 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIterative Collaborative Filtering for Sparse Noisy Tensor Estimation
Aug 03, 2019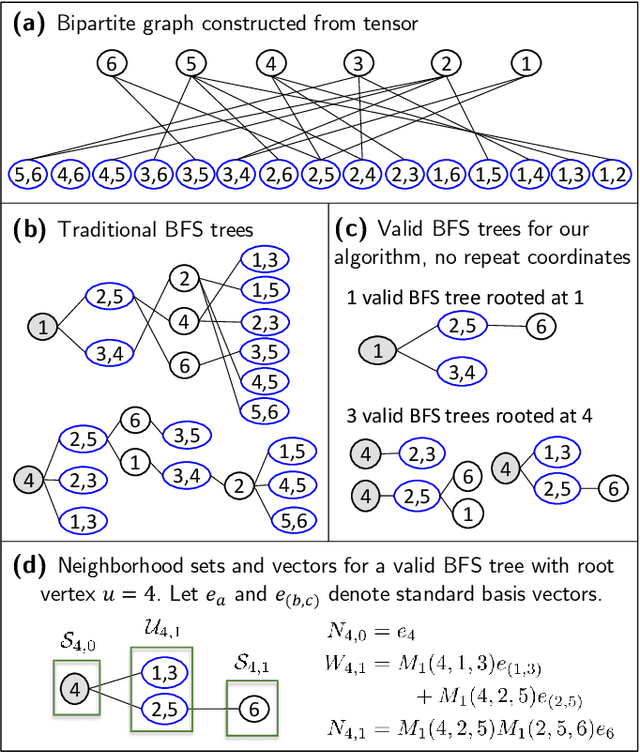
We consider the task of tensor estimation, i.e. estimating a low-rank 3-order $n \times n \times n$ tensor from noisy observations of randomly chosen entries in the sparse regime. In the context of matrix (2-order tensor) estimation, a variety of algorithms have been proposed and analyzed in the literature including the popular collaborative filtering algorithm that is extremely well utilized in practice. However, in the context of tensor estimation, there is limited progress. No natural extensions of collaborative filtering are known beyond ``flattening'' the tensor into a matrix and applying standard collaborative filtering. As the main contribution of this work, we introduce a generalization of the collaborative filtering algorithm for the setting of tensor estimation and argue that it achieves sample complexity that (nearly) matches the conjectured lower bound on the sample complexity. Interestingly, our generalization uses the matrix obtained from the ``flattened'' tensor to compute similarity as in the classical collaborative filtering but by defining a novel ``graph'' using it. The algorithm recovers the tensor with mean-squared-error (MSE) decaying to $0$ as long as each entry is observed independently with probability $p = \Omega(n^{-3/2 + \epsilon})$ for any arbitrarily small $\epsilon > 0$. It turns out that $p = \Omega(n^{-3/2})$ is the conjectured lower bound as well as ``connectivity threshold'' of graph considered to compute similarity in our algorithm.
On Reinforcement Learning Using Monte Carlo Tree Search with Supervised Learning: Non-Asymptotic Analysis
Apr 12, 2019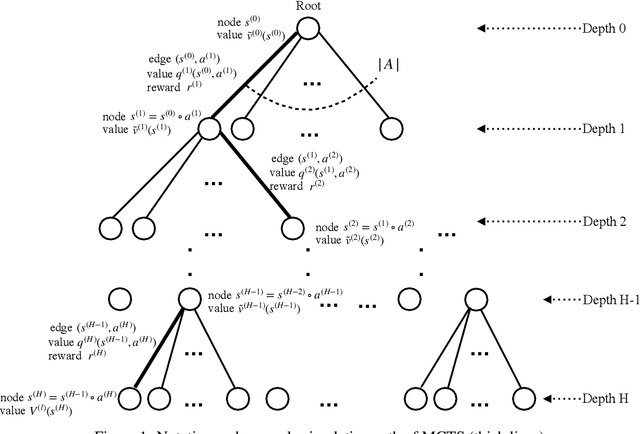
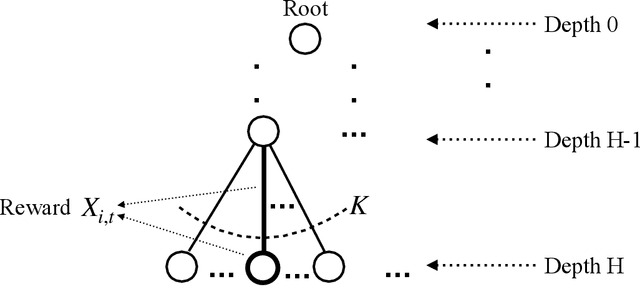
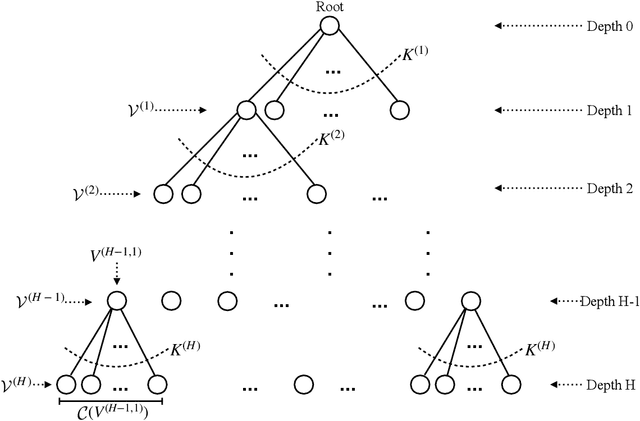
Inspired by the success of AlphaGo Zero (AGZ) which utilizes Monte Carlo Tree Search (MCTS) with Supervised Learning via Neural Network to learn the optimal policy and value function, we focus on establishing formally that such an approach indeed finds the optimal solution asymptotically, as well as establishing non-asymptotic guarantees. We shall focus on infinite-horizon discounted Markov Decision Process (MDP) to establish the results. To start with, this requires establishing that for any given query state, MCTS provides an approximate value function for the state with enough simulation steps of MDP. This property of MCTS was claimed in the literature, but the proof in the seminal works is incomplete. As an important contribution of this work, we establish the correctness of MCTS with appropriate polynomial bonus term in UCB. In the process, we establish polynomial concentration properties of regret for non-stationary Multi-Arm Bandits (MAB), which might be of interest in its own right. Interestingly