 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGradient-based Novelty Detection Boosted by Self-supervised Binary Classification
Dec 18, 2021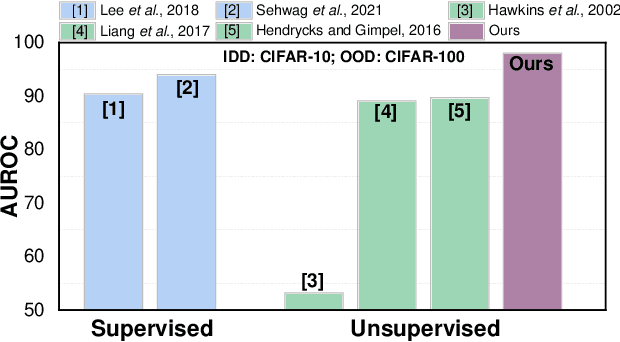
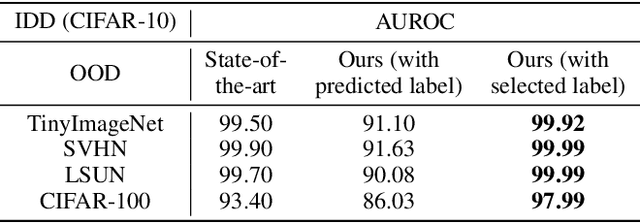
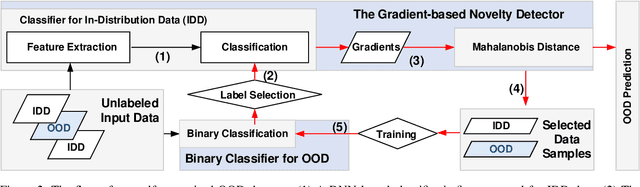
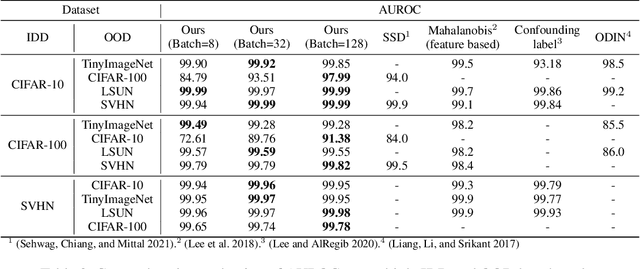
Novelty detection aims to automatically identify out-of-distribution (OOD) data, without any prior knowledge of them. It is a critical step in data monitoring, behavior analysis and other applications, helping enable continual learning in the field. Conventional methods of OOD detection perform multi-variate analysis on an ensemble of data or features, and usually resort to the supervision with OOD data to improve the accuracy. In reality, such supervision is impractical as one cannot anticipate the anomalous data. In this paper, we propose a novel, self-supervised approach that does not rely on any pre-defined OOD data: (1) The new method evaluates the Mahalanobis distance of the gradients between the in-distribution and OOD data. (2) It is assisted by a self-supervised binary classifier to guide the label selection to generate the gradients, and maximize the Mahalanobis distance. In the evaluation with multiple datasets, such as CIFAR-10, CIFAR-100, SVHN and TinyImageNet, the proposed approach consistently outperforms state-of-the-art supervised and unsupervised methods in the area under the receiver operating characteristic (AUROC) and area under the precision-recall curve (AUPR) metrics. We further demonstrate that this detector is able to accurately learn one OOD class in continual learning.
