 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTexar: A Modularized, Versatile, and Extensible Toolkit for Text Generation
Sep 04, 2018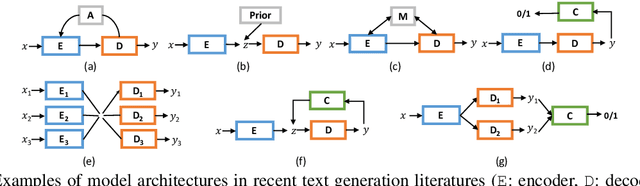
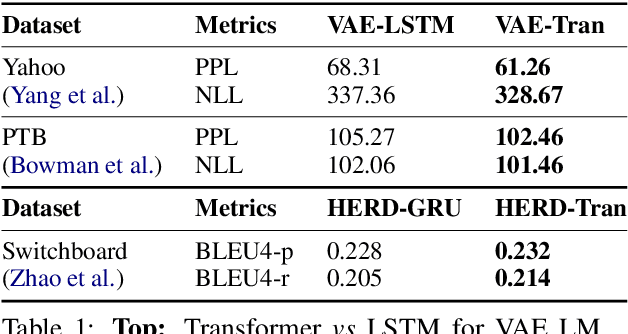
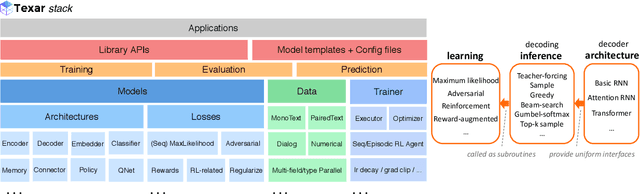

We introduce Texar, an open-source toolkit aiming to support the broad set of text generation tasks that transforms any inputs into natural language, such as machine translation, summarization, dialog, content manipulation, and so forth. With the design goals of modularity, versatility, and extensibility in mind, Texar extracts common patterns underlying the diverse tasks and methodologies, creates a library of highly reusable modules and functionalities, and allows arbitrary model architectures and algorithmic paradigms. In Texar, model architecture, losses, and learning processes are fully decomposed. Modules at high concept level can be freely assembled or plugged in/swapped out. These features make Texar particularly suitable for researchers and practitioners to do fast prototyping and experimentation, as well as foster technique sharing across different text generation tasks. We provide case studies to demonstrate the use and advantage of the toolkit. Texar is released under Apache license 2.0 at https://github.com/asyml/texar.
Effective Use of Bidirectional Language Modeling for Transfer Learning in Biomedical Named Entity Recognition
Aug 15, 2018
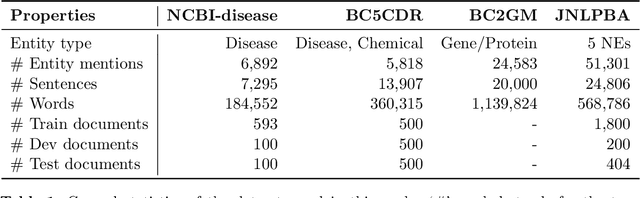
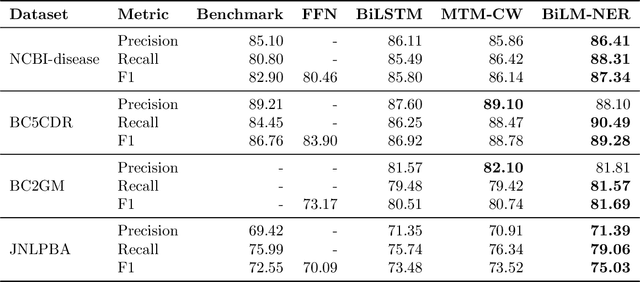
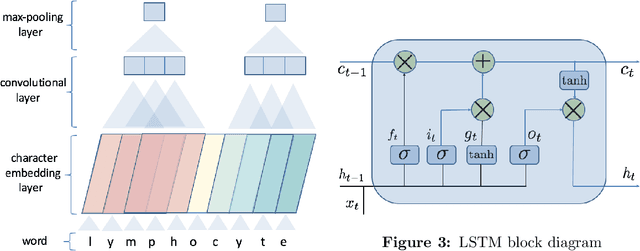
Biomedical named entity recognition (NER) is a fundamental task in text mining of medical documents and has many applications. Deep learning based approaches to this task have been gaining increasing attention in recent years as their parameters can be learned end-to-end without the need for hand-engineered features. However, these approaches rely on high-quality labeled data, which is expensive to obtain. To address this issue, we investigate how to use unlabeled text data to improve the performance of NER models. Specifically, we train a bidirectional language model (BiLM) on unlabeled data and transfer its weights to "pretrain" an NER model with the same architecture as the BiLM, which results in a better parameter initialization of the NER model. We evaluate our approach on four benchmark datasets for biomedical NER and show that it leads to a substantial improvement in the F1 scores compared with the state-of-the-art approaches. We also show that BiLM weight transfer leads to a faster model training and the pretrained model requires fewer training examples to achieve a particular F1 score.
