 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-attending RNN for Speech Enhancement to Improve Cross-corpus Generalization
May 26, 2021
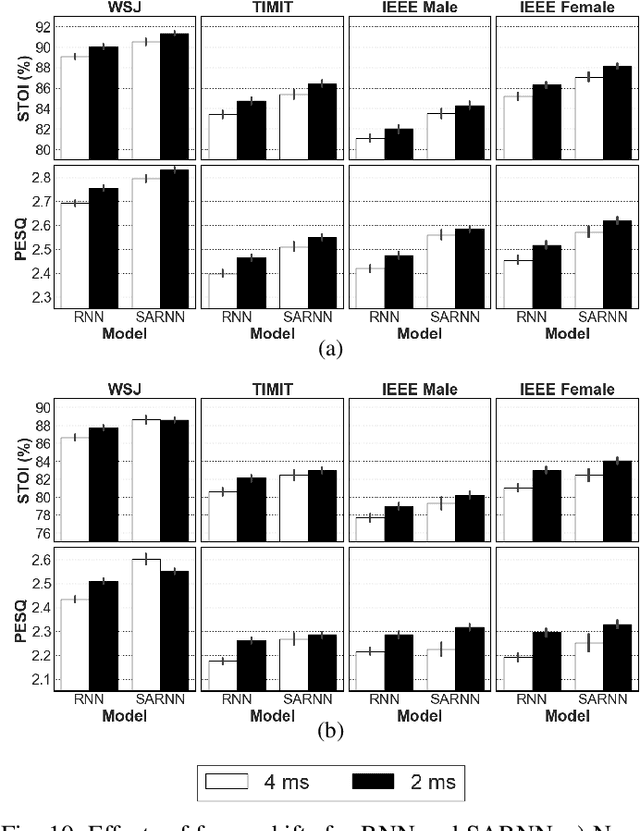
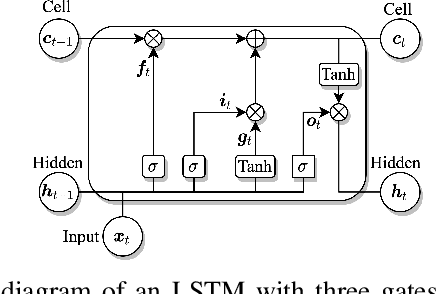
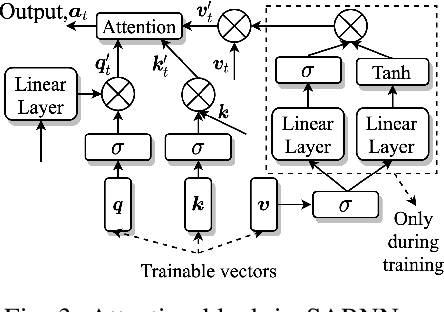
Deep neural networks (DNNs) represent the mainstream methodology for supervised speech enhancement, primarily due to their capability to model complex functions using hierarchical representations. However, a recent study revealed that DNNs trained on a single corpus fail to generalize to untrained corpora, especially in low signal-to-noise ratio (SNR) conditions. Developing a noise, speaker, and corpus independent speech enhancement algorithm is essential for real-world applications. In this study, we propose a self-attending recurrent neural network(SARNN) for time-domain speech enhancement to improve cross-corpus generalization. SARNN comprises of recurrent neural networks (RNNs) augmented with self-attention blocks and feedforward blocks. We evaluate SARNN on different corpora with nonstationary noises in low SNR conditions. Experimental results demonstrate that SARNN substantially outperforms competitive approaches to time-domain speech enhancement, such as RNNs and dual-path SARNNs. Additionally, we report an important finding that the two popular approaches to speech enhancement: complex spectral mapping and time-domain enhancement, obtain similar results for RNN and SARNN with large-scale training. We also provide a challenging subset of the test set used in this study for evaluating future algorithms and facilitating direct comparisons.
