 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemorization in NLP Fine-tuning Methods
May 25, 2022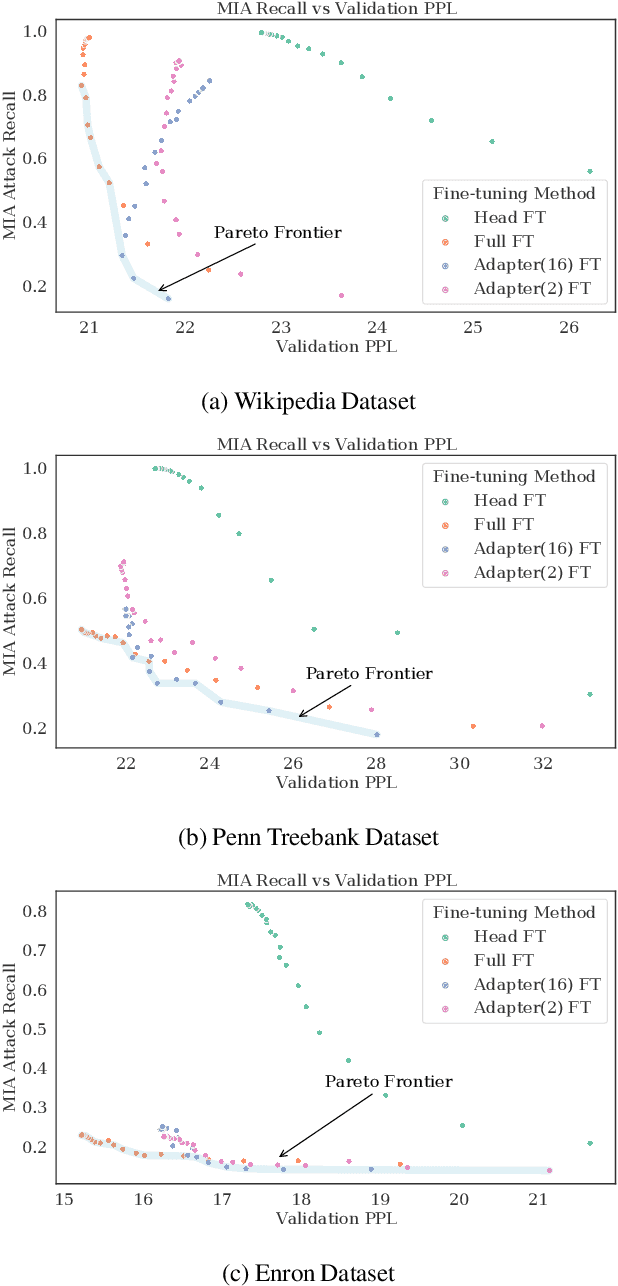
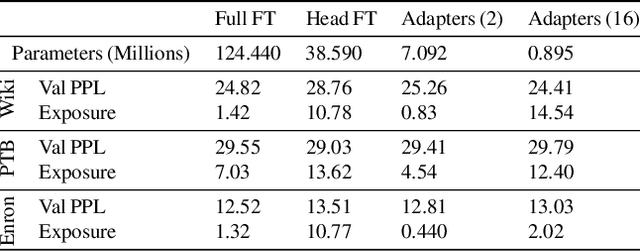
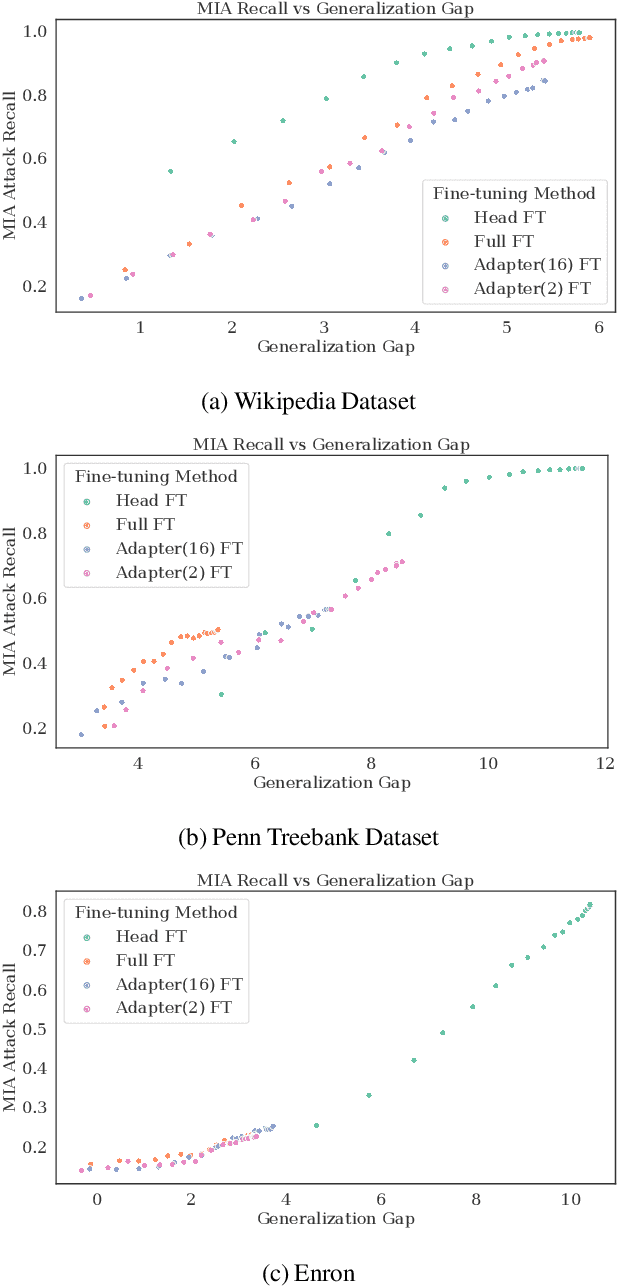

Large language models are shown to present privacy risks through memorization of training data, and several recent works have studied such risks for the pre-training phase. Little attention, however, has been given to the fine-tuning phase and it is not well understood how different fine-tuning methods (such as fine-tuning the full model, the model head, and adapter) compare in terms of memorization risk. This presents increasing concern as the "pre-train and fine-tune" paradigm proliferates. In this paper, we empirically study memorization of fine-tuning methods using membership inference and extraction attacks, and show that their susceptibility to attacks is very different. We observe that fine-tuning the head of the model has the highest susceptibility to attacks, whereas fine-tuning smaller adapters appears to be less vulnerable to known extraction attacks.
Formalizing and Estimating Distribution Inference Risks
Sep 24, 2021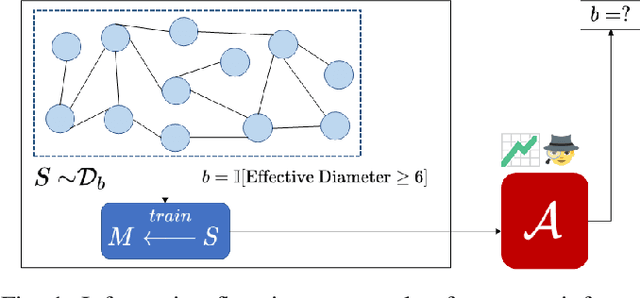
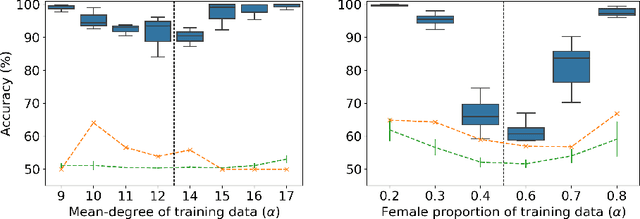
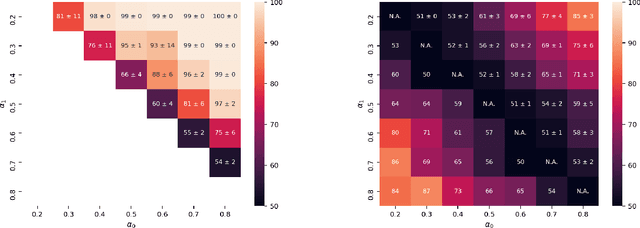
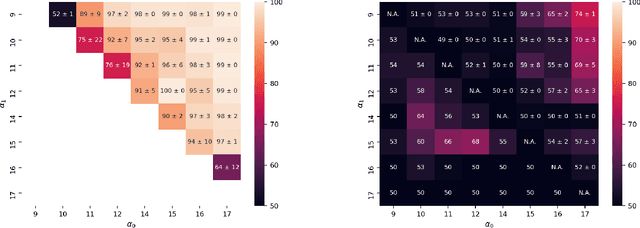