Investigating the Working of Text Classifiers
Aug 05, 2018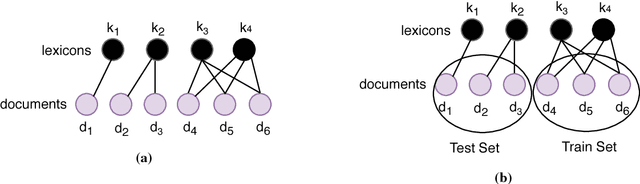
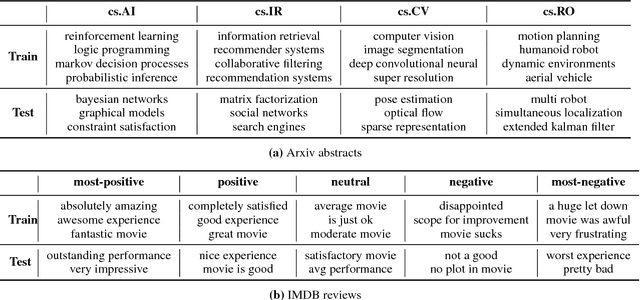
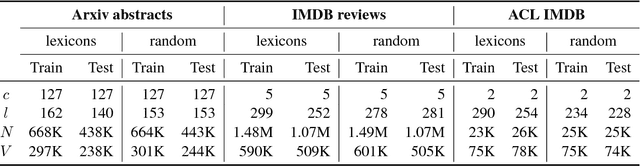

Text classification is one of the most widely studied tasks in natural language processing. Motivated by the principle of compositionality, large multilayer neural network models have been employed for this task in an attempt to effectively utilize the constituent expressions. Almost all of the reported work train large networks using discriminative approaches, which come with a caveat of no proper capacity control, as they tend to latch on to any signal that may not generalize. Using various recent state-of-the-art approaches for text classification, we explore whether these models actually learn to compose the meaning of the sentences or still just focus on some keywords or lexicons for classifying the document. To test our hypothesis, we carefully construct datasets where the training and test splits have no direct overlap of such lexicons, but overall language structure would be similar. We study various text classifiers and observe that there is a big performance drop on these datasets. Finally, we show that even simple models with our proposed regularization techniques, which disincentivize focusing on key lexicons, can substantially improve classification accuracy.
When and Why are Pre-trained Word Embeddings Useful for Neural Machine Translation?
Apr 18, 2018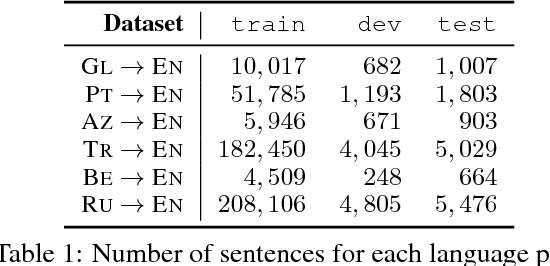
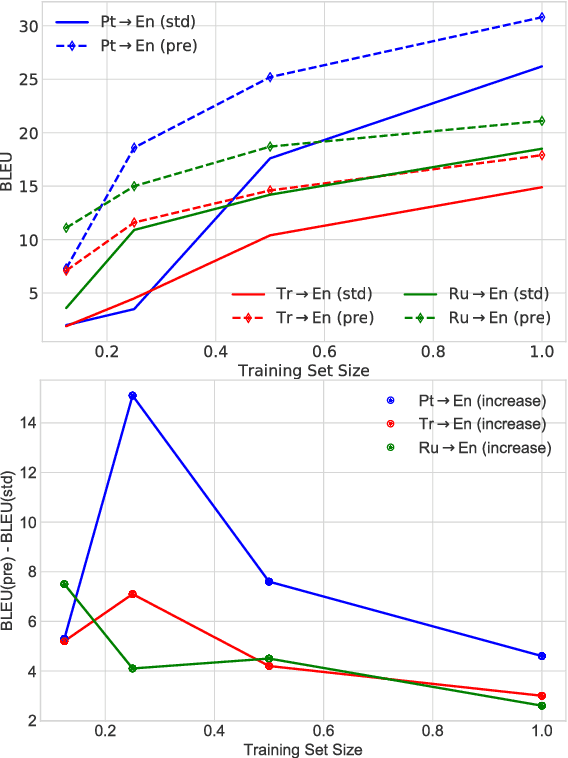
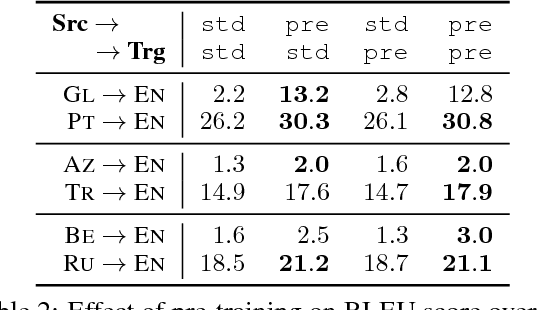
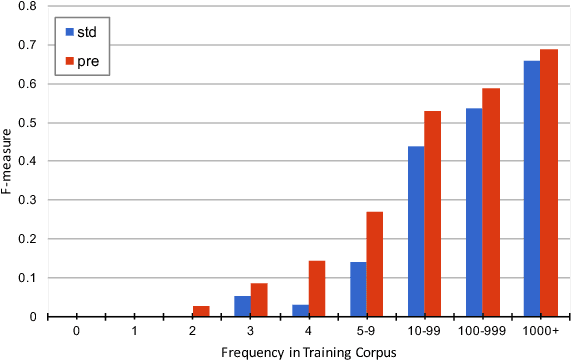
