results. We further study the impact of group size on both performance and accuracy. With a group size of $N=64$, we eliminate $\approx99\%$ of the multiplications; however, this introduces a noticeable drop in accuracy, which necessitates fine tuning the parameters at lower precision. We address this by fine-tuning Resnet-50 with 8-bit activations and ternary weights at $N=64$, improving the Top-1 accuracy to within $4\%$ of the full precision result with $<30\%$ additional training overhead. Our final quantized model can run on a full 8-bit compute pipeline using 2-bit weights and has the potential of up to $15\times$ improvement in performance compared to baseline full-precision models.
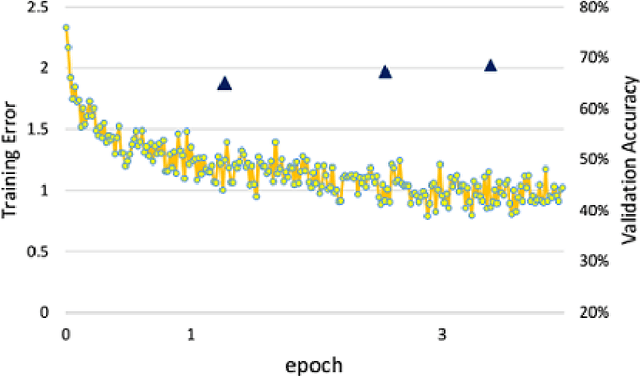
On Large-Batch Training for Deep Learning: Generalization Gap and Sharp Minima
Feb 09, 2017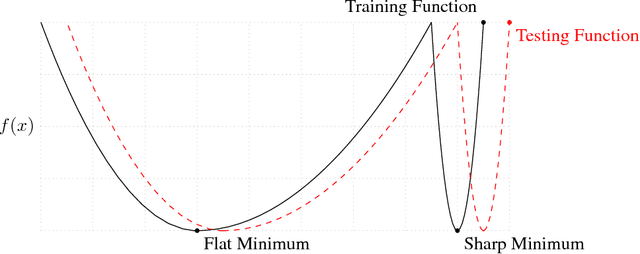
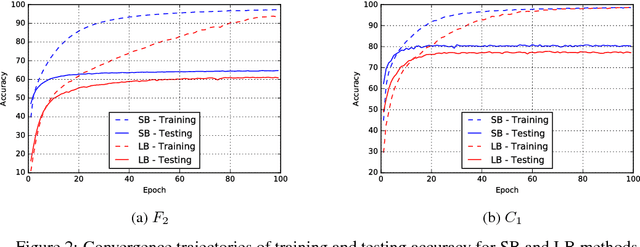
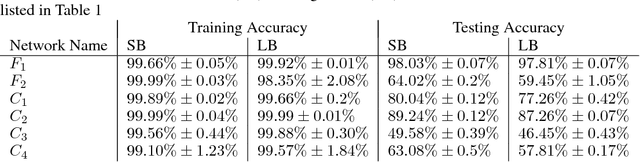
The stochastic gradient descent (SGD) method and its variants are algorithms of choice for many Deep Learning tasks. These methods operate in a small-batch regime wherein a fraction of the training data, say $32$-$512$ data points, is sampled to compute an approximation to the gradient. It has been observed in practice that when using a larger batch there is a degradation in the quality of the model, as measured by its ability to generalize. We investigate the cause for this generalization drop in the large-batch regime and present numerical evidence that supports the view that large-batch methods tend to converge to sharp minimizers of the training and testing functions - and as is well known, sharp minima lead to poorer generalization. In contrast, small-batch methods consistently converge to flat minimizers, and our experiments support a commonly held view that this is due to the inherent noise in the gradient estimation. We discuss several strategies to attempt to help large-batch methods eliminate this generalization gap.
