 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScene Compliant Trajectory Forecast with Agent-Centric Spatio-Temporal Grids
Sep 16, 2019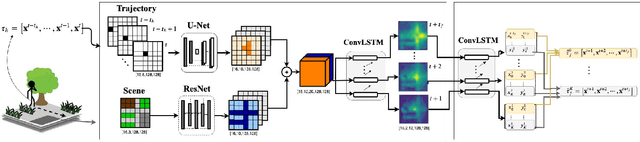
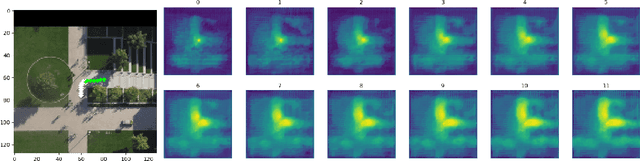
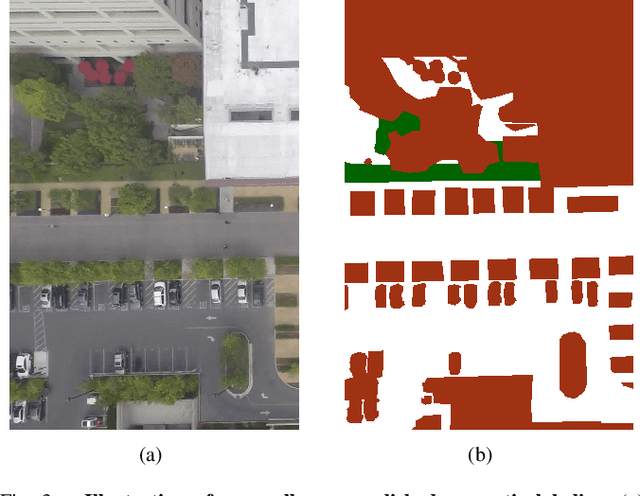
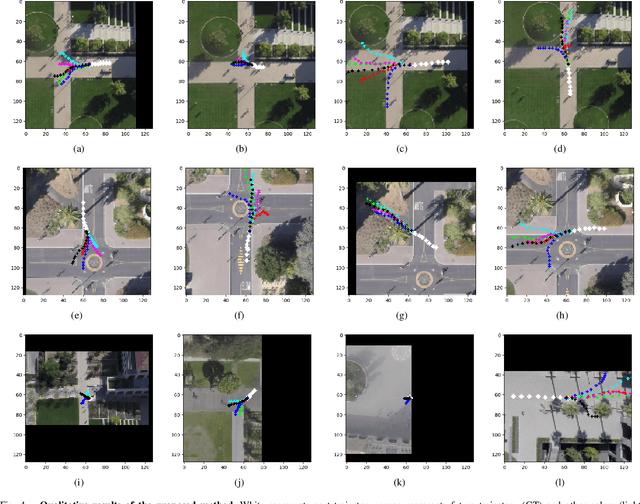
Forecasting long-term human motion is a challenging task due to the non-linearity, multi-modality and inherent uncertainty in future trajectories. The underlying scene and past motion of agents can provide useful cues to predict their future motion. However, the heterogeneity of the two inputs poses a challenge for learning a joint representation of the scene and past trajectories. To address this challenge, we propose a model based on grid representations to forecast agent trajectories. We represent the past trajectories of agents using binary 2-D grids, and the underlying scene as a RGB birds-eye view (BEV) image, with an agent-centric frame of reference. We encode the scene and past trajectories using convolutional layers and generate trajectory forecasts using a Convolutional LSTM (ConvLSTM) decoder. Results on the publicly available Stanford Drone Dataset (SDD) show that our model outperforms prior approaches and outputs realistic future trajectories that comply with scene structure and past motion.
