 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOCFR 2022: Competition on Occluded Face Recognition From Synthetically Generated Structure-Aware Occlusions
Aug 15, 2022



This work summarizes the IJCB Occluded Face Recognition Competition 2022 (IJCB-OCFR-2022) embraced by the 2022 International Joint Conference on Biometrics (IJCB 2022). OCFR-2022 attracted a total of 3 participating teams, from academia. Eventually, six valid submissions were submitted and then evaluated by the organizers. The competition was held to address the challenge of face recognition in the presence of severe face occlusions. The participants were free to use any training data and the testing data was built by the organisers by synthetically occluding parts of the face images using a well-known dataset. The submitted solutions presented innovations and performed very competitively with the considered baseline. A major output of this competition is a challenging, realistic, and diverse, and publicly available occluded face recognition benchmark with well defined evaluation protocols.
Federated Learning Enables Big Data for Rare Cancer Boundary Detection
Apr 25, 2022Although machine learning (ML) has shown promise in numerous domains, there are concerns about generalizability to out-of-sample data. This is currently addressed by centrally sharing ample, and importantly diverse, data from multiple sites. However, such centralization is challenging to scale (or even not feasible) due to various limitations. Federated ML (FL) provides an alternative to train accurate and generalizable ML models, by only sharing numerical model updates. Here we present findings from the largest FL study to-date, involving data from 71 healthcare institutions across 6 continents, to generate an automatic tumor boundary detector for the rare disease of glioblastoma, utilizing the largest dataset of such patients ever used in the literature (25,256 MRI scans from 6,314 patients). We demonstrate a 33% improvement over a publicly trained model to delineate the surgically targetable tumor, and 23% improvement over the tumor's entire extent. We anticipate our study to: 1) enable more studies in healthcare informed by large and diverse data, ensuring meaningful results for rare diseases and underrepresented populations, 2) facilitate further quantitative analyses for glioblastoma via performance optimization of our consensus model for eventual public release, and 3) demonstrate the effectiveness of FL at such scale and task complexity as a paradigm shift for multi-site collaborations, alleviating the need for data sharing.
ORCNet: A context-based network to simultaneously segment the ocular region components
Apr 15, 2022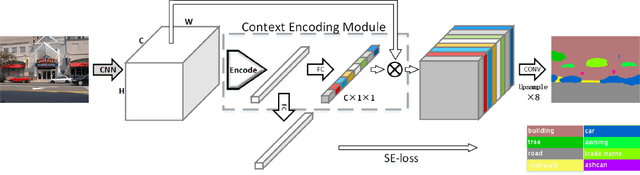
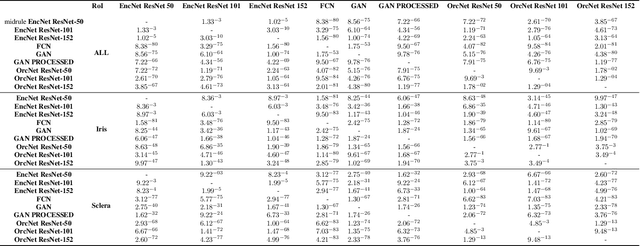
Accurate extraction of the Region of Interest is critical for successful ocular region-based biometrics. In this direction, we propose a new context-based segmentation approach, entitled Ocular Region Context Network (ORCNet), introducing a specific loss function, i.e., he Punish Context Loss (PC-Loss). The PC-Loss punishes the segmentation losses of a network by using a percentage difference value between the ground truth and the segmented masks. We obtain the percentage difference by taking into account Biederman's semantic relationship concepts, in which we use three contexts (semantic, spatial, and scale) to evaluate the relationships of the objects in an image. Our proposal achieved promising results in the evaluated scenarios: iris, sclera, and ALL (iris + sclera) segmentations, utperforming the literature baseline techniques. The ORCNet with ResNet-152 outperforms the best baseline (EncNet with ResNet-152) on average by 2.27%, 28.26% and 6.43% in terms of F-Score, Error Rate and Intersection Over Union, respectively. We also provide (for research purposes) 3,191 manually labeled masks for the MICHE-I database, as another contribution of our work.