Multi-Channel and Multi-Microphone Acoustic Echo Cancellation Using A Deep Learning Based Approach
Mar 03, 2021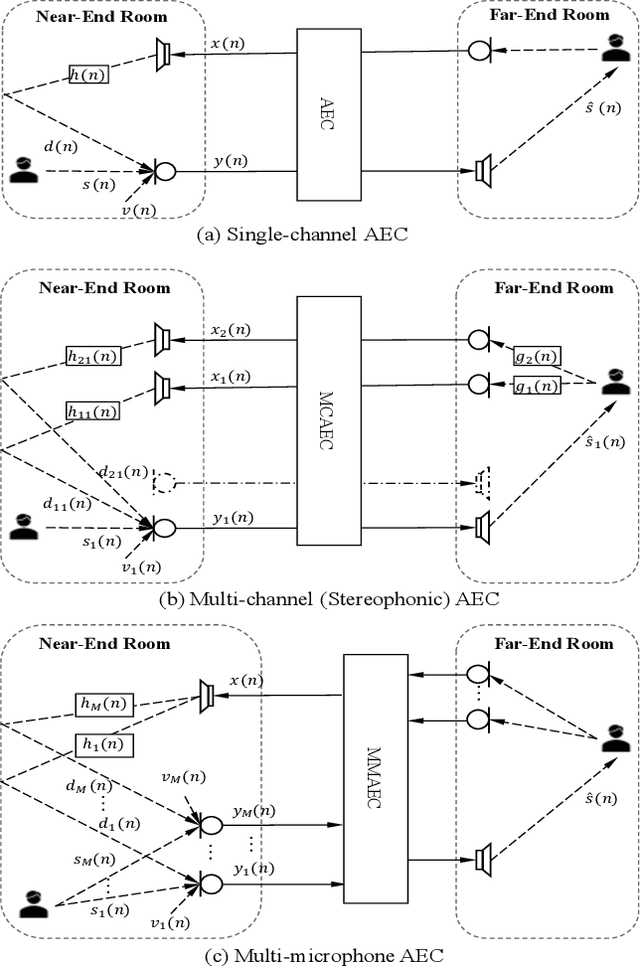
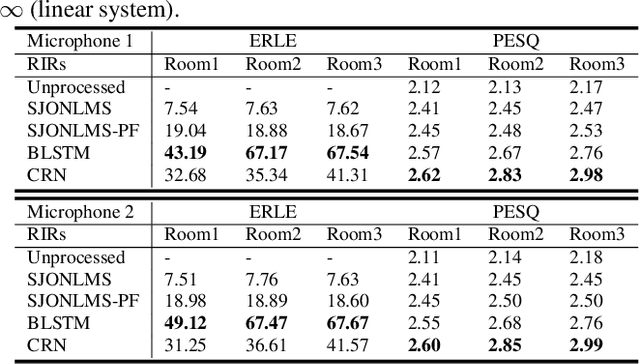
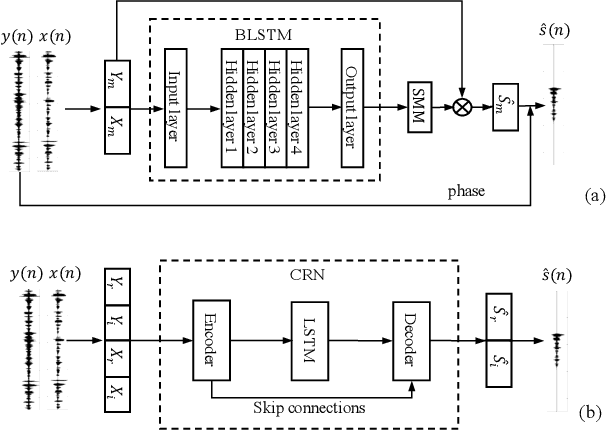
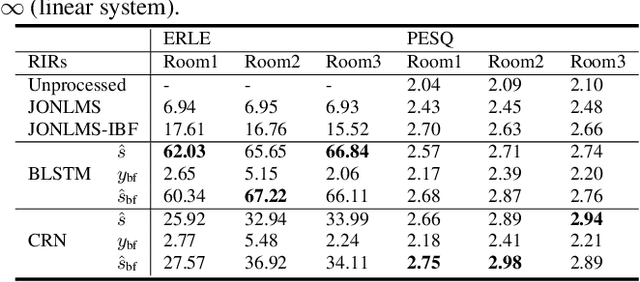
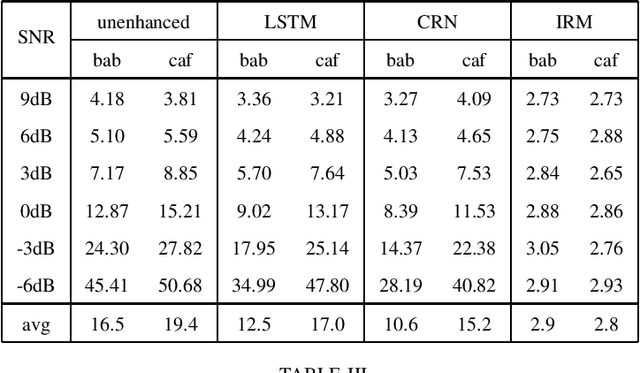
Building on the deep learning based acoustic echo cancellation (AEC) in the single-loudspeaker (single-channel) and single-microphone setup, this paper investigates multi-channel AEC (MCAEC) and multi-microphone AEC (MMAEC). We train a deep neural network (DNN) to predict the near-end speech from microphone signals with far-end signals used as additional information. We find that the deep learning approach avoids the non-uniqueness problem in traditional MCAEC algorithms. For the AEC setup with multiple microphones, rather than employing AEC for each microphone, a single DNN is trained to achieve echo removal for all microphones. Also, combining deep learning based AEC with deep learning based beamforming further improves the system performance. Experimental results show the effectiveness of both bidirectional long short-term memory (BLSTM) and convolutional recurrent network (CRN) based methods for MCAEC and MMAEC. Furthermore, deep learning based methods are capable of removing echo and noise simultaneously and work well in the presence of nonlinear distortions.
