 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGlobally Normalized Transition-Based Neural Networks
Jun 08, 2016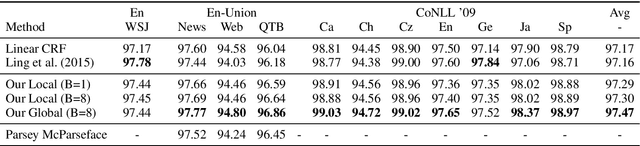
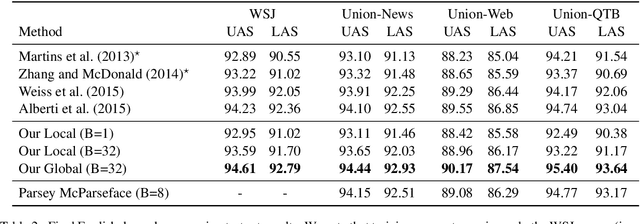
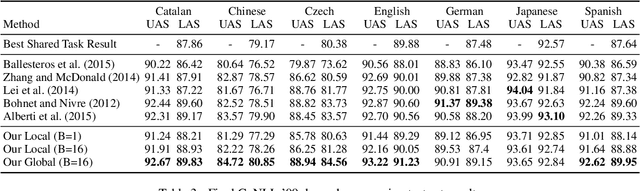
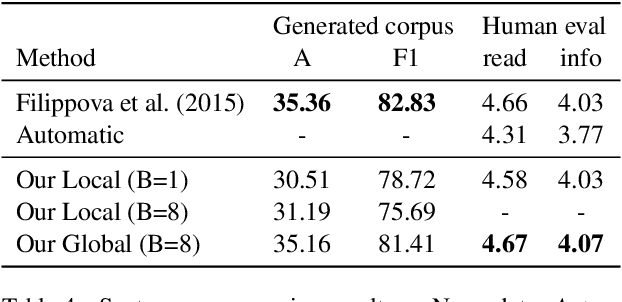
We introduce a globally normalized transition-based neural network model that achieves state-of-the-art part-of-speech tagging, dependency parsing and sentence compression results. Our model is a simple feed-forward neural network that operates on a task-specific transition system, yet achieves comparable or better accuracies than recurrent models. We discuss the importance of global as opposed to local normalization: a key insight is that the label bias problem implies that globally normalized models can be strictly more expressive than locally normalized models.
Stack-propagation: Improved Representation Learning for Syntax
Jun 08, 2016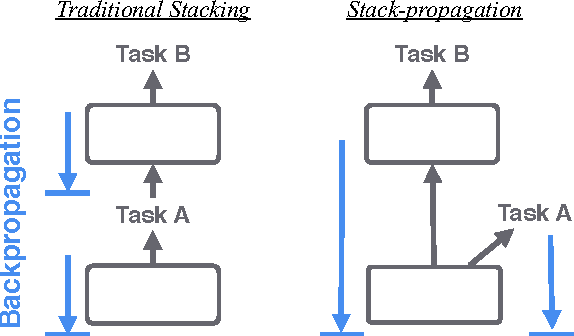
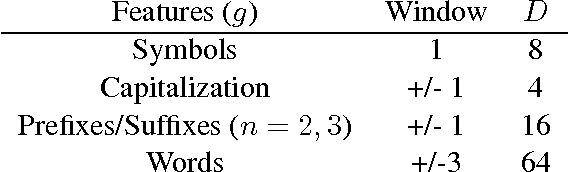
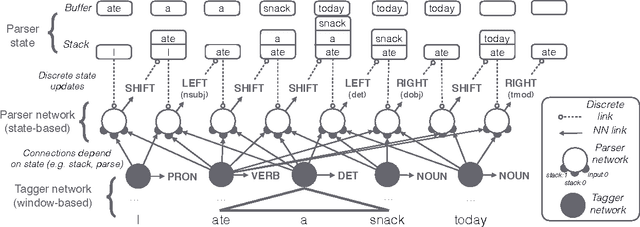
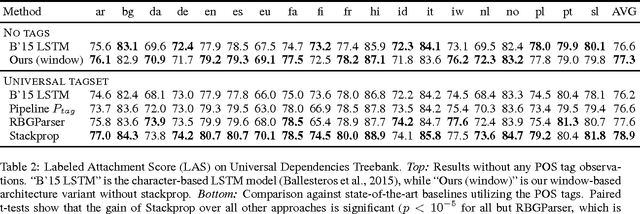
Traditional syntax models typically leverage part-of-speech (POS) information by constructing features from hand-tuned templates. We demonstrate that a better approach is to utilize POS tags as a regularizer of learned representations. We propose a simple method for learning a stacked pipeline of models which we call "stack-propagation". We apply this to dependency parsing and tagging, where we use the hidden layer of the tagger network as a representation of the input tokens for the parser. At test time, our parser does not require predicted POS tags. On 19 languages from the Universal Dependencies, our method is 1.3% (absolute) more accurate than a state-of-the-art graph-based approach and 2.7% more accurate than the most comparable greedy model.