Mixed Low-precision Deep Learning Inference using Dynamic Fixed Point
Feb 01, 2017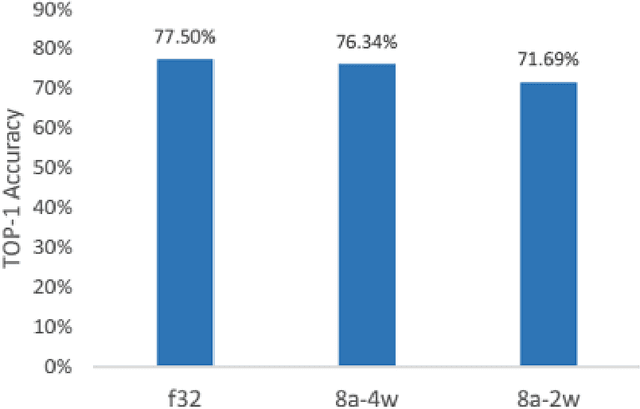
We propose a cluster-based quantization method to convert pre-trained full precision weights into ternary weights with minimal impact on the accuracy. In addition, we also constrain the activations to 8-bits thus enabling sub 8-bit full integer inference pipeline. Our method uses smaller clusters of N filters with a common scaling factor to minimize the quantization loss, while also maximizing the number of ternary operations. We show that with a cluster size of N=4 on Resnet-101, can achieve 71.8% TOP-1 accuracy, within 6% of the best full precision results while replacing ~85% of all multiplications with 8-bit accumulations. Using the same method with 4-bit weights achieves 76.3% TOP-1 accuracy which within 2% of the full precision result. We also study the impact of the size of the cluster on both performance and accuracy, larger cluster sizes N=64 can replace ~98% of the multiplications with ternary operations but introduces significant drop in accuracy which necessitates fine tuning the parameters with retraining the network at lower precision. To address this we have also trained low-precision Resnet-50 with 8-bit activations and ternary weights by pre-initializing the network with full precision weights and achieve 68.9% TOP-1 accuracy within 4 additional epochs. Our final quantized model can run on a full 8-bit compute pipeline, with a potential 16x improvement in performance compared to baseline full-precision models.
Distributed Hessian-Free Optimization for Deep Neural Network
Jan 15, 2017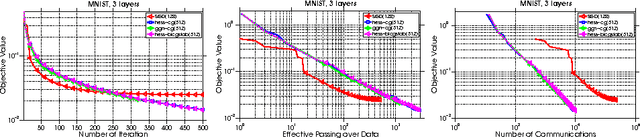
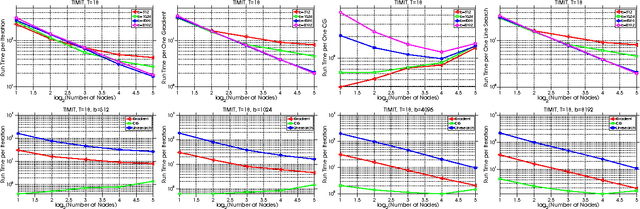
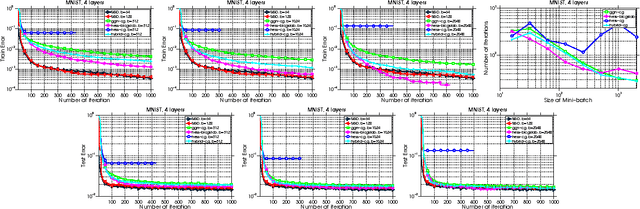
Training deep neural network is a high dimensional and a highly non-convex optimization problem. Stochastic gradient descent (SGD) algorithm and it's variations are the current state-of-the-art solvers for this task. However, due to non-covexity nature of the problem, it was observed that SGD slows down near saddle point. Recent empirical work claim that by detecting and escaping saddle point efficiently, it's more likely to improve training performance. With this objective, we revisit Hessian-free optimization method for deep networks. We also develop its distributed variant and demonstrate superior scaling potential to SGD, which allows more efficiently utilizing larger computing resources thus enabling large models and faster time to obtain desired solution. Furthermore, unlike truncated Newton method (Marten's HF) that ignores negative curvature information by using na\"ive conjugate gradient method and Gauss-Newton Hessian approximation information - we propose a novel algorithm to explore negative curvature direction by solving the sub-problem with stabilized bi-conjugate method involving possible indefinite stochastic Hessian information. We show that these techniques accelerate the training process for both the standard MNIST dataset and also the TIMIT speech recognition problem, demonstrating robust performance with upto an order of magnitude larger batch sizes. This increased scaling potential is illustrated with near linear speed-up on upto 16 CPU nodes for a simple 4-layer network.