Efficient End-to-End Speech Recognition Using Performers in Conformers
Nov 11, 2020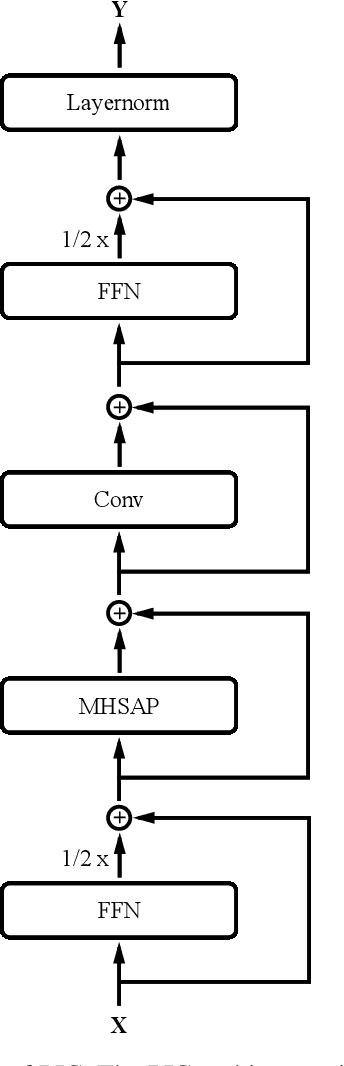
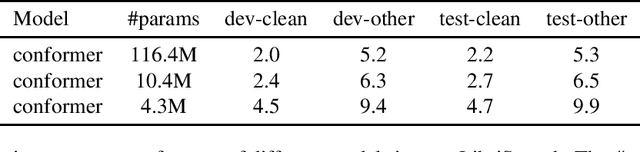

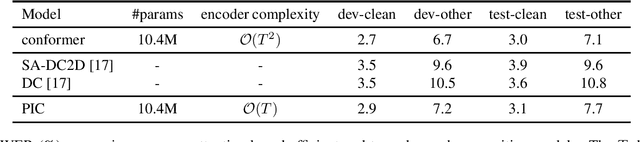
On-device end-to-end speech recognition poses a high requirement on model efficiency. Most prior works improve the efficiency by reducing model sizes. We propose to reduce the complexity of model architectures in addition to model sizes. More specifically, we reduce the floating-point operations in conformer by replacing the transformer module with a performer. The proposed attention-based efficient end-to-end speech recognition model yields competitive performance on the LibriSpeech corpus with 10 millions of parameters and linear computation complexity. The proposed model also outperforms previous lightweight end-to-end models by about 20% relatively in word error rate.
