 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Medical Deconfounder: Assessing Treatment Effect with Electronic Health Records (EHRs)
Apr 03, 2019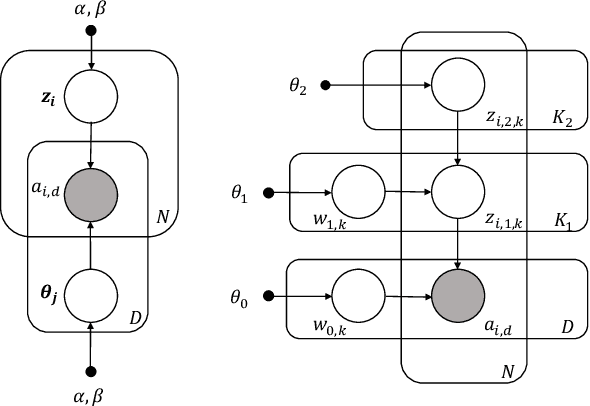
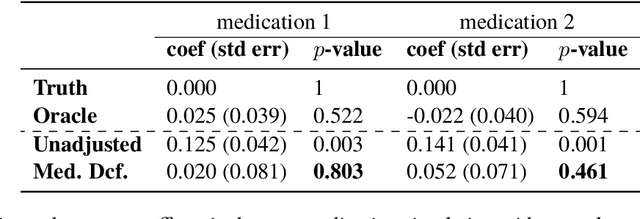
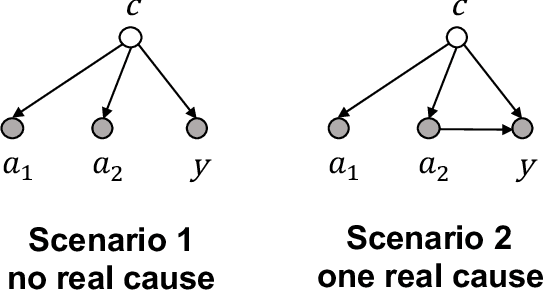
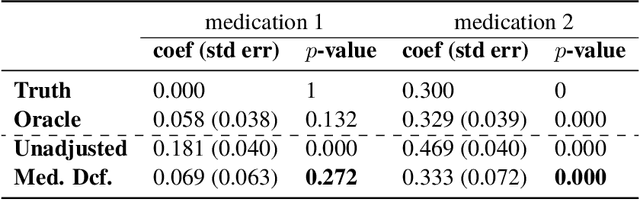
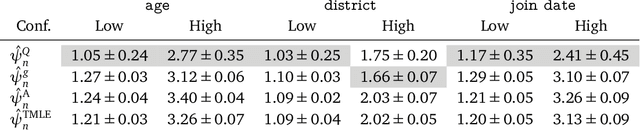
Causal estimation of treatment effect has an important role in guiding physicians' decision process for drug prescription. While treatment effect is classically assessed with randomized controlled trials (RCTs), the availability of electronic health records (EHRs) bring an unprecedented opportunity for more efficient estimation. However, the presence of unobserved confounders makes treatment effect assessment from EHRs a challenging task. Confounders are the variables that affect both drug prescription and the patient's outcome; examples include a patient's gender, race, social economic status and comorbidities. When these confounders are unobserved, they bias the estimation. To adjust for unobserved confounders, we develop the medical deconfounder, a machine learning algorithm that unbiasedly estimates treatment effect from EHRs. The medical deconfounder first constructs a substitute confounder by modeling which drugs were prescribed to each patient; this substitute confounder is guaranteed to capture all multi-drug confounders, observed or unobserved (Wang and Blei, 2018). It then uses this substitute confounder to adjust for the confounding bias in the analysis. We validate the medical deconfounder on simulations and two medical data sets. The medical deconfounder produces closer-to-truth estimates in simulations and identifies effective medications that are more consistent with the findings reported in the medical literature compared to classical approaches.