enough, AGZ utilizes a polynomial form of MCTS as suggested by our result. Using the above result, we argue that MCTS, combined with expressive enough supervised learning techniques, finds the optimal value at nearly minimax optimal rate. Specifically, when using the nearest neighbor supervised learning, we show that MCTS acts as a "policy improvement" operator: it has a natural "bootstrapping" property to improve value function approximation for all states, due to combining with supervised learning, despite evaluating at only finitely many states. To learn an $\epsilon$ approximation of the value function with respect to $\ell_\infty$ norm, MCTS combined with nearest neighbor requires a sample size scaling as $\tilde{O}(\epsilon^{-(d+4)})$, where $d$ is the dimension of the state space. This is nearly optimal due to a minimax lower bound of $\tilde{\Omega} (\epsilon^{-(d+2)}).$
Time Series Predict DB
Mar 17, 2019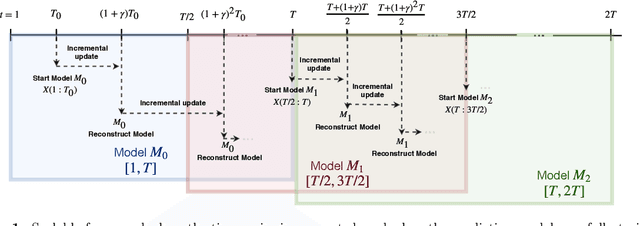
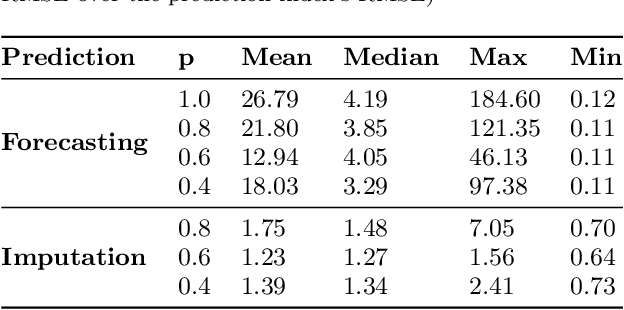


In this work, we are motivated to make predictive functionalities native to database systems with focus on time series data. We propose a system architecture, Time Series Predict DB, that enables predictive query in any existing time series database by building an additional "prediction index" for time series data. To be effective, such an index needs to be built incrementally while keeping up with database throughput, able to scale with volume of data, provide accurate predictions for heterogeneous data, and allow for "predictive" querying with latency comparable to the traditional database queries. Building upon a recently developed model agnostic time series algorithm by making it incremental and scalable, we build such a system on top of PostgreSQL. Using extensive experimentation, we show that our incremental prediction index updates faster than PostgreSQL ($1\mu s$ per data for prediction index vs $4\mu s$ per data for PostgreSQL) and thus not affecting the throughput of the database. Across a variety of time series data, we find? that our incremental, model agnostic algorithm provides better accuracy compared to the best state-of-art time series libraries (median improvement in range 3.29 to 4.19x over Prophet of Facebook, 1.27 to 1.48x over AMELIA in R). The latency of predictive queries with respect to SELECT queries (0.5ms) is < 1.9x (0.8ms) for imputation and < 7.6x (3ms) for forecasting across machine platforms. As a by-product, we find that the incremental, scalable variant we propose improves the accuracy of the batch prediction algorithm which may be of interest in its own right.
Model Agnostic High-Dimensional Error-in-Variable Regression
Mar 12, 2019
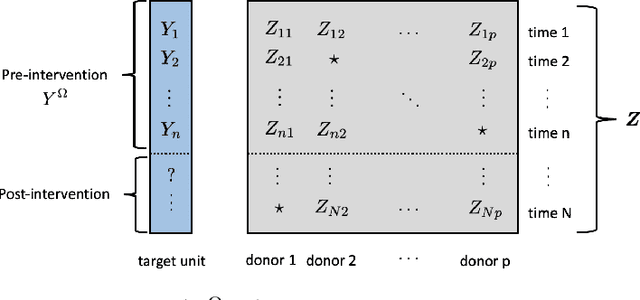