Understanding Pedestrian-Vehicle Interactions with Vehicle Mounted Vision: An LSTM Model and Empirical Analysis
May 14, 2019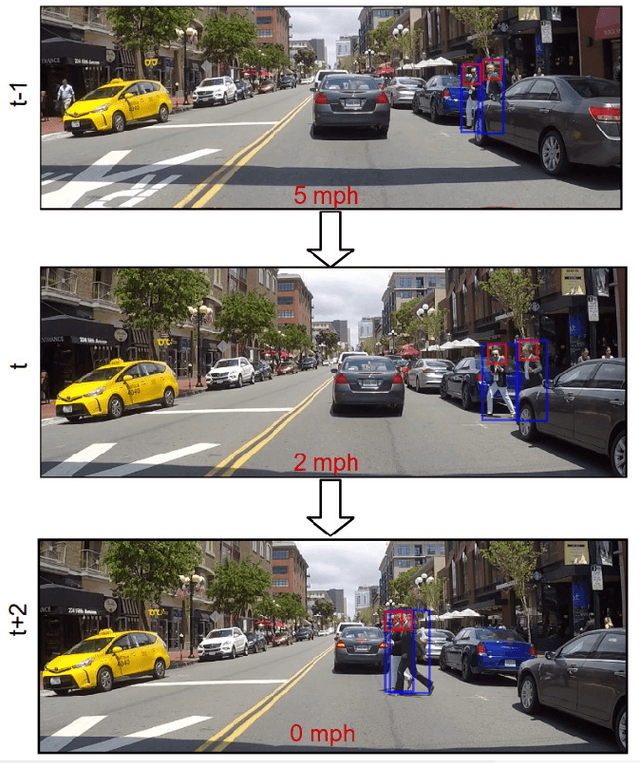
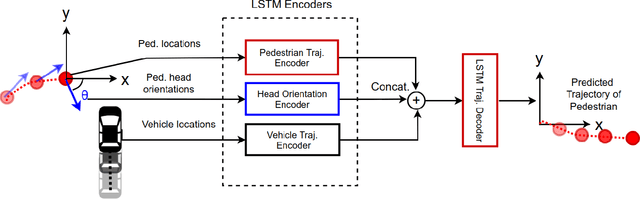
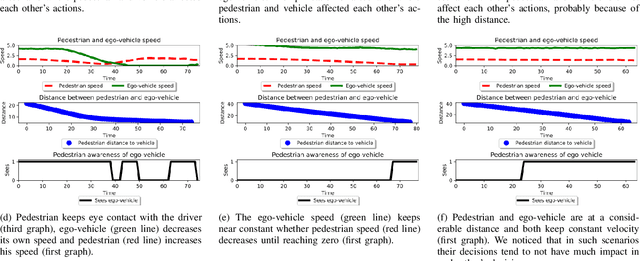
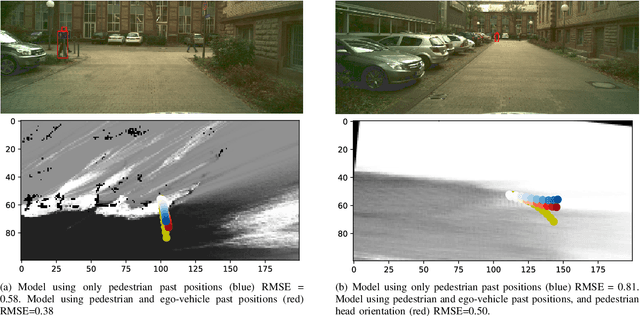
Pedestrians and vehicles often share the road in complex inner city traffic. This leads to interactions between the vehicle and pedestrians, with each affecting the other's motion. In order to create robust methods to reason about pedestrian behavior and to design interfaces of communication between self-driving cars and pedestrians we need to better understand such interactions. In this paper, we present a data-driven approach to implicitly model pedestrians' interactions with vehicles, to better predict pedestrian behavior. We propose a LSTM model that takes as input the past trajectories of the pedestrian and ego-vehicle, and pedestrian head orientation, and predicts the future positions of the pedestrian. Our experiments based on a real-world, inner city dataset captured with vehicle mounted cameras, show that the usage of such cues improve pedestrian prediction when compared to a baseline that purely uses the past trajectory of the pedestrian.
Instance Segmentation as Image Segmentation Annotation
Feb 01, 2019
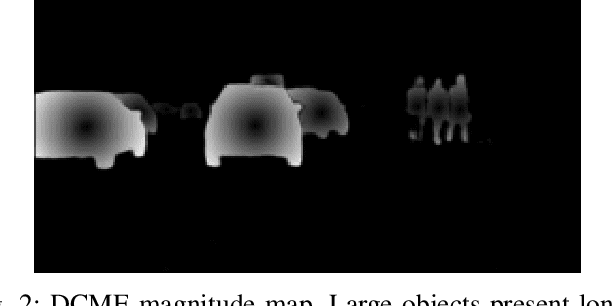

The instance segmentation problem intends to precisely detect and delineate objects in images. Most of the current solutions rely on deep convolutional neural networks but despite this fact proposed solutions are very diverse. Some solutions approach the problem as a network problem, where they use several networks or specialize a single network to solve several tasks. A different approach tries to solve the problem as an annotation problem, where the instance information is encoded in a mathematical representation. This work proposes a solution based in the DCME technique to solve the instance segmentation with a single segmentation network. Different from others, the segmentation network decoder is not specialized in a multi-task network. Instead, the network encoder is repurposed to classify image objects, reducing the computational cost of the solution.