Using Embeddings to Correct for Unobserved Confounding
Feb 11, 2019
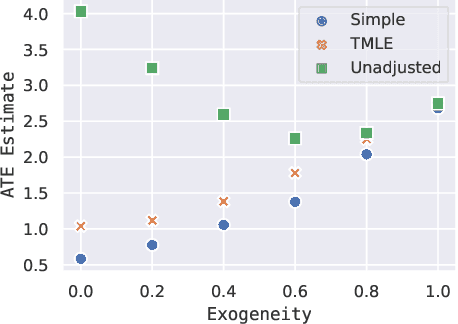
We consider causal inference in the presence of unobserved confounding. In particular, we study the case where a proxy is available for the confounder but the proxy has non-iid structure. As one example, the link structure of a social network carries information about its members. As another, the text of a document collection carries information about their meanings. In both these settings, we show how to effectively use the proxy to do causal inference. The main idea is to reduce the causal estimation problem to a semi-supervised prediction of both the treatments and outcomes. Networks and text both admit high-quality embedding models that can be used for this semi-supervised prediction. Our method yields valid inferences under suitable (weak) conditions on the quality of the predictive model. We validate the method with experiments on a semi-synthetic social network dataset. We demonstrate the method by estimating the causal effect of properties of computer science submissions on whether they are accepted at a conference.
A Probabilistic Model of Cardiac Physiology and Electrocardiograms
Dec 01, 2018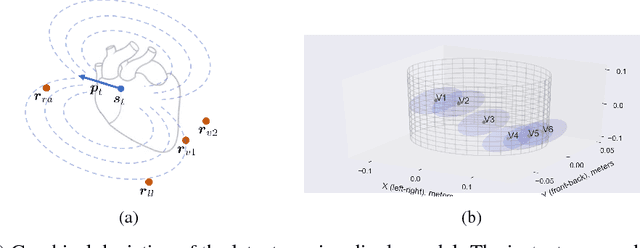
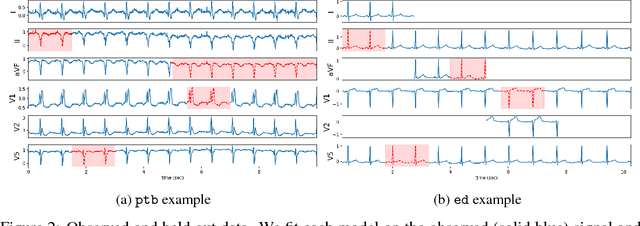
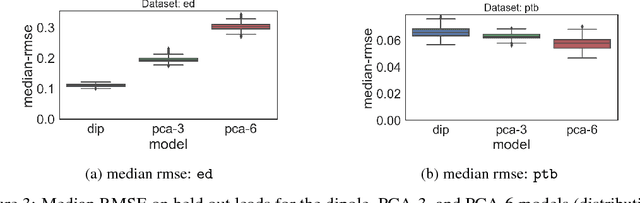
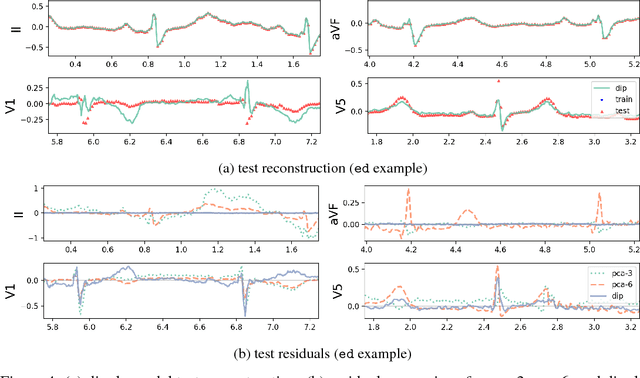
An electrocardiogram (EKG) is a common, non-invasive test that measures the electrical activity of a patient's heart. EKGs contain useful diagnostic information about patient health that may be absent from other electronic health record (EHR) data. As multi-dimensional waveforms, they could be modeled using generic machine learning tools, such as a linear factor model or a variational autoencoder. We take a different approach:~we specify a model that directly represents the underlying electrophysiology of the heart and the EKG measurement process. We apply our model to two datasets, including a sample of emergency department EKG reports with missing data. We show that our model can more accurately reconstruct missing data (measured by test reconstruction error) than a standard baseline when there is significant missing data. More broadly, this physiological representation of heart function may be useful in a variety of settings, including prediction, causal analysis, and discovery.