Image-based Automatic Dial Meter Reading in Unconstrained Scenarios
Jan 08, 2022

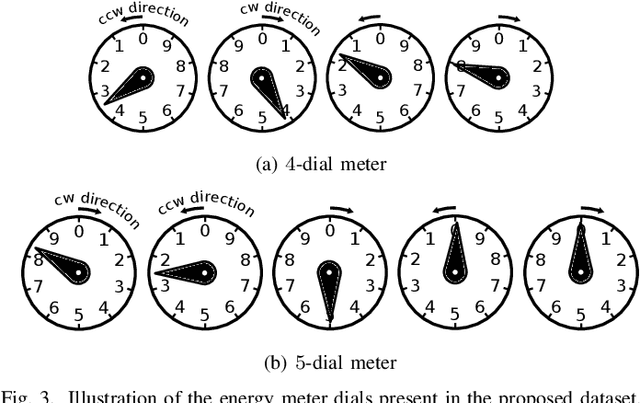
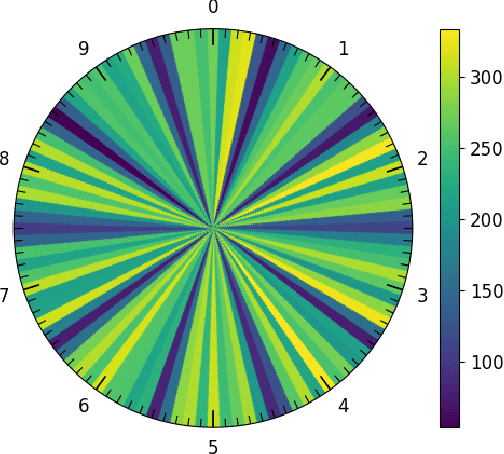
The replacement of analog meters with smart meters is costly, laborious, and far from complete in developing countries. The Energy Company of Parana (Copel) (Brazil) performs more than 4 million meter readings (almost entirely of non-smart devices) per month, and we estimate that 850 thousand of them are from dial meters. Therefore, an image-based automatic reading system can reduce human errors, create a proof of reading, and enable the customers to perform the reading themselves through a mobile application. We propose novel approaches for Automatic Dial Meter Reading (ADMR) and introduce a new dataset for ADMR in unconstrained scenarios, called UFPR-ADMR-v2. Our best-performing method combines YOLOv4 with a novel regression approach (AngReg), and explores several postprocessing techniques. Compared to previous works, it decreased the Mean Absolute Error (MAE) from 1,343 to 129 and achieved a meter recognition rate (MRR) of 98.90% -- with an error tolerance of 1 Kilowatt-hour (kWh).