DeepSteal: Advanced Model Extractions Leveraging Efficient Weight Stealing in Memories
Nov 08, 2021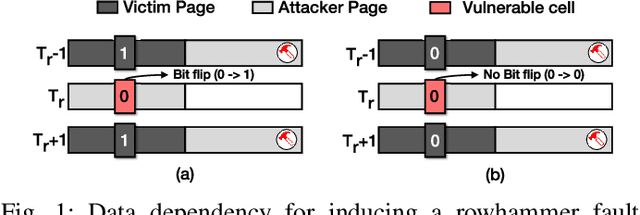
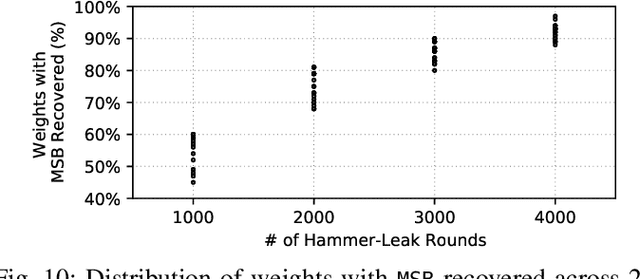
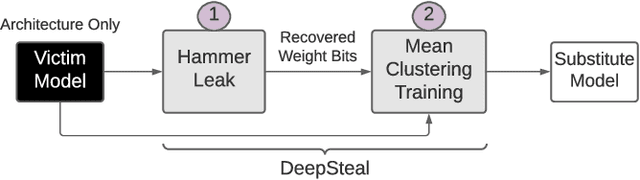
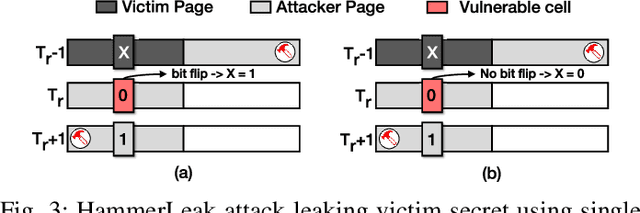
Recent advancements of Deep Neural Networks (DNNs) have seen widespread deployment in multiple security-sensitive domains. The need of resource-intensive training and use of valuable domain-specific training data have made these models a top intellectual property (IP) for model owners. One of the major threats to the DNN privacy is model extraction attacks where adversaries attempt to steal sensitive information in DNN models. Recent studies show hardware-based side channel attacks can reveal internal knowledge about DNN models (e.g., model architectures) However, to date, existing attacks cannot extract detailed model parameters (e.g., weights/biases). In this work, for the first time, we propose an advanced model extraction attack framework DeepSteal that effectively steals DNN weights with the aid of memory side-channel attack. Our proposed DeepSteal comprises two key stages. Firstly, we develop a new weight bit information extraction method, called HammerLeak, through adopting the rowhammer based hardware fault technique as the information leakage vector. HammerLeak leverages several novel system-level techniques tailed for DNN applications to enable fast and efficient weight stealing. Secondly, we propose a novel substitute model training algorithm with Mean Clustering weight penalty, which leverages the partial leaked bit information effectively and generates a substitute prototype of the target victim model. We evaluate this substitute model extraction method on three popular image datasets (e.g., CIFAR-10/100/GTSRB) and four DNN architectures (e.g., ResNet-18/34/Wide-ResNet/VGG-11). The extracted substitute model has successfully achieved more than 90 % test accuracy on deep residual networks for the CIFAR-10 dataset. Moreover, our extracted substitute model could also generate effective adversarial input samples to fool the victim model.
GROWN: GRow Only When Necessary for Continual Learning
Oct 03, 2021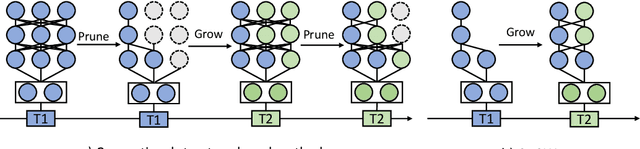
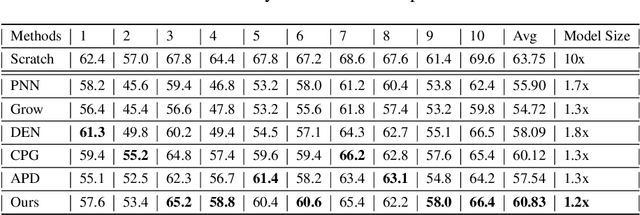

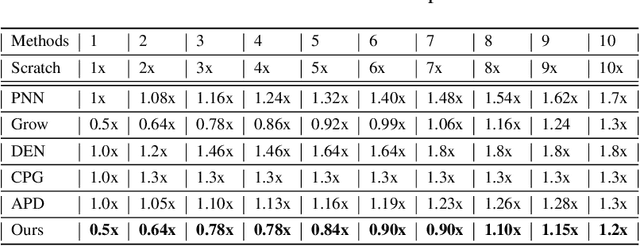
Catastrophic forgetting is a notorious issue in deep learning, referring to the fact that Deep Neural Networks (DNN) could forget the knowledge about earlier tasks when learning new tasks. To address this issue, continual learning has been developed to learn new tasks sequentially and perform knowledge transfer from the old tasks to the new ones without forgetting. While recent structure-based learning methods show the capability of alleviating the forgetting problem, these methods start from a redundant full-size network and require a complex learning process to gradually grow-and-prune or search the network structure for each task, which is inefficient. To address this problem and enable efficient network expansion for new tasks, we first develop a learnable sparse growth method eliminating the additional pruning/searching step in previous structure-based methods. Building on this learnable sparse growth method, we then propose GROWN, a novel end-to-end continual learning framework to dynamically grow the model only when necessary. Different from all previous structure-based methods, GROWN starts from a small seed network, instead of a full-sized one. We validate GROWN on multiple datasets against state-of-the-art methods, which shows superior performance in both accuracy and model size. For example, we achieve 1.0\% accuracy gain on average compared to the current SOTA results on CIFAR-100 Superclass 20 tasks setting.