The Deconfounded Recommender: A Causal Inference Approach to Recommendation
Aug 20, 2018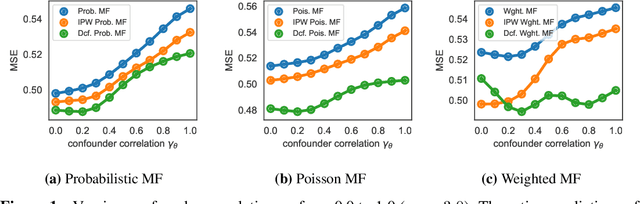
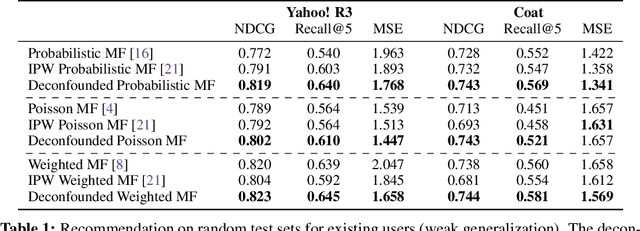
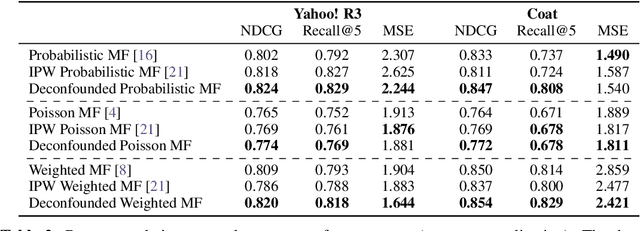
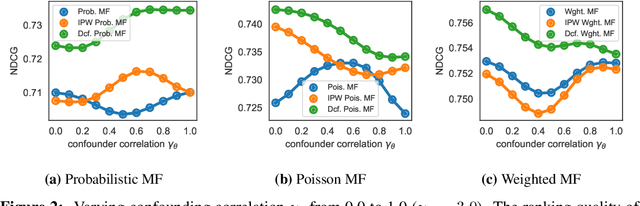
The goal of a recommender system is to show its users items that they will like. In forming its prediction, the recommender system tries to answer: "what would the rating be if we 'forced' the user to watch the movie?" This is a question about an intervention in the world, a causal question, and so traditional recommender systems are doing causal inference from observational data. This paper develops a causal inference approach to recommendation. Traditional recommenders are likely biased by unobserved confounders, variables that affect both the "treatment assignments" (which movies the users watch) and the "outcomes" (how they rate them). We develop the deconfounded recommender, a strategy to leverage classical recommendation models for causal predictions. The deconfounded recommender uses Poisson factorization on which movies users watched to infer latent confounders in the data; it then augments common recommendation models to correct for potential confounding bias. The deconfounded recommender improves recommendation and it enjoys stable performance against interventions on test sets.
Noisin: Unbiased Regularization for Recurrent Neural Networks
Jul 13, 2018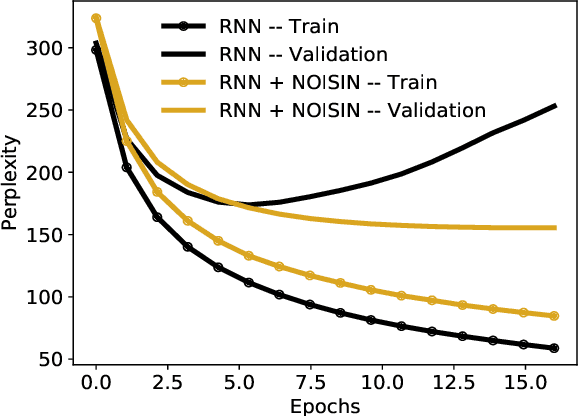
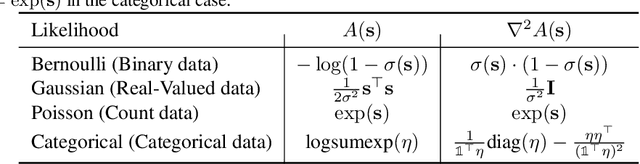

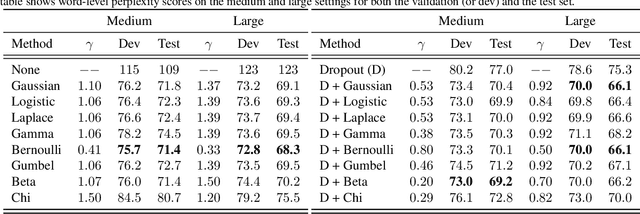
Recurrent neural networks (RNNs) are powerful models of sequential data. They have been successfully used in domains such as text and speech. However, RNNs are susceptible to overfitting; regularization is important. In this paper we develop Noisin, a new method for regularizing RNNs. Noisin injects random noise into the hidden states of the RNN and then maximizes the corresponding marginal likelihood of the data. We show how Noisin applies to any RNN and we study many different types of noise. Noisin is unbiased--it preserves the underlying RNN on average. We characterize how Noisin regularizes its RNN both theoretically and empirically. On language modeling benchmarks, Noisin improves over dropout by as much as 12.2% on the Penn Treebank and 9.4% on the Wikitext-2 dataset. We also compared the state-of-the-art language model of Yang et al. 2017, both with and without Noisin. On the Penn Treebank, the method with Noisin more quickly reaches state-of-the-art performance.