We consider the problem of high-dimensional error-in-variable regression where we only observe a sparse, noisy version of the covariate data. We propose an algorithm that utilizes matrix estimation (ME) as a key subroutine to de-noise the corrupted data, and then performs ordinary least squares regression. When the ME subroutine is instantiated with hard singular value thresholding (HSVT), our results indicate that if the number of samples scales as $\omega( \rho^{-4} r \log^5 (p))$, then our in- and out-of-sample prediction error decays to $0$ as $p \rightarrow \infty$; $\rho$ represents the fraction of observed data, $r$ is the (approximate) rank of the true covariate matrix, and $p$ is the number of covariates. As an important byproduct of our approach, we demonstrate that HSVT with regression acts as implicit $\ell_0$-regularization since HSVT aims to find a low-rank structure within the covariance matrix. Thus, we can view the sparsity of the estimated parameter as a consequence of the covariate structure rather than a model assumption as is often considered in the literature. Moreover, our non-asymptotic bounds match (up to $\log^4(p)$ factors) the best guaranteed sample complexity results in the literature for algorithms that require precise knowledge of the underlying model; we highlight that our approach is model agnostic. In our analysis, we obtain two technical results of independent interest: first, we provide a simple bound on the spectral norm of random matrices with independent sub-exponential rows with randomly missing entries; second, we bound the max column sum error -- a nonstandard error metric -- for HSVT. Our setting enables us to apply our results to applications such as synthetic control for causal inference, time series analysis, and regression with privacy. It is important to note that the existing inventory of methods is unable to analyze these applications.
Learning Mixture Model with Missing Values and its Application to Rankings
Dec 31, 2018We consider the question of learning mixtures of generic sub-gaussian distributions based on observations with missing values. To that end, we utilize a matrix estimation method from literature (soft- or hard- singular value thresholding). Specifically, we stack the observations (with missing values) to form a data matrix and learn a low-rank approximation of it so that the row indices can be correctly clustered to belong to appropriate mixture component using a simple distance-based algorithm. To analyze the performance of this algorithm by quantifying finite sample bound, we extend the result for matrix estimation methods in the literature in two important ways: one, noise across columns is correlated and not independent across all entries of matrix as considered in the literature; two, the performance metric of interest is the maximum l2 row norm error, which is stronger than the traditional mean-squared-error averaged over all entries. Equipped with these advances in the context of matrix estimation, we are able to connect matrix estimation and mixture model learning in the presence of missing data.
