 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeceptive Diffusion: Generating Synthetic Adversarial Examples
Jun 28, 2024



We introduce the concept of deceptive diffusion -- training a generative AI model to produce adversarial images. Whereas a traditional adversarial attack algorithm aims to perturb an existing image to induce a misclassificaton, the deceptive diffusion model can create an arbitrary number of new, misclassified images that are not directly associated with training or test images. Deceptive diffusion offers the possibility of strengthening defence algorithms by providing adversarial training data at scale, including types of misclassification that are otherwise difficult to find. In our experiments, we also investigate the effect of training on a partially attacked data set. This highlights a new type of vulnerability for generative diffusion models: if an attacker is able to stealthily poison a portion of the training data, then the resulting diffusion model will generate a similar proportion of misleading outputs.
Stealth edits for provably fixing or attacking large language models
Jun 18, 2024



We reveal new methods and the theoretical foundations of techniques for editing large language models. We also show how the new theory can be used to assess the editability of models and to expose their susceptibility to previously unknown malicious attacks. Our theoretical approach shows that a single metric (a specific measure of the intrinsic dimensionality of the model's features) is fundamental to predicting the success of popular editing approaches, and reveals new bridges between disparate families of editing methods. We collectively refer to these approaches as stealth editing methods, because they aim to directly and inexpensively update a model's weights to correct the model's responses to known hallucinating prompts without otherwise affecting the model's behaviour, without requiring retraining. By carefully applying the insight gleaned from our theoretical investigation, we are able to introduce a new network block -- named a jet-pack block -- which is optimised for highly selective model editing, uses only standard network operations, and can be inserted into existing networks. The intrinsic dimensionality metric also determines the vulnerability of a language model to a stealth attack: a small change to a model's weights which changes its response to a single attacker-chosen prompt. Stealth attacks do not require access to or knowledge of the model's training data, therefore representing a potent yet previously unrecognised threat to redistributed foundation models. They are computationally simple enough to be implemented in malware in many cases. Extensive experimental results illustrate and support the method and its theoretical underpinnings. Demos and source code for editing language models are available at https://github.com/qinghua-zhou/stealth-edits.
Diffusion Models for Generative Artificial Intelligence: An Introduction for Applied Mathematicians
Dec 21, 2023Generative artificial intelligence (AI) refers to algorithms that create synthetic but realistic output. Diffusion models currently offer state of the art performance in generative AI for images. They also form a key component in more general tools, including text-to-image generators and large language models. Diffusion models work by adding noise to the available training data and then learning how to reverse the process. The reverse operation may then be applied to new random data in order to produce new outputs. We provide a brief introduction to diffusion models for applied mathematicians and statisticians. Our key aims are (a) to present illustrative computational examples, (b) to give a careful derivation of the underlying mathematical formulas involved, and (c) to draw a connection with partial differential equation (PDE) diffusion models. We provide code for the computational experiments. We hope that this topic will be of interest to advanced undergraduate students and postgraduate students. Portions of the material may also provide useful motivational examples for those who teach courses in stochastic processes, inference, machine learning, PDEs or scientific computing.
Vulnerability Analysis of Transformer-based Optical Character Recognition to Adversarial Attacks
Nov 28, 2023



Recent advancements in Optical Character Recognition (OCR) have been driven by transformer-based models. OCR systems are critical in numerous high-stakes domains, yet their vulnerability to adversarial attack remains largely uncharted territory, raising concerns about security and compliance with emerging AI regulations. In this work we present a novel framework to assess the resilience of Transformer-based OCR (TrOCR) models. We develop and assess algorithms for both targeted and untargeted attacks. For the untargeted case, we measure the Character Error Rate (CER), while for the targeted case we use the success ratio. We find that TrOCR is highly vulnerable to untargeted attacks and somewhat less vulnerable to targeted attacks. On a benchmark handwriting data set, untargeted attacks can cause a CER of more than 1 without being noticeable to the eye. With a similar perturbation size, targeted attacks can lead to success rates of around $25\%$ -- here we attacked single tokens, requiring TrOCR to output the tenth most likely token from a large vocabulary.
The Boundaries of Verifiable Accuracy, Robustness, and Generalisation in Deep Learning
Sep 13, 2023In this work, we assess the theoretical limitations of determining guaranteed stability and accuracy of neural networks in classification tasks. We consider classical distribution-agnostic framework and algorithms minimising empirical risks and potentially subjected to some weights regularisation. We show that there is a large family of tasks for which computing and verifying ideal stable and accurate neural networks in the above settings is extremely challenging, if at all possible, even when such ideal solutions exist within the given class of neural architectures.
How adversarial attacks can disrupt seemingly stable accurate classifiers
Sep 07, 2023



Adversarial attacks dramatically change the output of an otherwise accurate learning system using a seemingly inconsequential modification to a piece of input data. Paradoxically, empirical evidence indicates that even systems which are robust to large random perturbations of the input data remain susceptible to small, easily constructed, adversarial perturbations of their inputs. Here, we show that this may be seen as a fundamental feature of classifiers working with high dimensional input data. We introduce a simple generic and generalisable framework for which key behaviours observed in practical systems arise with high probability -- notably the simultaneous susceptibility of the (otherwise accurate) model to easily constructed adversarial attacks, and robustness to random perturbations of the input data. We confirm that the same phenomena are directly observed in practical neural networks trained on standard image classification problems, where even large additive random noise fails to trigger the adversarial instability of the network. A surprising takeaway is that even small margins separating a classifier's decision surface from training and testing data can hide adversarial susceptibility from being detected using randomly sampled perturbations. Counterintuitively, using additive noise during training or testing is therefore inefficient for eradicating or detecting adversarial examples, and more demanding adversarial training is required.
Backward error analysis and the qualitative behaviour of stochastic optimization algorithms: Application to stochastic coordinate descent
Sep 05, 2023