Property inference attacks reveal statistical properties about a training set but are difficult to distinguish from the intrinsic purpose of statistical machine learning, namely to produce models that capture statistical properties about a distribution. Motivated by Yeom et al.'s membership inference framework, we propose a formal and general definition of property inference attacks. The proposed notion describes attacks that can distinguish between possible training distributions, extending beyond previous property inference attacks that infer the ratio of a particular type of data in the training data set such as the proportion of females. We show how our definition captures previous property inference attacks as well as a new attack that can reveal the average node degree or clustering coefficient of a training graph. Our definition also enables a theorem that connects the maximum possible accuracy of inference attacks distinguishing between distributions to the effective size of dataset leaked by the model. To quantify and understand property inference risks, we conduct a series of experiments across a range of different distributions using both black-box and white-box attacks. Our results show that inexpensive attacks are often as effective as expensive meta-classifier attacks, and that there are surprising asymmetries in the effectiveness of attacks. We also extend the state-of-the-art property inference attack to work on convolutional neural networks, and propose techniques to help identify parameters in a model that leak the most information, thus significantly lowering resource requirements for meta-classifier attacks.
Incorporating Label Uncertainty in Understanding Adversarial Robustness
Jul 07, 2021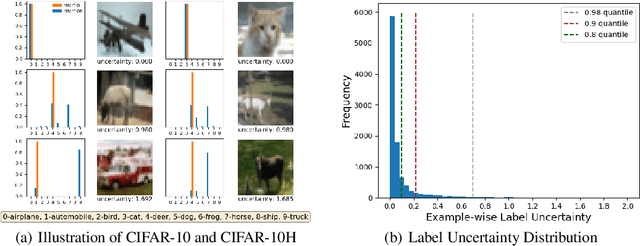
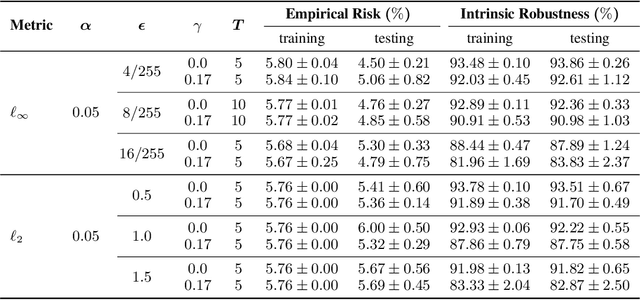
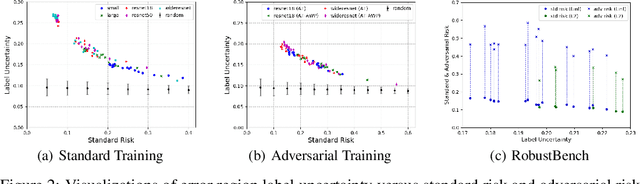
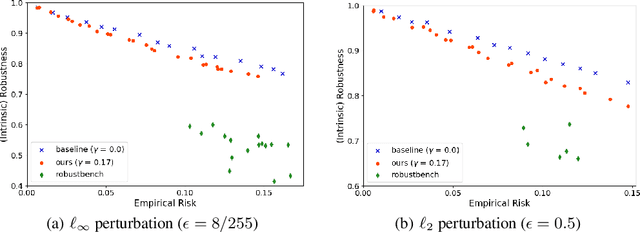
A fundamental question in adversarial machine learning is whether a robust classifier exists for a given task. A line of research has made progress towards this goal by studying concentration of measure, but without considering data labels. We argue that the standard concentration fails to fully characterize the intrinsic robustness of a classification problem, since it ignores data labels which are essential to any classification task. Building on a novel definition of label uncertainty, we empirically demonstrate that error regions induced by state-of-the-art models tend to have much higher label uncertainty compared with randomly-selected subsets. This observation motivates us to adapt a concentration estimation algorithm to account for label uncertainty, resulting in more accurate intrinsic robustness measures for benchmark image classification problems. We further provide empirical evidence showing that adding an abstain option for classifiers based on label uncertainty can help improve both the clean and robust accuracies of models.