Q-learning with Nearest Neighbors
Oct 23, 2018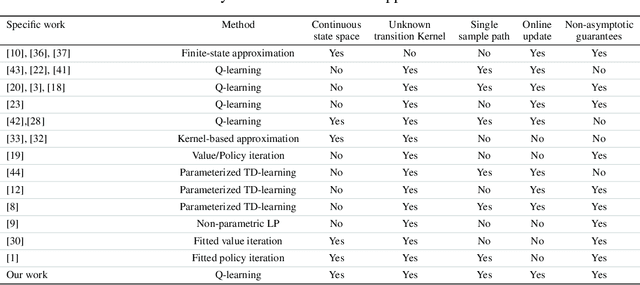
We consider model-free reinforcement learning for infinite-horizon discounted Markov Decision Processes (MDPs) with a continuous state space and unknown transition kernel, when only a single sample path under an arbitrary policy of the system is available. We consider the Nearest Neighbor Q-Learning (NNQL) algorithm to learn the optimal Q function using nearest neighbor regression method. As the main contribution, we provide tight finite sample analysis of the convergence rate. In particular, for MDPs with a $d$-dimensional state space and the discounted factor $\gamma \in (0,1)$, given an arbitrary sample path with "covering time" $ L $, we establish that the algorithm is guaranteed to output an $\varepsilon$-accurate estimate of the optimal Q-function using $\tilde{O}\big(L/(\varepsilon^3(1-\gamma)^7)\big)$ samples. For instance, for a well-behaved MDP, the covering time of the sample path under the purely random policy scales as $ \tilde{O}\big(1/\varepsilon^d\big),$ so the sample complexity scales as $\tilde{O}\big(1/\varepsilon^{d+3}\big).$ Indeed, we establish a lower bound that argues that the dependence of $ \tilde{\Omega}\big(1/\varepsilon^{d+2}\big)$ is necessary.
Regret vs. Bandwidth Trade-off for Recommendation Systems
Oct 15, 2018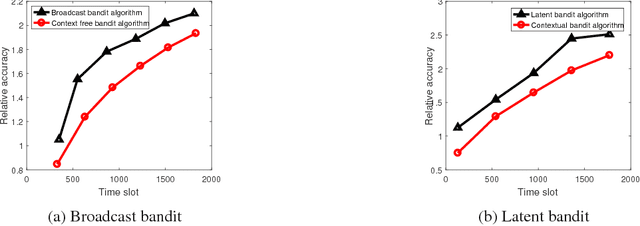
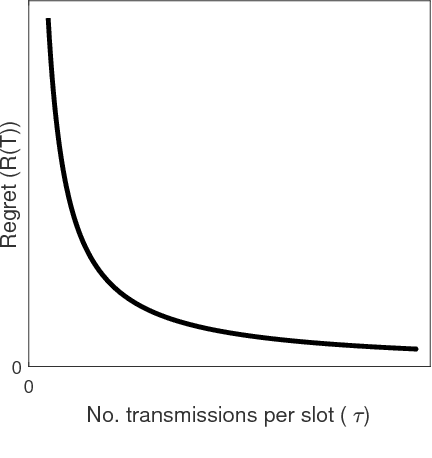
We consider recommendation systems that need to operate under wireless bandwidth constraints, measured as number of broadcast transmissions, and demonstrate a (tight for some instances) tradeoff between regret and bandwidth for two scenarios: the case of multi-armed bandit with context, and the case where there is a latent structure in the message space that we can exploit to reduce the learning phase.
