 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Protocol for Continual Explanation of SHAP
Jun 20, 2023


Continual Learning trains models on a stream of data, with the aim of learning new information without forgetting previous knowledge. Given the dynamic nature of such environments, explaining the predictions of these models can be challenging. We study the behavior of SHAP values explanations in Continual Learning and propose an evaluation protocol to robustly assess the change of explanations in Class-Incremental scenarios. We observed that, while Replay strategies enforce the stability of SHAP values in feedforward/convolutional models, they are not able to do the same with fully-trained recurrent models. We show that alternative recurrent approaches, like randomized recurrent models, are more effective in keeping the explanations stable over time.
Partial Hypernetworks for Continual Learning
Jun 19, 2023



Hypernetworks mitigate forgetting in continual learning (CL) by generating task-dependent weights and penalizing weight changes at a meta-model level. Unfortunately, generating all weights is not only computationally expensive for larger architectures, but also, it is not well understood whether generating all model weights is necessary. Inspired by latent replay methods in CL, we propose partial weight generation for the final layers of a model using hypernetworks while freezing the initial layers. With this objective, we first answer the question of how many layers can be frozen without compromising the final performance. Through several experiments, we empirically show that the number of layers that can be frozen is proportional to the distributional similarity in the CL stream. Then, to demonstrate the effectiveness of hypernetworks, we show that noisy streams can significantly impact the performance of latent replay methods, leading to increased forgetting when features from noisy experiences are replayed with old samples. In contrast, partial hypernetworks are more robust to noise by maintaining accuracy on previous experiences. Finally, we conduct experiments on the split CIFAR-100 and TinyImagenet benchmarks and compare different versions of partial hypernetworks to latent replay methods. We conclude that partial weight generation using hypernetworks is a promising solution to the problem of forgetting in neural networks. It can provide an effective balance between computation and final test accuracy in CL streams.
ADLER -- An efficient Hessian-based strategy for adaptive learning rate
May 25, 2023We derive a sound positive semi-definite approximation of the Hessian of deep models for which Hessian-vector products are easily computable. This enables us to provide an adaptive SGD learning rate strategy based on the minimization of the local quadratic approximation, which requires just twice the computation of a single SGD run, but performs comparably with grid search on SGD learning rates on different model architectures (CNN with and without residual connections) on classification tasks. We also compare the novel approximation with the Gauss-Newton approximation.
Projected Latent Distillation for Data-Agnostic Consolidation in Distributed Continual Learning
Mar 28, 2023



Distributed learning on the edge often comprises self-centered devices (SCD) which learn local tasks independently and are unwilling to contribute to the performance of other SDCs. How do we achieve forward transfer at zero cost for the single SCDs? We formalize this problem as a Distributed Continual Learning scenario, where SCD adapt to local tasks and a CL model consolidates the knowledge from the resulting stream of models without looking at the SCD's private data. Unfortunately, current CL methods are not directly applicable to this scenario. We propose Data-Agnostic Consolidation (DAC), a novel double knowledge distillation method that consolidates the stream of SC models without using the original data. DAC performs distillation in the latent space via a novel Projected Latent Distillation loss. Experimental results show that DAC enables forward transfer between SCDs and reaches state-of-the-art accuracy on Split CIFAR100, CORe50 and Split TinyImageNet, both in reharsal-free and distributed CL scenarios. Somewhat surprisingly, even a single out-of-distribution image is sufficient as the only source of data during consolidation.
Dual Algorithmic Reasoning
Feb 09, 2023Neural Algorithmic Reasoning is an emerging area of machine learning which seeks to infuse algorithmic computation in neural networks, typically by training neural models to approximate steps of classical algorithms. In this context, much of the current work has focused on learning reachability and shortest path graph algorithms, showing that joint learning on similar algorithms is beneficial for generalisation. However, when targeting more complex problems, such similar algorithms become more difficult to find. Here, we propose to learn algorithms by exploiting duality of the underlying algorithmic problem. Many algorithms solve optimisation problems. We demonstrate that simultaneously learning the dual definition of these optimisation problems in algorithmic learning allows for better learning and qualitatively better solutions. Specifically, we exploit the max-flow min-cut theorem to simultaneously learn these two algorithms over synthetically generated graphs, demonstrating the effectiveness of the proposed approach. We then validate the real-world utility of our dual algorithmic reasoner by deploying it on a challenging brain vessel classification task, which likely depends on the vessels' flow properties. We demonstrate a clear performance gain when using our model within such a context, and empirically show that learning the max-flow and min-cut algorithms together is critical for achieving such a result.
Class-Incremental Learning with Repetition
Jan 26, 2023