Speaker Separation Using Speaker Inventories and Estimated Speech
Oct 20, 2020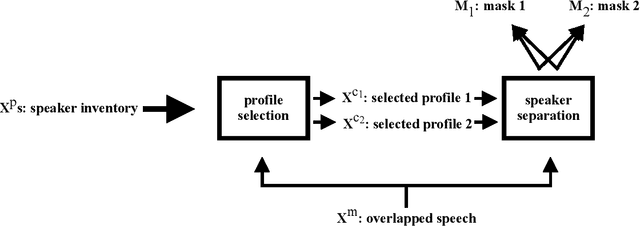
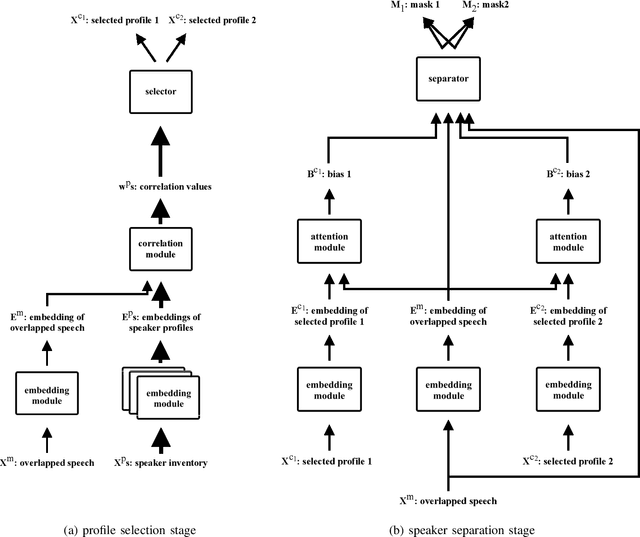
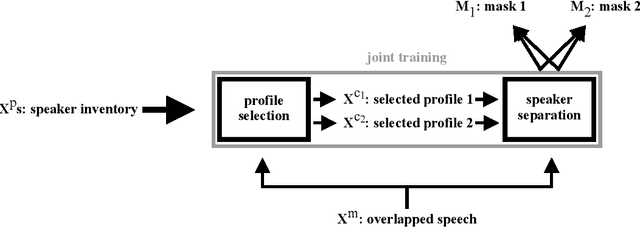
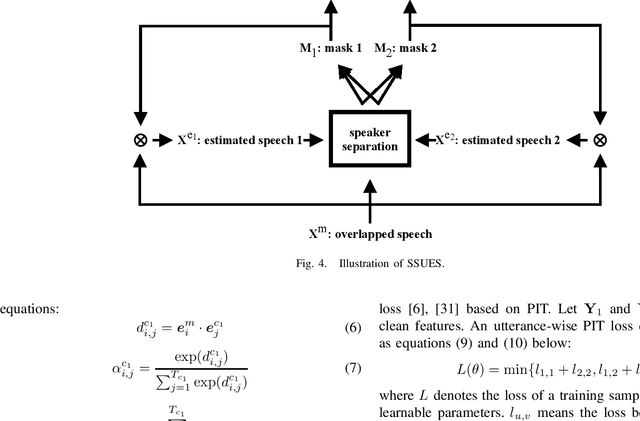
We propose speaker separation using speaker inventories and estimated speech (SSUSIES), a framework leveraging speaker profiles and estimated speech for speaker separation. SSUSIES contains two methods, speaker separation using speaker inventories (SSUSI) and speaker separation using estimated speech (SSUES). SSUSI performs speaker separation with the help of speaker inventory. By combining the advantages of permutation invariant training (PIT) and speech extraction, SSUSI significantly outperforms conventional approaches. SSUES is a widely applicable technique that can substantially improve speaker separation performance using the output of first-pass separation. We evaluate the models on both speaker separation and speech recognition metrics.
Multi-microphone Complex Spectral Mapping for Utterance-wise and Continuous Speaker Separation
Oct 04, 2020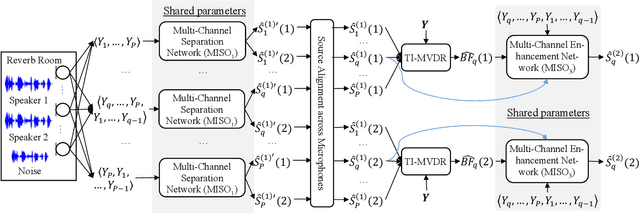
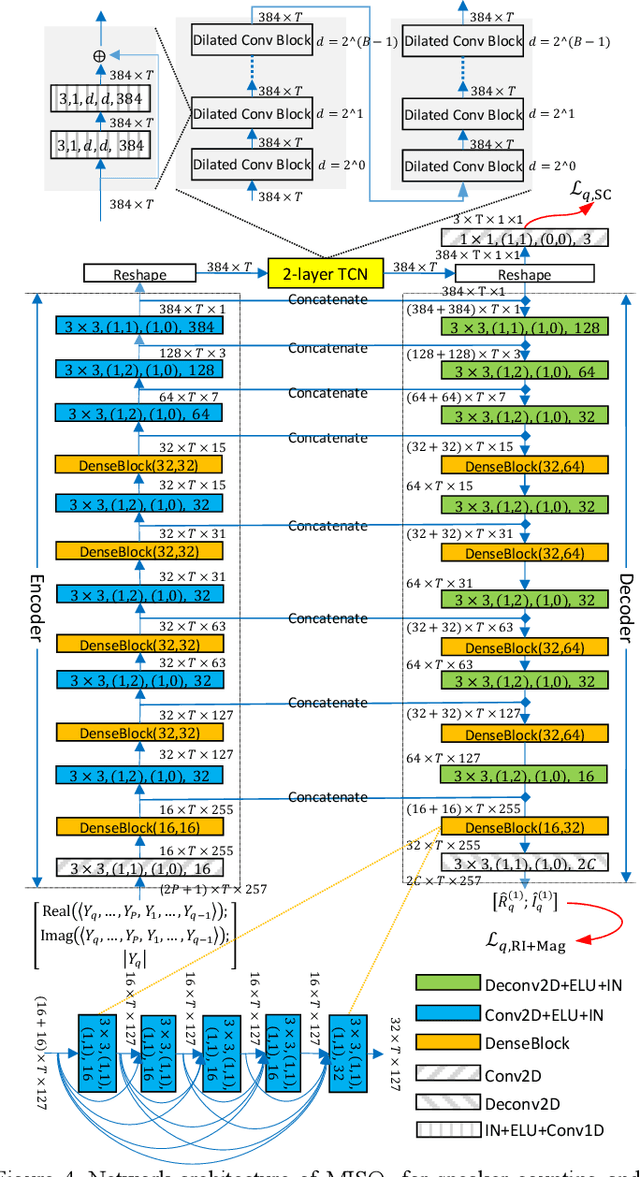
We propose multi-microphone complex spectral mapping, a simple way of applying deep learning for time-varying non-linear beamforming, for offline utterance-wise and block-online continuous speaker separation in reverberant conditions, aiming at both speaker separation and dereverberation. Assuming a fixed array geometry between training and testing, we train deep neural networks (DNN) to predict the real and imaginary (RI) components of target speech at a reference microphone from the RI