 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning heuristics for A*
Apr 11, 2022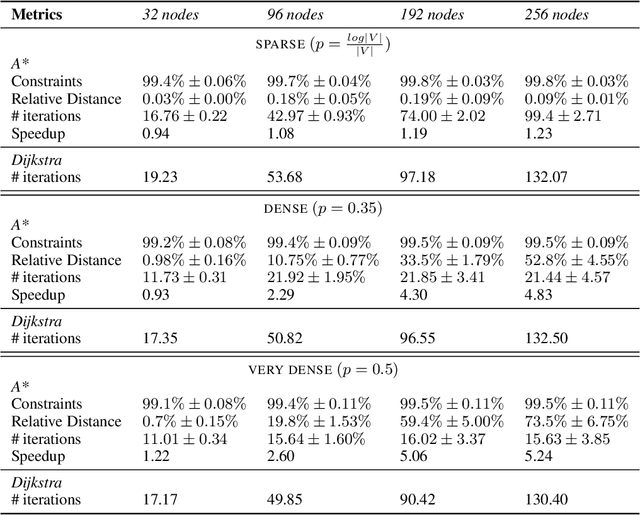
Path finding in graphs is one of the most studied classes of problems in computer science. In this context, search algorithms are often extended with heuristics for a more efficient search of target nodes. In this work we combine recent advancements in Neural Algorithmic Reasoning to learn efficient heuristic functions for path finding problems on graphs. At training time, we exploit multi-task learning to learn jointly the Dijkstra's algorithm and a consistent heuristic function for the A* search algorithm. At inference time, we plug our learnt heuristics into the A* algorithm. Results show that running A* over the learnt heuristics value can greatly speed up target node searching compared to Dijkstra, while still finding minimal-cost paths.
Avalanche RL: a Continual Reinforcement Learning Library
Mar 24, 2022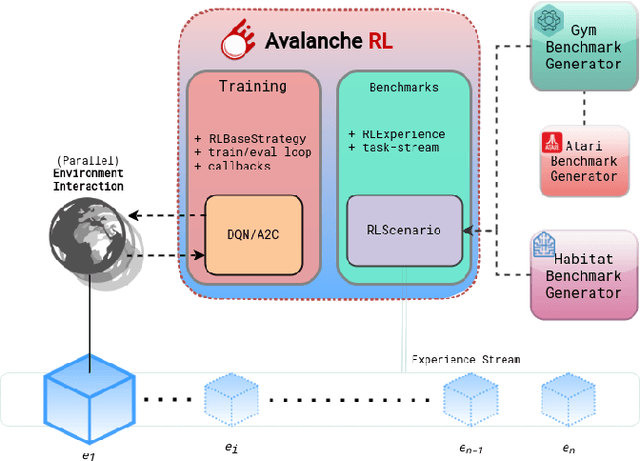

Continual Reinforcement Learning (CRL) is a challenging setting where an agent learns to interact with an environment that is constantly changing over time (the stream of experiences). In this paper, we describe Avalanche RL, a library for Continual Reinforcement Learning which allows to easily train agents on a continuous stream of tasks. Avalanche RL is based on PyTorch and supports any OpenAI Gym environment. Its design is based on Avalanche, one of the more popular continual learning libraries, which allow us to reuse a large number of continual learning strategies and improve the interaction between reinforcement learning and continual learning researchers. Additionally, we propose Continual Habitat-Lab, a novel benchmark and a high-level library which enables the usage of the photorealistic simulator Habitat-Sim for CRL research. Overall, Avalanche RL attempts to unify under a common framework continual reinforcement learning applications, which we hope will foster the growth of the field.
