 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinding Missing Children: Aging Deep Face Features
Nov 19, 2019



Given a gallery of face images of missing children, state-of-the-art face recognition systems fall short in identifying a child (probe) recovered at a later age. We propose an age-progression module that can age-progress deep face features output by any commodity face matcher. For time lapses larger than 10 years (the missing child is found after 10 or more years), the proposed age-progression module improves the closed-set identification accuracy of FaceNet from 40% to 49.56% and CosFace from 56.88% to 61.25% on a child celebrity dataset, namely ITWCC. The proposed method also outperforms state-of-the-art approaches with a rank-1 identification rate from 94.91% to 95.91% on a public aging dataset, FG-NET, and from 99.50% to 99.58% on CACD-VS. These results suggest that aging face features enhances the ability to identify young children who are possible victims of child trafficking or abduction.
Adversarial Attacks and Defenses in Images, Graphs and Text: A Review
Oct 09, 2019
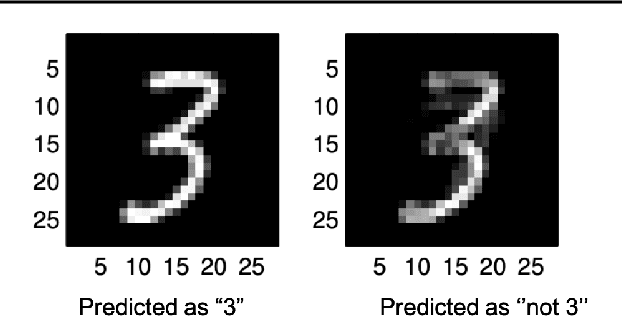

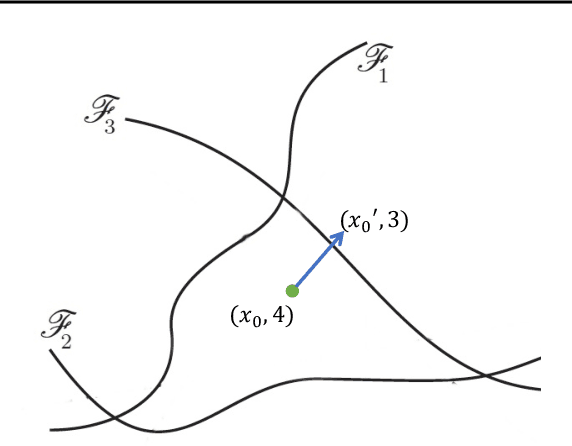
Deep neural networks (DNN) have achieved unprecedented success in numerous machine learning tasks in various domains. However, the existence of adversarial examples has raised concerns about applying deep learning to safety-critical applications. As a result, we have witnessed increasing interests in studying attack and defense mechanisms for DNN models on different data types, such as images, graphs and text. Thus, it is necessary to provide a systematic and comprehensive overview of the main threats of attacks and the success of corresponding countermeasures. In this survey, we review the state of the art algorithms for generating adversarial examples and the countermeasures against adversarial examples, for the three popular data types, i.e., images, graphs and text.
