 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausal Generative Neural Networks
Feb 05, 2018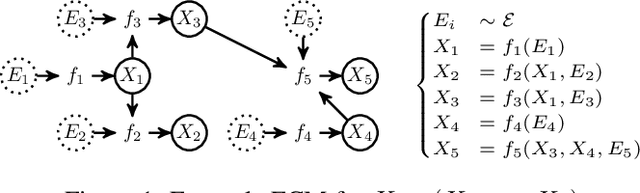
We present Causal Generative Neural Networks (CGNNs) to learn functional causal models from observational data. CGNNs leverage conditional independencies and distributional asymmetries to discover bivariate and multivariate causal structures. CGNNs make no assumption regarding the lack of confounders, and learn a differentiable generative model of the data by using backpropagation. Extensive experiments show their good performances comparatively to the state of the art in observational causal discovery on both simulated and real data, with respect to cause-effect inference, v-structure identification, and multivariate causal discovery.
Gradient Episodic Memory for Continual Learning
Nov 04, 2017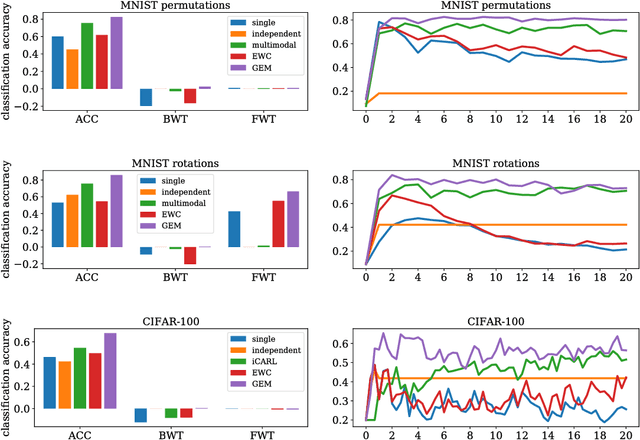

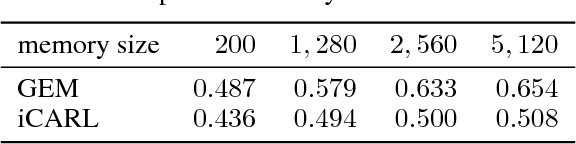
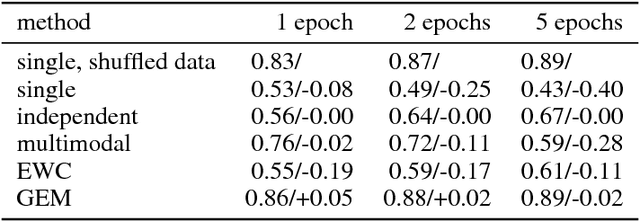
One major obstacle towards AI is the poor ability of models to solve new problems quicker, and without forgetting previously acquired knowledge. To better understand this issue, we study the problem of continual learning, where the model observes, once and one by one, examples concerning a sequence of tasks. First, we propose a set of metrics to evaluate models learning over a continuum of data. These metrics characterize models not only by their test accuracy, but also in terms of their ability to transfer knowledge across tasks. Second, we propose a model for continual learning, called Gradient Episodic Memory (GEM) that alleviates forgetting, while allowing beneficial transfer of knowledge to previous tasks. Our experiments on variants of the MNIST and CIFAR-100 datasets demonstrate the strong performance of GEM when compared to the state-of-the-art.
Discovering Causal Signals in Images
Oct 31, 2017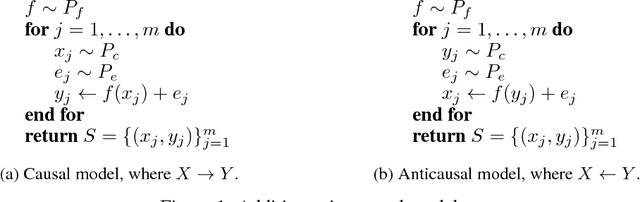
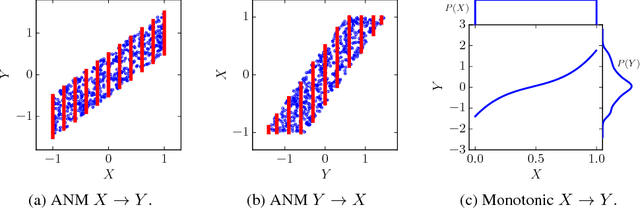

This paper establishes the existence of observable footprints that reveal the "causal dispositions" of the object categories appearing in collections of images. We achieve this goal in two steps. First, we take a learning approach to observational causal discovery, and build a classifier that achieves state-of-the-art performance on finding the causal direction between pairs of random variables, given samples from their joint distribution. Second, we use our causal direction classifier to effectively distinguish between features of objects and features of their contexts in collections of static images. Our experiments demonstrate the existence of a relation between the direction of causality and the difference between objects and their contexts, and by the same token, the existence of observable signals that reveal the causal dispositions of objects.