Practical Recommendations for Replay-based Continual Learning Methods
Mar 19, 2022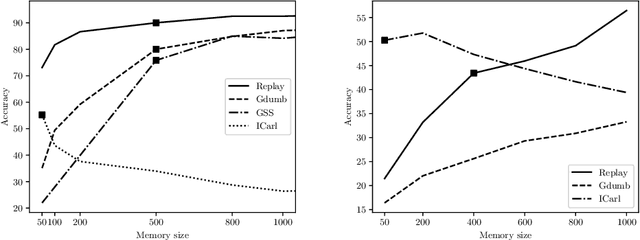
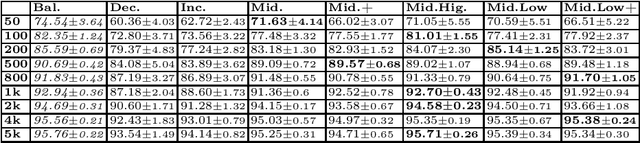
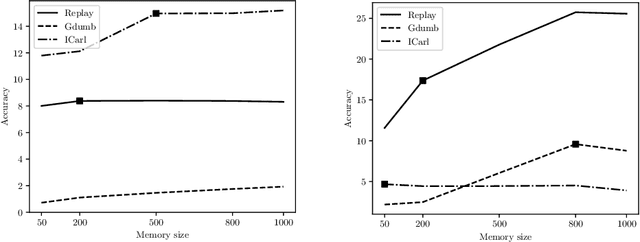

Continual Learning requires the model to learn from a stream of dynamic, non-stationary data without forgetting previous knowledge. Several approaches have been developed in the literature to tackle the Continual Learning challenge. Among them, Replay approaches have empirically proved to be the most effective ones. Replay operates by saving some samples in memory which are then used to rehearse knowledge during training in subsequent tasks. However, an extensive comparison and deeper understanding of different replay implementation subtleties is still missing in the literature. The aim of this work is to compare and analyze existing replay-based strategies and provide practical recommendations on developing efficient, effective and generally applicable replay-based strategies. In particular, we investigate the role of the memory size value, different weighting policies and discuss about the impact of data augmentation, which allows reaching better performance with lower memory sizes.
AI-as-a-Service Toolkit for Human-Centered Intelligence in Autonomous Driving
Feb 09, 2022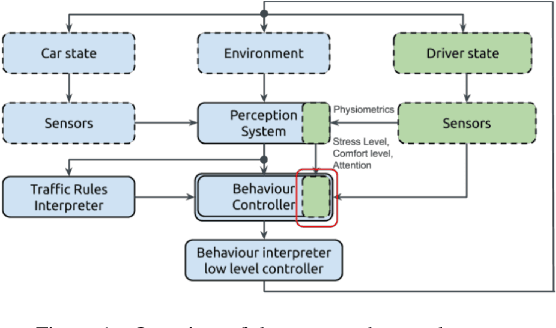
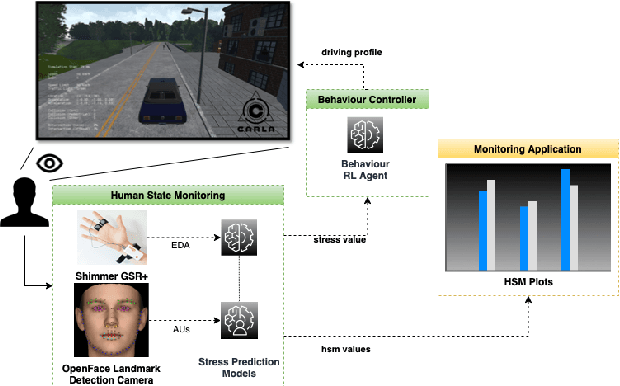
This paper presents a proof-of-concept implementation of the AI-as-a-Service toolkit developed within the H2020 TEACHING project and designed to implement an autonomous driving personalization system according to the output of an automatic driver's stress recognition algorithm, both of them realizing a Cyber-Physical System of Systems. In addition, we implemented a data-gathering subsystem to collect data from different sensors, i.e., wearables and cameras, to automatize stress recognition. The system was attached for testing to a driving simulation software, CARLA, which allows testing the approach's feasibility with minimum cost and without putting at risk drivers and passengers. At the core of the relative subsystems, different learning algorithms were implemented using Deep Neural Networks, Recurrent Neural Networks, and Reinforcement Learning.
