 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMLPerf HPC: A Holistic Benchmark Suite for Scientific Machine Learning on HPC Systems
Oct 26, 2021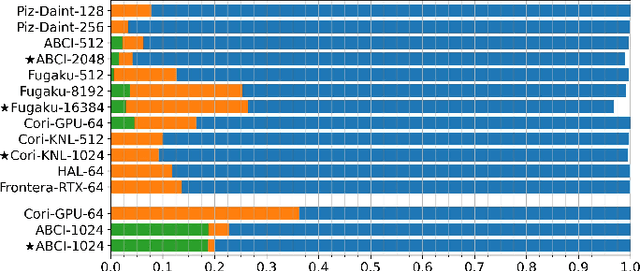
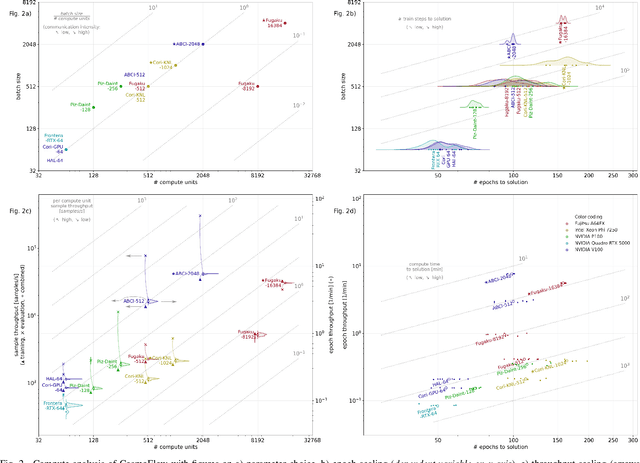
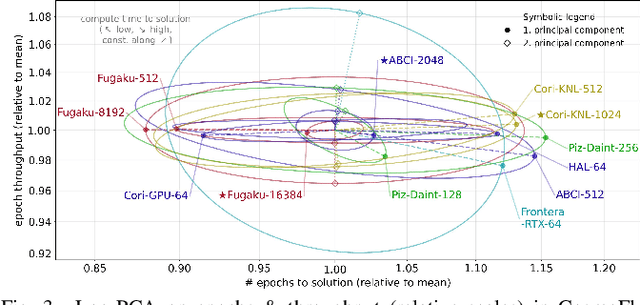
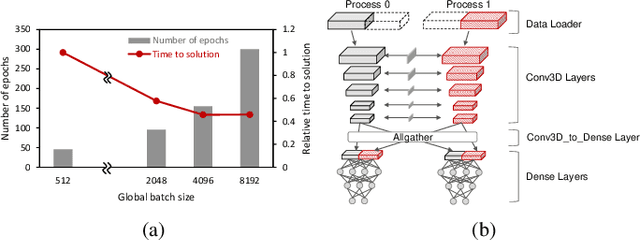
Scientific communities are increasingly adopting machine learning and deep learning models in their applications to accelerate scientific insights. High performance computing systems are pushing the frontiers of performance with a rich diversity of hardware resources and massive scale-out capabilities. There is a critical need to understand fair and effective benchmarking of machine learning applications that are representative of real-world scientific use cases. MLPerf is a community-driven standard to benchmark machine learning workloads, focusing on end-to-end performance metrics. In this paper, we introduce MLPerf HPC, a benchmark suite of large-scale scientific machine learning training applications driven by the MLCommons Association. We present the results from the first submission round, including a diverse set of some of the world's largest HPC systems. We develop a systematic framework for their joint analysis and compare them in terms of data staging, algorithmic convergence, and compute performance. As a result, we gain a quantitative understanding of optimizations on different subsystems such as staging and on-node loading of data, compute-unit utilization, and communication scheduling, enabling overall $>10 \times$ (end-to-end) performance improvements through system scaling. Notably, our analysis shows a scale-dependent interplay between the dataset size, a system's memory hierarchy, and training convergence that underlines the importance of near-compute storage. To overcome the data-parallel scalability challenge at large batch sizes, we discuss specific learning techniques and hybrid data-and-model parallelism that are effective on large systems. We conclude by characterizing each benchmark with respect to low-level memory, I/O, and network behavior to parameterize extended roofline performance models in future rounds.