AdvFaces: Adversarial Face Synthesis
Aug 14, 2019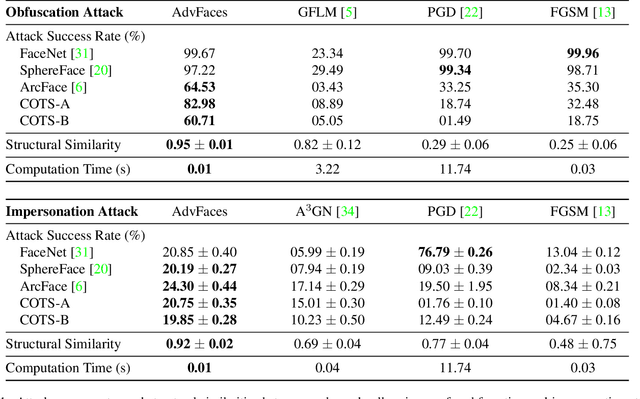

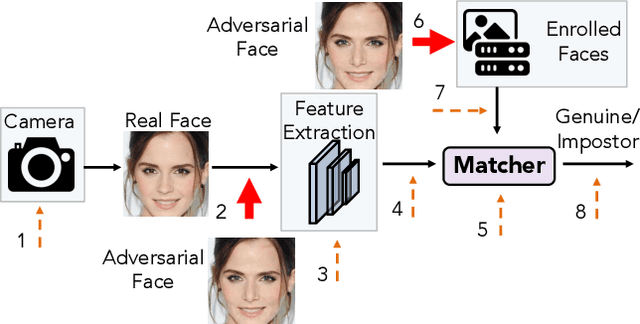
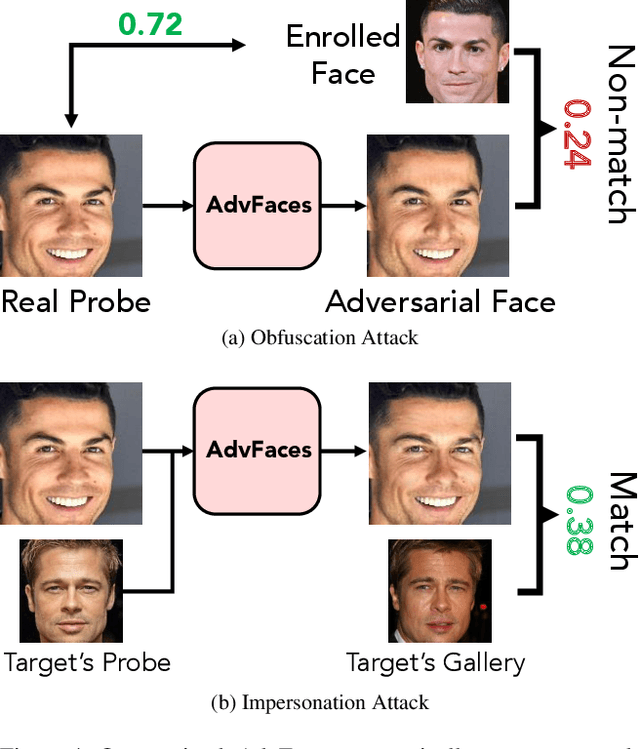
Face recognition systems have been shown to be vulnerable to adversarial examples resulting from adding small perturbations to probe images. Such adversarial images can lead state-of-the-art face recognition systems to falsely reject a genuine subject (obfuscation attack) or falsely match to an impostor (impersonation attack). Current approaches to crafting adversarial face images lack perceptual quality and take an unreasonable amount of time to generate them. We propose, AdvFaces, an automated adversarial face synthesis method that learns to generate minimal perturbations in the salient facial regions via Generative Adversarial Networks. Once AdvFaces is trained, it can automatically generate imperceptible perturbations that can evade state-of-the-art face matchers with attack success rates as high as 97.22% and 24.30% for obfuscation and impersonation attacks, respectively.
Infant-Prints: Fingerprints for Reducing Infant Mortality
Apr 01, 2019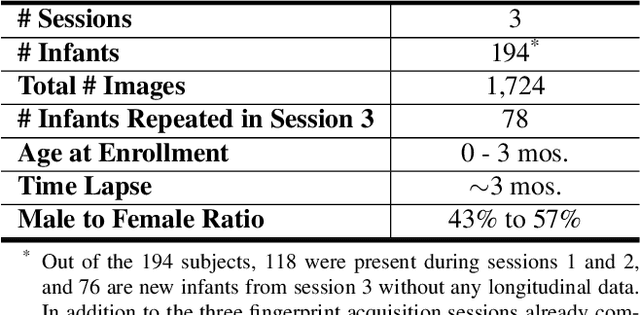


In developing countries around the world, a multitude of infants continue to suffer and die from vaccine-preventable diseases, and malnutrition. Lamentably, the lack of any official identification documentation makes it exceedingly difficult to prevent these infant deaths. To solve this global crisis, we propose Infant-Prints which is comprised of (i) a custom, compact, low-cost (85 USD), high-resolution (1,900 ppi) fingerprint reader, (ii) a high-resolution fingerprint matcher, and (iii) a mobile application for search and verification for the infant fingerprint. Using Infant-Prints, we have collected a longitudinal database of infant fingerprints and demonstrate its ability to perform accurate and reliable recognition of infants enrolled at the ages 0-3 months, in time for effective delivery of critical vaccinations and nutritional supplements (TAR=90% @ FAR = 0.1% for infants older than 8 weeks).