Ex-Model: Continual Learning from a Stream of Trained Models
Dec 13, 2021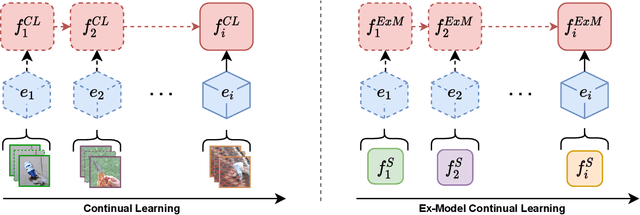
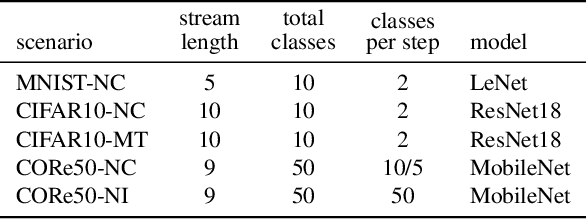
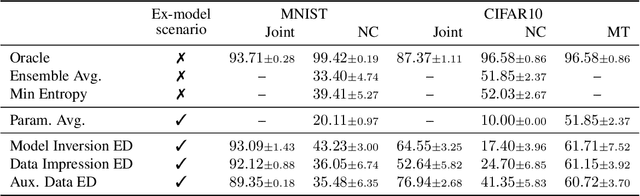

Learning continually from non-stationary data streams is a challenging research topic of growing popularity in the last few years. Being able to learn, adapt, and generalize continually in an efficient, effective, and scalable way is fundamental for a sustainable development of Artificial Intelligent systems. However, an agent-centric view of continual learning requires learning directly from raw data, which limits the interaction between independent agents, the efficiency, and the privacy of current approaches. Instead, we argue that continual learning systems should exploit the availability of compressed information in the form of trained models. In this paper, we introduce and formalize a new paradigm named "Ex-Model Continual Learning" (ExML), where an agent learns from a sequence of previously trained models instead of raw data. We further contribute with three ex-model continual learning algorithms and an empirical setting comprising three datasets (MNIST, CIFAR-10 and CORe50), and eight scenarios, where the proposed algorithms are extensively tested. Finally, we highlight the peculiarities of the ex-model paradigm and we point out interesting future research directions.
Is Class-Incremental Enough for Continual Learning?
Dec 06, 2021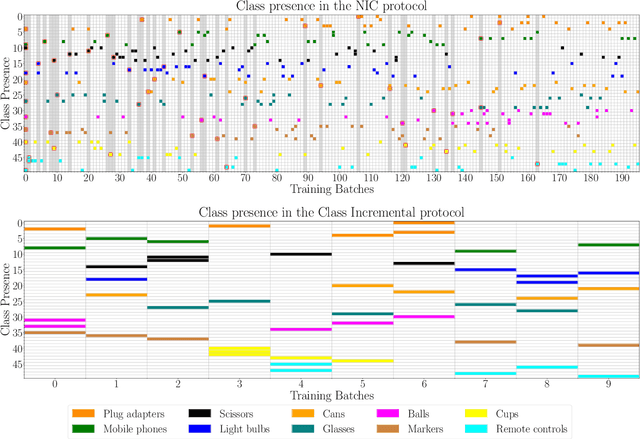
The ability of a model to learn continually can be empirically assessed in different continual learning scenarios. Each scenario defines the constraints and the opportunities of the learning environment. Here, we challenge the current trend in the continual learning literature to experiment mainly on class-incremental scenarios, where classes present in one experience are never revisited. We posit that an excessive focus on this setting may be limiting for future research on continual learning, since class-incremental scenarios artificially exacerbate catastrophic forgetting, at the expense of other important objectives like forward transfer and computational efficiency. In many real-world environments, in fact, repetition of previously encountered concepts occurs naturally and contributes to softening the disruption of previous knowledge. We advocate for a more in-depth study of alternative continual learning scenarios, in which repetition is integrated by design in the stream of incoming information. Starting from already existing proposals, we describe the advantages such class-incremental with repetition scenarios could offer for a more comprehensive assessment of continual learning models.