Stochastic optimization methods have been hugely successful in making large-scale optimization problems feasible when computing the full gradient is computationally prohibitive. Using the theory of modified equations for numerical integrators, we propose a class of stochastic differential equations that approximate the dynamics of general stochastic optimization methods more closely than the original gradient flow. Analyzing a modified stochastic differential equation can reveal qualitative insights about the associated optimization method. Here, we study mean-square stability of the modified equation in the case of stochastic coordinate descent.
Can We Rely on AI?
Aug 29, 2023
Over the last decade, adversarial attack algorithms have revealed instabilities in deep learning tools. These algorithms raise issues regarding safety, reliability and interpretability in artificial intelligence; especially in high risk settings. From a practical perspective, there has been a war of escalation between those developing attack and defence strategies. At a more theoretical level, researchers have also studied bigger picture questions concerning the existence and computability of attacks. Here we give a brief overview of the topic, focusing on aspects that are likely to be of interest to researchers in applied and computational mathematics.
Adversarial Ink: Componentwise Backward Error Attacks on Deep Learning
Jun 05, 2023



Deep neural networks are capable of state-of-the-art performance in many classification tasks. However, they are known to be vulnerable to adversarial attacks -- small perturbations to the input that lead to a change in classification. We address this issue from the perspective of backward error and condition number, concepts that have proved useful in numerical analysis. To do this, we build on the work of Beuzeville et al. (2021). In particular, we develop a new class of attack algorithms that use componentwise relative perturbations. Such attacks are highly relevant in the case of handwritten documents or printed texts where, for example, the classification of signatures, postcodes, dates or numerical quantities may be altered by changing only the ink consistency and not the background. This makes the perturbed images look natural to the naked eye. Such ``adversarial ink'' attacks therefore reveal a weakness that can have a serious impact on safety and security. We illustrate the new attacks on real data and contrast them with existing algorithms. We also study the use of a componentwise condition number to quantify vulnerability.
The Feasibility and Inevitability of Stealth Attacks
Jun 26, 2021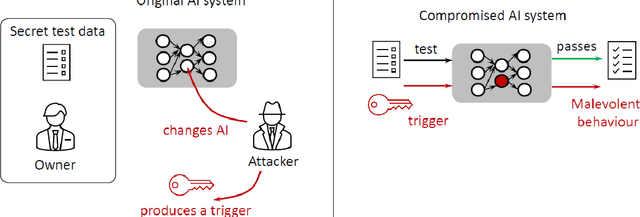
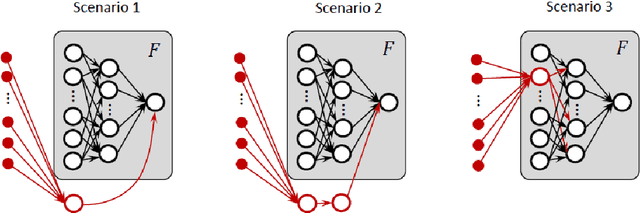
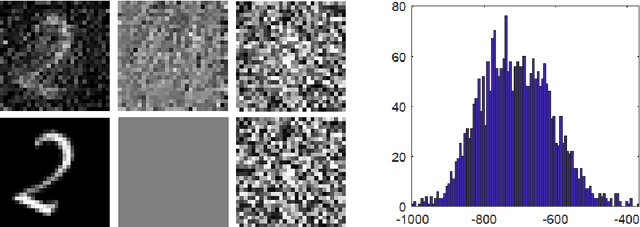
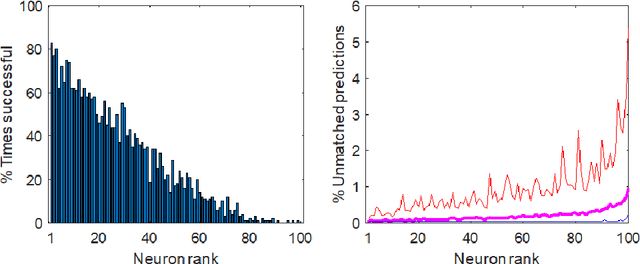
We develop and study new adversarial perturbations that enable an attacker to gain control over decisions in generic Artificial Intelligence (AI) systems including deep learning neural networks. In contrast to adversarial data modification, the attack mechanism we consider here involves alterations to the AI system itself. Such a stealth attack could be conducted by a mischievous, corrupt or disgruntled member of a software development team. It could also be made by those wishing to exploit a "democratization of AI" agenda, where network architectures and trained parameter sets are shared publicly. Building on work by [Tyukin et al., International Joint Conference on Neural Networks, 2020], we develop a range of new implementable attack strategies with accompanying analysis, showing that with high probability a stealth attack can be made transparent, in the sense that system performance is unchanged on a fixed validation set which is unknown to the attacker, while evoking any desired output on a trigger input of interest. The attacker only needs to have estimates of the size of the validation set and the spread of the AI's relevant latent space. In the case of deep learning neural networks, we show that a one neuron attack is possible - a modification to the weights and bias associated with a single neuron - revealing a vulnerability arising from over-parameterization. We illustrate these concepts in a realistic setting. Guided by the theory and computational results, we also propose strategies to guard against stealth attacks.