The performance of Neural Machine Translation (NMT) systems often suffers in low-resource scenarios where sufficiently large-scale parallel corpora cannot be obtained. Pre-trained word embeddings have proven to be invaluable for improving performance in natural language analysis tasks, which often suffer from paucity of data. However, their utility for NMT has not been extensively explored. In this work, we perform five sets of experiments that analyze when we can expect pre-trained word embeddings to help in NMT tasks. We show that such embeddings can be surprisingly effective in some cases -- providing gains of up to 20 BLEU points in the most favorable setting.
XNMT: The eXtensible Neural Machine Translation Toolkit
Mar 01, 2018


This paper describes XNMT, the eXtensible Neural Machine Translation toolkit. XNMT distin- guishes itself from other open-source NMT toolkits by its focus on modular code design, with the purpose of enabling fast iteration in research and replicable, reliable results. In this paper we describe the design of XNMT and its experiment configuration system, and demonstrate its utility on the tasks of machine translation, speech recognition, and multi-tasked machine translation/parsing. XNMT is available open-source at https://github.com/neulab/xnmt
Class Vectors: Embedding representation of Document Classes
Aug 02, 2015
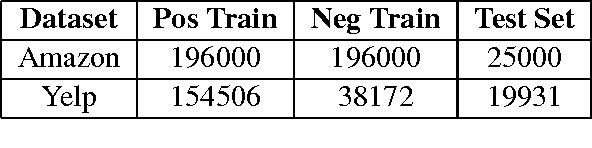
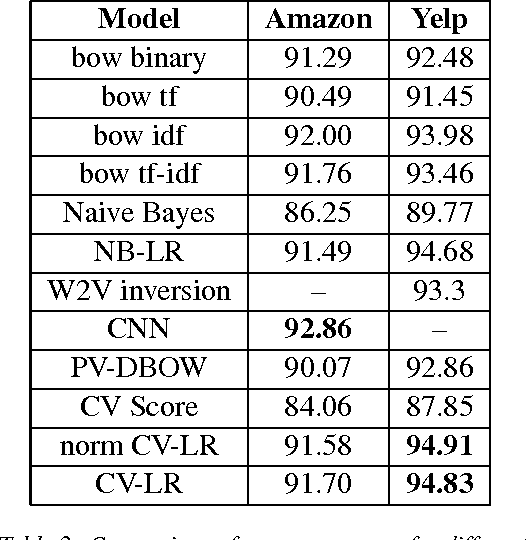
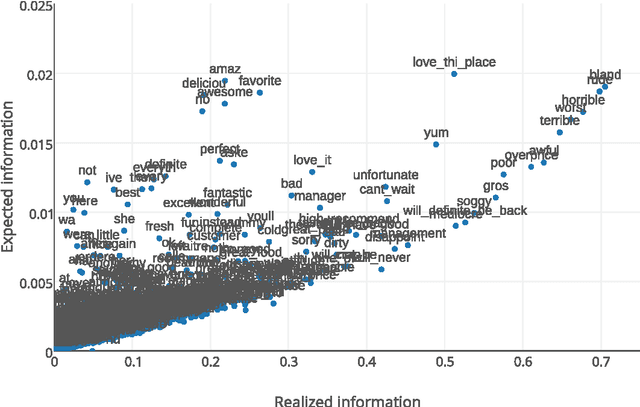
Distributed representations of words and paragraphs as semantic embeddings in high dimensional data are used across a number of Natural Language Understanding tasks such as retrieval, translation, and classification. In this work, we propose "Class Vectors" - a framework for learning a vector per class in the same embedding space as the word and paragraph embeddings. Similarity between these class vectors and word vectors are used as features to classify a document to a class. In experiment on several sentiment analysis tasks such as Yelp reviews and Amazon electronic product reviews, class vectors have shown better or comparable results in classification while learning very meaningful class embeddings.