 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty-Aware Unsupervised Domain Adaptation in Object Detection
Feb 27, 2021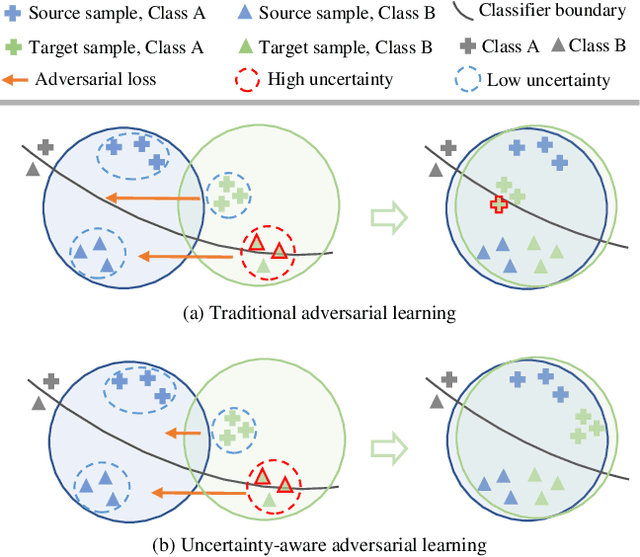
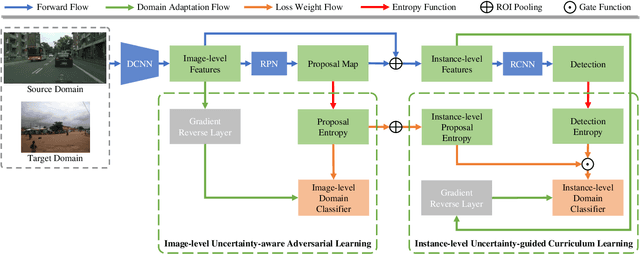

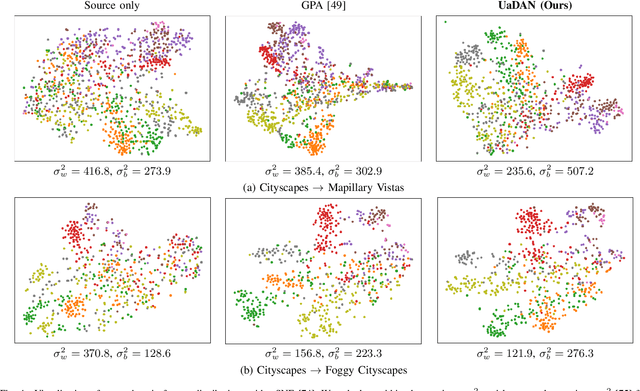
Unsupervised domain adaptive object detection aims to adapt detectors from a labelled source domain to an unlabelled target domain. Most existing works take a two-stage strategy that first generates region proposals and then detects objects of interest, where adversarial learning is widely adopted to mitigate the inter-domain discrepancy in both stages. However, adversarial learning may impair the alignment of well-aligned samples as it merely aligns the global distributions across domains. To address this issue, we design an uncertainty-aware domain adaptation network (UaDAN) that introduces conditional adversarial learning to align well-aligned and poorly-aligned samples separately in different manners. Specifically, we design an uncertainty metric that assesses the alignment of each sample and adjusts the strength of adversarial learning for well-aligned and poorly-aligned samples adaptively. In addition, we exploit the uncertainty metric to achieve curriculum learning that first performs easier image-level alignment and then more difficult instance-level alignment progressively. Extensive experiments over four challenging domain adaptive object detection datasets show that UaDAN achieves superior performance as compared with state-of-the-art methods.