On the Cross-dataset Generalization in License Plate Recognition
Jan 04, 2022
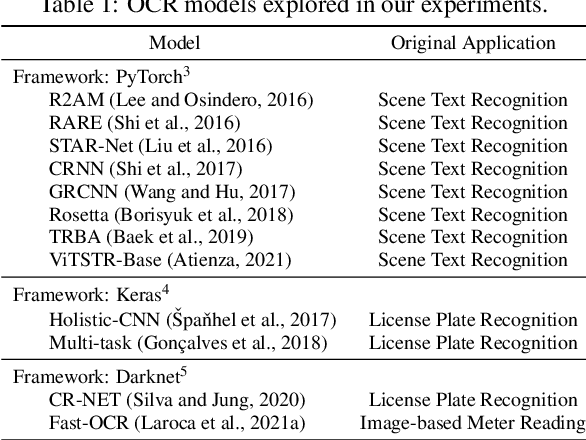
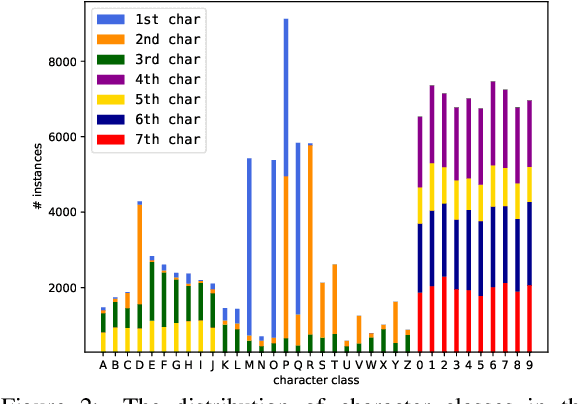
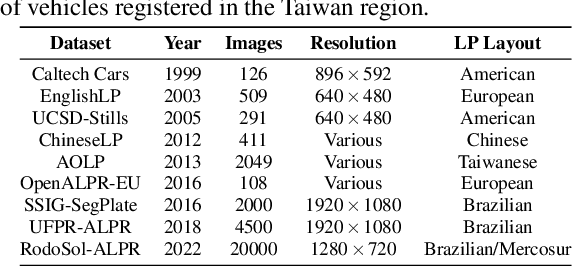
Automatic License Plate Recognition (ALPR) systems have shown remarkable performance on license plates (LPs) from multiple regions due to advances in deep learning and the increasing availability of datasets. The evaluation of deep ALPR systems is usually done within each dataset; therefore, it is questionable if such results are a reliable indicator of generalization ability. In this paper, we propose a traditional-split versus leave-one-dataset-out experimental setup to empirically assess the cross-dataset generalization of 12 Optical Character Recognition (OCR) models applied to LP recognition on nine publicly available datasets with a great variety in several aspects (e.g., acquisition settings, image resolution, and LP layouts). We also introduce a public dataset for end-to-end ALPR that is the first to contain images of vehicles with Mercosur LPs and the one with the highest number of motorcycle images. The experimental results shed light on the limitations of the traditional-split protocol for evaluating approaches in the ALPR context, as there are significant drops in performance for most datasets when training and testing the models in a leave-one-dataset-out fashion.
Tell me what you see: A zero-shot action recognition method based on natural language descriptions
Dec 18, 2021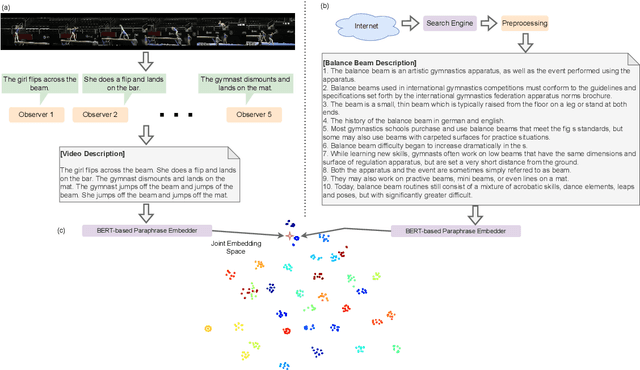
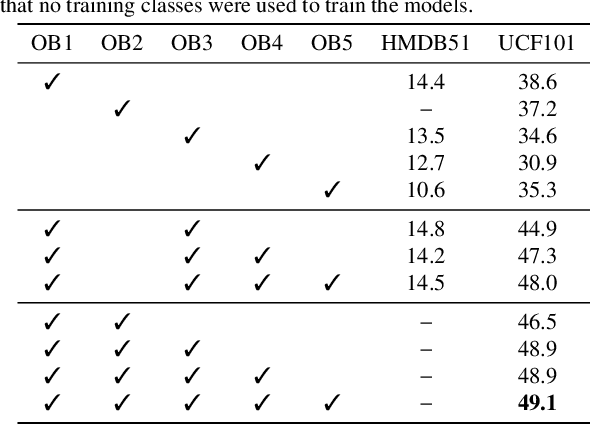

Recently, several approaches have explored the detection and classification of objects in videos to perform Zero-Shot Action Recognition with remarkable results. In these methods, class-object relationships are used to associate visual patterns with the semantic side information because these relationships also tend to appear in texts. Therefore, word vector methods would reflect them in their latent representations. Inspired by these methods and by video captioning's ability to describe