 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeq-to-Final: A Benchmark for Tuning from Sequential Distributions to a Final Time Point
Jul 12, 2024



Distribution shift over time occurs in many settings. Leveraging historical data is necessary to learn a model for the last time point when limited data is available in the final period, yet few methods have been developed specifically for this purpose. In this work, we construct a benchmark with different sequences of synthetic shifts to evaluate the effectiveness of 3 classes of methods that 1) learn from all data without adapting to the final period, 2) learn from historical data with no regard to the sequential nature and then adapt to the final period, and 3) leverage the sequential nature of historical data when tailoring a model to the final period. We call this benchmark Seq-to-Final to highlight the focus on using a sequence of time periods to learn a model for the final time point. Our synthetic benchmark allows users to construct sequences with different types of shift and compare different methods. We focus on image classification tasks using CIFAR-10 and CIFAR-100 as the base images for the synthetic sequences. We also evaluate the same methods on the Portraits dataset to explore the relevance to real-world shifts over time. Finally, we create a visualization to contrast the initializations and updates from different methods at the final time step. Our results suggest that, for the sequences in our benchmark, methods that disregard the sequential structure and adapt to the final time point tend to perform well. The approaches we evaluate that leverage the sequential nature do not offer any improvement. We hope that this benchmark will inspire the development of new algorithms that are better at leveraging sequential historical data or a deeper understanding of why methods that disregard the sequential nature are able to perform well.
Large-Scale Study of Temporal Shift in Health Insurance Claims
May 08, 2023



Most machine learning models for predicting clinical outcomes are developed using historical data. Yet, even if these models are deployed in the near future, dataset shift over time may result in less than ideal performance. To capture this phenomenon, we consider a task--that is, an outcome to be predicted at a particular time point--to be non-stationary if a historical model is no longer optimal for predicting that outcome. We build an algorithm to test for temporal shift either at the population level or within a discovered sub-population. Then, we construct a meta-algorithm to perform a retrospective scan for temporal shift on a large collection of tasks. Our algorithms enable us to perform the first comprehensive evaluation of temporal shift in healthcare to our knowledge. We create 1,010 tasks by evaluating 242 healthcare outcomes for temporal shift from 2015 to 2020 on a health insurance claims dataset. 9.7% of the tasks show temporal shifts at the population level, and 93.0% have some sub-population affected by shifts. We dive into case studies to understand the clinical implications. Our analysis highlights the widespread prevalence of temporal shifts in healthcare.
Finding Regions of Heterogeneity in Decision-Making via Expected Conditional Covariance
Oct 27, 2021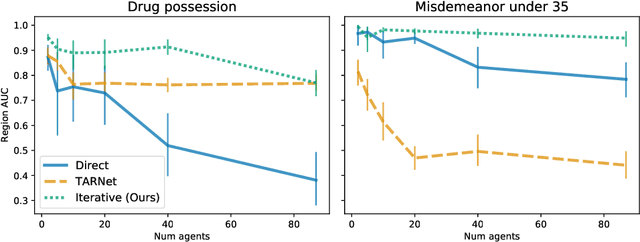
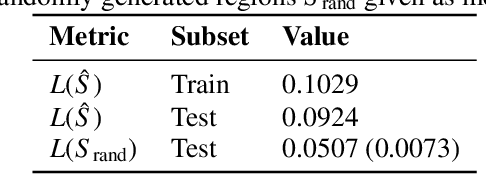
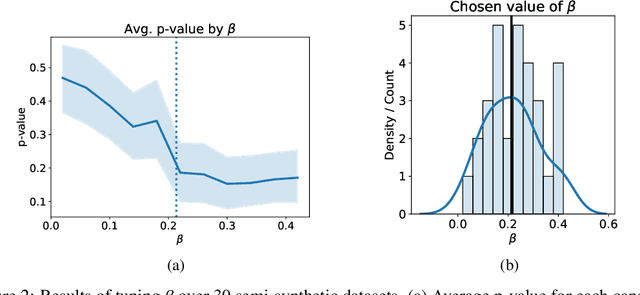

Individuals often make different decisions when faced with the same context, due to personal preferences and background. For instance, judges may vary in their leniency towards certain drug-related offenses, and doctors may vary in their preference for how to start treatment for certain types of patients. With these examples in mind, we present an algorithm for identifying types of contexts (e.g., types of cases or patients) with high inter-decision-maker disagreement. We formalize this as a causal inference problem, seeking a region where the assignment of decision-maker has a large causal effect on the decision. Our algorithm finds such a region by maximizing an empirical objective, and we give a generalization bound for its performance. In a semi-synthetic experiment, we show that our algorithm recovers the correct region of heterogeneity accurately compared to baselines. Finally, we apply our algorithm to real-world healthcare datasets, recovering variation that aligns with existing clinical knowledge.