Contextual-Relation Consistent Domain Adaptation for Semantic Segmentation
Jul 15, 2020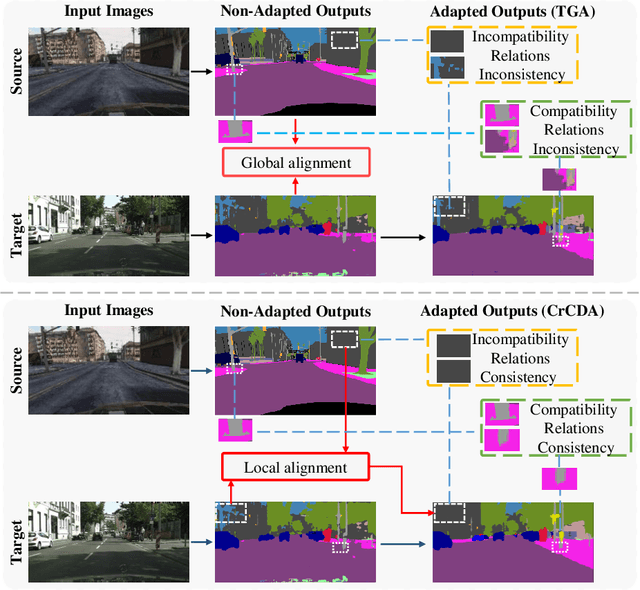
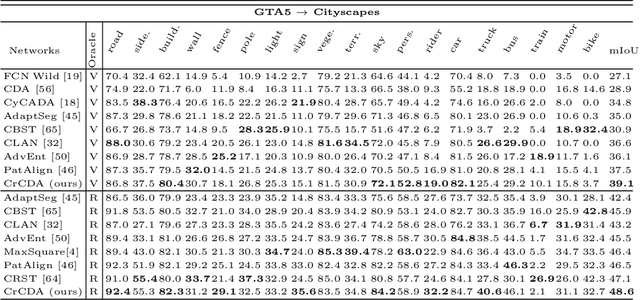
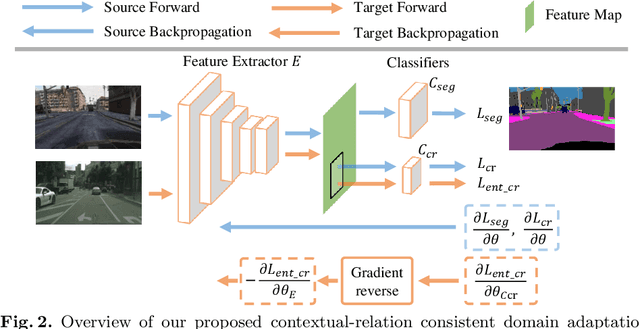
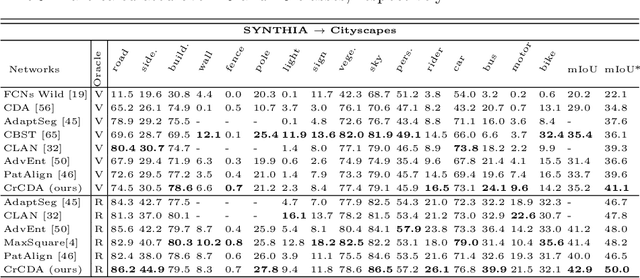
Recent advances in unsupervised domain adaptation for semantic segmentation have shown great potentials to relieve the demand of expensive per-pixel annotations. However, most existing works address the domain discrepancy by aligning the data distributions of two domains at a global image level whereas the local consistencies are largely neglected. This paper presents an innovative local contextual-relation consistent domain adaptation (CrCDA) technique that aims to achieve local-level consistencies during the global-level alignment. The idea is to take a closer look at region-wise feature representations and align them for local-level consistencies. Specifically, CrCDA learns and enforces the prototypical local contextual-relations explicitly in the feature space of a labelled source domain while transferring them to an unlabelled target domain via backpropagation-based adversarial learning. An adaptive entropy max-min adversarial learning scheme is designed to optimally align these hundreds of local contextual-relations across domain without requiring discriminator or extra computation overhead. The proposed CrCDA has been evaluated extensively over two challenging domain adaptive segmentation tasks (e.g., GTA5 to Cityscapes and SYNTHIA to Cityscapes), and experiments demonstrate its superior segmentation performance as compared with state-of-the-art methods.