RA-BNN: Constructing Robust & Accurate Binary Neural Network to Simultaneously Defend Adversarial Bit-Flip Attack and Improve Accuracy
Mar 22, 2021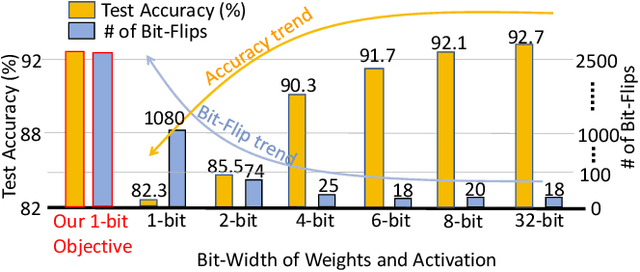
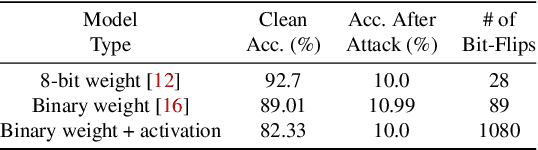
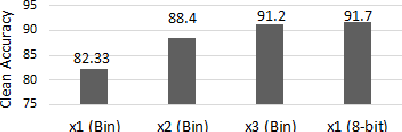

Recently developed adversarial weight attack, a.k.a. bit-flip attack (BFA), has shown enormous success in compromising Deep Neural Network (DNN) performance with an extremely small amount of model parameter perturbation. To defend against this threat, we propose RA-BNN that adopts a complete binary (i.e., for both weights and activation) neural network (BNN) to significantly improve DNN model robustness (defined as the number of bit-flips required to degrade the accuracy to as low as a random guess). However, such an aggressive low bit-width model suffers from poor clean (i.e., no attack) inference accuracy. To counter this, we propose a novel and efficient two-stage network growing method, named Early-Growth. It selectively grows the channel size of each BNN layer based on channel-wise binary masks training with Gumbel-Sigmoid function. Apart from recovering the inference accuracy, our RA-BNN after growing also shows significantly higher resistance to BFA. Our evaluation of the CIFAR-10 dataset shows that the proposed RA-BNN can improve the clean model accuracy by ~2-8 %, compared with a baseline BNN, while simultaneously improving the resistance to BFA by more than 125 x. Moreover, on ImageNet, with a sufficiently large (e.g., 5,000) amount of bit-flips, the baseline BNN accuracy drops to 4.3 % from 51.9 %, while our RA-BNN accuracy only drops to 37.1 % from 60.9 % (9 % clean accuracy improvement).
