 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLinear Convergence of Reshuffling Kaczmarz Methods With Sparse Constraints
Apr 20, 2023



The Kaczmarz method (KZ) and its variants, which are types of stochastic gradient descent (SGD) methods, have been extensively studied due to their simplicity and efficiency in solving linear equation systems. The iterative thresholding (IHT) method has gained popularity in various research fields, including compressed sensing or sparse linear regression, machine learning with additional structure, and optimization with nonconvex constraints. Recently, a hybrid method called Kaczmarz-based IHT (KZIHT) has been proposed, combining the benefits of both approaches, but its theoretical guarantees are missing. In this paper, we provide the first theoretical convergence guarantees for KZIHT by showing that it converges linearly to the solution of a system with sparsity constraints up to optimal statistical bias when the reshuffling data sampling scheme is used. We also propose the Kaczmarz with periodic thresholding (KZPT) method, which generalizes KZIHT by applying the thresholding operation for every certain number of KZ iterations and by employing two different types of step sizes. We establish a linear convergence guarantee for KZPT for randomly subsampled bounded orthonormal systems (BOS) and mean-zero isotropic sub-Gaussian random matrices, which are most commonly used models in compressed sensing, dimension reduction, matrix sketching, and many inverse problems in neural networks. Our analysis shows that KZPT with an optimal thresholding period outperforms KZIHT. To support our theory, we include several numerical experiments.
One-Bit Quadratic Compressed Sensing: From Sample Abundance to Linear Feasibility
Mar 16, 2023



One-bit quantization with time-varying sampling thresholds has recently found significant utilization potential in statistical signal processing applications due to its relatively low power consumption and low implementation cost. In addition to such advantages, an attractive feature of one-bit analog-to-digital converters (ADCs) is their superior sampling rates as compared to their conventional multi-bit counterparts. This characteristic endows one-bit signal processing frameworks with what we refer to as sample abundance. On the other hand, many signal recovery and optimization problems are formulated as (possibly non-convex) quadratic programs with linear feasibility constraints in the one-bit sampling regime. We demonstrate, with a particular focus on quadratic compressed sensing, that the sample abundance paradigm allows for the transformation of such quadratic problems to merely a linear feasibility problem by forming a large-scale overdetermined linear system; thus removing the need for costly optimization constraints and objectives. To efficiently tackle the emerging overdetermined linear feasibility problem, we further propose an enhanced randomized Kaczmarz algorithm, called Block SKM. Several numerical results are presented to illustrate the effectiveness of the proposed methodologies.
Neural Nonnegative Matrix Factorization for Hierarchical Multilayer Topic Modeling
Feb 28, 2023We introduce a new method based on nonnegative matrix factorization, Neural NMF, for detecting latent hierarchical structure in data. Datasets with hierarchical structure arise in a wide variety of fields, such as document classification, image processing, and bioinformatics. Neural NMF recursively applies NMF in layers to discover overarching topics encompassing the lower-level features. We derive a backpropagation optimization scheme that allows us to frame hierarchical NMF as a neural network. We test Neural NMF on a synthetic hierarchical dataset, the 20 Newsgroups dataset, and the MyLymeData symptoms dataset. Numerical results demonstrate that Neural NMF outperforms other hierarchical NMF methods on these data sets and offers better learned hierarchical structure and interpretability of topics.
Distributed Randomized Kaczmarz for the Adversarial Workers
Feb 24, 2023Developing large-scale distributed methods that are robust to the presence of adversarial or corrupted workers is an important part of making such methods practical for real-world problems. In this paper, we propose an iterative approach that is adversary-tolerant for convex optimization problems. By leveraging simple statistics, our method ensures convergence and is capable of adapting to adversarial distributions. Additionally, the efficiency of the proposed methods for solving convex problems is shown in simulations with the presence of adversaries. Through simulations, we demonstrate the efficiency of our approach in the presence of adversaries and its ability to identify adversarial workers with high accuracy and tolerate varying levels of adversary rates.
Federated Gradient Matching Pursuit
Feb 20, 2023