Avoiding Latent Variable Collapse With Generative Skip Models
Jul 12, 2018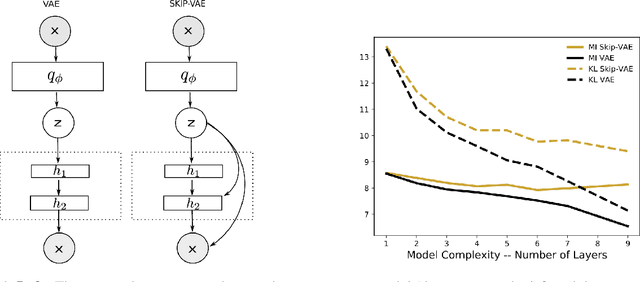
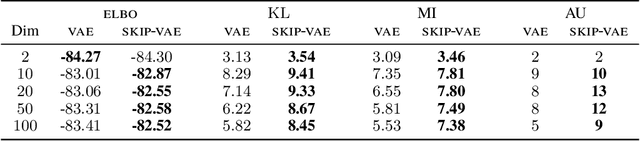

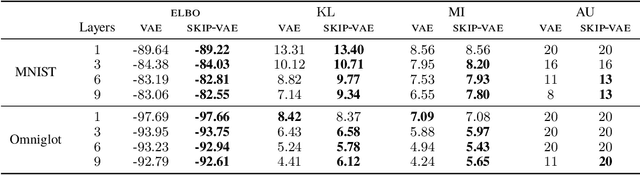
Variational autoencoders (VAEs) learn distributions of high-dimensional data. They model data by introducing a deep latent-variable model and then maximizing a lower bound of the log marginal likelihood. While VAEs can capture complex distributions, they also suffer from an issue known as "latent variable collapse." Specifically, the lower bound involves an approximate posterior of the latent variables; this posterior "collapses" when it is set equal to the prior, i.e., when the posterior is independent of the data. While VAEs learn good generative models, latent variable collapse prevents them from learning useful representations. In this paper, we propose a new way to avoid latent variable collapse. We expand the model class to one that includes skip connections; these connections enforce strong links between the latent variables and the likelihood function. We study these generative skip models both theoretically and empirically. Theoretically, we prove that skip models increase the mutual information between the observations and the inferred latent variables. Empirically, on both images (MNIST and Omniglot) and text (Yahoo), we show that generative skip models lead to less collapse than existing VAE architectures.