Patient-Driven Privacy Control through Generalized Distillation
Oct 13, 2017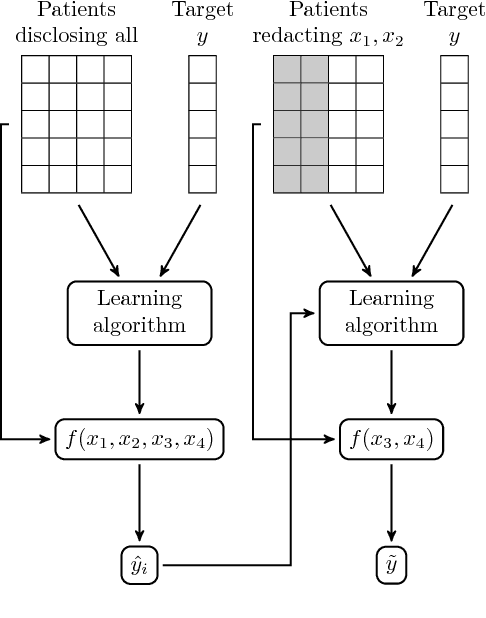

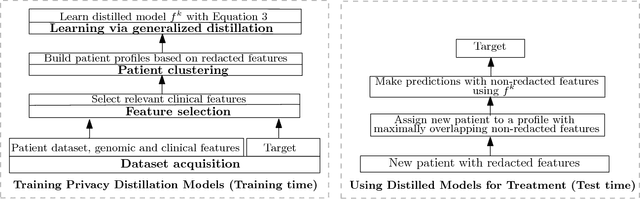
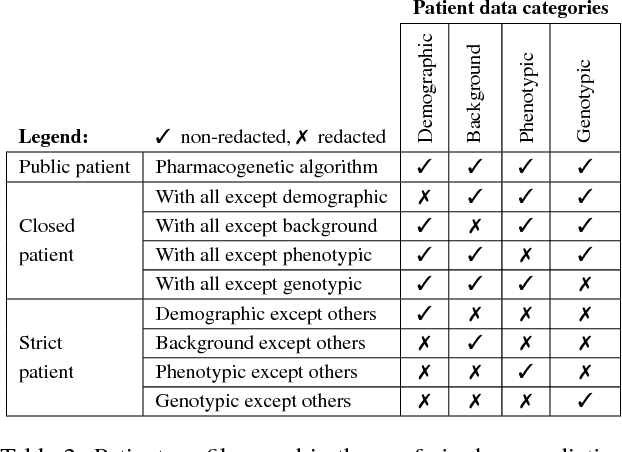
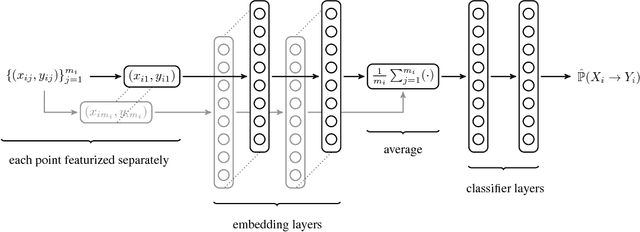
The introduction of data analytics into medicine has changed the nature of patient treatment. In this, patients are asked to disclose personal information such as genetic markers, lifestyle habits, and clinical history. This data is then used by statistical models to predict personalized treatments. However, due to privacy concerns, patients often desire to withhold sensitive information. This self-censorship can impede proper diagnosis and treatment, which may lead to serious health complications and even death over time. In this paper, we present privacy distillation, a mechanism which allows patients to control the type and amount of information they wish to disclose to the healthcare providers for use in statistical models. Meanwhile, it retains the accuracy of models that have access to all patient data under a sufficient but not full set of privacy-relevant information. We validate privacy distillation using a corpus of patients prescribed to warfarin for a personalized dosage. We use a deep neural network to implement privacy distillation for training and making dose predictions. We find that privacy distillation with sufficient privacy-relevant information i) retains accuracy almost as good as having all patient data (only 3\% worse), and ii) is effective at preventing errors that introduce health-related risks (only 3.9\% worse under- or over-prescriptions).