Predictive Auto-scaling with OpenStack Monasca
Nov 03, 2021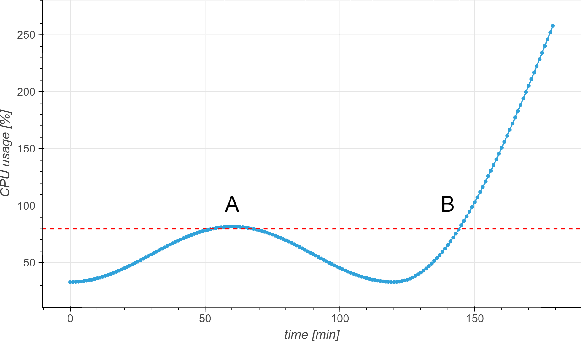
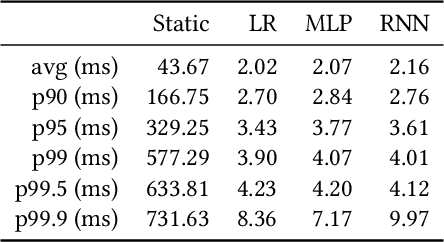

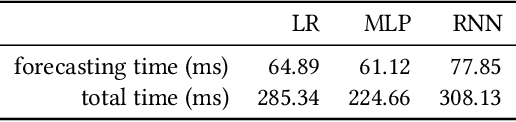
Cloud auto-scaling mechanisms are typically based on reactive automation rules that scale a cluster whenever some metric, e.g., the average CPU usage among instances, exceeds a predefined threshold. Tuning these rules becomes particularly cumbersome when scaling-up a cluster involves non-negligible times to bootstrap new instances, as it happens frequently in production cloud services. To deal with this problem, we propose an architecture for auto-scaling cloud services based on the status in which the system is expected to evolve in the near future. Our approach leverages on time-series forecasting techniques, like those based on machine learning and artificial neural networks, to predict the future dynamics of key metrics, e.g., resource consumption metrics, and apply a threshold-based scaling policy on them. The result is a predictive automation policy that is able, for instance, to automatically anticipate peaks in the load of a cloud application and trigger ahead of time appropriate scaling actions to accommodate the expected increase in traffic. We prototyped our approach as an open-source OpenStack component, which relies on, and extends, the monitoring capabilities offered by Monasca, resulting in the addition of predictive metrics that can be leveraged by orchestration components like Heat or Senlin. We show experimental results using a recurrent neural network and a multi-layer perceptron as predictor, which are compared with a simple linear regression and a traditional non-predictive auto-scaling policy. However, the proposed framework allows for the easy customization of the prediction policy as needed.
Inductive learning for product assortment graph completion
Oct 04, 2021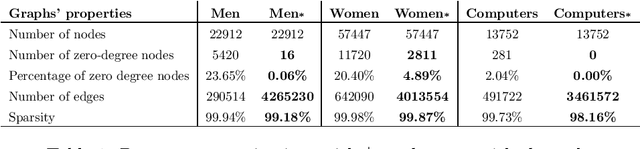
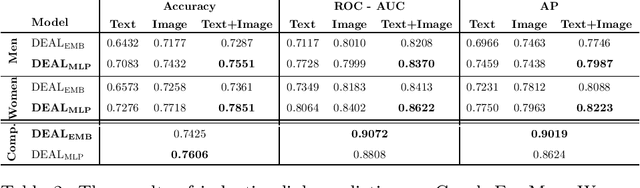
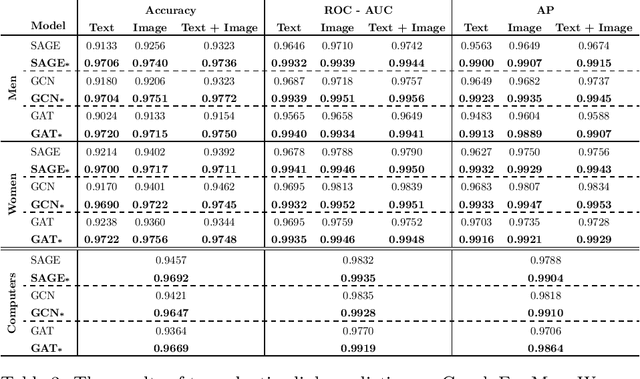
Global retailers have assortments that contain hundreds of thousands of products that can be linked by several types of relationships like style compatibility, "bought together", "watched together", etc. Graphs are a natural representation for assortments, where products are nodes and relations are edges. Relations like style compatibility are often produced by a manual process and therefore do not cover uniformly the whole graph. We propose to use inductive learning to enhance a graph encoding style compatibility of a fashion assortment, leveraging rich node information comprising textual descriptions and visual data. Then, we show how the proposed graph enhancement improves substantially the performance on transductive tasks with a minor impact on graph sparsity.