events not only with a set of objects but with contextual information, we propose a method in which video captioning models, called observers, provide different and complementary descriptive sentences. We demonstrate that representing videos with descriptive sentences instead of deep features, in ZSAR, is viable and naturally alleviates the domain adaptation problem, as we reached state-of-the-art (SOTA) performance on the UCF101 dataset and competitive performance on HMDB51 without their training sets. We also demonstrate that word vectors are unsuitable for building the semantic embedding space of our descriptions. Thus, we propose to represent the classes with sentences extracted from documents acquired with search engines on the Internet, without any human evaluation on the quality of descriptions. Lastly, we build a shared semantic space employing BERT-based embedders pre-trained in the paraphrasing task on multiple text datasets. We show that this pre-training is essential for bridging the semantic gap. The projection onto this space is straightforward for both types of information, visual and semantic, because they are sentences, enabling the classification with nearest neighbour rule in this shared space. Our code is available at https://github.com/valterlej/zsarcap.
Dense Video Captioning Using Unsupervised Semantic Information
Dec 15, 2021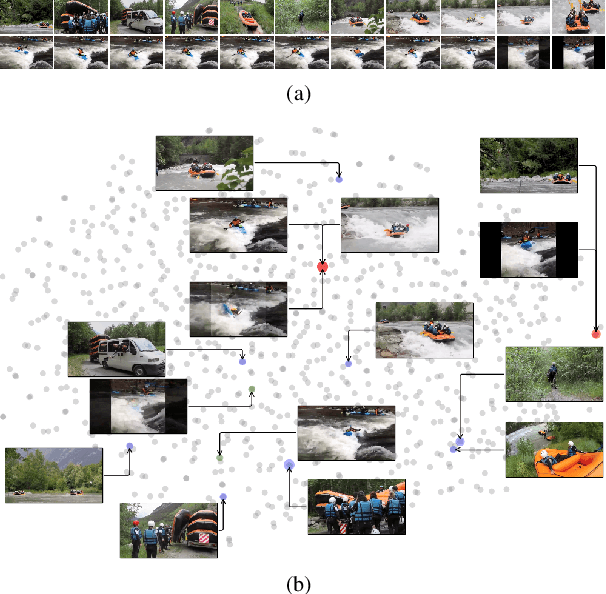
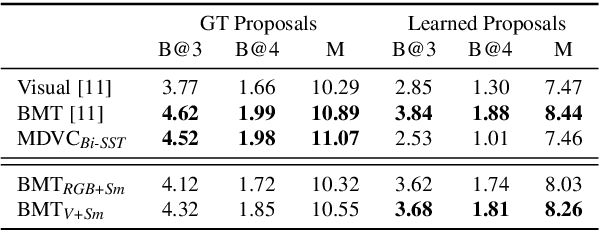
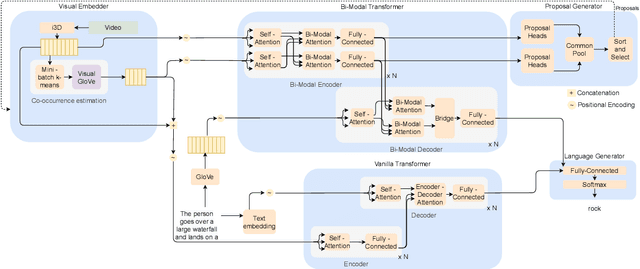
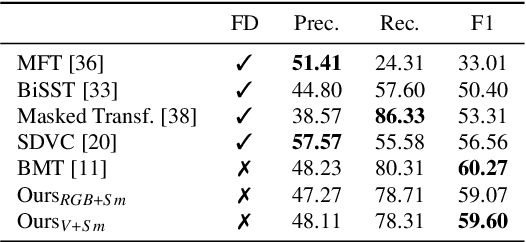
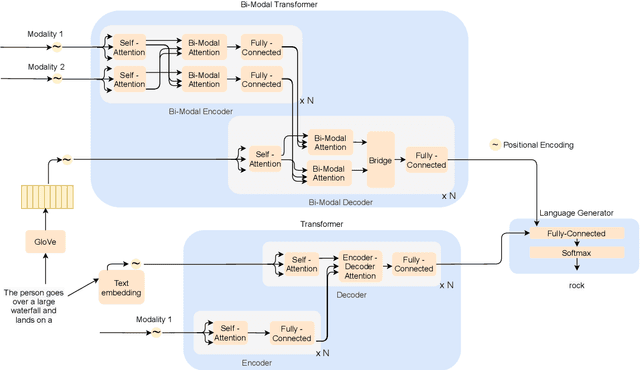
We introduce a method to learn unsupervised semantic visual information based on the premise that complex events (e.g., minutes) can be decomposed into simpler events (e.g., a few seconds), and that these simple events are shared across several complex events. We split a long video into short frame sequences to extract their latent representation with three-dimensional convolutional neural networks. A clustering method is used to group representations producing a visual codebook (i.e., a long video is represented