Learning Functional Causal Models with Generative Neural Networks
Oct 04, 2017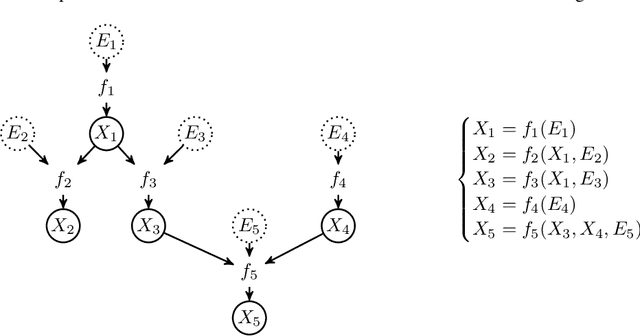
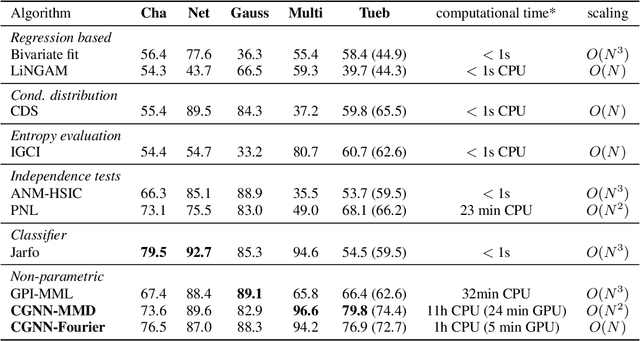
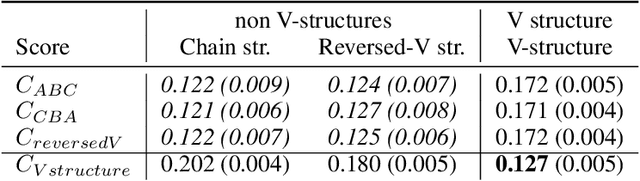
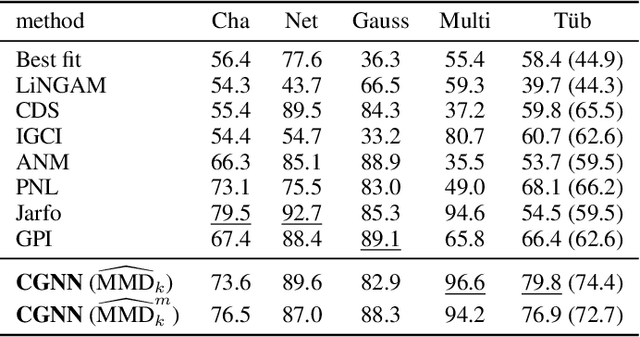
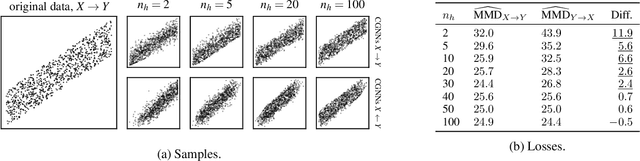
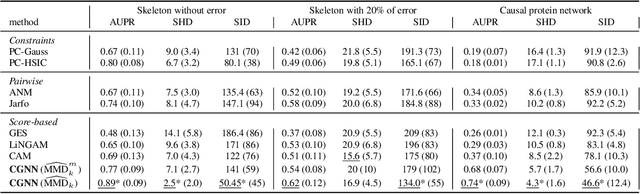
We introduce a new approach to functional causal modeling from observational data. The approach, called Causal Generative Neural Networks (CGNN), leverages the power of neural networks to learn a generative model of the joint distribution of the observed variables, by minimizing the Maximum Mean Discrepancy between generated and observed data. An approximate learning criterion is proposed to scale the computational cost of the approach to linear complexity in the number of observations. The performance of CGNN is studied throughout three experiments. First, we apply CGNN to the problem of cause-effect inference, where two CGNNs model $P(Y|X,\textrm{noise})$ and $P(X|Y,\textrm{noise})$ identify the best causal hypothesis out of $X\rightarrow Y$ and $Y\rightarrow X$. Second, CGNN is applied to the problem of identifying v-structures and conditional independences. Third, we apply CGNN to problem of multivariate functional causal modeling: given a skeleton describing the dependences in a set of random variables $\{X_1, \ldots, X_d\}$, CGNN orients the edges in the skeleton to uncover the directed acyclic causal graph describing the causal structure of the random variables. On all three tasks, CGNN is extensively assessed on both artificial and real-world data, comparing favorably to the state-of-the-art. Finally, we extend CGNN to handle the case of confounders, where latent variables are involved in the overall causal model.