RADAR: Run-time Adversarial Weight Attack Detection and Accuracy Recovery
Jan 20, 2021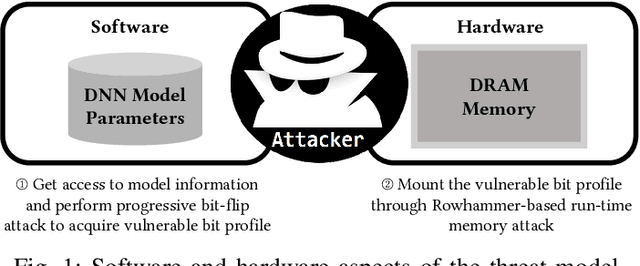
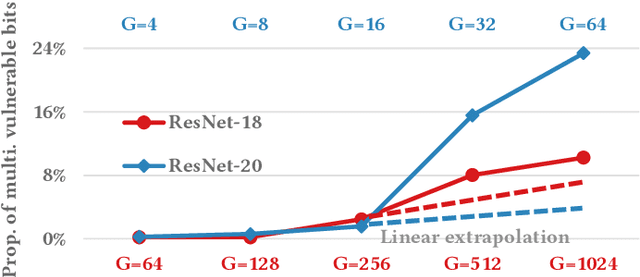
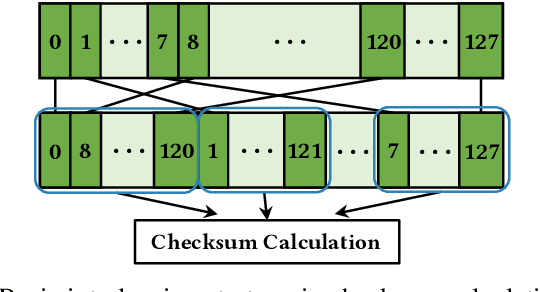
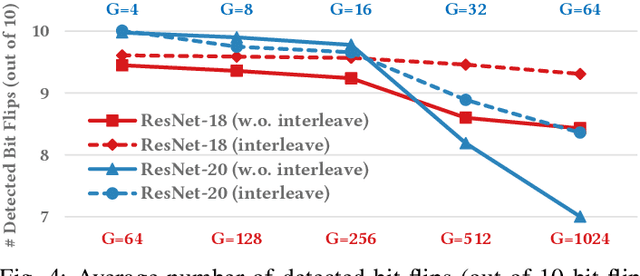
Adversarial attacks on Neural Network weights, such as the progressive bit-flip attack (PBFA), can cause a catastrophic degradation in accuracy by flipping a very small number of bits. Furthermore, PBFA can be conducted at run time on the weights stored in DRAM main memory. In this work, we propose RADAR, a Run-time adversarial weight Attack Detection and Accuracy Recovery scheme to protect DNN weights against PBFA. We organize weights that are interspersed in a layer into groups and employ a checksum-based algorithm on weights to derive a 2-bit signature for each group. At run time, the 2-bit signature is computed and compared with the securely stored golden signature to detect the bit-flip attacks in a group. After successful detection, we zero out all the weights in a group to mitigate the accuracy drop caused by malicious bit-flips. The proposed scheme is embedded in the inference computation stage. For the ResNet-18 ImageNet model, our method can detect 9.6 bit-flips out of 10 on average. For this model, the proposed accuracy recovery scheme can restore the accuracy from below 1% caused by 10 bit flips to above 69%. The proposed method has extremely low time and storage overhead. System-level simulation on gem5 shows that RADAR only adds <1% to the inference time, making this scheme highly suitable for run-time attack detection and mitigation.
DA2: Deep Attention Adapter for Memory-EfficientOn-Device Multi-Domain Learning
Dec 02, 2020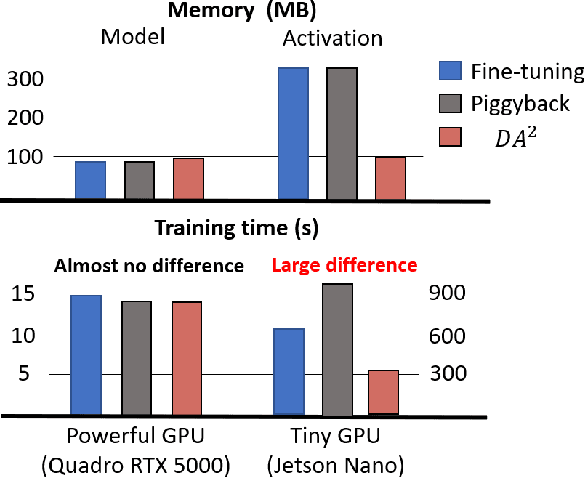

Nowadays, one practical limitation of deep neural network (DNN) is its high degree of specialization to a single task or domain (e.g. one visual domain). It motivates researchers to develop algorithms that can adapt DNN model to multiple domains sequentially, meanwhile still performing well on the past domains, which is known as multi-domain learning. Conventional methods only focus on improving accuracy with minimal parameter update, while ignoring high computing and memory usage during training, which makes it impossible to deploy into more and more widely used resource-limited edge devices, like mobile phone, IoT, embedded systems, etc. During our study, we observe that memory used for activation storage is the bottleneck that largely limits the training time and cost on edge devices. To reduce training memory usage, while keeping the domain adaption accuracy performance, in this work, we propose Deep Attention Adaptor, a novel on-device multi-domain learning method, aiming to achieve domain adaption on resource-limited edge devices in both fast and memory-efficient manner. During on-device training, DA2 freezes the weights of pre-trained backbone model to reduce the training memory consumption (i.e., no need to store activation features during backward propagation). Furthermore, to improve the adaption accuracy performance, we propose to improve the model capacity by learning a light-weight memory-efficient residual attention adaptor module. We validate DA2 on multiple datasets against state-of-the-art methods, which shows good improvement in both accuracy and training cost. Finally, we demonstrate the algorithm's efficiency on NIVDIA Jetson Nano tiny GPU, proving the proposed DA2 reduces the on-device memory consumption by 19-37x during training in comparison to the baseline methods.