Traditional machine learning techniques require centralizing all training data on one server or data hub. Due to the development of communication technologies and a huge amount of decentralized data on many clients, collaborative machine learning has become the main interest while providing privacy-preserving frameworks. In particular, federated learning (FL) provides such a solution to learn a shared model while keeping training data at local clients. On the other hand, in a wide range of machine learning and signal processing applications, the desired solution naturally has a certain structure that can be framed as sparsity with respect to a certain dictionary. This problem can be formulated as an optimization problem with sparsity constraints and solving it efficiently has been one of the primary research topics in the traditional centralized setting. In this paper, we propose a novel algorithmic framework, federated gradient matching pursuit (FedGradMP), to solve the sparsity constrained minimization problem in the FL setting. We also generalize our algorithms to accommodate various practical FL scenarios when only a subset of clients participate per round, when the local model estimation at clients could be inexact, or when the model parameters are sparse with respect to general dictionaries. Our theoretical analysis shows the linear convergence of the proposed algorithms. A variety of numerical experiments are conducted to demonstrate the great potential of the proposed framework -- fast convergence both in communication rounds and computation time for many important scenarios without sophisticated parameter tuning.
A Convergence Rate for Manifold Neural Networks
Dec 23, 2022High-dimensional data arises in numerous applications, and the rapidly developing field of geometric deep learning seeks to develop neural network architectures to analyze such data in non-Euclidean domains, such as graphs and manifolds. Recent work by Z. Wang, L. Ruiz, and A. Ribeiro has introduced a method for constructing manifold neural networks using the spectral decomposition of the Laplace Beltrami operator. Moreover, in this work, the authors provide a numerical scheme for implementing such neural networks when the manifold is unknown and one only has access to finitely many sample points. The authors show that this scheme, which relies upon building a data-driven graph, converges to the continuum limit as the number of sample points tends to infinity. Here, we build upon this result by establishing a rate of convergence that depends on the intrinsic dimension of the manifold but is independent of the ambient dimension. We also discuss how the rate of convergence depends on the depth of the network and the number of filters used in each layer.
Continuous Semi-Supervised Nonnegative Matrix Factorization
Dec 19, 2022



Nonnegative matrix factorization can be used to automatically detect topics within a corpus in an unsupervised fashion. The technique amounts to an approximation of a nonnegative matrix as the product of two nonnegative matrices of lower rank. In this paper, we show this factorization can be combined with regression on a continuous response variable. In practice, the method performs better than regression done after topics are identified and retrains interpretability.
Inference of Media Bias and Content Quality Using Natural-Language Processing
Dec 01, 2022Media bias can significantly impact the formation and development of opinions and sentiments in a population. It is thus important to study the emergence and development of partisan media and political polarization. However, it is challenging to quantitatively infer the ideological positions of media outlets. In this paper, we present a quantitative framework to infer both political bias and content quality of media outlets from text, and we illustrate this framework with empirical experiments with real-world data. We apply a bidirectional long short-term memory (LSTM) neural network to a data set of more than 1 million tweets to generate a two-dimensional ideological-bias and content-quality measurement for each tweet. We then infer a ``media-bias chart'' of (bias, quality) coordinates for the media outlets by integrating the (bias, quality) measurements of the tweets of the media outlets. We also apply a variety of baseline machine-learning methods, such as a naive-Bayes method and a support-vector machine (SVM), to infer the bias and quality values for each tweet. All of these baseline approaches are based on a bag-of-words approach. We find that the LSTM-network approach has the best performance of the examined methods. Our results illustrate the importance of leveraging word order into machine-learning methods in text analysis.
Sketched Gaussian Model Linear Discriminant Analysis via the Randomized Kaczmarz Method
Nov 10, 2022



We present sketched linear discriminant analysis, an iterative randomized approach to binary-class Gaussian model linear discriminant analysis (LDA) for very large data. We harness a least squares formulation and mobilize the stochastic gradient descent framework. Therefore, we obtain a randomized classifier with performance that is very comparable to that of full data LDA while requiring access to only one row of the training data at a time. We present convergence guarantees for the sketched predictions on new data within a fixed number of iterations. These guarantees account for both the Gaussian modeling assumptions on the data and algorithmic randomness from the sketching procedure. Finally, we demonstrate performance with varying step-sizes and numbers of iterations. Our numerical experiments demonstrate that sketched LDA can offer a very viable alternative to full data LDA when the data may be too large for full data analysis.
Matrix Completion with Cross-Concentrated Sampling: Bridging Uniform Sampling and CUR Sampling
Aug 20, 2022
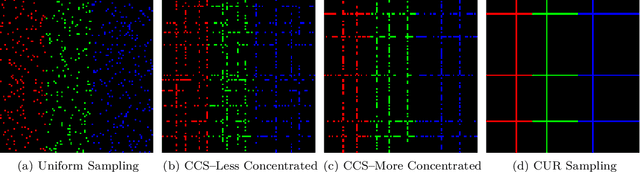

While uniform sampling has been widely studied in the matrix completion literature, CUR sampling approximates a low-rank matrix via row and column samples. Unfortunately, both sampling models lack flexibility for various circumstances in real-world applications. In this work, we propose a novel and easy-to-implement sampling strategy, coined Cross-Concentrated Sampling (CCS). By bridging uniform sampling and CUR sampling, CCS provides extra flexibility that can potentially save sampling costs in applications. In addition, we also provide a sufficient condition for CCS-based matrix completion. Moreover, we propose a highly efficient non-convex algorithm, termed Iterative CUR Completion (ICURC), for the proposed CCS model. Numerical experiments verify the empirical advantages of CCS and ICURC against uniform sampling and its baseline algorithms, on both synthetic and real-world datasets.