Optimizing the Latent Space of Generative Networks
Jul 18, 2017
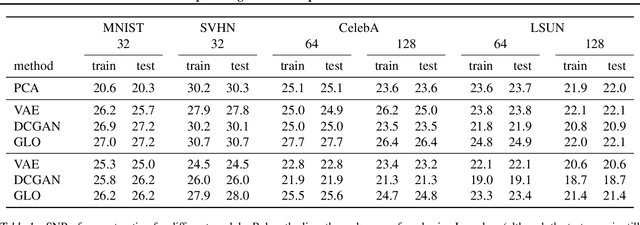


Generative Adversarial Networks (GANs) have been shown to be able to sample impressively realistic images. GAN training consists of a saddle point optimization problem that can be thought of as an adversarial game between a generator which produces the images, and a discriminator, which judges if the images are real. Both the generator and the discriminator are commonly parametrized as deep convolutional neural networks. The goal of this paper is to disentangle the contribution of the optimization procedure and the network parametrization to the success of GANs. To this end we introduce and study Generative Latent Optimization (GLO), a framework to train a generator without the need to learn a discriminator, thus avoiding challenging adversarial optimization problems. We show experimentally that GLO enjoys many of the desirable properties of GANs: learning from large data, synthesizing visually-appealing samples, interpolating meaningfully between samples, and performing linear arithmetic with noise vectors.
Causal Discovery Using Proxy Variables
Feb 23, 2017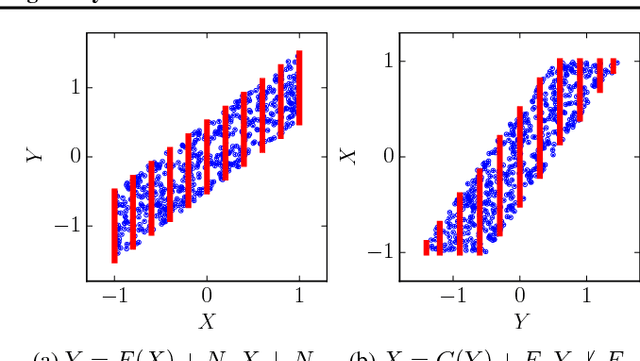
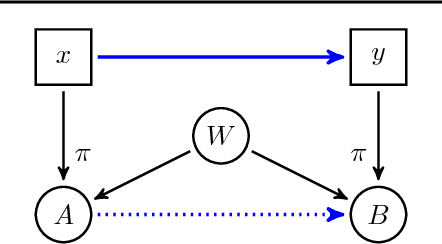
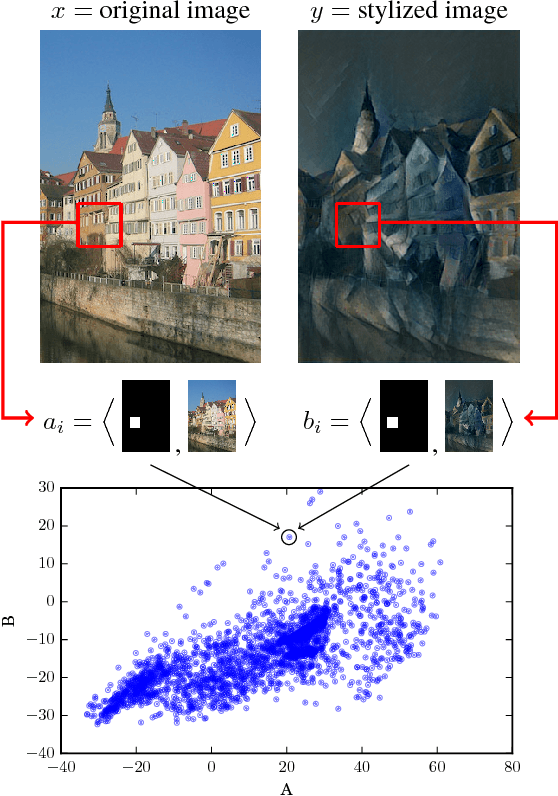

Discovering causal relations is fundamental to reasoning and intelligence. In particular, observational causal discovery algorithms estimate the cause-effect relation between two random entities $X$ and $Y$, given $n$ samples from $P(X,Y)$. In this paper, we develop a framework to estimate the cause-effect relation between two static entities $x$ and $y$: for instance, an art masterpiece $x$ and its fraudulent copy $y$. To this end, we introduce the notion of proxy variables, which allow the construction of a pair of random entities $(A,B)$ from the pair of static entities $(x,y)$. Then, estimating the cause-effect relation between $A$ and $B$ using an observational causal discovery algorithm leads to an estimation of the cause-effect relation between $x$ and $y$. For example, our framework detects the causal relation between unprocessed photographs and their modifications, and orders in time a set of shuffled frames from a video. As our main case study, we introduce a human-elicited dataset of 10,000 pairs of casually-linked pairs of words from natural language. Our methods discover 75% of these causal relations. Finally, we discuss the role of proxy variables in machine learning, as a general tool to incorporate static knowledge into prediction tasks.
