 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Verification Fails: How Compositionally Infeasible Claims Escape Rejection
Apr 13, 2026Scientific claim verification, the task of determining whether claims are entailed by scientific evidence, is fundamental to establishing discoveries in evidence while preventing misinformation. This process involves evaluating each asserted constraint against validated evidence. Under the Closed-World Assumption (CWA), a claim is accepted if and only if all asserted constraints are positively supported. We show that existing verification benchmarks cannot distinguish models enforcing this standard from models applying a simpler shortcut called salient-constraint checking, which applies CWA's rejection criterion only to the most salient constraint and accepts when that constraint is supported. Because existing benchmarks construct infeasible claims by perturbing a single salient element they are insufficient at distinguishing between rigorous claim verification and simple salient-constraint reliance. To separate the two, we construct compositionally infeasible claims where the salient constraint is supported but a non-salient constraint is contradicted. Across model families and modalities, models that otherwise saturate existing benchmarks consistently over-accept these claims, confirming the prevalence of such shortcut reasoning. Via model context interventions, we show that different models and prompting strategies occupy distinct positions on a shared ROC curve, indicating that the gap between model families reflects differences in verification threshold rather than underlying reasoning ability, and that the compositional inference bottleneck is a structural property of current verification behavior that strategy guidance alone cannot overcome.
BibTeX Citation Hallucinations in Scientific Publishing Agents: Evaluation and Mitigation
Apr 03, 2026Large language models with web search are increasingly used in scientific publishing agents, yet they still produce BibTeX entries with pervasive field-level errors. Prior evaluations tested base models without search, which does not reflect current practice. We construct a benchmark of 931 papers across four scientific domains and three citation tiers -- popular, low-citation, and recent post-cutoff -- designed to disentangle parametric memory from search dependence, with version-aware ground truth accounting for multiple citable versions of the same paper. Three search-enabled frontier models (GPT-5, Claude Sonnet-4.6, Gemini-3 Flash) generate BibTeX entries scored on nine fields and a six-way error taxonomy, producing ~23,000 field-level observations. Overall accuracy is 83.6%, but only 50.9% of entries are fully correct; accuracy drops 27.7pp from popular to recent papers, revealing heavy reliance on parametric memory even when search is available. Field-error co-occurrence analysis identifies two failure modes: wholesale entry substitution (identity fields fail together) and isolated field error. We evaluate clibib, an open-source tool for deterministic BibTeX retrieval from the Zotero Translation Server with CrossRef fallback, as a mitigation mechanism. In a two-stage integration where baseline entries are revised against authoritative records, accuracy rises +8.0pp to 91.5%, fully correct entries rise from 50.9% to 78.3%, and regression rate is only 0.8%. An ablation comparing single-stage and two-stage integration shows that separating search from revision yields larger gains and lower regression (0.8% vs. 4.8%), demonstrating that integration architecture matters independently of model capability. We release the benchmark, error taxonomy, and clibib tool to support evaluation and mitigation of citation hallucinations in LLM-based scientific writing.
Detecting and Correcting Reference Hallucinations in Commercial LLMs and Deep Research Agents
Apr 03, 2026Large language models and deep research agents supply citation URLs to support their claims, yet the reliability of these citations has not been systematically measured. We address six research questions about citation URL validity using 10 models and agents on DRBench (53,090 URLs) and 3 models on ExpertQA (168,021 URLs across 32 academic fields). We find that 3--13\% of citation URLs are hallucinated -- they have no record in the Wayback Machine and likely never existed -- while 5--18\% are non-resolving overall. Deep research agents generate substantially more citations per query than search-augmented LLMs but hallucinate URLs at higher rates. Domain effects are pronounced: non-resolving rates range from 5.4\% (Business) to 11.4\% (Theology), with per-model effects even larger. Decomposing failures reveals that some models fabricate every non-resolving URL, while others show substantial link-rot fractions indicating genuine retrieval. As a solution, we release urlhealth, an open-source tool for URL liveness checking and stale-vs-hallucinated classification using the Wayback Machine. In agentic self-correction experiments, models equipped with urlhealth reduce non-resolving citation URLs by $6\textrm{--}79\times$ to under 1\%, though effectiveness depends on the model's tool-use competence. The tool and all data are publicly available. Our characterization findings, failure taxonomy, and open-source tooling establish that citation URL validity is both measurable at scale and correctable in practice.