Time Series Analysis via Matrix Estimation
Aug 24, 2018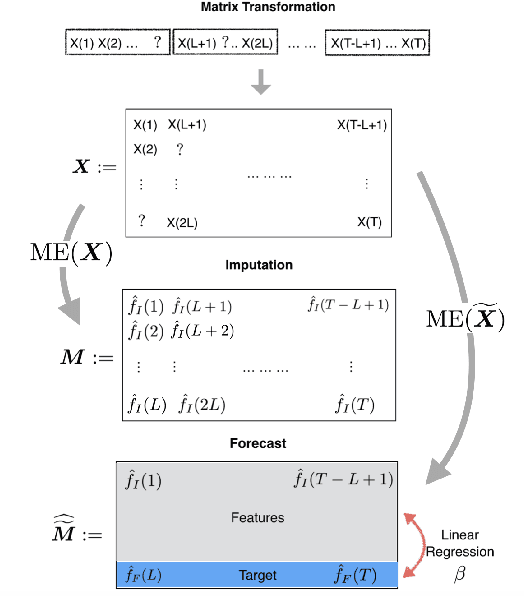
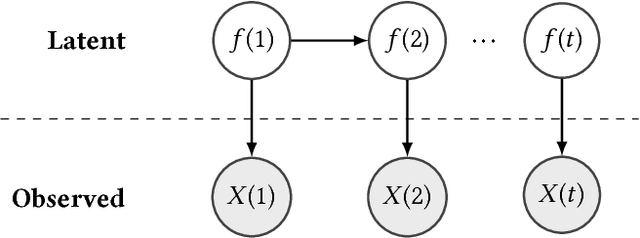
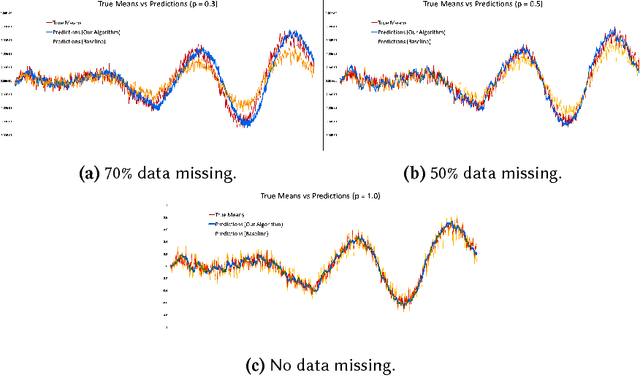
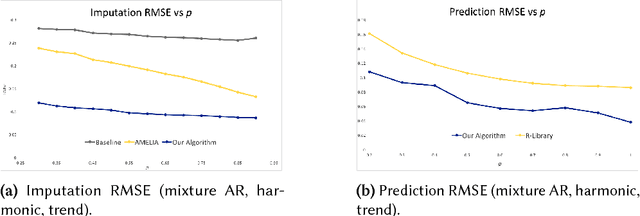
We propose an algorithm to impute and forecast a time series by transforming the observed time series into a matrix, utilizing matrix estimation to recover missing values and de-noise observed entries, and performing linear regression to make predictions. At the core of our analysis is a representation result, which states that for a large model class, the transformed matrix obtained from the time series via our algorithm is (approximately) low-rank. This, in effect, generalizes the widely used Singular Spectrum Analysis (SSA) in literature, and allows us to establish a rigorous link between time series analysis and matrix estimation. The key is to construct a matrix with non-overlapping entries rather than with the Hankel matrix as done in the literature, including in SSA. We provide finite sample analysis for imputation and prediction leading to the asymptotic consistency of our method. A salient feature of our algorithm is that it is model agnostic both with respect to the underlying time dynamics as well as the noise model in the observations. Being noise agnostic makes our algorithm applicable to the setting where the state is hidden and we only have access to its noisy observations a la a Hidden Markov Model, e.g., observing a Poisson process with a time-varying parameter without knowing that the process is Poisson, but still recovering the time-varying parameter accurately. As part of the forecasting algorithm, an important task is to perform regression with noisy observations of the features a la an error- in-variable regression. In essence, our approach suggests a matrix estimation based method for such a setting, which could be of interest in its own right. Through synthetic and real-world datasets, we demonstrate that our algorithm outperforms standard software packages (including R libraries) in the presence of missing data as well as high levels of noise.
