 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRemining Hard Negatives for Generative Pseudo Labeled Domain Adaptation
Jan 24, 2025



Dense retrievers have demonstrated significant potential for neural information retrieval; however, they exhibit a lack of robustness to domain shifts, thereby limiting their efficacy in zero-shot settings across diverse domains. A state-of-the-art domain adaptation technique is Generative Pseudo Labeling (GPL). GPL uses synthetic query generation and initially mined hard negatives to distill knowledge from cross-encoder to dense retrievers in the target domain. In this paper, we analyze the documents retrieved by the domain-adapted model and discover that these are more relevant to the target queries than those of the non-domain-adapted model. We then propose refreshing the hard-negative index during the knowledge distillation phase to mine better hard negatives. Our remining R-GPL approach boosts ranking performance in 13/14 BEIR datasets and 9/12 LoTTe datasets. Our contributions are (i) analyzing hard negatives returned by domain-adapted and non-domain-adapted models and (ii) applying the GPL training with and without hard-negative re-mining in LoTTE and BEIR datasets.
Context Embeddings for Efficient Answer Generation in RAG
Jul 12, 2024Retrieval-Augmented Generation (RAG) allows overcoming the limited knowledge of LLMs by extending the input with external information. As a consequence, the contextual inputs to the model become much longer which slows down decoding time directly translating to the time a user has to wait for an answer. We address this challenge by presenting COCOM, an effective context compression method, reducing long contexts to only a handful of Context Embeddings speeding up the generation time by a large margin. Our method allows for different compression rates trading off decoding time for answer quality. Compared to earlier methods, COCOM allows for handling multiple contexts more effectively, significantly reducing decoding time for long inputs. Our method demonstrates a speed-up of up to 5.69 $\times$ while achieving higher performance compared to existing efficient context compression methods.
BERGEN: A Benchmarking Library for Retrieval-Augmented Generation
Jul 01, 2024



Retrieval-Augmented Generation allows to enhance Large Language Models with external knowledge. In response to the recent popularity of generative LLMs, many RAG approaches have been proposed, which involve an intricate number of different configurations such as evaluation datasets, collections, metrics, retrievers, and LLMs. Inconsistent benchmarking poses a major challenge in comparing approaches and understanding the impact of each component in the pipeline. In this work, we study best practices that lay the groundwork for a systematic evaluation of RAG and present BERGEN, an end-to-end library for reproducible research standardizing RAG experiments. In an extensive study focusing on QA, we benchmark different state-of-the-art retrievers, rerankers, and LLMs. Additionally, we analyze existing RAG metrics and datasets. Our open-source library BERGEN is available under \url{https://github.com/naver/bergen}.
Retrieval-augmented generation in multilingual settings
Jul 01, 2024



Retrieval-augmented generation (RAG) has recently emerged as a promising solution for incorporating up-to-date or domain-specific knowledge into large language models (LLMs) and improving LLM factuality, but is predominantly studied in English-only settings. In this work, we consider RAG in the multilingual setting (mRAG), i.e. with user queries and the datastore in 13 languages, and investigate which components and with which adjustments are needed to build a well-performing mRAG pipeline, that can be used as a strong baseline in future works. Our findings highlight that despite the availability of high-quality off-the-shelf multilingual retrievers and generators, task-specific prompt engineering is needed to enable generation in user languages. Moreover, current evaluation metrics need adjustments for multilingual setting, to account for variations in spelling named entities. The main limitations to be addressed in future works include frequent code-switching in non-Latin alphabet languages, occasional fluency errors, wrong reading of the provided documents, or irrelevant retrieval. We release the code for the resulting mRAG baseline pipeline at https://github.com/naver/bergen.
The Role of Complex NLP in Transformers for Text Ranking?
Jul 06, 2022