components of multiple microphones. We then integrate multi-microphone complex spectral mapping with beamforming and post-filtering to further improve separation, and combine it with frame-level speaker counting for block-online continuous speaker separation (CSS). Although our system is trained on simulated room impulse responses (RIR) based on a fixed number of microphones arranged in a given geometry, it generalizes well to a real array with the same geometry. State-of-the-art separation performance is obtained on the simulated two-talker SMS-WSJ corpus and the real-recorded LibriCSS dataset.
Divide and Conquer: A Deep CASA Approach to Talker-independent Monaural Speaker Separation
Apr 25, 2019
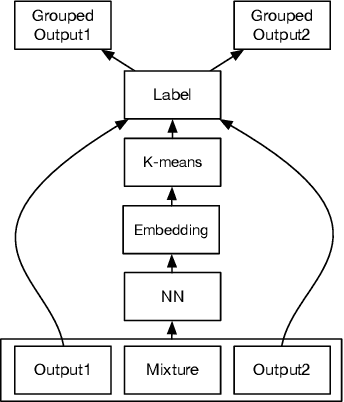
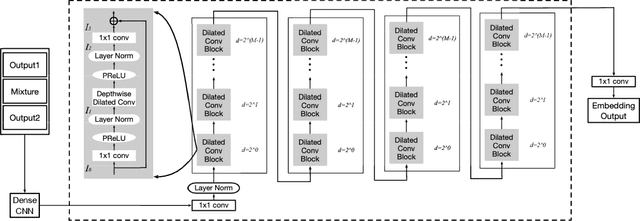
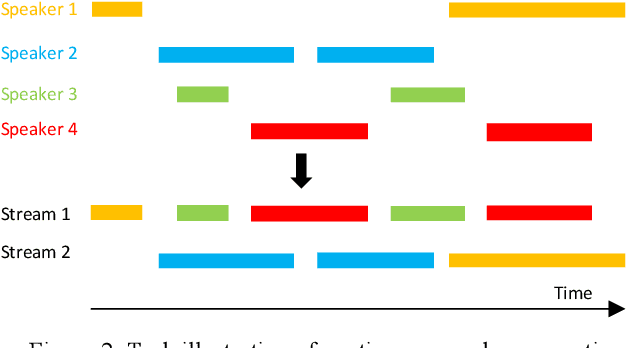
We address talker-independent monaural speaker separation from the perspectives of deep learning and computational auditory scene analysis (CASA). Specifically, we decompose the multi-speaker separation task into the stages of simultaneous grouping and sequential grouping. Simultaneous grouping is first performed in each time frame by separating the spectra of different speakers with a permutation-invariantly trained neural network. In the second stage, the frame-level separated spectra are sequentially grouped to different speakers by a clustering network. The proposed deep CASA approach optimizes frame-level separation and speaker tracking in turn, and produces excellent results for both objectives. Experimental results on the benchmark WSJ0-2mix database show that the new approach achieves the state-of-the-art results with a modest model size.