Formalizing Distribution Inference Risks
Jun 07, 2021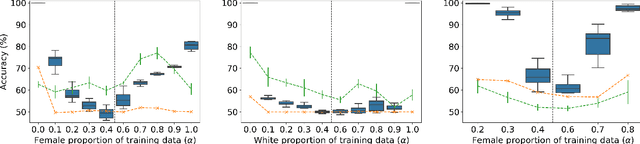
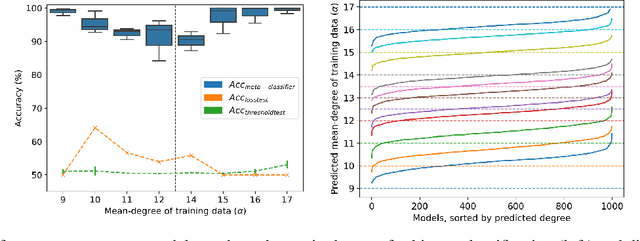
Property inference attacks reveal statistical properties about a training set but are difficult to distinguish from the primary purposes of statistical machine learning, which is to produce models that capture statistical properties about a distribution. Motivated by Yeom et al.'s membership inference framework, we propose a formal and generic definition of property inference attacks. The proposed notion describes attacks that can distinguish between possible training distributions, extending beyond previous property inference attacks that infer the ratio of a particular type of data in the training data set. In this paper, we show how our definition captures previous property inference attacks as well as a new attack that reveals the average degree of nodes of a training graph and report on experiments giving insight into the potential risks of property inference attacks.
Stealthy Backdoors as Compression Artifacts
Apr 30, 2021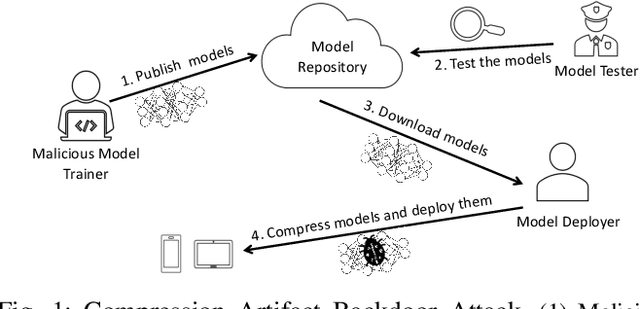
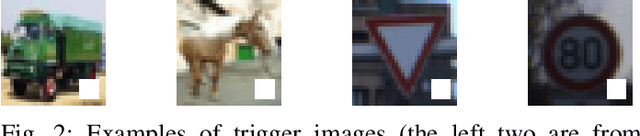
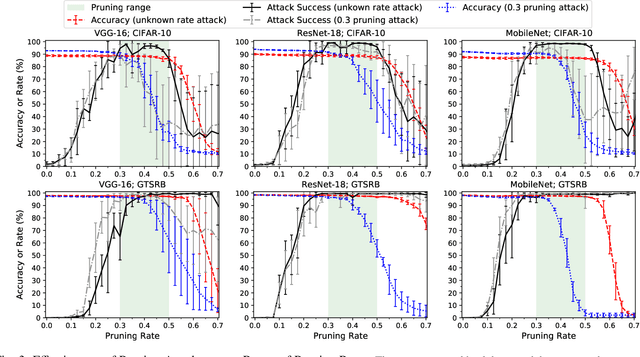

In a backdoor attack on a machine learning model, an adversary produces a model that performs well on normal inputs but outputs targeted misclassifications on inputs containing a small trigger pattern. Model compression is a widely-used approach for reducing the size of deep learning models without much accuracy loss, enabling resource-hungry models to be compressed for use on resource-constrained devices. In this paper, we study the risk that model compression could provide an opportunity for adversaries to inject stealthy backdoors. We design stealthy backdoor attacks such that the full-sized model released by adversaries appears to be free from backdoors (even when tested using state-of-the-art techniques), but when the model is compressed it exhibits highly effective backdoors. We show this can be done for two common model compression techniques -- model pruning and model quantization. Our findings demonstrate how an adversary may be able to hide a backdoor as a compression artifact, and show the importance of performing security tests on the models that will actually be deployed not their precompressed version.