Actions Speak Louder Than (Pass)words: Passive Authentication of Smartphone Users via Deep Temporal Features
Jan 16, 2019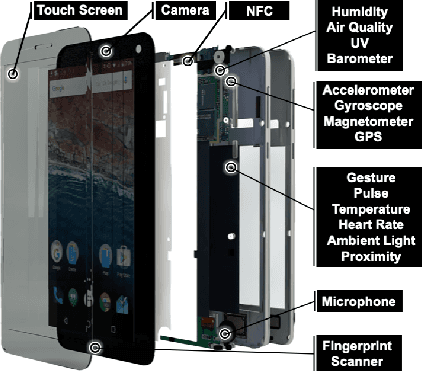
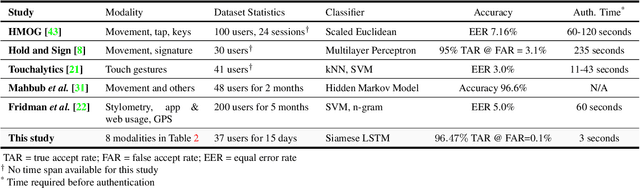

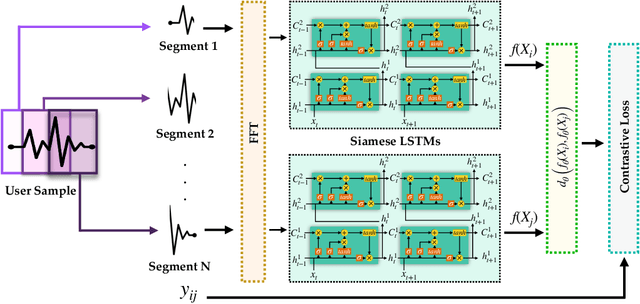
Prevailing user authentication schemes on smartphones rely on explicit user interaction, where a user types in a passcode or presents a biometric cue such as face, fingerprint, or iris. In addition to being cumbersome and obtrusive to the users, such authentication mechanisms pose security and privacy concerns. Passive authentication systems can tackle these challenges by frequently and unobtrusively monitoring the user's interaction with the device. In this paper, we propose a Siamese Long Short-Term Memory network architecture for passive authentication, where users can be verified without requiring any explicit authentication step. We acquired a dataset comprising of measurements from 30 smartphone sensor modalities for 37 users. We evaluate our approach on 8 dominant modalities, namely, keystroke dynamics, GPS location, accelerometer, gyroscope, magnetometer, linear accelerometer, gravity, and rotation sensors. Experimental results find that, within 3 seconds, a genuine user can be correctly verified 97.15% of the time at a false accept rate of 0.1%.
WarpGAN: Automatic Caricature Generation
Nov 28, 2018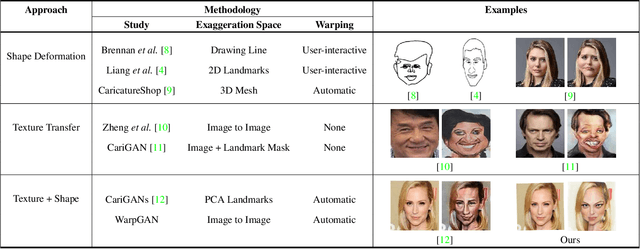
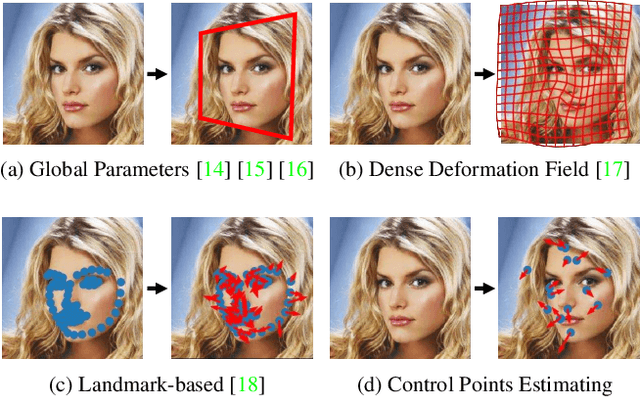
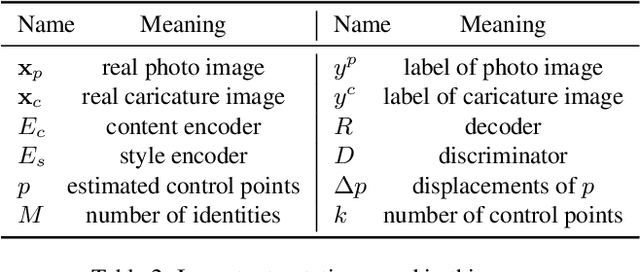
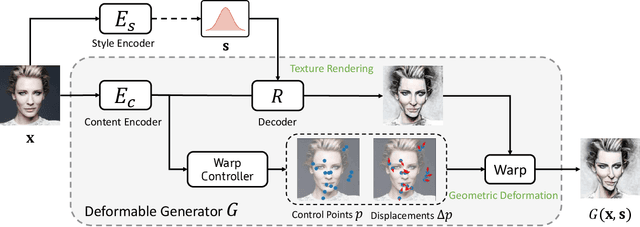