MetaGater: Fast Learning of Conditional Channel Gated Networks via Federated Meta-Learning
Nov 28, 2020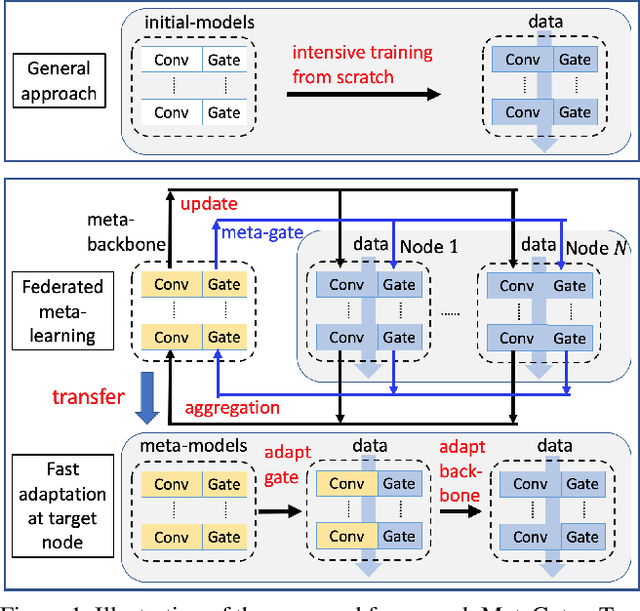
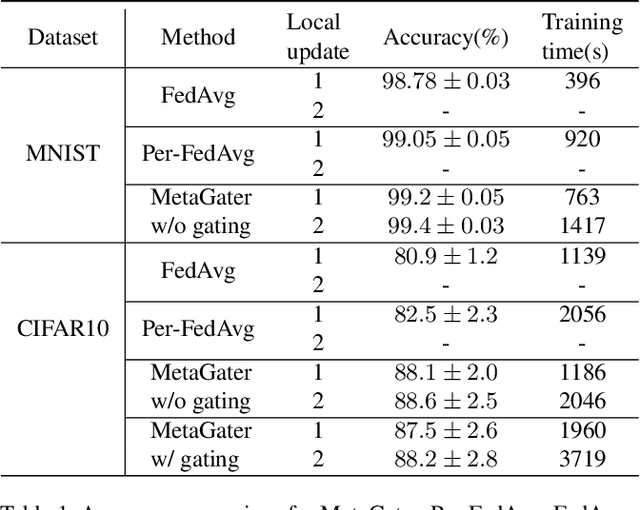
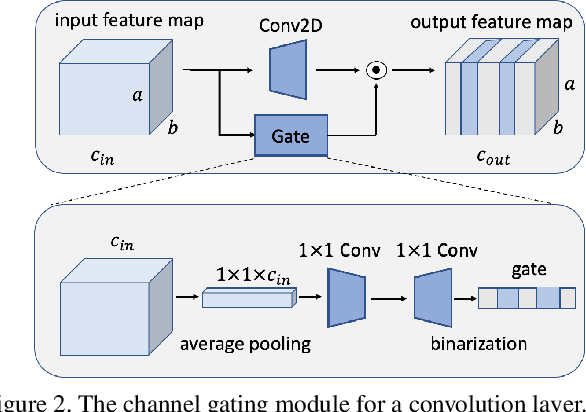

While deep learning has achieved phenomenal successes in many AI applications, its enormous model size and intensive computation requirements pose a formidable challenge to the deployment in resource-limited nodes. There has recently been an increasing interest in computationally-efficient learning methods, e.g., quantization, pruning and channel gating. However, most existing techniques cannot adapt to different tasks quickly. In this work, we advocate a holistic approach to jointly train the backbone network and the channel gating which enables dynamical selection of a subset of filters for more efficient local computation given the data input. Particularly, we develop a federated meta-learning approach to jointly learn good meta-initializations for both backbone networks and gating modules, by making use of the model similarity across learning tasks on different nodes. In this way, the learnt meta-gating module effectively captures the important filters of a good meta-backbone network, based on which a task-specific conditional channel gated network can be quickly adapted, i.e., through one-step gradient descent, from the meta-initializations in a two-stage procedure using new samples of that task. The convergence of the proposed federated meta-learning algorithm is established under mild conditions. Experimental results corroborate the effectiveness of our method in comparison to related work.