Improved Estimation of Concentration Under $\ell_p$-Norm Distance Metrics Using Half Spaces
Mar 24, 2021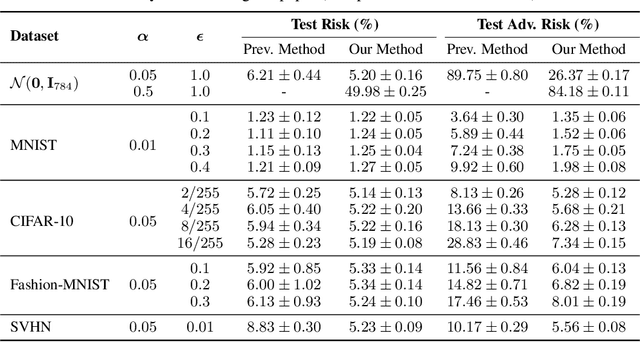
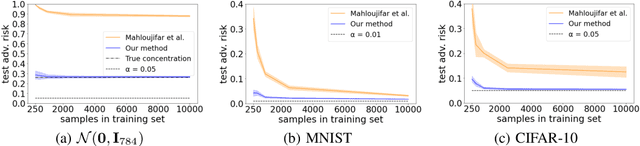
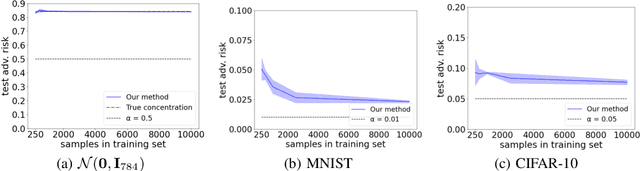
Concentration of measure has been argued to be the fundamental cause of adversarial vulnerability. Mahloujifar et al. presented an empirical way to measure the concentration of a data distribution using samples, and employed it to find lower bounds on intrinsic robustness for several benchmark datasets. However, it remains unclear whether these lower bounds are tight enough to provide a useful approximation for the intrinsic robustness of a dataset. To gain a deeper understanding of the concentration of measure phenomenon, we first extend the Gaussian Isoperimetric Inequality to non-spherical Gaussian measures and arbitrary $\ell_p$-norms ($p \geq 2$). We leverage these theoretical insights to design a method that uses half-spaces to estimate the concentration of any empirical dataset under $\ell_p$-norm distance metrics. Our proposed algorithm is more efficient than Mahloujifar et al.'s, and our experiments on synthetic datasets and image benchmarks demonstrate that it is able to find much tighter intrinsic robustness bounds. These tighter estimates provide further evidence that rules out intrinsic dataset concentration as a possible explanation for the adversarial vulnerability of state-of-the-art classifiers.
Finding Friends and Flipping Frenemies: Automatic Paraphrase Dataset Augmentation Using Graph Theory
Nov 03, 2020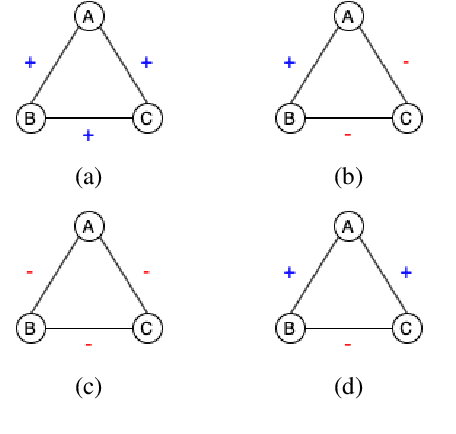
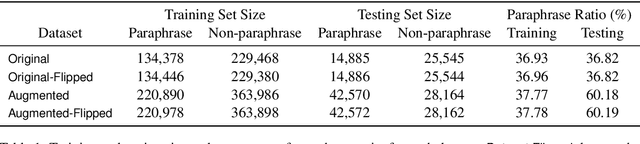
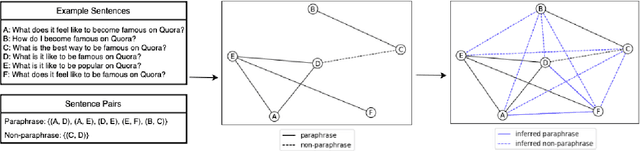
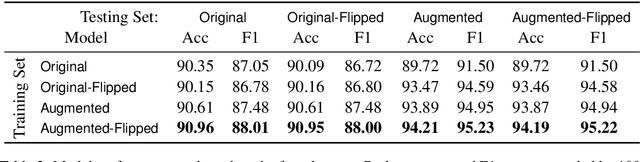
Most NLP datasets are manually labeled, so suffer from inconsistent labeling or limited size. We propose methods for automatically improving datasets by viewing them as graphs with expected semantic properties. We construct a paraphrase graph from the provided sentence pair labels, and create an augmented dataset by directly inferring labels from the original sentence pairs using a transitivity property. We use structural balance theory to identify likely mislabelings in the graph, and flip their labels. We evaluate our methods on paraphrase models trained using these datasets starting from a pretrained BERT model, and find that the automatically-enhanced training sets result in more accurate models.
