 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Data-Centric Approach To Generate Faithful and High Quality Patient Summaries with Large Language Models
Feb 23, 2024



Patients often face difficulties in understanding their hospitalizations, while healthcare workers have limited resources to provide explanations. In this work, we investigate the potential of large language models to generate patient summaries based on doctors' notes and study the effect of training data on the faithfulness and quality of the generated summaries. To this end, we develop a rigorous labeling protocol for hallucinations, and have two medical experts annotate 100 real-world summaries and 100 generated summaries. We show that fine-tuning on hallucination-free data effectively reduces hallucinations from 2.60 to 1.55 per summary for Llama 2, while preserving relevant information. Although the effect is still present, it is much smaller for GPT-4 when prompted with five examples (0.70 to 0.40). We also conduct a qualitative evaluation using hallucination-free and improved training data. GPT-4 shows very good results even in the zero-shot setting. We find that common quantitative metrics do not correlate well with faithfulness and quality. Finally, we test GPT-4 for automatic hallucination detection, which yields promising results.
Benchmarking Observational Studies with Experimental Data under Right-Censoring
Feb 23, 2024



Drawing causal inferences from observational studies (OS) requires unverifiable validity assumptions; however, one can falsify those assumptions by benchmarking the OS with experimental data from a randomized controlled trial (RCT). A major limitation of existing procedures is not accounting for censoring, despite the abundance of RCTs and OSes that report right-censored time-to-event outcomes. We consider two cases where censoring time (1) is independent of time-to-event and (2) depends on time-to-event the same way in OS and RCT. For the former, we adopt a censoring-doubly-robust signal for the conditional average treatment effect (CATE) to facilitate an equivalence test of CATEs in OS and RCT, which serves as a proxy for testing if the validity assumptions hold. For the latter, we show that the same test can still be used even though unbiased CATE estimation may not be possible. We verify the effectiveness of our censoring-aware tests via semi-synthetic experiments and analyze RCT and OS data from the Women's Health Initiative study.
Impact of Large Language Model Assistance on Patients Reading Clinical Notes: A Mixed-Methods Study
Jan 17, 2024