Structured Training for Neural Network Transition-Based Parsing
Jun 19, 2015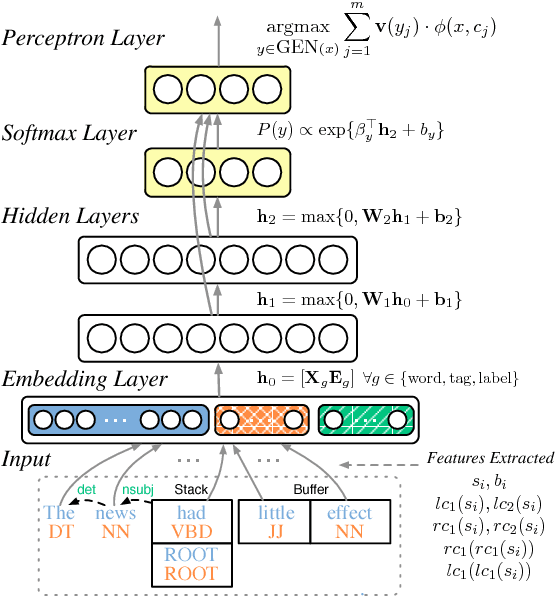
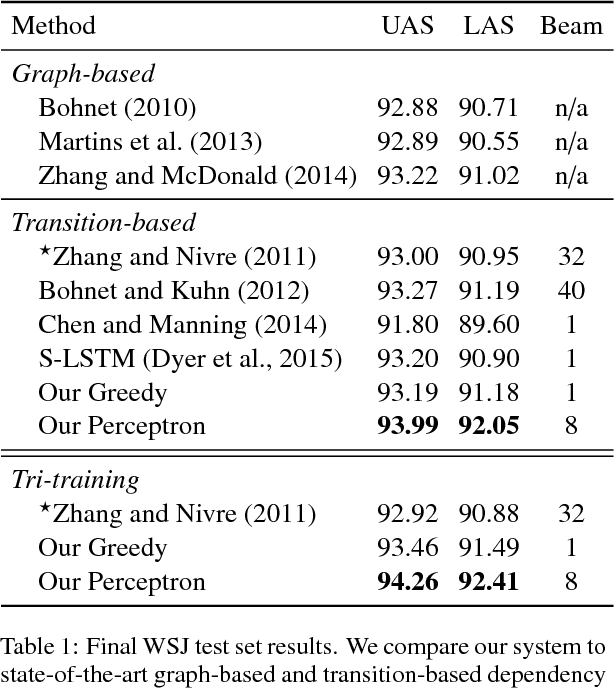
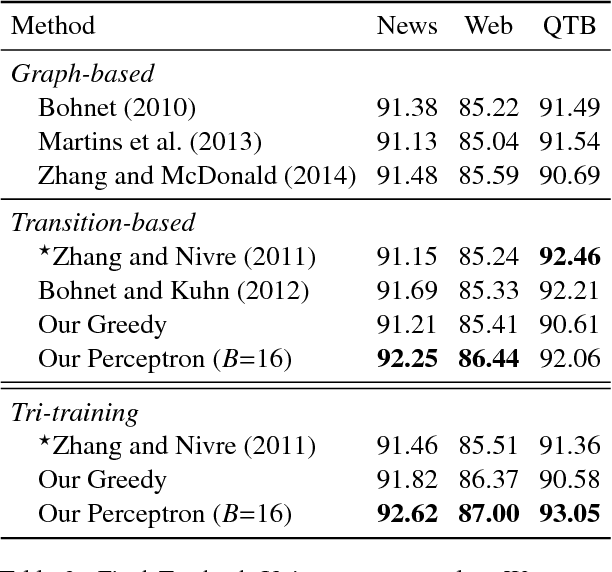
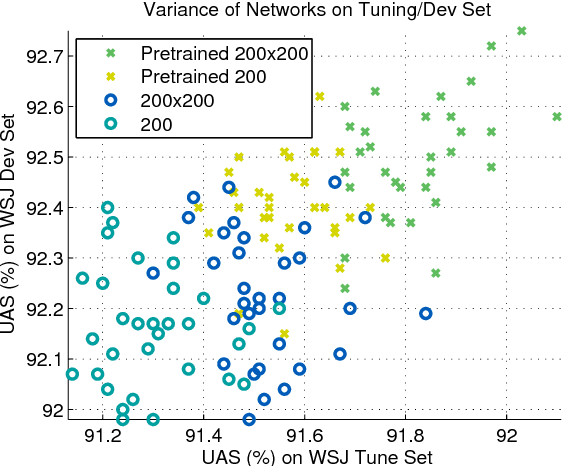
We present structured perceptron training for neural network transition-based dependency parsing. We learn the neural network representation using a gold corpus augmented by a large number of automatically parsed sentences. Given this fixed network representation, we learn a final layer using the structured perceptron with beam-search decoding. On the Penn Treebank, our parser reaches 94.26% unlabeled and 92.41% labeled attachment accuracy, which to our knowledge is the best accuracy on Stanford Dependencies to date. We also provide in-depth ablative analysis to determine which aspects of our model provide the largest gains in accuracy.