by a sequence of integers given by the cluster labels). A dense representation is learned by encoding the co-occurrence probability matrix for the codebook entries. We demonstrate how this representation can leverage the performance of the dense video captioning task in a scenario with only visual features. As a result of this approach, we are able to replace the audio signal in the Bi-Modal Transformer (BMT) method and produce temporal proposals with comparable performance. Furthermore, we concatenate the visual signal with our descriptor in a vanilla transformer method to achieve state-of-the-art performance in captioning compared to the methods that explore only visual features, as well as a competitive performance with multi-modal methods. Our code is available at https://github.com/valterlej/dvcusi.
A Decidability-Based Loss Function
Sep 12, 2021
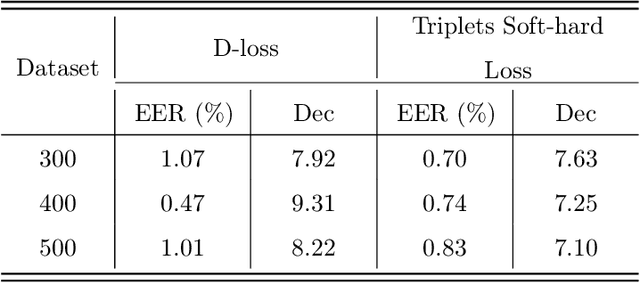
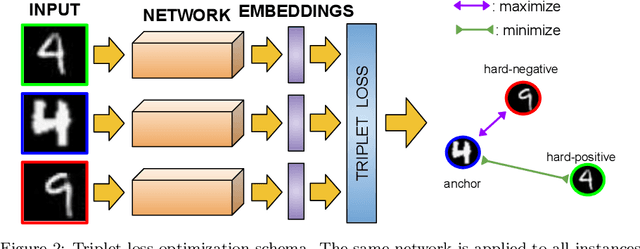

Nowadays, deep learning is the standard approach for a wide range of problems, including biometrics, such as face recognition and speech recognition, etc. Biometric problems often use deep learning models to extract features from images, also known as embeddings. Moreover, the loss function used during training strongly influences the quality of the generated embeddings. In this work, a loss function based on the decidability index is proposed to improve the quality of embeddings for the verification routine. Our proposal, the D-loss, avoids some Triplet-based loss disadvantages such as the use of hard samples and tricky parameter tuning, which can lead to slow convergence. The proposed approach is compared against the Softmax (cross-entropy), Triplets Soft-Hard, and the Multi Similarity losses in four different benchmarks: MNIST, Fashion-MNIST, CIFAR10 and CASIA-IrisV4. The achieved results show the efficacy of the proposal when compared to other popular metrics in the literature. The D-loss computation, besides being simple, non-parametric and easy to implement, favors both the inter-class and intra-class scenarios.