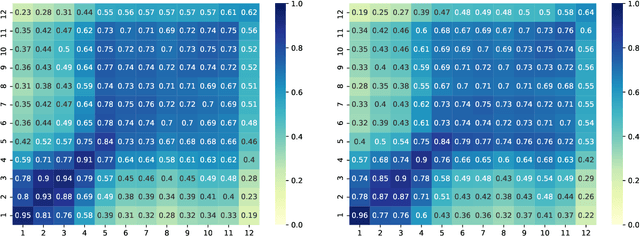
Even though term-based methods such as BM25 provide strong baselines in ranking, under certain conditions they are dominated by large pre-trained masked language models (MLMs) such as BERT. To date, the source of their effectiveness remains unclear. Is it their ability to truly understand the meaning through modeling syntactic aspects? We answer this by manipulating the input order and position information in a way that destroys the natural sequence order of query and passage and shows that the model still achieves comparable performance. Overall, our results highlight that syntactic aspects do not play a critical role in the effectiveness of re-ranking with BERT. We point to other mechanisms such as query-passage cross-attention and richer embeddings that capture word meanings based on aggregated context regardless of the word order for being the main attributions for its superior performance.
How Different are Pre-trained Transformers for Text Ranking?
Apr 05, 2022
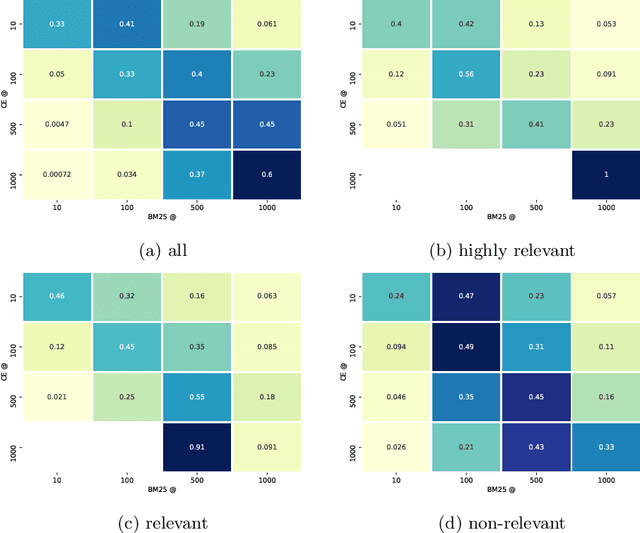