Structured Prediction Cascades
Aug 06, 2012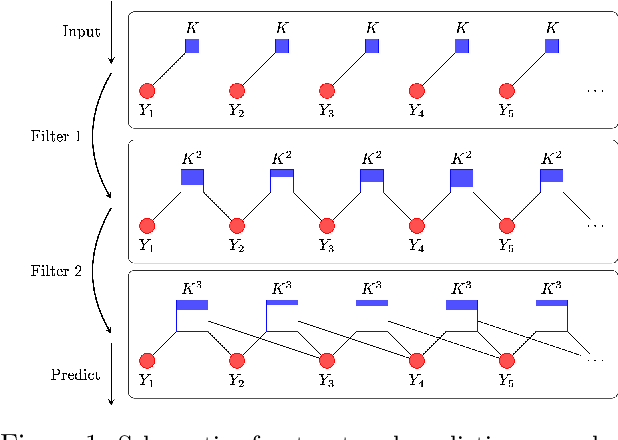
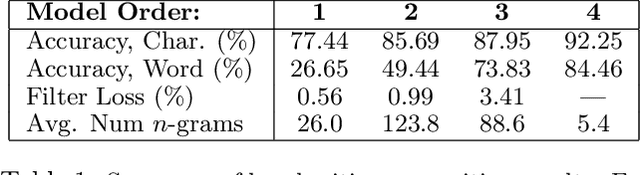
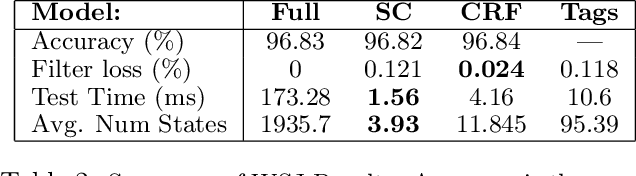
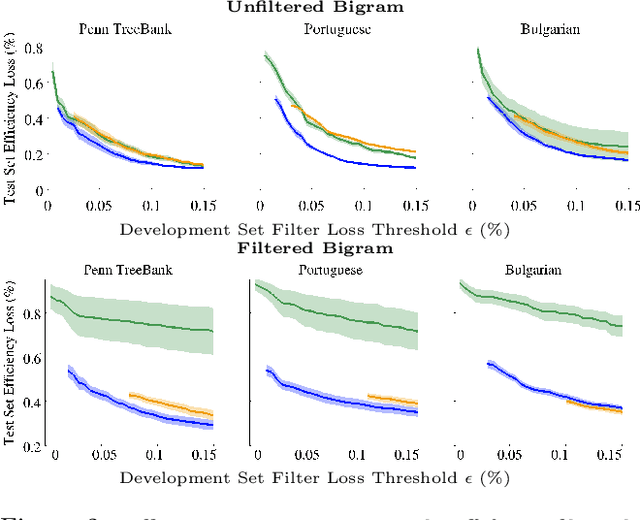
Structured prediction tasks pose a fundamental trade-off between the need for model complexity to increase predictive power and the limited computational resources for inference in the exponentially-sized output spaces such models require. We formulate and develop the Structured Prediction Cascade architecture: a sequence of increasingly complex models that progressively filter the space of possible outputs. The key principle of our approach is that each model in the cascade is optimized to accurately filter and refine the structured output state space of the next model, speeding up both learning and inference in the next layer of the cascade. We learn cascades by optimizing a novel convex loss function that controls the trade-off between the filtering efficiency and the accuracy of the cascade, and provide generalization bounds for both accuracy and efficiency. We also extend our approach to intractable models using tree-decomposition ensembles, and provide algorithms and theory for this setting. We evaluate our approach on several large-scale problems, achieving state-of-the-art performance in handwriting recognition and human pose recognition. We find that structured prediction cascades allow tremendous speedups and the use of previously intractable features and models in both settings.