Model-Targeted Poisoning Attacks: Provable Convergence and Certified Bounds
Jun 30, 2020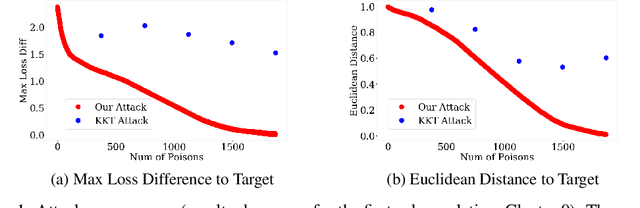

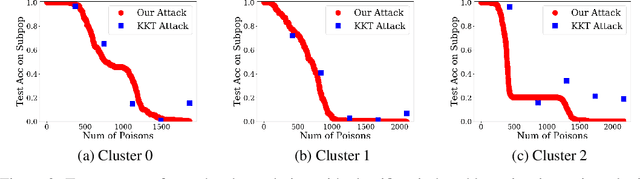

Machine learning systems that rely on training data collected from untrusted sources are vulnerable to poisoning attacks, in which adversaries controlling some of the collected data are able to induce a corrupted model. In this paper, we consider poisoning attacks where there is an adversary who has a particular target classifier in mind and hopes to induce a classifier close to that target by adding as few poisoning points as possible. We propose an efficient poisoning attack based on online convex optimization. Unlike previous model-targeted poisoning attacks, our attack comes with provable convergence to any achievable target classifier. The distance from the induced classifier to the target classifier is inversely proportional to the square root of the number of poisoning points. We also provide a certified lower bound on the minimum number of poisoning points needed to achieve a given target classifier. We report on experiments showing our attack has performance that is similar to or better than the state-of-the-art attacks in terms of attack success rate and distance to the target model, while providing the advantages of provable convergence, and the efficiency benefits associated with being an online attack that can determine near-optimal poisoning points incrementally.