Distributed Deep Learning Using Synchronous Stochastic Gradient Descent
Feb 22, 2016
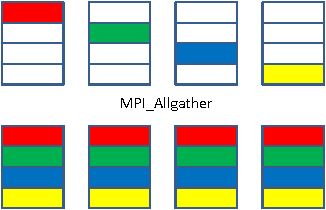
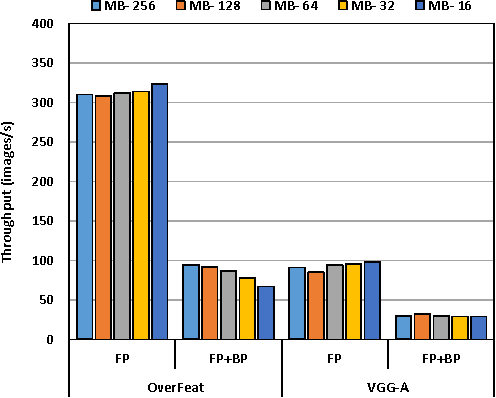
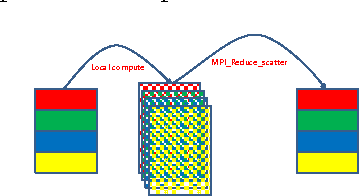
We design and implement a distributed multinode synchronous SGD algorithm, without altering hyper parameters, or compressing data, or altering algorithmic behavior. We perform a detailed analysis of scaling, and identify optimal design points for different networks. We demonstrate scaling of CNNs on 100s of nodes, and present what we believe to be record training throughputs. A 512 minibatch VGG-A CNN training run is scaled 90X on 128 nodes. Also 256 minibatch VGG-A and OverFeat-FAST networks are scaled 53X and 42X respectively on a 64 node cluster. We also demonstrate the generality of our approach via best-in-class 6.5X scaling for a 7-layer DNN on 16 nodes. Thereafter we attempt to democratize deep-learning by training on an Ethernet based AWS cluster and show ~14X scaling on 16 nodes.
Identification of Helicopter Dynamics based on Flight Data using Nature Inspired Techniques
Nov 12, 2014


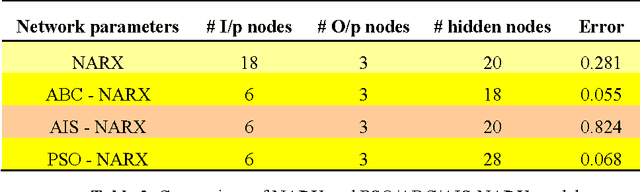
The complexity of helicopter flight dynamics makes modeling and helicopter system identification a very difficult task. Most of the traditional techniques require a model structure to be defined apriori and in case of helicopter dynamics, this is difficult due to its complexity and the interplay between various subsystems.To overcome this difficulty, non-parametric approaches are commonly adopted for helicopter system identification. Artificial Neural Network are a widely used class of algorithms for non-parametric system identification, among them, the Nonlinear Auto Regressive eXogeneous input network (NARX) model is very popular, but it also necessitates some in depth knowledge regarding the system being modeled. There have been many approaches proposed to circumvent this and yet still retain the advantageous characteristics. In this paper we carry out an extensive study of one such newly proposed approach using a modified NARX model with a two tiered, externally driven recurrent neural network architecture. This is coupled with an outer optimization routine for evolving the order of the system. This generic architecture is comprehensively explored to ascertain its usability and critically asses its potential. Different instantiations of this architecture, based on nature inspired computational techniques (Artificial Bee Colony, Artificial Immune System and Particle Swarm Optimization) are evaluated and critically compared in this paper. Simulations have been carried out for identifying the longitudinally uncoupled dynamics. Results of identification indicate a quite close correlation between the actual and the predicted response of the helicopter for all the models.