SHOPPER: A Probabilistic Model of Consumer Choice with Substitutes and Complements
Jul 02, 2018
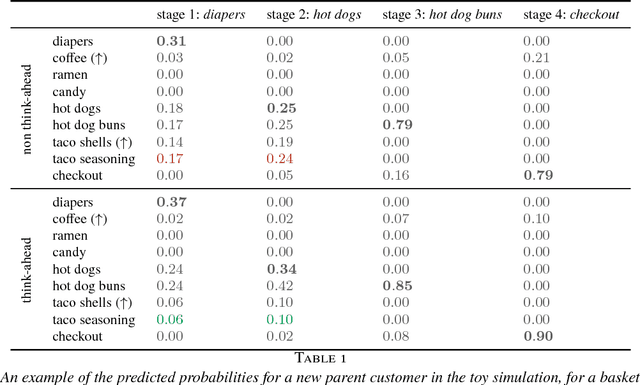
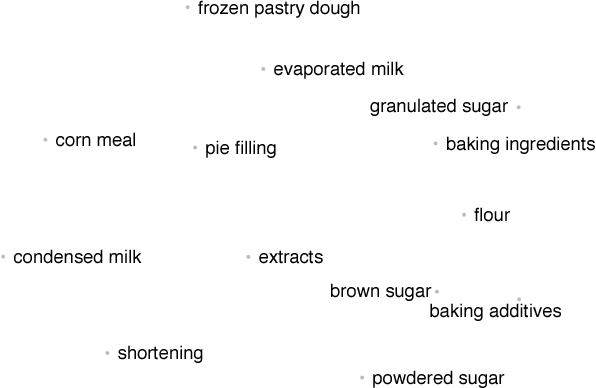

We develop SHOPPER, a sequential probabilistic model of shopping data. SHOPPER uses interpretable components to model the forces that drive how a customer chooses products; in particular, we designed SHOPPER to capture how items interact with other items. We develop an efficient posterior inference algorithm to estimate these forces from large-scale data, and we analyze a large dataset from a major chain grocery store. We are interested in answering counterfactual queries about changes in prices. We found that SHOPPER provides accurate predictions even under price interventions, and that it helps identify complementary and substitutable pairs of products.
Empirical Risk Minimization and Stochastic Gradient Descent for Relational Data
Jun 27, 2018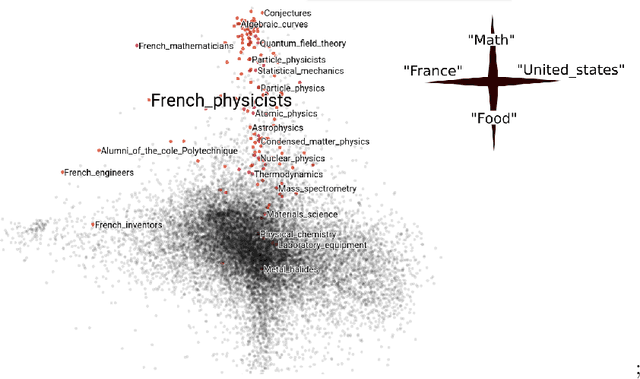


Empirical risk minimization is the principal tool for prediction problems, but its extension to relational data remains unsolved. We solve this problem using recent advances in graph sampling theory. We (i) define an empirical risk for relational data and (ii) obtain stochastic gradients for this risk that are automatically unbiased. The key ingredient is to consider the method by which data is sampled from a graph as an explicit component of model design. Theoretical results establish that the choice of sampling scheme is critical. By integrating fast implementations of graph sampling schemes with standard automatic differentiation tools, we are able to solve the risk minimization in a plug-and-play fashion even on large datasets. We demonstrate empirically that relational ERM models achieve state-of-the-art results on semi-supervised node classification tasks. The experiments also confirm the importance of the choice of sampling scheme.
Robust Probabilistic Modeling with Bayesian Data Reweighting
Jun 19, 2018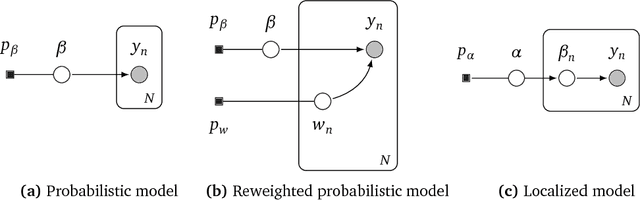

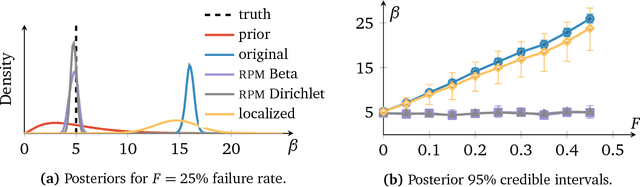
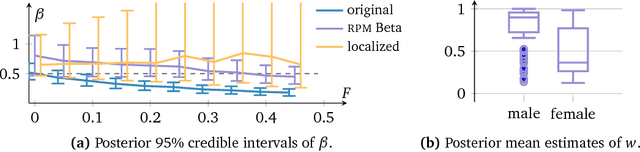
Probabilistic models analyze data by relying on a set of assumptions. Data that exhibit deviations from these assumptions can undermine inference and prediction quality. Robust models offer protection against mismatch between a model's assumptions and reality. We propose a way to systematically detect and mitigate mismatch of a large class of probabilistic models. The idea is to raise the likelihood of each observation to a weight and then to infer both the latent variables and the weights from data. Inferring the weights allows a model to identify observations that match its assumptions and down-weight others. This enables robust inference and improves predictive accuracy. We study four different forms of mismatch with reality, ranging from missing latent groups to structure misspecification. A Poisson factorization analysis of the Movielens 1M dataset shows the benefits of this approach in a practical scenario.