Bridging the Gap Between Monaural Speech Enhancement and Recognition with Distortion-Independent Acoustic Modeling
Mar 13, 2019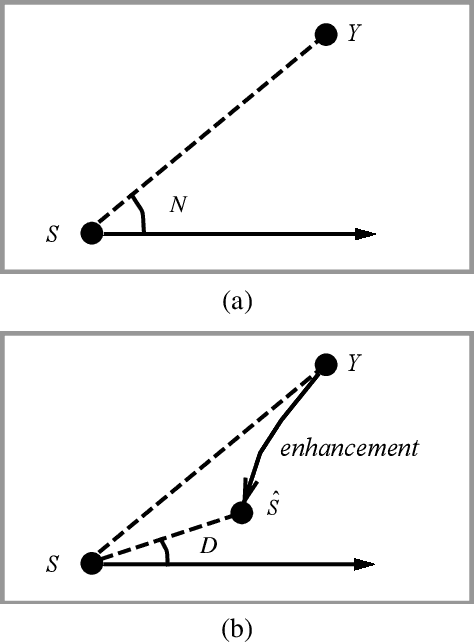
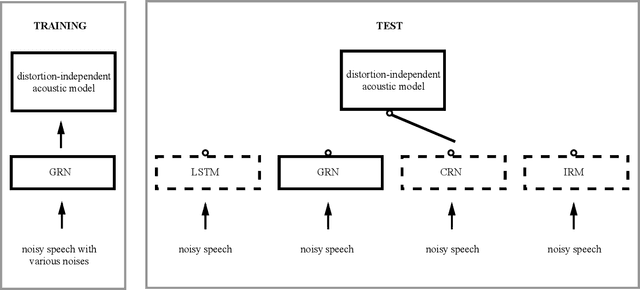
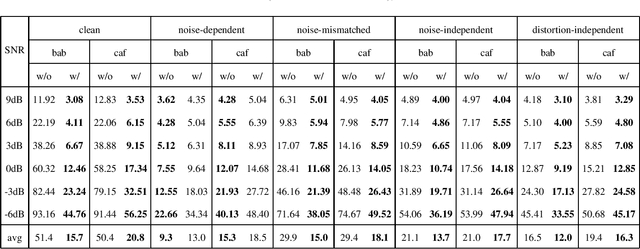
Monaural speech enhancement has made dramatic advances since the introduction of deep learning a few years ago. Although enhanced speech has been demonstrated to have better intelligibility and quality for human listeners, feeding it directly to automatic speech recognition (ASR) systems trained with noisy speech has not produced expected improvements in ASR performance. The lack of an enhancement benefit on recognition, or the gap between monaural speech enhancement and recognition, is often attributed to speech distortions introduced in the enhancement process. In this study, we analyze the distortion problem, compare different acoustic models, and investigate a distortion-independent training scheme for monaural speech recognition. Experimental results suggest that distortion-independent acoustic modeling is able to overcome the distortion problem. Such an acoustic model can also work with speech enhancement models different from the one used during training. Moreover, the models investigated in this paper outperform the previous best system on the CHiME-2 corpus.
Deep Learning Based Phase Reconstruction for Speaker Separation: A Trigonometric Perspective
Nov 22, 2018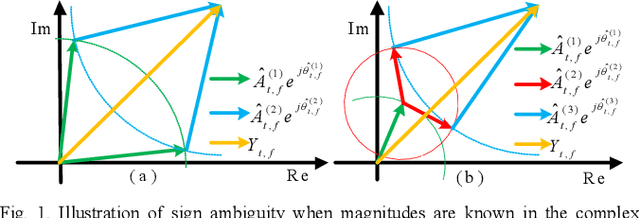
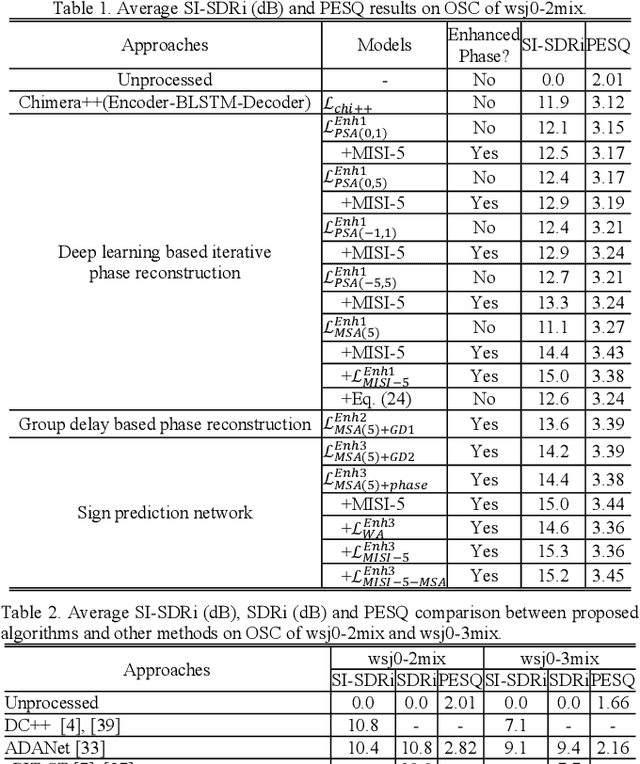
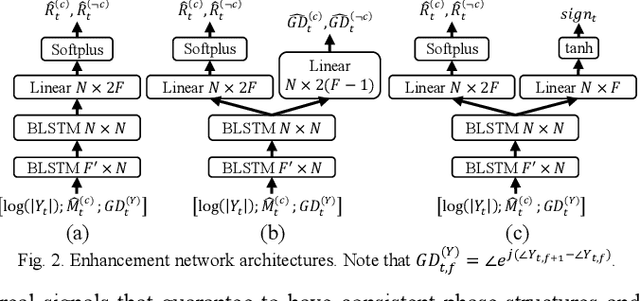
This study investigates phase reconstruction for deep learning based monaural talker-independent speaker separation in the short-time Fourier transform (STFT) domain. The key observation is that, for a mixture of two sources, with their magnitudes accurately estimated and under a geometric constraint, the absolute phase difference between each source and the mixture can be uniquely determined; in addition, the source