Unsupervised Domain Adaptation for Multispectral Pedestrian Detection
Apr 07, 2019
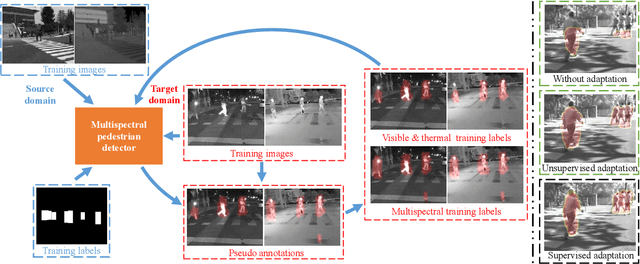

Multimodal information (e.g., visible and thermal) can generate robust pedestrian detections to facilitate around-the-clock computer vision applications, such as autonomous driving and video surveillance. However, it still remains a crucial challenge to train a reliable detector working well in different multispectral pedestrian datasets without manual annotations. In this paper, we propose a novel unsupervised domain adaptation framework for multispectral pedestrian detection, by iteratively generating pseudo annotations and updating the parameters of our designed multispectral pedestrian detector on target domain. Pseudo annotations are generated using the detector trained on source domain, and then updated by fixing the parameters of detector and minimizing the cross entropy loss without back-propagation. Training labels are generated using the pseudo annotations by considering the characteristics of similarity and complementarity between well-aligned visible and infrared image pairs. The parameters of detector are updated using the generated labels by minimizing our defined multi-detection loss function with back-propagation. The optimal parameters of detector can be obtained after iteratively updating the pseudo annotations and parameters. Experimental results show that our proposed unsupervised multimodal domain adaptation method achieves significantly higher detection performance than the approach without domain adaptation, and is competitive with the supervised multispectral pedestrian detectors.
Box-level Segmentation Supervised Deep Neural Networks for Accurate and Real-time Multispectral Pedestrian Detection
Feb 14, 2019
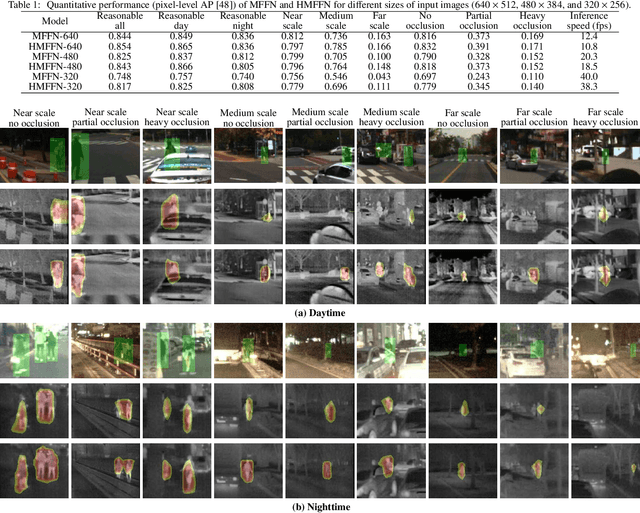
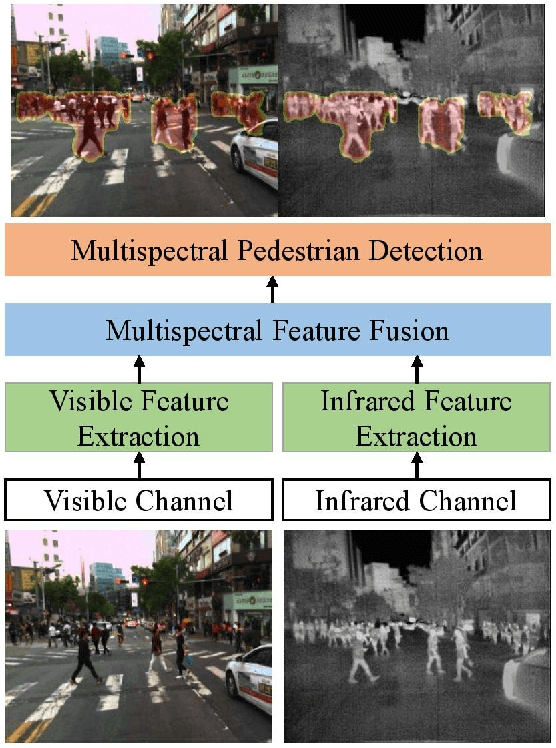
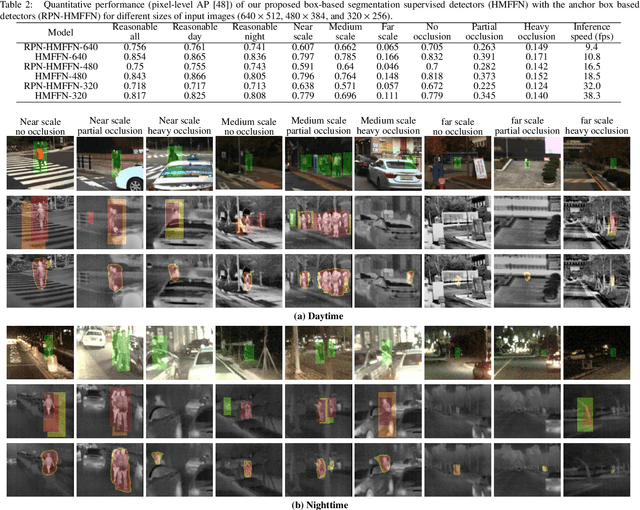
Effective fusion of complementary information captured by multi-modal sensors (visible and infrared cameras) enables robust pedestrian detection under various surveillance situations (e.g. daytime and nighttime). In this paper, we present a novel box-level segmentation supervised learning framework for accurate and real-time multispectral pedestrian detection by incorporating features extracted in visible and infrared channels. Specifically, our method takes pairs of aligned visible and infrared images with easily obtained bounding box annotations as input and estimates accurate prediction maps to highlight the existence of pedestrians. It offers two major advantages over the existing anchor box based multispectral detection methods. Firstly, it overcomes the hyperparameter setting problem occurred during the training phase of anchor box based detectors and can obtain more accurate detection results, especially for small and occluded pedestrian instances. Secondly, it is capable of generating accurate detection results using small-size input images, leading to improvement of computational efficiency for real-time autonomous driving applications. Experimental results on KAIST multispectral dataset show that our proposed method outperforms state-of-the-art approaches in terms of both accuracy and speed.