Open-set Face Recognition for Small Galleries Using Siamese Networks
May 14, 2021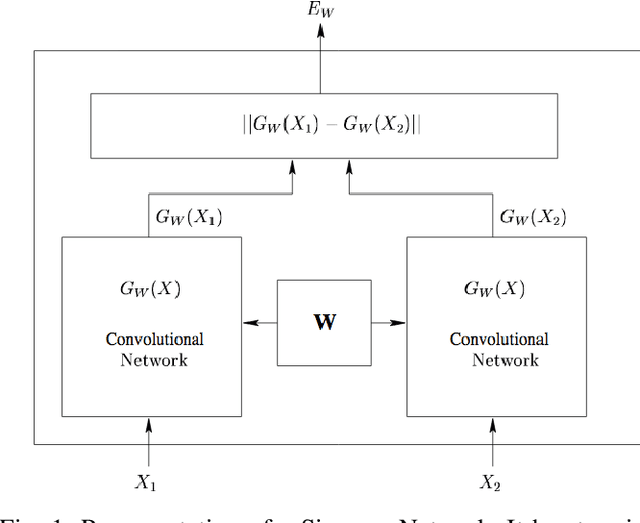
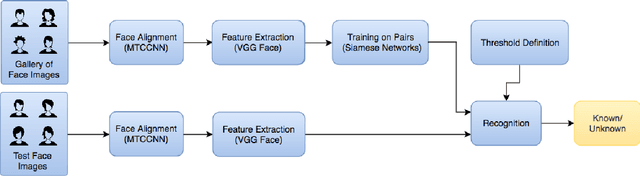
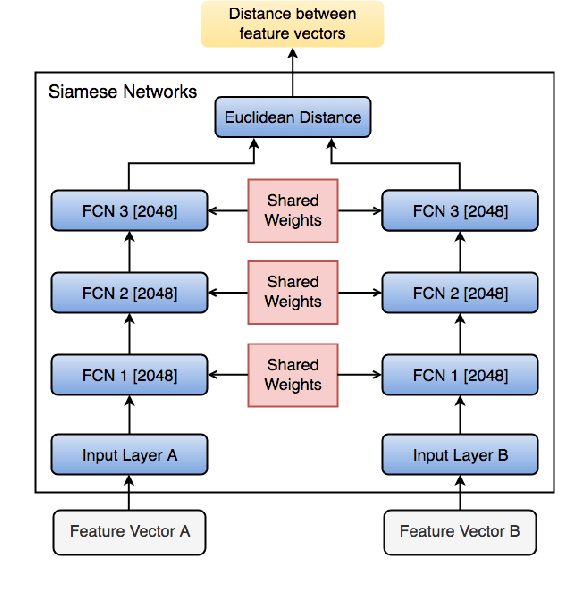

Face recognition has been one of the most relevant and explored fields of Biometrics. In real-world applications, face recognition methods usually must deal with scenarios where not all probe individuals were seen during the training phase (open-set scenarios). Therefore, open-set face recognition is a subject of increasing interest as it deals with identifying individuals in a space where not all faces are known in advance. This is useful in several applications, such as access authentication, on which only a few individuals that have been previously enrolled in a gallery are allowed. The present work introduces a novel approach towards open-set face recognition focusing on small galleries and in enrollment detection, not identity retrieval. A Siamese Network architecture is proposed to learn a model to detect if a face probe is enrolled in the gallery based on a verification-like approach. Promising results were achieved for small galleries on experiments carried out on Pubfig83, FRGCv1 and LFW datasets. State-of-the-art methods like HFCN and HPLS were outperformed on FRGCv1. Besides, a new evaluation protocol is introduced for experiments in small galleries on LFW.