phases at each time-frequency (T-F) unit can be narrowed down to only two candidates. To pick the right candidate, we propose three algorithms based on iterative phase reconstruction, group delay estimation, and phase-difference sign prediction. State-of-the-art results are obtained on the publicly available wsj0-2mix and 3mix corpus.
Supervised Speech Separation Based on Deep Learning: An Overview
Jun 15, 2018
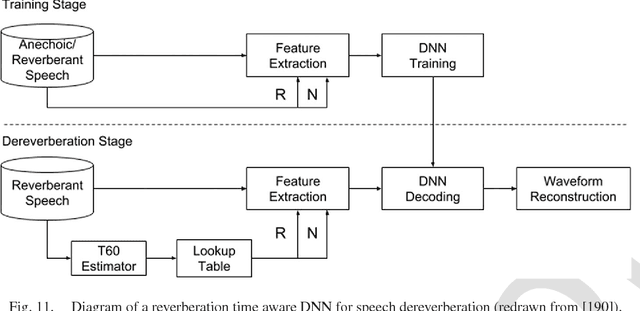
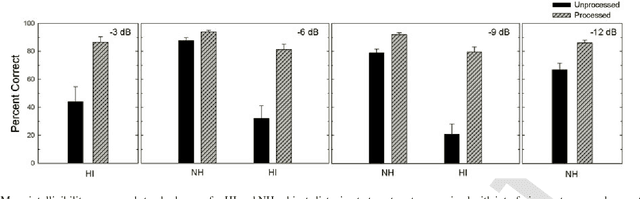
Speech separation is the task of separating target speech from background interference. Traditionally, speech separation is studied as a signal processing problem. A more recent approach formulates speech separation as a supervised learning problem, where the discriminative patterns of speech, speakers, and background noise are learned from training data. Over the past decade, many supervised separation algorithms have been put forward. In particular, the recent introduction of deep learning to supervised speech separation has dramatically accelerated progress and boosted separation performance. This article provides a comprehensive overview of the research on deep learning based supervised speech separation in the last several years. We first introduce the background of speech separation and the formulation of supervised separation. Then we discuss three main components of supervised separation: learning machines, training targets, and acoustic features. Much of the overview is on separation algorithms where we review monaural methods, including speech enhancement (speech-nonspeech separation), speaker separation (multi-talker separation), and speech dereverberation, as well as multi-microphone techniques. The important issue of generalization, unique to supervised learning, is discussed. This overview provides a historical perspective on how advances are made. In addition, we discuss a number of conceptual issues, including what constitutes the target source.