Deep-Dup: An Adversarial Weight Duplication Attack Framework to Crush Deep Neural Network in Multi-Tenant FPGA
Nov 05, 2020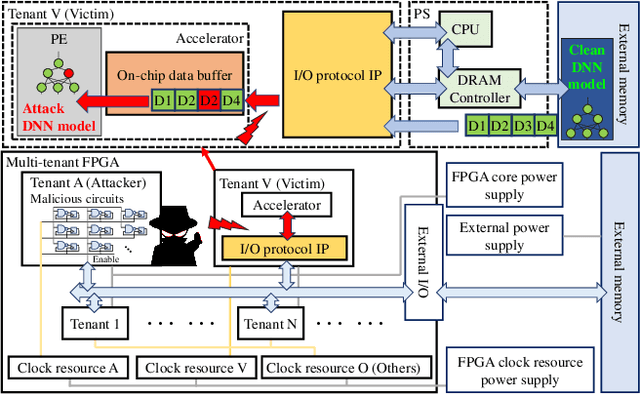
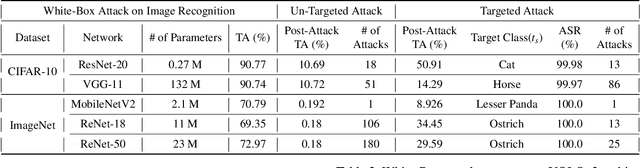
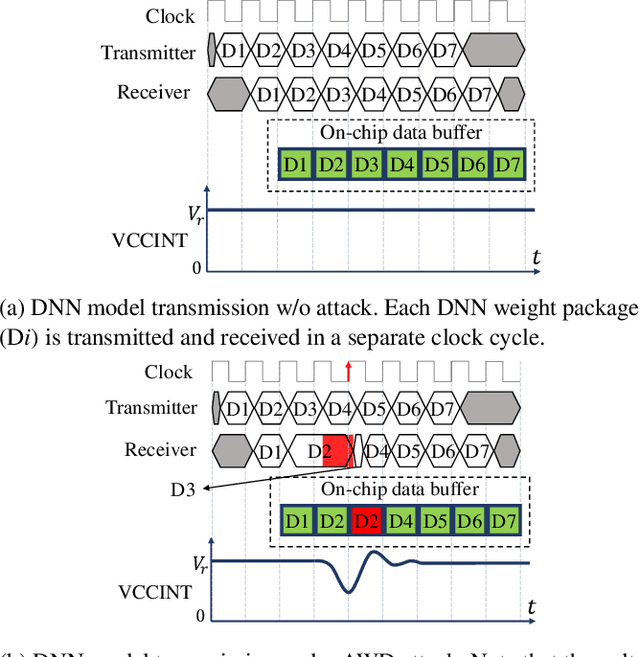
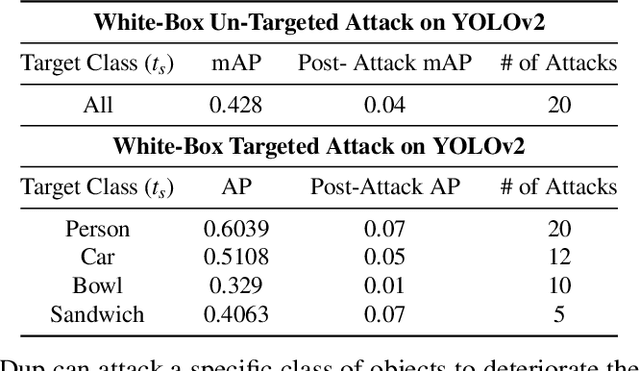
The wide deployment of Deep Neural Networks (DNN) in high-performance cloud computing platforms has emerged field-programmable gate arrays (FPGA) as a popular choice of accelerator to boost performance due to its hardware reprogramming flexibility. To improve the efficiency of hardware resource utilization, growing efforts have been invested in FPGA virtualization, enabling the co-existence of multiple independent tenants in a shared FPGA chip. Such a multi-tenant FPGA setup for DNN acceleration potentially exposes the DNN interference task under severe threat from malicious users. This work, to the best of our knowledge, is the first to explore DNN model vulnerabilities in multi-tenant FPGAs. We propose a novel adversarial attack framework: Deep-Dup, in which the adversarial tenant can inject faults to the DNN model of victim tenant in FPGA. Specifically, she can aggressively overload the shared power distribution system of FPGA with malicious power-plundering circuits, achieving adversarial weight duplication (AWD) hardware attack that duplicates certain DNN weight packages during data transmission between off-chip memory and on-chip buffer, with the objective to hijack DNN function of the victim tenant. Further, to identify the most vulnerable DNN weight packages for a given malicious objective, we propose a generic vulnerable weight package searching algorithm, called Progressive Differential Evolution Search (P-DES), which is, for the first time, adaptive to both deep learning white-box and black-box attack models. Unlike prior works only working in a deep learning white-box setup, our adaptiveness mainly comes from the fact that the proposed P-DES does not require any gradient information of DNN model.