UFPR-Periocular: A Periocular Dataset Collected by Mobile Devices in Unconstrained Scenarios
Nov 24, 2020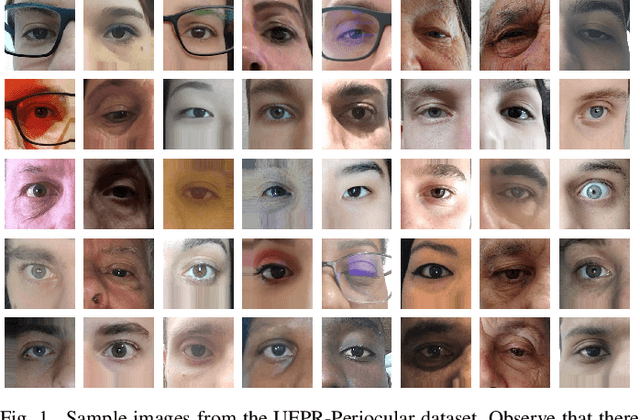
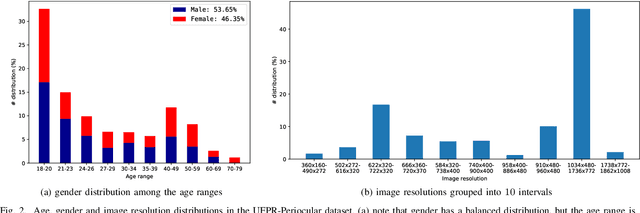
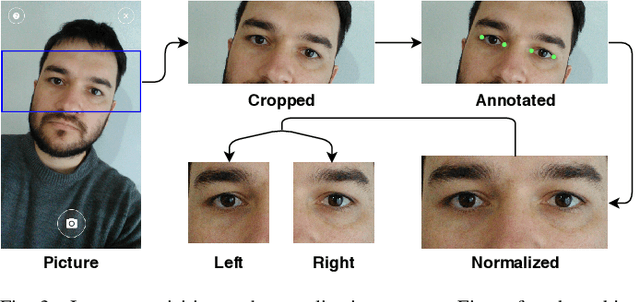
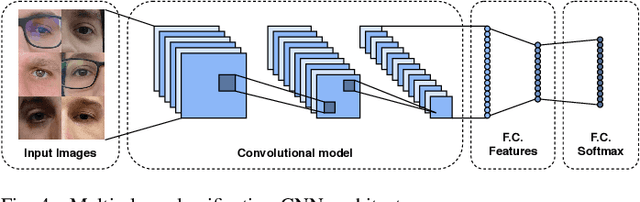
Recently, ocular biometrics in unconstrained environments using images obtained at visible wavelength have gained the researchers' attention, especially with images captured by mobile devices. Periocular recognition has been demonstrated to be an alternative when the iris trait is not available due to occlusions or low image resolution. However, the periocular trait does not have the high uniqueness presented in the iris trait. Thus, the use of datasets containing many subjects is essential to assess biometric systems' capacity to extract discriminating information from the periocular region. Also, to address the within-class variability caused by lighting and attributes in the periocular region, it is of paramount importance to use datasets with images of the same subject captured in distinct sessions. As the datasets available in the literature do not present all these factors, in this work, we present a new periocular dataset containing samples from 1,122 subjects, acquired in 3 sessions by 196 different mobile devices. The images were captured under unconstrained environments with just a single instruction to the participants: to place their eyes on a region of interest. We also performed an extensive benchmark with several Convolutional Neural Network (CNN) architectures and models that have been employed in state-of-the-art approaches based on Multi-class Classification, Multitask Learning, Pairwise Filters Network, and Siamese Network. The results achieved in the closed- and open-world protocol, considering the identification and verification tasks, show that this area still needs research and development.