* 6 pages
GraphGen-Redux: a Fast and Lightweight Recurrent Model for labeled Graph Generation
Jul 18, 2021
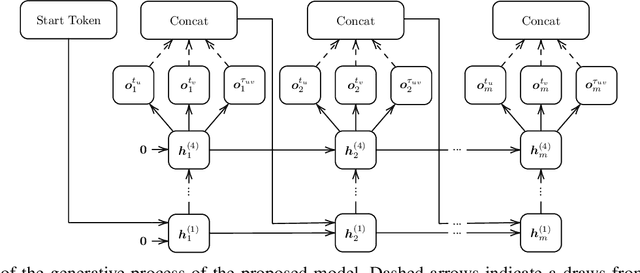
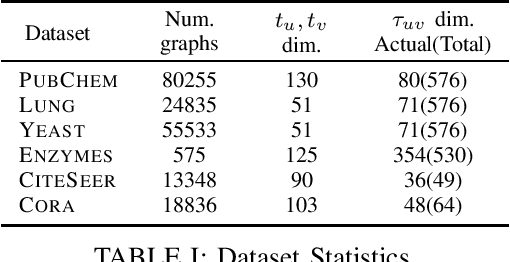
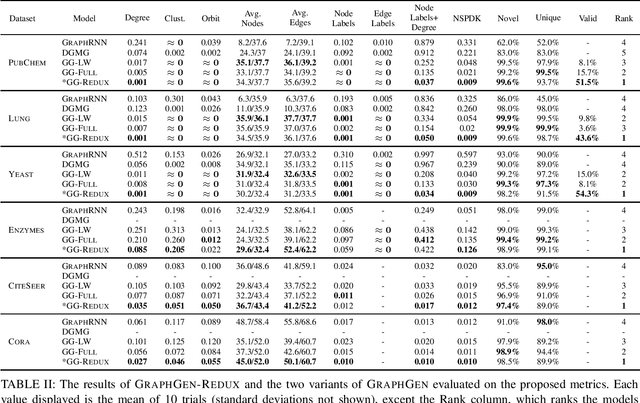
The problem of labeled graph generation is gaining attention in the Deep Learning community. The task is challenging due to the sparse and discrete nature of graph spaces. Several approaches have been proposed in the literature, most of which require to transform the graphs into sequences that encode their structure and labels and to learn the distribution of such sequences through an auto-regressive generative model. Among this family of approaches, we focus on the GraphGen model. The preprocessing phase of GraphGen transforms graphs into unique edge sequences called Depth-First Search (DFS) codes, such that two isomorphic graphs are assigned the same DFS code. Each element of a DFS code is associated with a graph edge: specifically, it is a quintuple comprising one node identifier for each of the two endpoints, their node labels, and the edge label. GraphGen learns to generate such sequences auto-regressively and models the probability of each component of the quintuple independently. While effective, the independence assumption made by the model is too loose to capture the complex label dependencies of real-world graphs precisely. By introducing a novel graph preprocessing approach, we are able to process the labeling information of both nodes and edges jointly. The corresponding model, which we term GraphGen-Redux, improves upon the generative performances of GraphGen in a wide range of datasets of chemical and social graphs. In addition, it uses approximately 78% fewer parameters than the vanilla variant and requires 50% fewer epochs of training on average.