In recent years, large pre-trained transformers have led to substantial gains in performance over traditional retrieval models and feedback approaches. However, these results are primarily based on the MS Marco/TREC Deep Learning Track setup, with its very particular setup, and our understanding of why and how these models work better is fragmented at best. We analyze effective BERT-based cross-encoders versus traditional BM25 ranking for the passage retrieval task where the largest gains have been observed, and investigate two main questions. On the one hand, what is similar? To what extent does the neural ranker already encompass the capacity of traditional rankers? Is the gain in performance due to a better ranking of the same documents (prioritizing precision)? On the other hand, what is different? Can it retrieve effectively documents missed by traditional systems (prioritizing recall)? We discover substantial differences in the notion of relevance identifying strengths and weaknesses of BERT that may inspire research for future improvement. Our results contribute to our understanding of (black-box) neural rankers relative to (well-understood) traditional rankers, help understand the particular experimental setting of MS-Marco-based test collections.
On the Realization of Compositionality in Neural Networks
Jun 06, 2019
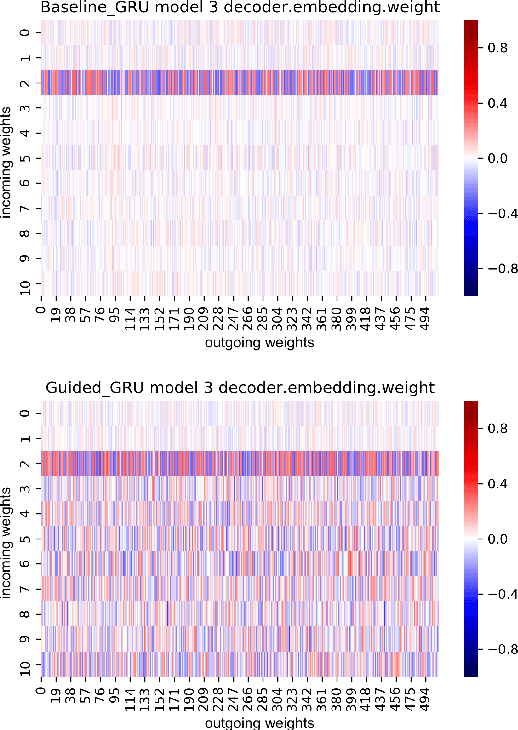
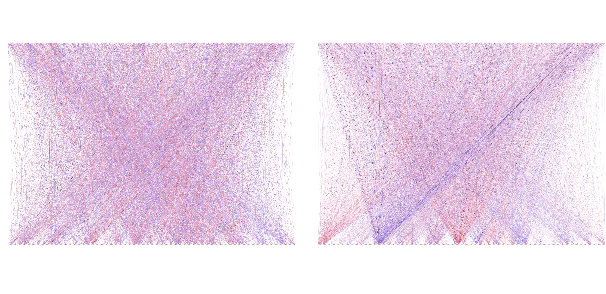
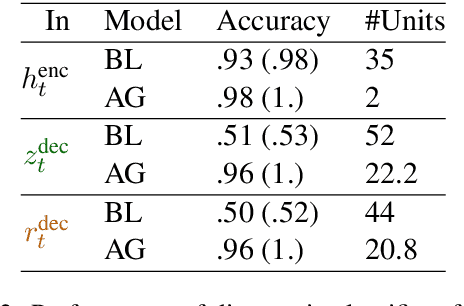
We present a detailed comparison of two types of sequence to sequence models trained to conduct a compositional task. The models are architecturally identical at inference time, but differ in the way that they are trained: our baseline model is trained with a task-success signal only, while the other model receives additional supervision on its attention mechanism (Attentive Guidance), which has shown to be an effective method for encouraging more compositional solutions (Hupkes et al.,2019). We first confirm that the models with attentive guidance indeed infer more compositional solutions than the baseline, by training them on the lookup table task presented by Li\v{s}ka et al. (2019). We then do an in-depth analysis of the structural differences between the two model types, focusing in particular on the organisation of the parameter space and the hidden layer activations and find noticeable differences in both these aspects. Guided networks focus more on the components of the input rather than the sequence as a whole and develop small functional groups of neurons with specific purposes that use their gates more selectively. Results from parameter heat maps, component swapping and graph analysis also indicate that guided networks exhibit a more modular structure with a small number of specialized, strongly connected neurons.
Point-less: More Abstractive Summarization with Pointer-Generator Networks
Apr 18, 2019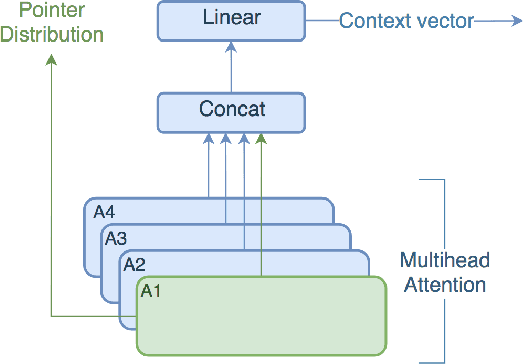
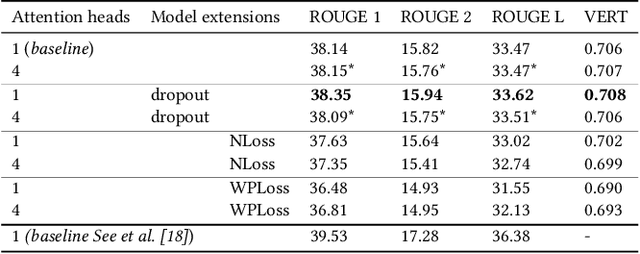
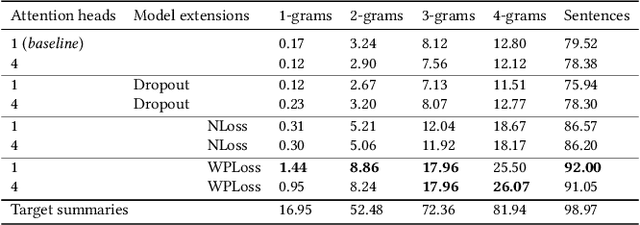
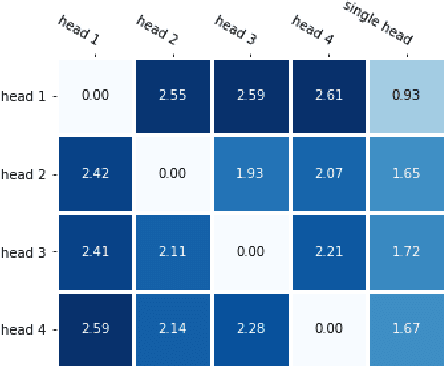
The Pointer-Generator architecture has shown to be a big improvement for abstractive summarization seq2seq models. However, the summaries produced by this model are largely extractive as over 30% of the generated sentences are copied from the source text. This work proposes a multihead attention mechanism, pointer dropout, and two new loss functions to promote more abstractive summaries while maintaining similar ROUGE scores. Both the multihead attention and dropout do not improve N-gram novelty, however, the dropout acts as a regularizer which improves the ROUGE score. The new loss function achieves significantly higher novel N-grams and sentences, at the cost of a slightly lower ROUGE score.