Fusion of Multispectral Data Through Illumination-aware Deep Neural Networks for Pedestrian Detection
Feb 27, 2018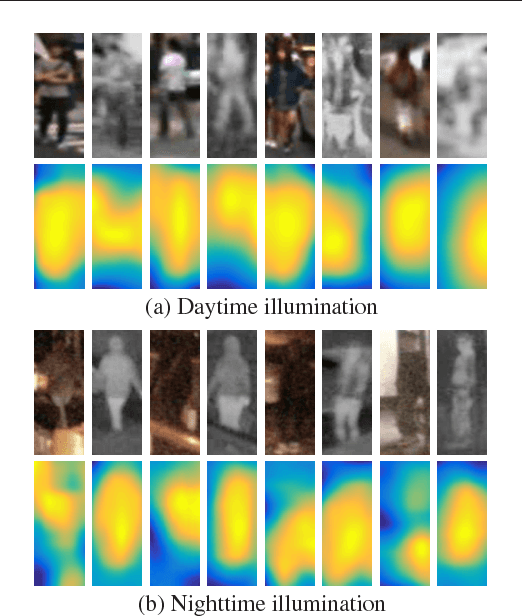
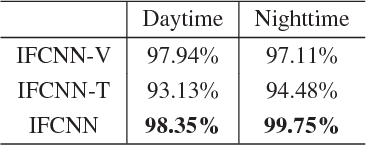
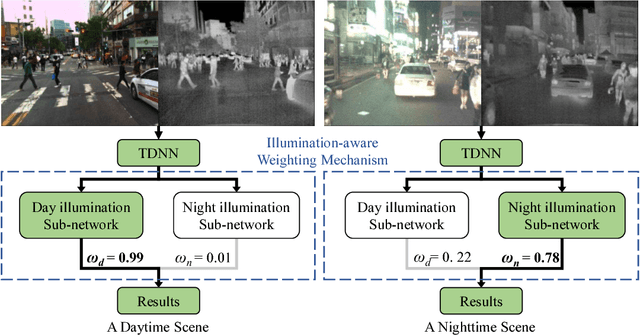
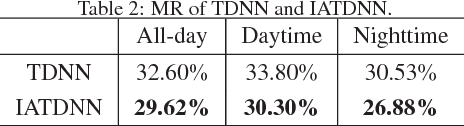
Multispectral pedestrian detection has received extensive attention in recent years as a promising solution to facilitate robust human target detection for around-the-clock applications (e.g. security surveillance and autonomous driving). In this paper, we demonstrate illumination information encoded in multispectral images can be utilized to significantly boost performance of pedestrian detection. A novel illumination-aware weighting mechanism is present to accurately depict illumination condition of a scene. Such illumination information is incorporated into two-stream deep convolutional neural networks to learn multispectral human-related features under different illumination conditions (daytime and nighttime). Moreover, we utilized illumination information together with multispectral data to generate more accurate semantic segmentation which are used to boost pedestrian detection accuracy. Putting all of the pieces together, we present a powerful framework for multispectral pedestrian detection based on multi-task learning of illumination-aware pedestrian detection and semantic segmentation. Our proposed method is trained end-to-end using a well-designed multi-task loss function and outperforms state-of-the-art approaches on KAIST multispectral pedestrian dataset.