The Blessings of Multiple Causes
Jun 19, 2018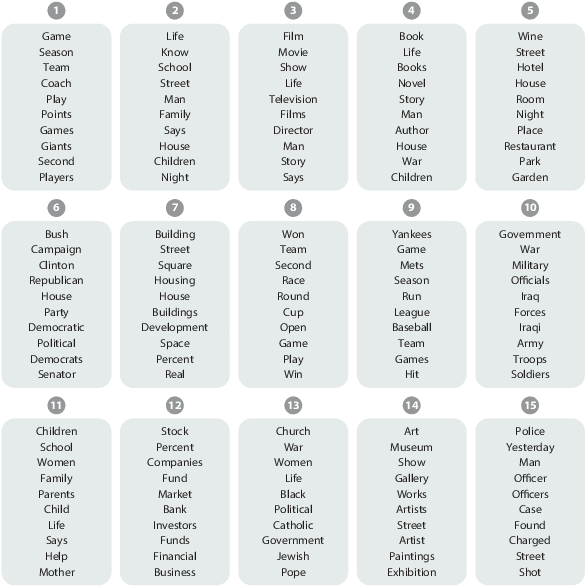
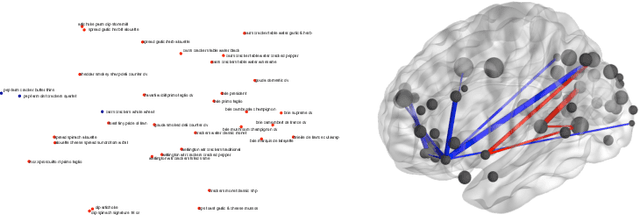
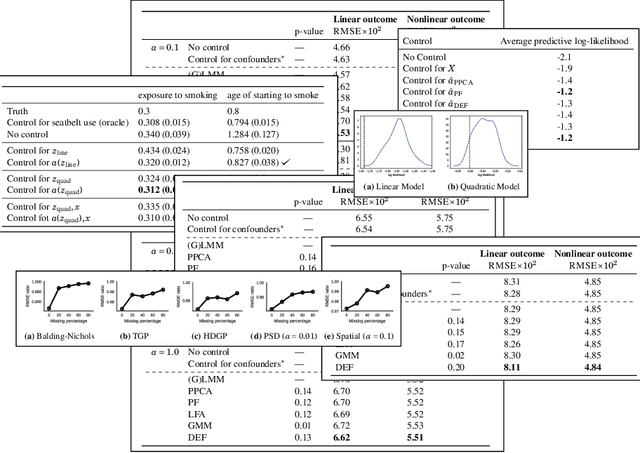
Causal inference from observational data often assumes "strong ignorability," that all confounders are observed. This assumption is standard yet untestable. However, many scientific studies involve multiple causes, different variables whose effects are simultaneously of interest. We propose the deconfounder, an algorithm that combines unsupervised machine learning and predictive model checking to perform causal inference in multiple-cause settings. The deconfounder infers a latent variable as a substitute for unobserved confounders and then uses that substitute to perform causal inference. We develop theory for when the deconfounder leads to unbiased causal estimates, and show that it requires weaker assumptions than classical causal inference. We analyze its performance in three types of studies: semi-simulated data around smoking and lung cancer, semi-simulated data around genomewide association studies, and a real dataset about actors and movie revenue. The deconfounder provides a checkable approach to estimating close-to-truth causal effects.