Revisiting Membership Inference Under Realistic Assumptions
Jun 21, 2020
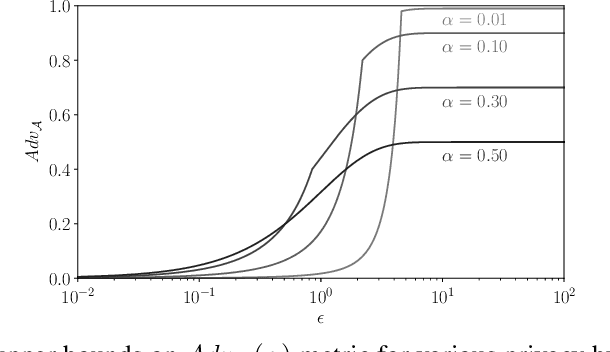
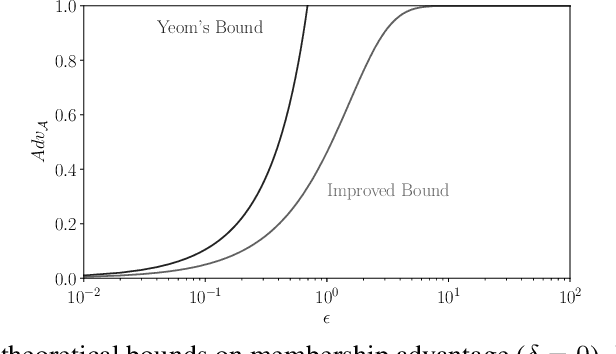

Membership inference attacks on models trained using machine learning have been shown to pose significant privacy risks. However, previous works on membership inference assume a balanced prior distribution where the adversary randomly chooses target records from a pool that has equal numbers of members and non-members. Such an assumption of balanced prior is unrealistic in practical scenarios. This paper studies membership inference attacks under more realistic assumptions. First, we consider skewed priors where a non-member is more likely to occur than a member record. For this, we use metric based on positive predictive value (PPV) in conjunction with membership advantage for privacy leakage evaluation, since PPV considers the prior. Second, we consider adversaries that can select inference thresholds according to their attack goals. For this, we develop a threshold selection procedure that improves inference attacks. We also propose a new membership inference attack called Merlin which outperforms previous attacks. Our experimental evaluation shows that while models trained without privacy mechanisms are vulnerable to membership inference attacks in balanced prior settings, there appears to be negligible privacy risk in the skewed prior setting. Code for our experiments can be found here: https://github.com/bargavj/EvaluatingDPML.
Pointwise Paraphrase Appraisal is Potentially Problematic
Jun 05, 2020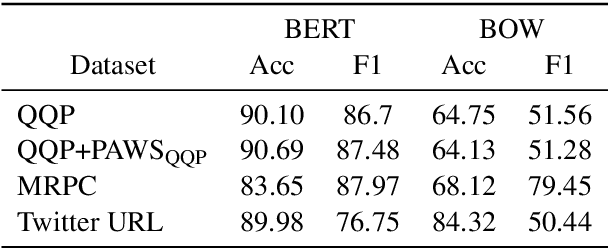
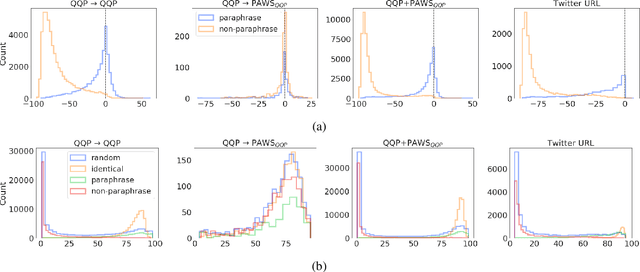
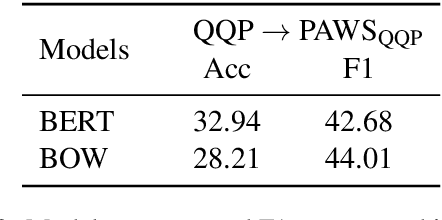
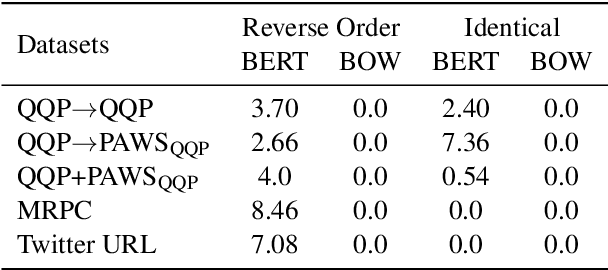
The prevailing approach for training and evaluating paraphrase identification models is constructed as a binary classification problem: the model is given a pair of sentences, and is judged by how accurately it classifies pairs as either paraphrases or non-paraphrases. This pointwise-based evaluation method does not match well the objective of most real world applications, so the goal of our work is to understand how models which perform well under pointwise evaluation may fail in practice and find better methods for evaluating paraphrase identification models. As a first step towards that goal, we show that although the standard way of fine-tuning BERT for paraphrase identification by pairing two sentences as one sequence results in a model with state-of-the-art performance, that model may perform poorly on simple tasks like identifying pairs with two identical sentences. Moreover, we show that these models may even predict a pair of randomly-selected sentences with higher paraphrase score than a pair of identical ones.