What Do Claim Verification Datasets Actually Test? A Reasoning Trace Analysis
Apr 02, 2026Despite rapid progress in claim verification, we lack a systematic understanding of what reasoning these benchmarks actually exercise. We generate structured reasoning traces for 24K claim-verification examples across 9 datasets using GPT-4o-mini and find that direct evidence extraction dominates, while multi-sentence synthesis and numerical reasoning are severely under-represented. A dataset-level breakdown reveals stark biases: some datasets almost exclusively test lexical matching, while others require information synthesis in roughly half of cases. Using a compact 1B-parameter reasoning verifier, we further characterize five error types and show that error profiles vary dramatically by domain -- general-domain verification is dominated by lexical overlap bias, scientific verification by overcautiousness, and mathematical verification by arithmetic reasoning failures. Our findings suggest that high benchmark scores primarily reflect retrieval-plus-entailment ability. We outline recommendations for building more challenging evaluation suites that better test the reasoning capabilities verification systems need.
ThinknCheck: Grounded Claim Verification with Compact, Reasoning-Driven, and Interpretable Models
Apr 02, 2026We present ThinknCheck, a 1B-parameter verifier for grounded claim verification that first produces a short, structured rationale and then a binary verdict. We construct LLMAggreFact-Think, a 24.1k reasoning-augmented training set derived from LLMAggreFact, and fine-tune a 4-bit Gemma3 model to follow this format. On LLMAggreFact, ThinknCheck attains 78.1 balanced accuracy (BAcc), surpassing MiniCheck-7B (77.4) with 7x fewer parameters; removing the reasoning step reduces BAcc to 57.5. On SciFact, ThinknCheck reaches 64.7 BAcc, a +14.7 absolute gain over MiniCheck-7B. By contrast, zero-shot chain-of-thought on the base Gemma3-1B harms accuracy relative to direct answers, and preference optimization with a simple format+accuracy reward underperforms supervised reasoning. To probe the latter, we introduce GSMClaims and a domain-specialized variant, ThinknCheck-Science, which improves across benchmarks, including 61.0\% accuracy on GSMClaims. Overall, explicit, supervised reasoning enables compact verifiers that are competitive while remaining resource-efficient and interpretable.
NSF-SciFy: Mining the NSF Awards Database for Scientific Claims
Mar 11, 2025



We present NSF-SciFy, a large-scale dataset for scientific claim extraction derived from the National Science Foundation (NSF) awards database, comprising over 400K grant abstracts spanning five decades. While previous datasets relied on published literature, we leverage grant abstracts which offer a unique advantage: they capture claims at an earlier stage in the research lifecycle before publication takes effect. We also introduce a new task to distinguish between existing scientific claims and aspirational research intentions in proposals.Using zero-shot prompting with frontier large language models, we jointly extract 114K scientific claims and 145K investigation proposals from 16K grant abstracts in the materials science domain to create a focused subset called NSF-SciFy-MatSci. We use this dataset to evaluate 3 three key tasks: (1) technical to non-technical abstract generation, where models achieve high BERTScore (0.85+ F1); (2) scientific claim extraction, where fine-tuned models outperform base models by 100% relative improvement; and (3) investigation proposal extraction, showing 90%+ improvement with fine-tuning. We introduce novel LLM-based evaluation metrics for robust assessment of claim/proposal extraction quality. As the largest scientific claim dataset to date -- with an estimated 2.8 million claims across all STEM disciplines funded by the NSF -- NSF-SciFy enables new opportunities for claim verification and meta-scientific research. We publicly release all datasets, trained models, and evaluation code to facilitate further research.