We propose, WarpGAN, a fully automatic network that can generate caricatures given an input face photo. Besides transferring rich texture styles, WarpGAN learns to automatically predict a set of control points that can warp the photo into a caricature, while preserving identity. We introduce an identity-preserving adversarial loss that aids the discriminator to distinguish between different subjects. Moreover, WarpGAN allows customization of the generated caricatures by controlling the exaggeration extent and the visual styles. Experimental results on a public domain dataset, WebCaricature, show that WarpGAN is capable of generating a diverse set of caricatures while preserving the identities. Five caricature experts suggest that caricatures generated by WarpGAN are visually similar to hand-drawn ones and only prominent facial features are exaggerated.
Altered Fingerprints: Detection and Localization
Sep 18, 2018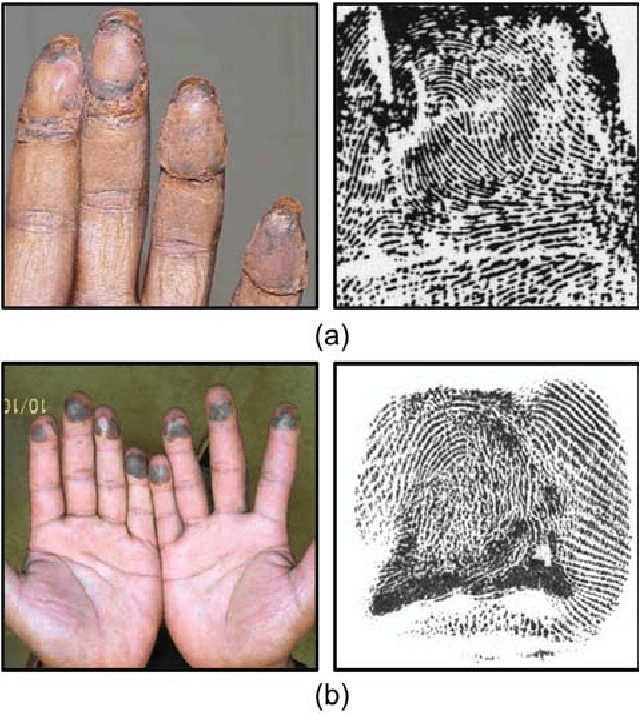
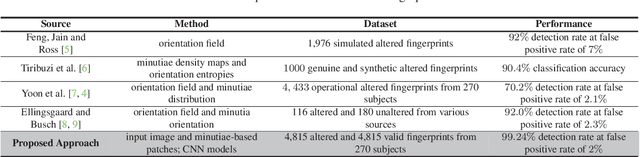
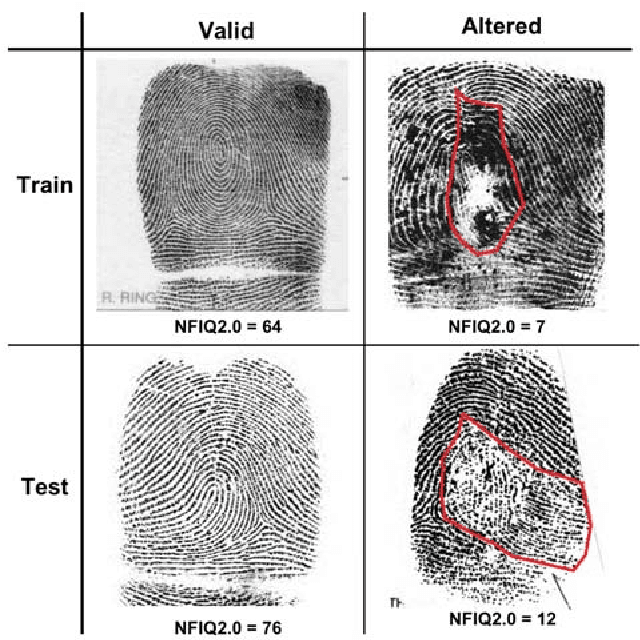
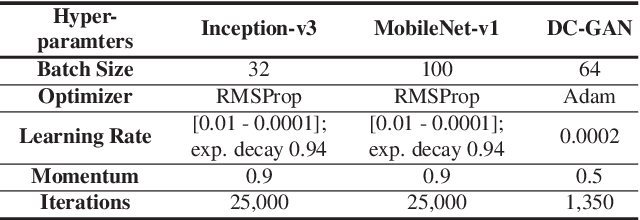
Fingerprint alteration, also referred to as obfuscation presentation attack, is to intentionally tamper or damage the real friction ridge patterns to avoid identification by an AFIS. This paper proposes a method for detection and localization of fingerprint alterations. Our main contributions are: (i) design and train CNN models on fingerprint images and minutiae-centered local patches in the image to detect and localize regions of fingerprint alterations, and (ii) train a Generative Adversarial Network (GAN) to synthesize altered fingerprints whose