Confluence of Artificial Intelligence and High Performance Computing for Accelerated, Scalable and Reproducible Gravitational Wave Detection
Dec 15, 2020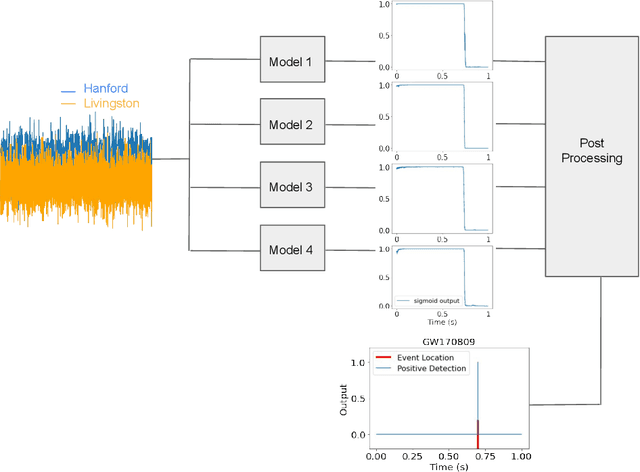
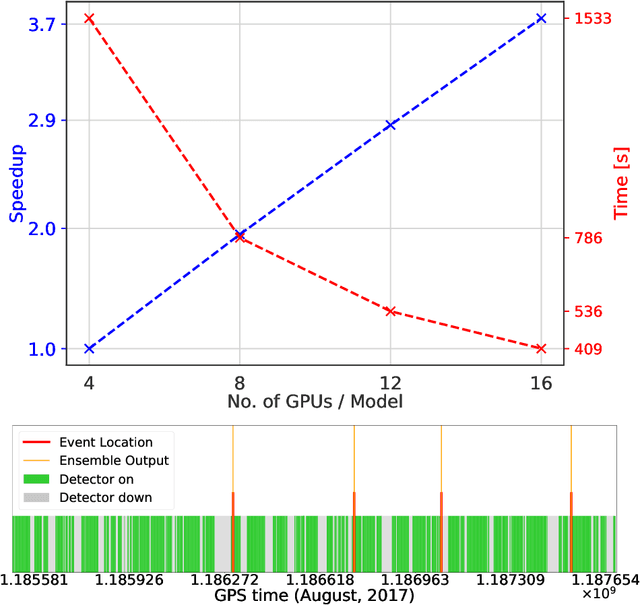
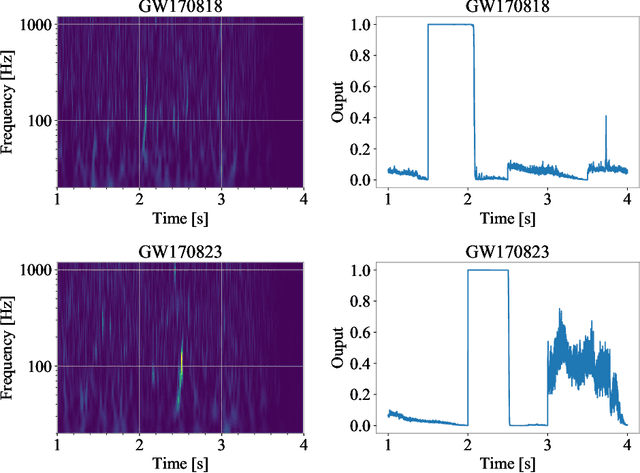
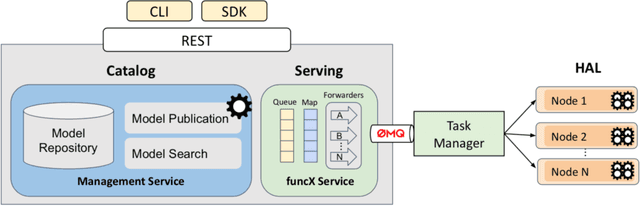
Finding new ways to use artificial intelligence (AI) to accelerate the analysis of gravitational wave data, and ensuring the developed models are easily reusable promises to unlock new opportunities in multi-messenger astrophysics (MMA), and to enable wider use, rigorous validation, and sharing of developed models by the community. In this work, we demonstrate how connecting recently deployed DOE and NSF-sponsored cyberinfrastructure allows for new ways to publish models, and to subsequently deploy these models into applications using computing platforms ranging from laptops to high performance computing clusters. We develop a workflow that connects the Data and Learning Hub for Science (DLHub), a repository for publishing machine learning models, with the Hardware Accelerated Learning (HAL) deep learning computing cluster, using funcX as a universal distributed computing service. We then use this workflow to search for binary black hole gravitational wave signals in open source advanced LIGO data. We find that using this workflow, an ensemble of four openly available deep learning models can be run on HAL and process the entire month of August 2017 of advanced LIGO data in just seven minutes, identifying all four binary black hole mergers previously identified in this dataset, and reporting no misclassifications. This approach, which combines advances in AI, distributed computing, and scientific data infrastructure opens new pathways to conduct reproducible, accelerated, data-driven gravitational wave detection.