WithdrarXiv: A Large-Scale Dataset for Retraction Study
Dec 04, 2024



Retractions play a vital role in maintaining scientific integrity, yet systematic studies of retractions in computer science and other STEM fields remain scarce. We present WithdrarXiv, the first large-scale dataset of withdrawn papers from arXiv, containing over 14,000 papers and their associated retraction comments spanning the repository's entire history through September 2024. Through careful analysis of author comments, we develop a comprehensive taxonomy of retraction reasons, identifying 10 distinct categories ranging from critical errors to policy violations. We demonstrate a simple yet highly accurate zero-shot automatic categorization of retraction reasons, achieving a weighted average F1-score of 0.96. Additionally, we release WithdrarXiv-SciFy, an enriched version including scripts for parsed full-text PDFs, specifically designed to enable research in scientific feasibility studies, claim verification, and automated theorem proving. These findings provide valuable insights for improving scientific quality control and automated verification systems. Finally, and most importantly, we discuss ethical issues and take a number of steps to implement responsible data release while fostering open science in this area.
Learning Interpretable Style Embeddings via Prompting LLMs
May 22, 2023



Style representation learning builds content-independent representations of author style in text. Stylometry, the analysis of style in text, is often performed by expert forensic linguists and no large dataset of stylometric annotations exists for training. Current style representation learning uses neural methods to disentangle style from content to create style vectors, however, these approaches result in uninterpretable representations, complicating their usage in downstream applications like authorship attribution where auditing and explainability is critical. In this work, we use prompting to perform stylometry on a large number of texts to create a synthetic dataset and train human-interpretable style representations we call LISA embeddings. We release our synthetic stylometry dataset and our interpretable style models as resources.
Faithful Chain-of-Thought Reasoning
Feb 01, 2023



While Chain-of-Thought (CoT) prompting boosts Language Models' (LM) performance on a gamut of complex reasoning tasks, the generated reasoning chain does not necessarily reflect how the model arrives at the answer (aka. faithfulness). We propose Faithful CoT, a faithful-by-construction framework that decomposes a reasoning task into two stages: Translation (Natural Language query $\rightarrow$ symbolic reasoning chain) and Problem Solving (reasoning chain $\rightarrow$ answer), using an LM and a deterministic solver respectively. We demonstrate the efficacy of our approach on 10 reasoning datasets from 4 diverse domains. It outperforms traditional CoT prompting on 9 out of the 10 datasets, with an average accuracy gain of 4.4 on Math Word Problems, 1.9 on Planning, 4.0 on Multi-hop Question Answering (QA), and 18.1 on Logical Inference, under greedy decoding. Together with self-consistency decoding, we achieve new state-of-the-art few-shot performance on 7 out of the 10 datasets, showing a strong synergy between faithfulness and accuracy.
Listening to the World Improves Speech Command Recognition
Oct 23, 2017
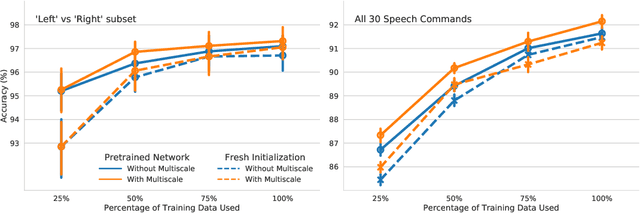
We study transfer learning in convolutional network architectures applied to the task of recognizing audio, such as environmental sound events and speech commands. Our key finding is that not only is it possible to transfer representations from an unrelated task like environmental sound classification to a voice-focused task like speech command recognition, but also that doing so improves accuracies significantly. We also investigate the effect of increased model capacity for transfer learning audio, by first validating known results from the field of Computer Vision of achieving better accuracies with increasingly deeper networks on two audio datasets: UrbanSound8k and the newly released Google Speech Commands dataset. Then we propose a simple multiscale input representation using dilated convolutions and show that it is able to aggregate larger contexts and increase classification performance. Further, the models trained using a combination of transfer learning and multiscale input representations need only 40% of the training data to achieve similar accuracies as a freshly trained model with 100% of the training data. Finally, we demonstrate a positive interaction effect for the multiscale input and transfer learning, making a case for the joint application of the two techniques.