characteristics are similar to true altered fingerprints. A successfully trained GAN can alleviate the limited availability of altered fingerprint images for research. A database of 4,815 altered fingerprints from 270 subjects, and an equal number of rolled fingerprint images are used to train and test our models. The proposed approach achieves a True Detection Rate (TDR) of 99.24% at a False Detection Rate (FDR) of 2%, outperforming published results. The synthetically generated altered fingerprint dataset will be open-sourced.
Face Recognition: Primates in the Wild
Apr 24, 2018
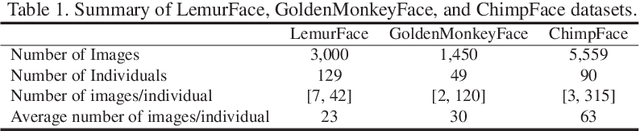


We present a new method of primate face recognition, and evaluate this method on several endangered primates, including golden monkeys, lemurs, and chimpanzees. The three datasets contain a total of 11,637 images of 280 individual primates from 14 species. Primate face recognition performance is evaluated using two existing state-of-the-art open-source systems, (i) FaceNet and (ii) SphereFace, (iii) a lemur face recognition system from literature, and (iv) our new convolutional neural network (CNN) architecture called PrimNet. Three recognition scenarios are considered: verification (1:1 comparison), and both open-set and closed-set identification (1:N search). We demonstrate that PrimNet outperforms all of the other systems in all three scenarios for all primate species tested. Finally, we implement an Android application of this recognition system to assist primate researchers and conservationists in the wild for individual recognition of primates.