Verisimilar Percept Sequences Tests for Autonomous Driving Intelligent Agent Assessment
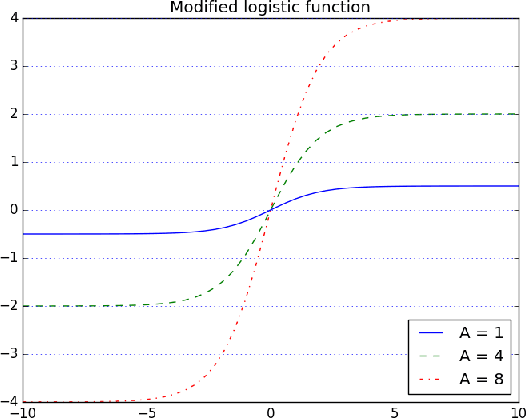
May 07, 2018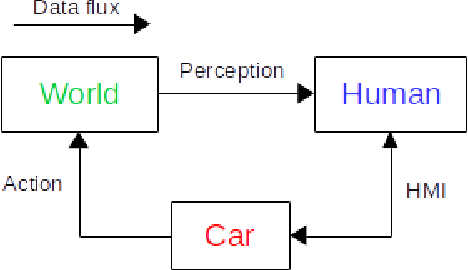
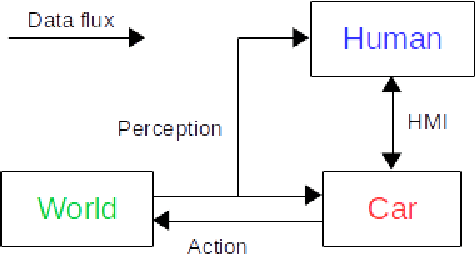
The autonomous car technology promises to replace human drivers with safer driving systems. But although autonomous cars can become safer than human drivers this is a long process that is going to be refined over time. Before these vehicles are deployed on urban roads a minimum safety level must be assured. Since the autonomous car technology is still under development there is no standard methodology to evaluate such systems. It is important to completely understand the technology that is being developed to design efficient means to evaluate it. In this paper we assume safety-critical systems reliability as a safety measure. We model an autonomous road vehicle as an intelligent agent and we approach its evaluation from an artificial intelligence perspective. Our focus is the evaluation of perception and decision making systems and also to propose a systematic method to evaluate their integration in the vehicle. We identify critical aspects of the data dependency from the artificial intelligence state of the art models and we also propose procedures to reproduce them.
Distance to Center of Mass Encoding for Instance Segmentation
Nov 24, 2017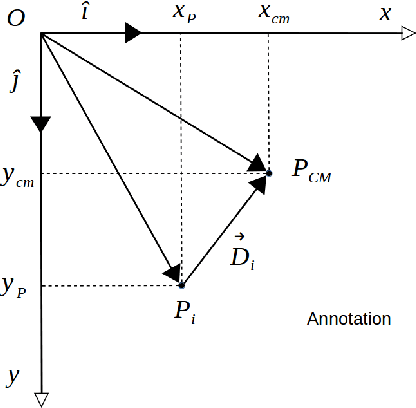



The instance segmentation can be considered an extension of the object detection problem where bounding boxes are replaced by object contours. Strictly speaking the problem requires to identify each pixel instance and class independently of the artifice used for this mean. The advantage of instance segmentation over the usual object detection lies in the precise delineation of objects improving object localization. Additionally, object contours allow the evaluation of partial occlusion with basic image processing algorithms. This work approaches the instance segmentation problem as an annotation problem and presents a novel technique to encode and decode ground truth annotations. We propose a mathematical representation of instances that any deep semantic segmentation model can learn and generalize. Each individual instance is represented by a center of mass and a field of vectors pointing to it. This encoding technique has been denominated Distance to Center of Mass Encoding (DCME).