Real-world data streams naturally include the repetition of previous concepts. From a Continual Learning (CL) perspective, repetition is a property of the environment and, unlike replay, cannot be controlled by the user. Nowadays, Class-Incremental scenarios represent the leading test-bed for assessing and comparing CL strategies. This family of scenarios is very easy to use, but it never allows revisiting previously seen classes, thus completely disregarding the role of repetition. We focus on the family of Class-Incremental with Repetition (CIR) scenarios, where repetition is embedded in the definition of the stream. We propose two stochastic scenario generators that produce a wide range of CIR scenarios starting from a single dataset and a few control parameters. We conduct the first comprehensive evaluation of repetition in CL by studying the behavior of existing CL strategies under different CIR scenarios. We then present a novel replay strategy that exploits repetition and counteracts the natural imbalance present in the stream. On both CIFAR100 and TinyImageNet, our strategy outperforms other replay approaches, which are not designed for environments with repetition.
ECGAN: Self-supervised generative adversarial network for electrocardiography
Jan 23, 2023High-quality synthetic data can support the development of effective predictive models for biomedical tasks, especially in rare diseases or when subject to compelling privacy constraints. These limitations, for instance, negatively impact open access to electrocardiography datasets about arrhythmias. This work introduces a self-supervised approach to the generation of synthetic electrocardiography time series which is shown to promote morphological plausibility. Our model (ECGAN) allows conditioning the generative process for specific rhythm abnormalities, enhancing synchronization and diversity across samples with respect to literature models. A dedicated sample quality assessment framework is also defined, leveraging arrhythmia classifiers. The empirical results highlight a substantial improvement against state-of-the-art generative models for sequences and audio synthesis.
Causal Abstraction with Soft Interventions
Nov 22, 2022



Causal abstraction provides a theory describing how several causal models can represent the same system at different levels of detail. Existing theoretical proposals limit the analysis of abstract models to "hard" interventions fixing causal variables to be constant values. In this work, we extend causal abstraction to "soft" interventions, which assign possibly non-constant functions to variables without adding new causal connections. Specifically, (i) we generalize $\tau$-abstraction from Beckers and Halpern (2019) to soft interventions, (ii) we propose a further definition of soft abstraction to ensure a unique map $\omega$ between soft interventions, and (iii) we prove that our constructive definition of soft abstraction guarantees the intervention map $\omega$ has a specific and necessary explicit form.
Anti-Symmetric DGN: a stable architecture for Deep Graph Networks
Oct 18, 2022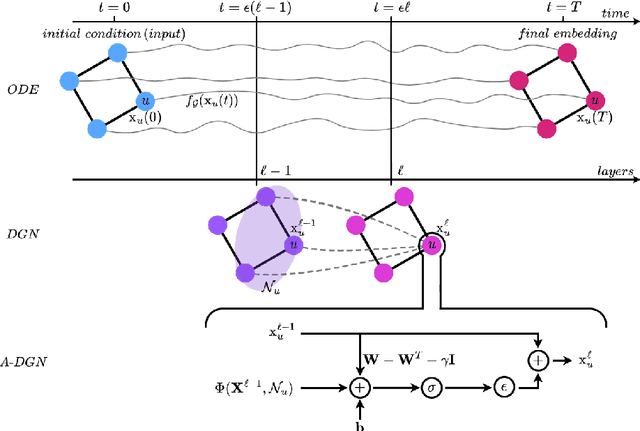