Leaders, Followers, and Community Detectio
Jun 29, 2018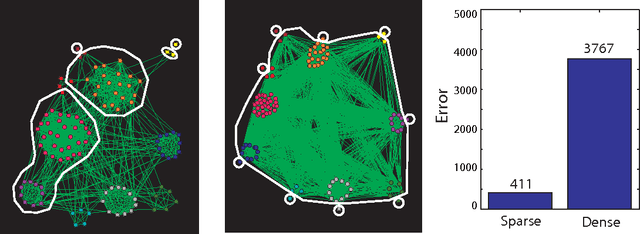
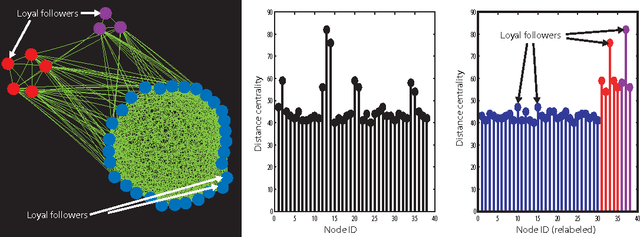
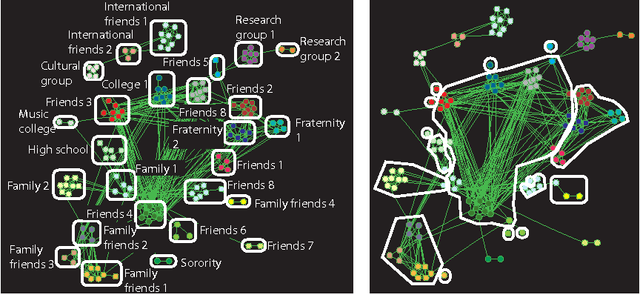
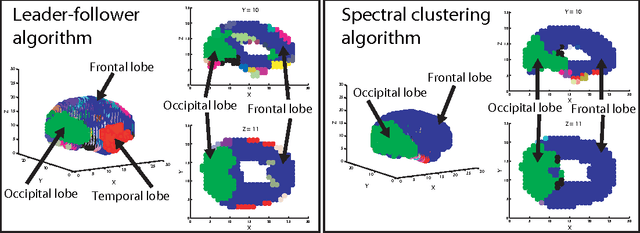
Communities in social networks or graphs are sets of well-connected, overlapping vertices. The effectiveness of a community detection algorithm is determined by accuracy in finding the ground-truth communities and ability to scale with the size of the data. In this work, we provide three contributions. First, we show that a popular measure of accuracy known as the F1 score, which is between 0 and 1, with 1 being perfect detection, has an information lower bound is 0.5. We provide a trivial algorithm that produces communities with an F1 score of 0.5 for any graph! Somewhat surprisingly, we find that popular algorithms such as modularity optimization, BigClam and CESNA have F1 scores less than 0.5 for the popular IMDB graph. To rectify this, as the second contribution we propose a generative model for community formation, the sequential community graph, which is motivated by the formation of social networks. Third, motivated by our generative model, we propose the leader-follower algorithm (LFA). We prove that it recovers all communities for sequential community graphs by establishing a structural result that sequential community graphs are chordal. For a large number of popular social networks, it recovers communities with a much higher F1 score than other popular algorithms. For the IMDB graph, it obtains an F1 score of 0.81. We also propose a modification to the LFA called the fast leader-follower algorithm (FLFA) which in addition to being highly accurate, is also fast, with a scaling that is almost linear in the network size.
Reducing Crowdsourcing to Graphon Estimation, Statistically
Feb 21, 2018Inferring the correct answers to binary tasks based on multiple noisy answers in an unsupervised manner has emerged as the canonical question for micro-task crowdsourcing or more generally aggregating opinions. In graphon estimation, one is interested in estimating edge intensities or probabilities between nodes using a single snapshot of a graph realization. In the recent literature, there has been exciting development within both of these topics. In the context of crowdsourcing, the key intellectual challenge is to understand whether a given task can be more accurately denoised by aggregating answers collected from other different tasks. In the context of graphon estimation, precise information limits and estimation algorithms remain of interest. In this paper, we utilize a statistical reduction from crowdsourcing to graphon estimation to advance the state-of-art for both of these challenges. We use concepts from graphon estimation to design an algorithm that achieves better performance than the {\em majority voting} scheme for a setup that goes beyond the {\em rank one} models considered in the literature. We use known explicit lower bounds for crowdsourcing to provide refined lower bounds for graphon estimation.