Patients derive numerous benefits from reading their clinical notes, including an increased sense of control over their health and improved understanding of their care plan. However, complex medical concepts and jargon within clinical notes hinder patient comprehension and may lead to anxiety. We developed a patient-facing tool to make clinical notes more readable, leveraging large language models (LLMs) to simplify, extract information from, and add context to notes. We prompt engineered GPT-4 to perform these augmentation tasks on real clinical notes donated by breast cancer survivors and synthetic notes generated by a clinician, a total of 12 notes with 3868 words. In June 2023, 200 female-identifying US-based participants were randomly assigned three clinical notes with varying levels of augmentations using our tool. Participants answered questions about each note, evaluating their understanding of follow-up actions and self-reported confidence. We found that augmentations were associated with a significant increase in action understanding score (0.63 $\pm$ 0.04 for select augmentations, compared to 0.54 $\pm$ 0.02 for the control) with p=0.002. In-depth interviews of self-identifying breast cancer patients (N=7) were also conducted via video conferencing. Augmentations, especially definitions, elicited positive responses among the seven participants, with some concerns about relying on LLMs. Augmentations were evaluated for errors by clinicians, and we found misleading errors occur, with errors more common in real donated notes than synthetic notes, illustrating the importance of carefully written clinical notes. Augmentations improve some but not all readability metrics. This work demonstrates the potential of LLMs to improve patients' experience with clinical notes at a lower burden to clinicians. However, having a human in the loop is important to correct potential model errors.
Towards Verifiable Text Generation with Symbolic References
Nov 15, 2023Large language models (LLMs) have demonstrated an impressive ability to synthesize plausible and fluent text. However they remain vulnerable to hallucinations, and thus their outputs generally require manual human verification for high-stakes applications, which can be time-consuming and difficult. This paper proposes symbolically grounded generation (SymGen) as a simple approach for enabling easier validation of an LLM's output. SymGen prompts an LLM to interleave its regular output text with explicit symbolic references to fields present in some conditioning data (e.g., a table in JSON format). The references can be used to display the provenance of different spans of text in the generation, reducing the effort required for manual verification. Across data-to-text and question answering experiments, we find that LLMs are able to directly output text that makes use of symbolic references while maintaining fluency and accuracy.
Effective Human-AI Teams via Learned Natural Language Rules and Onboarding
Nov 07, 2023People are relying on AI agents to assist them with various tasks. The human must know when to rely on the agent, collaborate with the agent, or ignore its suggestions. In this work, we propose to learn rules, grounded in data regions and described in natural language, that illustrate how the human should collaborate with the AI. Our novel region discovery algorithm finds local regions in the data as neighborhoods in an embedding space where prior human behavior should be corrected. Each region is then described using a large language model in an iterative and contrastive procedure. We then teach these rules to the human via an onboarding stage. Through user studies on object detection and question-answering tasks, we show that our method can lead to more accurate human-AI teams. We also evaluate our region discovery and description algorithms separately.
Conceptualizing Machine Learning for Dynamic Information Retrieval of Electronic Health Record Notes
Aug 09, 2023The large amount of time clinicians spend sifting through patient notes and documenting in electronic health records (EHRs) is a leading cause of clinician burnout. By proactively and dynamically retrieving relevant notes during the documentation process, we can reduce the effort required to find relevant patient history. In this work, we conceptualize the use of EHR audit logs for machine learning as a source of supervision of note relevance in a specific clinical context, at a particular point in time. Our evaluation focuses on the dynamic retrieval in the emergency department, a high acuity setting with unique patterns of information retrieval and note writing. We show that our methods can achieve an AUC of 0.963 for predicting which notes will be read in an individual note writing session. We additionally conduct a user study with several clinicians and find that our framework can help clinicians retrieve relevant information more efficiently. Demonstrating that our framework and methods can perform well in this demanding setting is a promising proof of concept that they will translate to other clinical settings and data modalities (e.g., labs, medications, imaging).
Closing the Gap in High-Risk Pregnancy Care Using Machine Learning and Human-AI Collaboration
May 26, 2023



Health insurers often use algorithms to identify members who would benefit from care and condition management programs, which provide personalized, high-touch clinical support. Timely, accurate, and seamless integration between algorithmic identification and clinical intervention depends on effective collaboration between the system designers and nurse care managers. We focus on a high-risk pregnancy (HRP) program designed to reduce the likelihood of adverse prenatal, perinatal, and postnatal events and describe how we overcome three challenges of HRP programs as articulated by nurse care managers; (1) early detection of pregnancy, (2) accurate identification of impactable high-risk members, and (3) provision of explainable indicators to supplement predictions. We propose a novel algorithm for pregnancy identification that identifies pregnancies 57 days earlier than previous code-based models in a retrospective study. We then build a model to predict impactable pregnancy complications that achieves an AUROC of 0.760. Models for pregnancy identification and complications are then integrated into a proposed user interface. In a set of user studies, we collected quantitative and qualitative feedback from nurses on the utility of the predictions combined with clinical information driving the predictions on triaging members for the HRP program.
Large-Scale Study of Temporal Shift in Health Insurance Claims
May 08, 2023