A Progressive Sub-Network Searching Framework for Dynamic Inference
Sep 11, 2020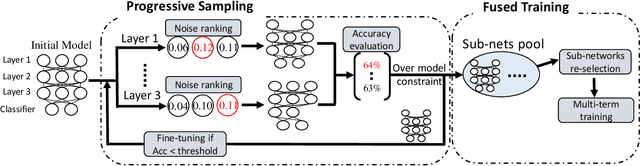
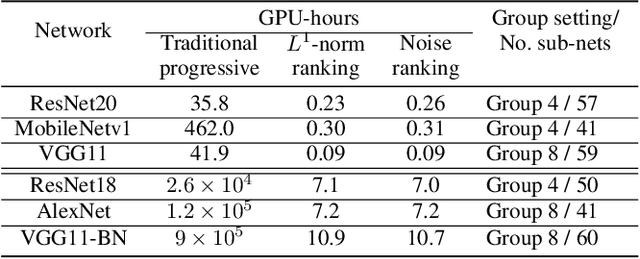
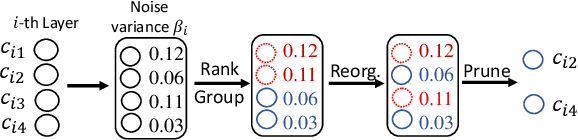
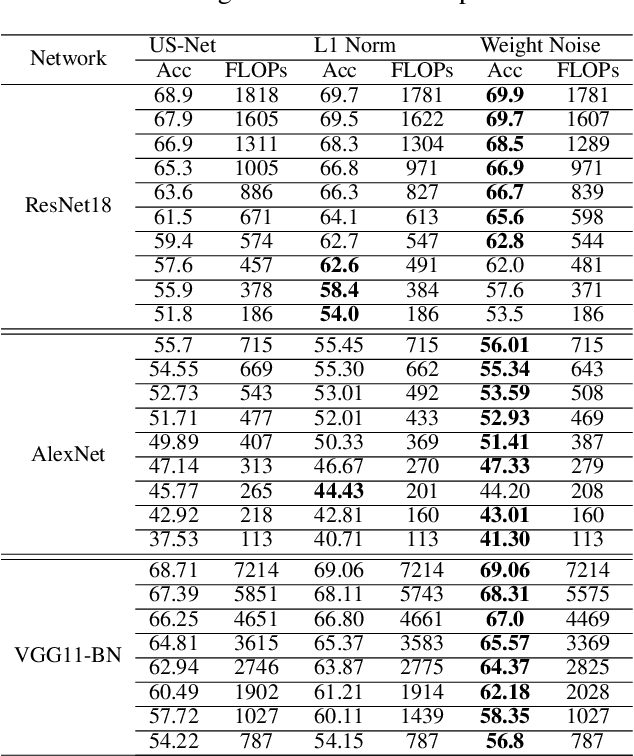
Many techniques have been developed, such as model compression, to make Deep Neural Networks (DNNs) inference more efficiently. Nevertheless, DNNs still lack excellent run-time dynamic inference capability to enable users trade-off accuracy and computation complexity (i.e., latency on target hardware) after model deployment, based on dynamic requirements and environments. Such research direction recently draws great attention, where one realization is to train the target DNN through a multiple-term objective function, which consists of cross-entropy terms from multiple sub-nets. Our investigation in this work show that the performance of dynamic inference highly relies on the quality of sub-net sampling. With objective to construct a dynamic DNN and search multiple high quality sub-nets with minimal searching cost, we propose a progressive sub-net searching framework, which is embedded with several effective techniques, including trainable noise ranking, channel group and fine-tuning threshold setting, sub-nets re-selection. The proposed framework empowers the target DNN with better dynamic inference capability, which outperforms prior works on both CIFAR-10 and ImageNet dataset via comprehensive experiments on different network structures. Taken ResNet18 as an example, our proposed method achieves much better dynamic inference accuracy compared with prior popular Universally-Slimmable-Network by 4.4%-maximally and 2.3%-averagely in ImageNet dataset with the same model size.