Matching Fingerphotos to Slap Fingerprint Images
Apr 22, 2018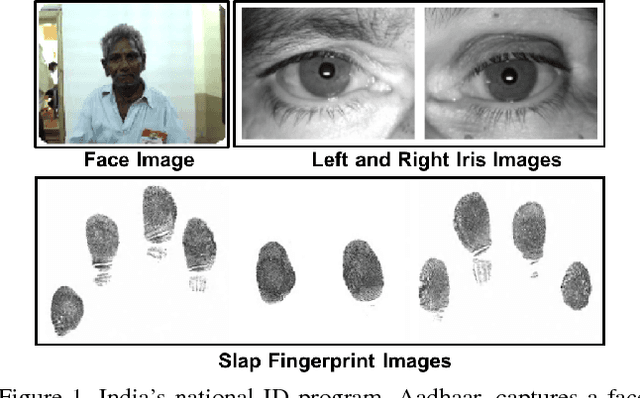

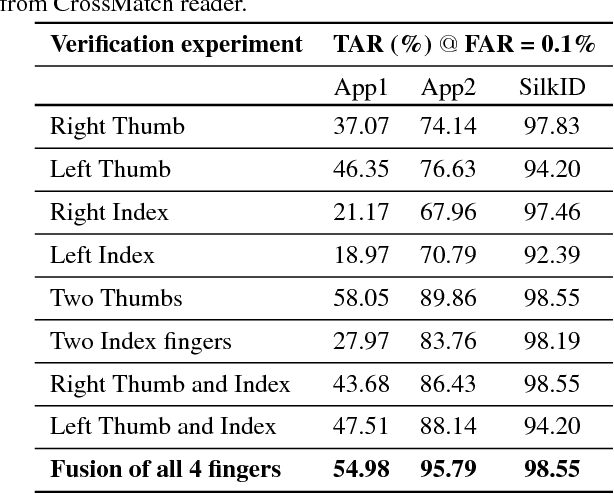
We address the problem of comparing fingerphotos, fingerprint images from a commodity smartphone camera, with the corresponding legacy slap contact-based fingerprint images. Development of robust versions of these technologies would enable the use of the billions of standard Android phones as biometric readers through a simple software download, dramatically lowering the cost and complexity of deployment relative to using a separate fingerprint reader. Two fingerphoto apps running on Android phones and an optical slap reader were utilized for fingerprint collection of 309 subjects who primarily work as construction workers, farmers, and domestic helpers. Experimental results show that a True Accept Rate (TAR) of 95.79 at a False Accept Rate (FAR) of 0.1% can be achieved in matching fingerphotos to slaps (two thumbs and two index fingers) using a COTS fingerprint matcher. By comparison, a baseline TAR of 98.55% at 0.1% FAR is achieved when matching fingerprint images from two different contact-based optical readers. We also report the usability of the two smartphone apps, in terms of failure to acquire rate and fingerprint acquisition time. Our results show that fingerphotos are promising to authenticate individuals (against a national ID database) for banking, welfare distribution, and healthcare applications in developing countries.
Longitudinal Study of Child Face Recognition
Nov 10, 2017
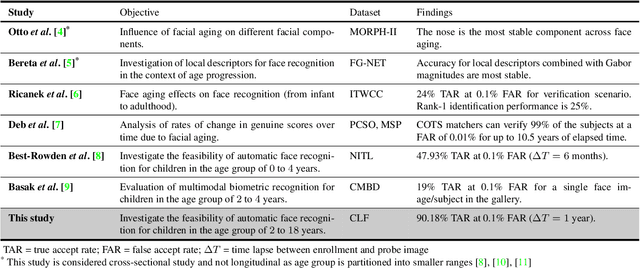

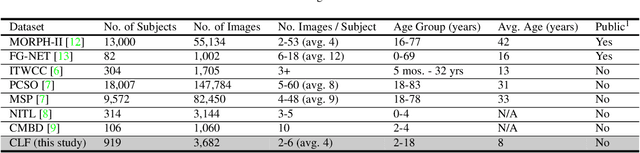
We present a longitudinal study of face recognition performance on Children Longitudinal Face (CLF) dataset containing 3,682 face images of 919 subjects, in the age group [2, 18] years. Each subject has at least four face images acquired over a time span of up to six years. Face comparison scores are obtained from (i) a state-of-the-art COTS matcher (COTS-A), (ii) an open-source matcher (FaceNet), and (iii) a simple sum fusion of scores obtained from COTS-A and FaceNet matchers. To improve the performance of the open-source FaceNet matcher for child face recognition, we were able to fine-tune it on an independent training set of 3,294 face images of 1,119 children in the age group [3, 18] years. Multilevel statistical models are fit to genuine comparison scores from the CLF dataset to determine the decrease in face recognition accuracy over time. Additionally, we analyze both the verification and open-set identification accuracies in order to evaluate state-of-the-art face recognition technology for tracing and identifying children lost at a young age as victims of child trafficking or abduction.