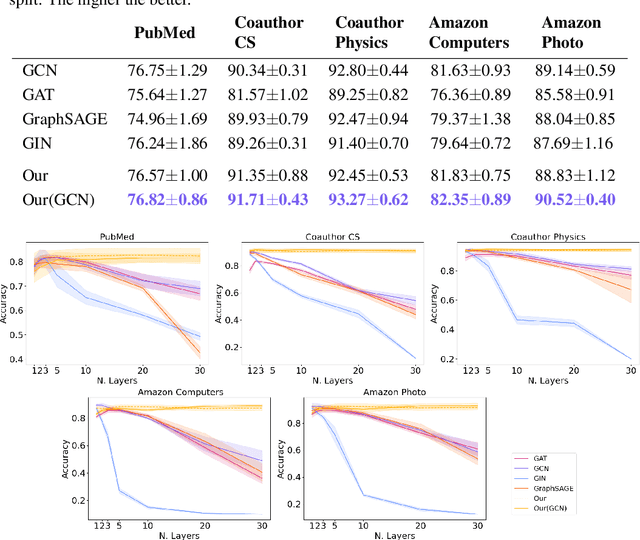
Deep Graph Networks (DGNs) currently dominate the research landscape of learning from graphs, due to their efficiency and ability to implement an adaptive message-passing scheme between the nodes. However, DGNs are typically limited in their ability to propagate and preserve long-term dependencies between nodes, \ie they suffer from the over-squashing phenomena. This reduces their effectiveness, since predictive problems may require to capture interactions at different, and possibly large, radii in order to be effectively solved. In this work, we present Anti-Symmetric Deep Graph Networks (A-DGNs), a framework for stable and non-dissipative DGN design, conceived through the lens of ordinary differential equations. We give theoretical proof that our method is stable and non-dissipative, leading to two key results: long-range information between nodes is preserved, and no gradient vanishing or explosion occurs in training. We empirically validate the proposed approach on several graph benchmarks, showing that A-DGN yields to improved performance and enables to learn effectively even when dozens of layers are used.
ChemAlgebra: Algebraic Reasoning on Chemical Reactions
Oct 05, 2022
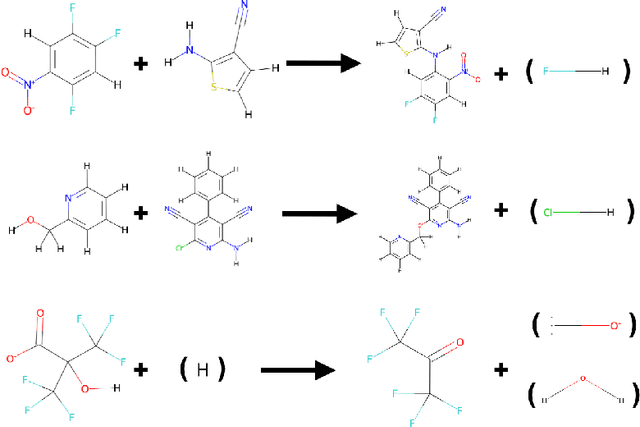

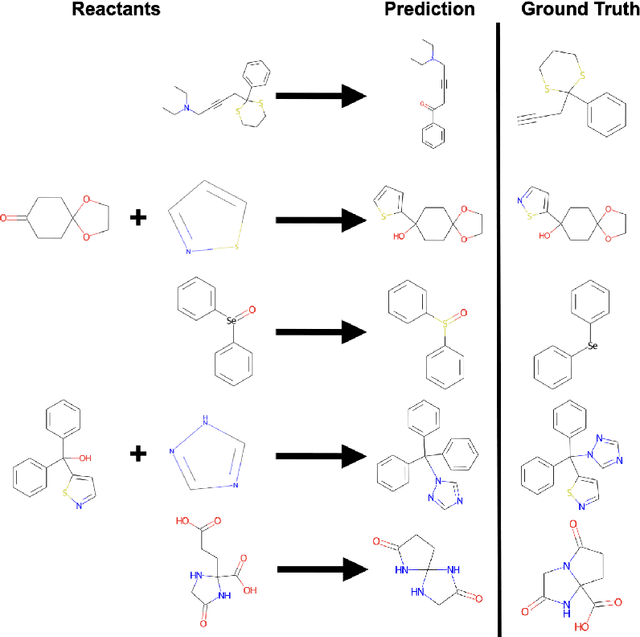
While showing impressive performance on various kinds of learning tasks, it is yet unclear whether deep learning models have the ability to robustly tackle reasoning tasks. than by learning the underlying reasoning process that is actually required to solve the tasks. Measuring the robustness of reasoning in machine learning models is challenging as one needs to provide a task that cannot be easily shortcut by exploiting spurious statistical correlations in the data, while operating on complex objects and constraints. reasoning task. To address this issue, we propose ChemAlgebra, a benchmark for measuring the reasoning capabilities of deep learning models through the prediction of stoichiometrically-balanced chemical reactions. ChemAlgebra requires manipulating sets of complex discrete objects -- molecules represented as formulas or graphs -- under algebraic constraints such as the mass preservation principle. We believe that ChemAlgebra can serve as a useful test bed for the next generation of machine reasoning models and as a promoter of their development.