KSM: Fast Multiple Task Adaption via Kernel-wise Soft Mask Learning
Sep 11, 2020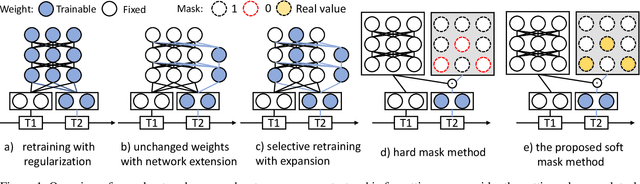

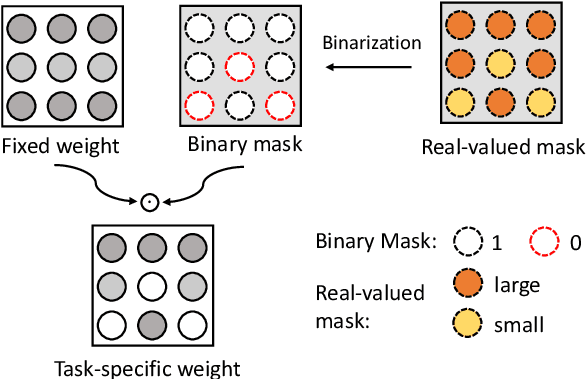
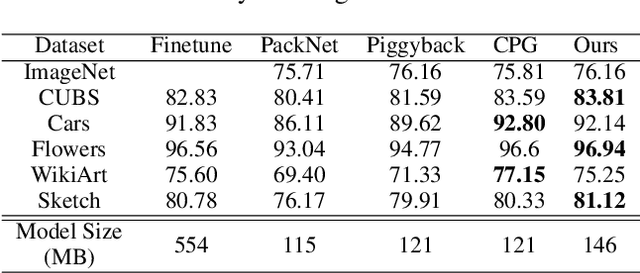
Deep Neural Networks (DNN) could forget the knowledge about earlier tasks when learning new tasks, and this is known as \textit{catastrophic forgetting}. While recent continual learning methods are capable of alleviating the catastrophic problem on toy-sized datasets, some issues still remain to be tackled when applying them in real-world problems. Recently, the fast mask-based learning method (e.g. piggyback \cite{mallya2018piggyback}) is proposed to address these issues by learning only a binary element-wise mask in a fast manner, while keeping the backbone model fixed. However, the binary mask has limited modeling capacity for new tasks. A more recent work \cite{hung2019compacting} proposes a compress-grow-based method (CPG) to achieve better accuracy for new tasks by partially training backbone model, but with order-higher training cost, which makes it infeasible to be deployed into popular state-of-the-art edge-/mobile-learning. The primary goal of this work is to simultaneously achieve fast and high-accuracy multi task adaption in continual learning setting. Thus motivated, we propose a new training method called \textit{kernel-wise Soft Mask} (KSM), which learns a kernel-wise hybrid binary and real-value soft mask for each task, while using the same backbone model. Such a soft mask can be viewed as a superposition of a binary mask and a properly scaled real-value tensor, which offers a richer representation capability without low-level kernel support to meet the objective of low hardware overhead. We validate KSM on multiple benchmark datasets against recent state-of-the-art methods (e.g. Piggyback, Packnet, CPG, etc.), which shows good improvement in both accuracy and training cost.