From Dependence to Causation
Jul 12, 2016
Machine learning is the science of discovering statistical dependencies in data, and the use of those dependencies to perform predictions. During the last decade, machine learning has made spectacular progress, surpassing human performance in complex tasks such as object recognition, car driving, and computer gaming. However, the central role of prediction in machine learning avoids progress towards general-purpose artificial intelligence. As one way forward, we argue that causal inference is a fundamental component of human intelligence, yet ignored by learning algorithms. Causal inference is the problem of uncovering the cause-effect relationships between the variables of a data generating system. Causal structures provide understanding about how these systems behave under changing, unseen environments. In turn, knowledge about these causal dynamics allows to answer "what if" questions, describing the potential responses of the system under hypothetical manipulations and interventions. Thus, understanding cause and effect is one step from machine learning towards machine reasoning and machine intelligence. But, currently available causal inference algorithms operate in specific regimes, and rely on assumptions that are difficult to verify in practice. This thesis advances the art of causal inference in three different ways. First, we develop a framework for the study of statistical dependence based on copulas and random features. Second, we build on this framework to interpret the problem of causal inference as the task of distribution classification, yielding a family of novel causal inference algorithms. Third, we discover causal structures in convolutional neural network features using our algorithms. The algorithms presented in this thesis are scalable, exhibit strong theoretical guarantees, and achieve state-of-the-art performance in a variety of real-world benchmarks.
No Regret Bound for Extreme Bandits
Apr 11, 2016Algorithms for hyperparameter optimization abound, all of which work well under different and often unverifiable assumptions. Motivated by the general challenge of sequentially choosing which algorithm to use, we study the more specific task of choosing among distributions to use for random hyperparameter optimization. This work is naturally framed in the extreme bandit setting, which deals with sequentially choosing which distribution from a collection to sample in order to minimize (maximize) the single best cost (reward). Whereas the distributions in the standard bandit setting are primarily characterized by their means, a number of subtleties arise when we care about the minimal cost as opposed to the average cost. For example, there may not be a well-defined "best" distribution as there is in the standard bandit setting. The best distribution depends on the rewards that have been obtained and on the remaining time horizon. Whereas in the standard bandit setting, it is sensible to compare policies with an oracle which plays the single best arm, in the extreme bandit setting, there are multiple sensible oracle models. We define a sensible notion of "extreme regret" in the extreme bandit setting, which parallels the concept of regret in the standard bandit setting. We then prove that no policy can asymptotically achieve no extreme regret.
Unifying distillation and privileged information
Feb 26, 2016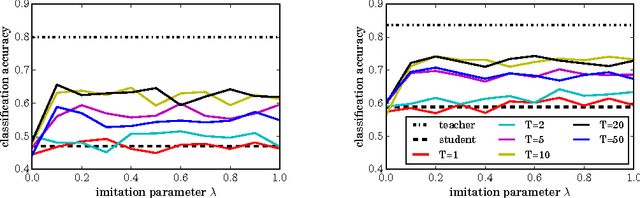
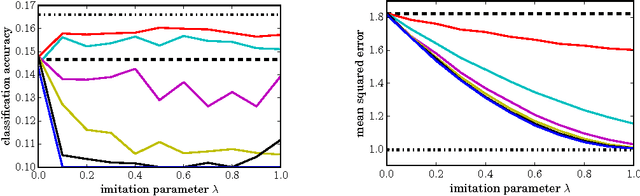
Distillation (Hinton et al., 2015) and privileged information (Vapnik & Izmailov, 2015) are two techniques that enable machines to learn from other machines. This paper unifies these two techniques into generalized distillation, a framework to learn from multiple machines and data representations. We provide theoretical and causal insight about the inner workings of generalized distillation, extend it to unsupervised, semisupervised and multitask learning scenarios, and illustrate its efficacy on a variety of numerical simulations on both synthetic and real-world data.