Most machine learning models for predicting clinical outcomes are developed using historical data. Yet, even if these models are deployed in the near future, dataset shift over time may result in less than ideal performance. To capture this phenomenon, we consider a task--that is, an outcome to be predicted at a particular time point--to be non-stationary if a historical model is no longer optimal for predicting that outcome. We build an algorithm to test for temporal shift either at the population level or within a discovered sub-population. Then, we construct a meta-algorithm to perform a retrospective scan for temporal shift on a large collection of tasks. Our algorithms enable us to perform the first comprehensive evaluation of temporal shift in healthcare to our knowledge. We create 1,010 tasks by evaluating 242 healthcare outcomes for temporal shift from 2015 to 2020 on a health insurance claims dataset. 9.7% of the tasks show temporal shifts at the population level, and 93.0% have some sub-population affected by shifts. We dive into case studies to understand the clinical implications. Our analysis highlights the widespread prevalence of temporal shifts in healthcare.
Beyond Summarization: Designing AI Support for Real-World Expository Writing Tasks
Apr 05, 2023Large language models have introduced exciting new opportunities and challenges in designing and developing new AI-assisted writing support tools. Recent work has shown that leveraging this new technology can transform writing in many scenarios such as ideation during creative writing, editing support, and summarization. However, AI-supported expository writing--including real-world tasks like scholars writing literature reviews or doctors writing progress notes--is relatively understudied. In this position paper, we argue that developing AI supports for expository writing has unique and exciting research challenges and can lead to high real-world impacts. We characterize expository writing as evidence-based and knowledge-generating: it contains summaries of external documents as well as new information or knowledge. It can be seen as the product of authors' sensemaking process over a set of source documents, and the interplay between reading, reflection, and writing opens up new opportunities for designing AI support. We sketch three components for AI support design and discuss considerations for future research.
Conformalized Unconditional Quantile Regression
Apr 04, 2023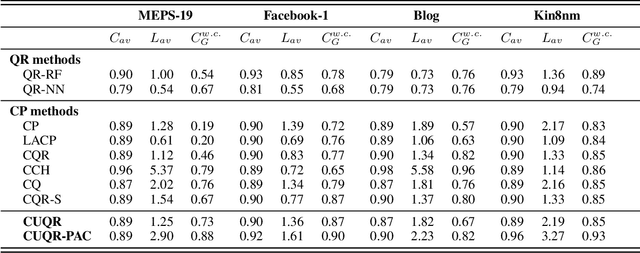
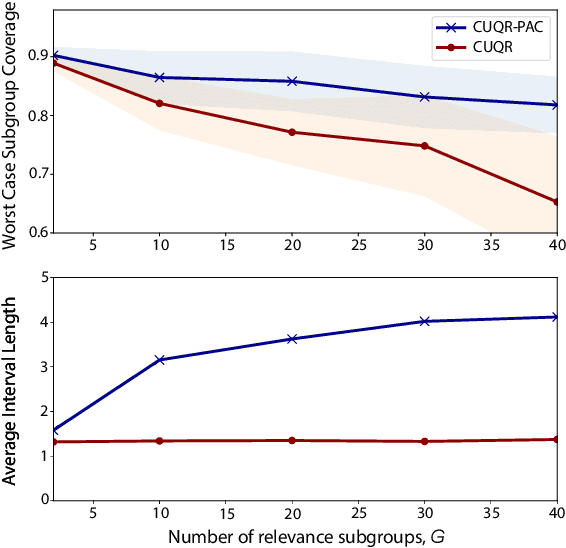
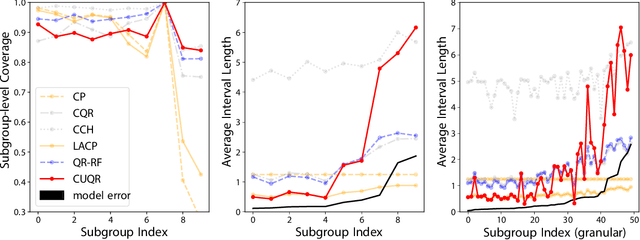

We develop a predictive inference procedure that combines conformal prediction (CP) with unconditional quantile regression (QR) -- a commonly used tool in econometrics that involves regressing the recentered influence function (RIF) of the quantile functional over input covariates. Unlike the more widely-known conditional QR, unconditional QR explicitly captures the impact of changes in covariate distribution on the quantiles of the marginal distribution of outcomes. Leveraging this property, our procedure issues adaptive predictive intervals with localized frequentist coverage guarantees. It operates by fitting a machine learning model for the RIFs using training data, and then applying the CP procedure for any test covariate with respect to a ``hypothetical'' covariate distribution localized around the new instance. Experiments show that our procedure is adaptive to heteroscedasticity, provides transparent coverage guarantees that are relevant to the test instance at hand, and performs competitively with existing methods in terms of efficiency.