TEACHING -- Trustworthy autonomous cyber-physical applications through human-centred intelligence
Jul 14, 2021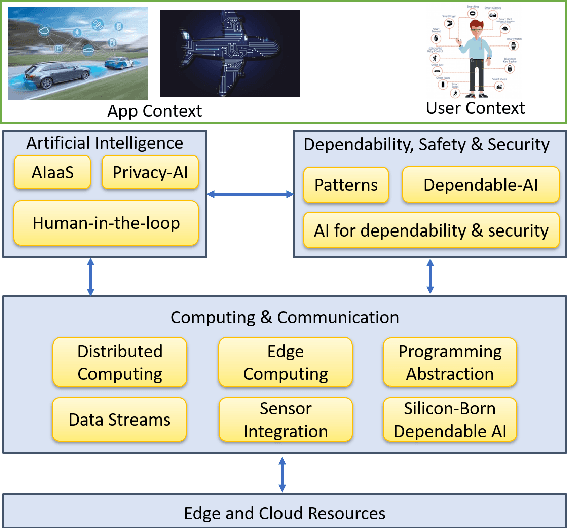
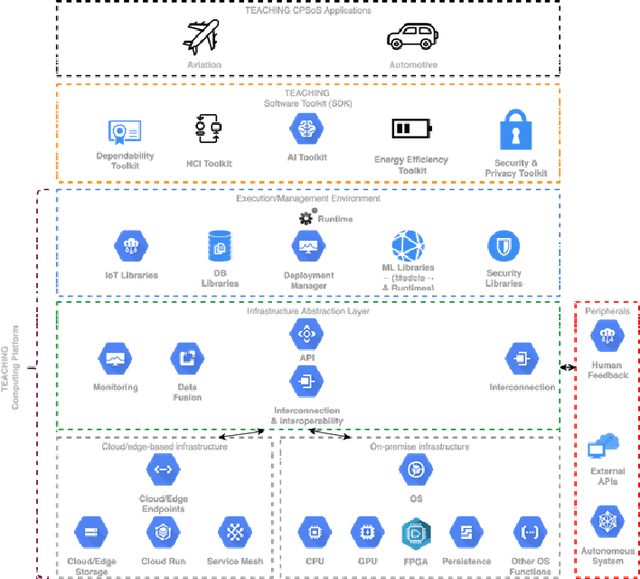
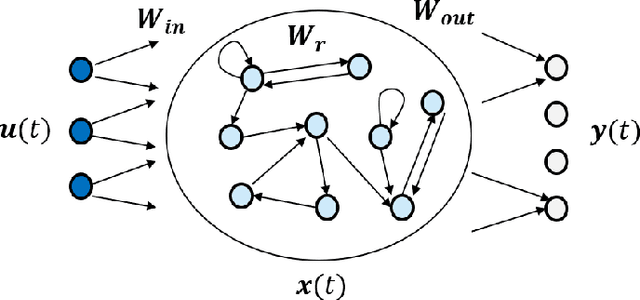
This paper discusses the perspective of the H2020 TEACHING project on the next generation of autonomous applications running in a distributed and highly heterogeneous environment comprising both virtual and physical resources spanning the edge-cloud continuum. TEACHING puts forward a human-centred vision leveraging the physiological, emotional, and cognitive state of the users as a driver for the adaptation and optimization of the autonomous applications. It does so by building a distributed, embedded and federated learning system complemented by methods and tools to enforce its dependability, security and privacy preservation. The paper discusses the main concepts of the TEACHING approach and singles out the main AI-related research challenges associated with it. Further, we provide a discussion of the design choices for the TEACHING system to tackle the aforementioned challenges