End-to-End Speech Separation with Unfolded Iterative Phase Reconstruction
Apr 26, 2018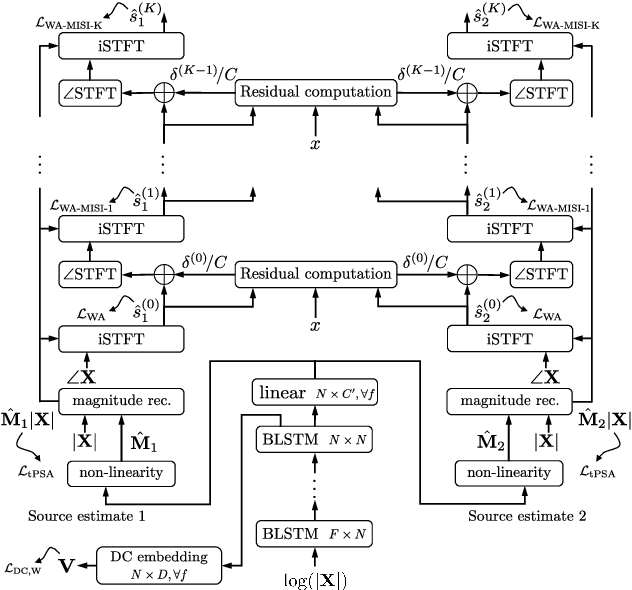
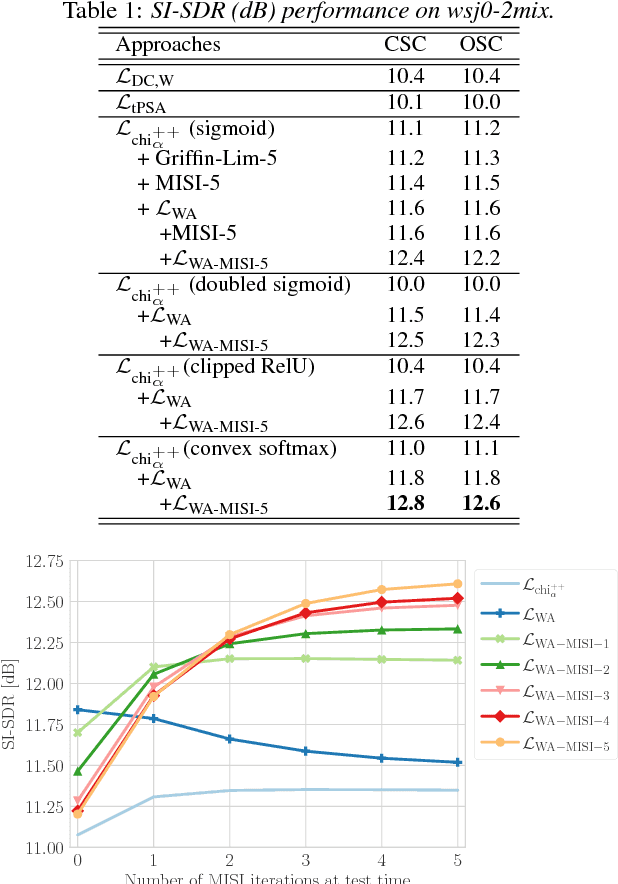
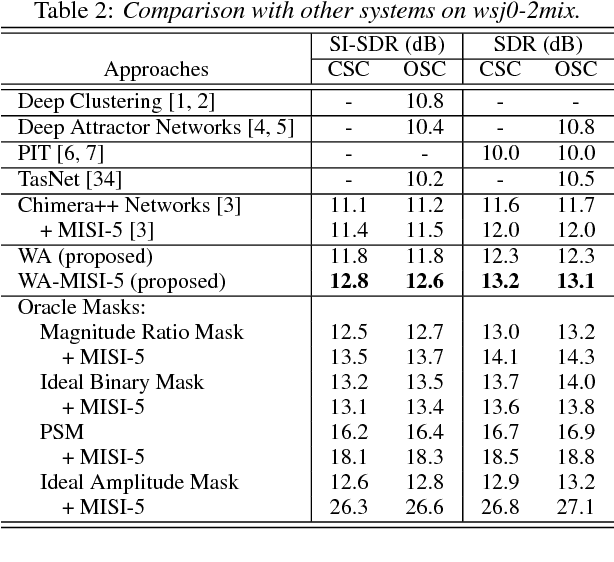
This paper proposes an end-to-end approach for single-channel speaker-independent multi-speaker speech separation, where time-frequency (T-F) masking, the short-time Fourier transform (STFT), and its inverse are represented as layers within a deep network. Previous approaches, rather than computing a loss on the reconstructed signal, used a surrogate loss based on the target STFT magnitudes. This ignores reconstruction error introduced by phase inconsistency. In our approach, the loss function is directly defined on the reconstructed signals, which are optimized for best separation. In addition, we train through unfolded iterations of a phase reconstruction algorithm, represented as a series of STFT and inverse STFT layers. While mask values are typically limited to lie between zero and one for approaches using the mixture phase for reconstruction, this limitation is less relevant if the estimated magnitudes are to be used together with phase reconstruction. We thus propose several novel activation functions for the output layer of the T-F masking, to allow mask values beyond one. On the publicly-available wsj0-2mix dataset, our approach achieves state-of-the-art 12.6 dB scale-invariant signal-to-distortion ratio (SI-SDR) and 13.1 dB SDR, revealing new possibilities for deep learning based phase reconstruction and representing a fundamental progress towards solving the notoriously-hard cocktail party problem.